

Panoramica
 Suggerisci modifiche
Suggerisci modifiche
La comprensione dell'impatto del tiering FabricPool su Oracle e altri database richiede una conoscenza dell'architettura FabricPool di basso livello.
Architettura
FabricPool è una tecnologia di tiering che classifica i blocchi come "hot" o "cool" e li colloca nel Tier di storage più appropriato. Il Tier di performance è nella maggior parte dei casi collocato nello storage SSD e ospita i blocchi di dati "hot". Il Tier di capacità si trova in un archivio di oggetti e ospita i blocchi di dati "cool". Il supporto per lo storage a oggetti include NetApp StorageGRID, ONTAP S3, archiviazione BLOB di Microsoft Azure, il servizio di storage a oggetti Alibaba Cloud, archiviazione a oggetti IBM Cloud, archiviazione Google Cloud e Amazon AWS S3.
Sono disponibili più policy di tiering che controllano le modalità di classificazione dei blocchi come "hot" o "cool", che possono essere impostate in base al volume e modificate secondo necessità. Solo i blocchi di dati vengono spostati tra i Tier di performance e capacità. I metadati che definiscono la struttura LUN e del file system rimangono sempre sul Tier di performance. Di conseguenza, la gestione è centralizzata su ONTAP. I file e le LUN non appaiono diversi dai dati memorizzati in qualsiasi altra configurazione ONTAP. Il controller NetApp AFF o FAS applica le policy definite per spostare i dati nel Tier appropriato.
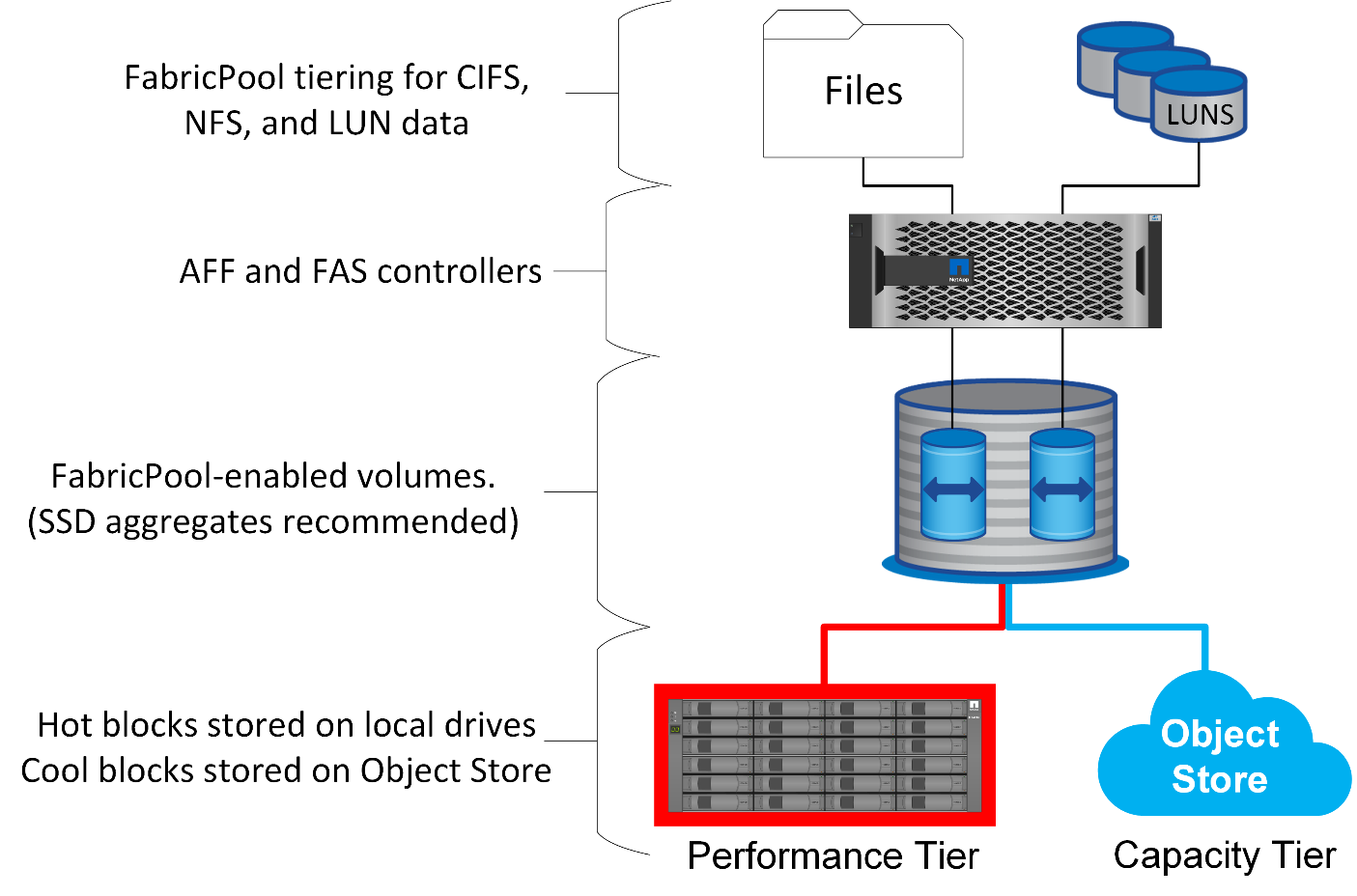
Provider di archivi di oggetti
I protocolli di storage a oggetti utilizzano semplici richieste HTTP o HTTPS per la memorizzazione di un grande numero di oggetti dati. L'accesso allo storage a oggetti deve essere affidabile, poiché l'accesso ai dati da parte di ONTAP dipende dalla puntuale manutenzione delle richieste. Le opzioni includono le opzioni Amazon S3 Standard e accesso poco frequente, Microsoft Azure Hot e Cool Blob Storage, IBM Cloud e Google Cloud. Le opzioni di archiviazione come Amazon Glacier e Amazon Archive non sono supportate, perché il tempo necessario per recuperare i dati può superare le tolleranze dei sistemi operativi e delle applicazioni host.
NetApp StorageGRID è anche supportato e rappresenta una soluzione di livello Enterprise ottimale. Si tratta di un sistema storage a oggetti dalle performance elevate, scalabile e altamente sicuro, in grado di fornire ridondanza geografica per i dati FabricPool nonché per altre applicazioni di archivi di oggetti che hanno sempre più probabilità di far parte di ambienti applicativi Enterprise.
StorageGRID può anche ridurre i costi evitando le spese di uscita imposte da molti provider di cloud pubblici per la lettura dei dati di nuovo dai propri servizi.
Dati e metadati
Si noti che il termine "dati" si applica in questo caso ai blocchi di dati effettivi, non ai metadati. Viene eseguito il tiering solo dei blocchi di dati, mentre i metadati rimangono nel Tier di performance. Inoltre, lo stato di un blocco come caldo o freddo è influenzato solo dalla lettura del blocco di dati effettivo. La semplice lettura del nome, dell'indicatore data e ora o dei metadati di proprietà di un file non influisce sulla posizione dei blocchi di dati sottostanti.
Backup
Anche se FabricPool può ridurre significativamente l'impatto dello storage, non rappresenta di per sé una soluzione di backup. I metadati NetApp WAFL rimangono sempre nel Tier di performance. Se un disastro catastrofico distrugge il Tier di performance, non è possibile creare un nuovo ambiente utilizzando i dati sul Tier di capacità perché non contiene metadati WAFL.
FabricPool, tuttavia, può entrare a far parte di una strategia di backup. Ad esempio, FabricPool può essere configurato con la tecnologia di replica NetApp SnapMirror. Ciascuna metà del mirror può avere la propria connessione a una destinazione dello storage a oggetti. Il risultato sono due copie indipendenti dei dati. La copia primaria è costituita dai blocchi sul Tier di performance e dai blocchi associati nel Tier di capacità, mentre la replica è un secondo set di blocchi di performance e capacità.