

Creare un bucket ONTAP S3 su un aggregato con mirroring o senza mirror in una configurazione MetroCluster
 Suggerisci modifiche
Suggerisci modifiche
A partire da ONTAP 9.14.1, è possibile eseguire il provisioning di un bucket su un aggregato con mirroring o senza mirror nelle configurazioni FC e IP di MetroCluster.
-
Per impostazione predefinita, i bucket sono in provisioning su aggregati con mirroring.
-
Le stesse linee guida per il provisioning delineate in "Creare un bucket" Applicare per creare un bucket in un ambiente MetroCluster.
-
Le seguenti funzioni di storage a oggetti S3 sono non supportate negli ambienti MetroCluster:
-
SnapMirror S3
-
S3 Gestione del ciclo di vita della benna
-
S3 blocco degli oggetti in modalità conformità

S3 è supportato il blocco degli oggetti in modalità Governance. -
Tiering FabricPool locale
-
Una SVM contenente un server S3 deve già esistere.
Processo per la creazione di bucket
-
Se si prevede di selezionare autonomamente aggregati e componenti FlexGroup, impostare il livello di privilegio su Advanced (altrimenti, il livello di privilegio admin è sufficiente):
set -privilege advanced -
Creare un bucket:
vserver object-store-server bucket create -vserver <svm_name> -bucket <bucket_name> [-size integer[KB|MB|GB|TB|PB]] [-use-mirrored-aggregates true/false]Impostare
-use-mirrored-aggregatesopzione a.trueoppurefalsea seconda che si desideri utilizzare un aggregato con mirroring o senza mirror.
Per impostazione predefinita, il -use-mirrored-aggregatesl'opzione è impostata sutrue.-
Il nome della SVM deve essere una SVM dati.
-
Se non si specifica alcuna opzione, ONTAP crea un bucket 800GB con il livello di servizio al livello più alto disponibile per il sistema.
-
Se si desidera che ONTAP crei un bucket in base alle performance o all'utilizzo, utilizzare una delle seguenti opzioni:
-
livello di servizio
Includere il
-storage-service-levelcon uno dei seguenti valori:value,performance, o.extreme. -
tiering
Includere il
-used-as-capacity-tier trueopzione.
-
-
Se si desidera specificare gli aggregati su cui creare il volume FlexGroup sottostante, utilizzare le seguenti opzioni:
-
Il
-aggr-listParametro specifica l'elenco di aggregati da utilizzare per i componenti del volume FlexGroup.Ogni voce dell'elenco crea un costituente nell'aggregato specificato. È possibile specificare un aggregato più volte per creare più costituenti sull'aggregato.
-
Per ottenere performance costanti nel volume FlexGroup, tutti gli aggregati devono utilizzare lo stesso tipo di disco e le stesse configurazioni del gruppo RAID.
-
Il
-aggr-list-multiplieril parametro specifica il numero di iterazioni degli aggregati elencati con-aggr-listQuando si crea un volume FlexGroup.Il valore predefinito di
-aggr-list-multiplieril parametro è 4.
-
-
Aggiungere un gruppo di criteri QoS, se necessario:
vserver object-store-server bucket modify -bucket bucket_name -qos-policy-group qos_policy_group -
Verificare la creazione del bucket:
vserver object-store-server bucket show [-instance]
L'esempio seguente crea un bucket per SVM VS1 di dimensione 1TB su un aggregato mirrorato:
cluster-1::*> vserver object-store-server bucket create -vserver svm1.example.com -bucket testbucket -size 1TB -use-mirrored-aggregates true
-
Aggiungi un nuovo bucket su una VM di storage abilitata per S3.
-
Fare clic su Storage > Bucket, quindi su Add (Aggiungi).
-
Immettere un nome, selezionare la VM di storage e immettere una dimensione.
Per impostazione predefinita, il bucket è in provisioning su un aggregato con mirroring. Se si desidera creare un bucket su un aggregato senza mirror, selezionare altre opzioni e deselezionare la casella Usa il livello SyncMirror in protezione come mostrato nell'immagine seguente:
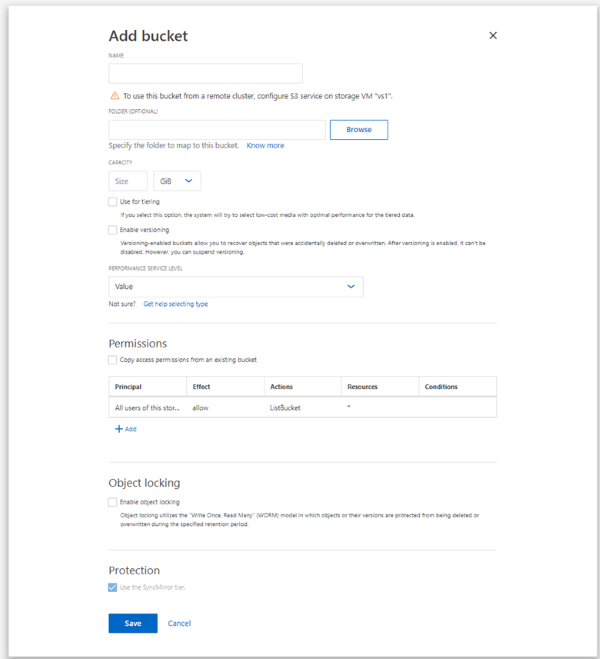
-
Se si fa clic su Save (Salva) a questo punto, viene creato un bucket con le seguenti impostazioni predefinite:
-
A nessun utente viene concesso l'accesso al bucket, a meno che non siano già in vigore policy di gruppo.
Non utilizzare l'utente root S3 per gestire lo storage a oggetti ONTAP e condividerne le autorizzazioni, in quanto dispone di accesso illimitato all'archivio di oggetti. Creare invece un utente o un gruppo con privilegi amministrativi assegnati. -
Un livello di qualità del servizio (performance) il più alto disponibile per il sistema.
-
-
È possibile fare clic su altre opzioni per configurare le autorizzazioni utente e il livello di performance durante la configurazione del bucket, oppure modificare queste impostazioni in un secondo momento.
-
È necessario aver già creato utenti e gruppi prima di utilizzare altre opzioni per configurare le relative autorizzazioni.
-
Se si intende utilizzare l'archivio di oggetti S3 per il tiering FabricPool, si consiglia di selezionare Use for Tiering (utilizzare supporti a basso costo con performance ottimali per i dati a più livelli) piuttosto che un livello di servizio per le performance.
-
-
-
-
Sulle applicazioni client S3 (un altro sistema ONTAP o un'applicazione esterna di 3rd parti), verificare l'accesso al nuovo bucket immettendo quanto segue:
-
Certificato CA del server S3.
-
La chiave di accesso e la chiave segreta dell'utente.
-
Il nome FQDN e il nome bucket del server S3.
-