

Strategia di distribuzione e best practice per ONTAP SnapMirror ActiveSync
 Suggerisci modifiche
Suggerisci modifiche
È importante che la strategia di protezione dei dati identifichi chiaramente i carichi di lavoro che devono essere protetti per garantire la continuità aziendale. Il passaggio più critico nella strategia di protezione dei dati è avere chiarezza nel layout dei dati delle applicazioni aziendali, in modo da poter decidere come distribuire i volumi e proteggere la continuità aziendale. Poiché il failover avviene a livello di gruppo di coerenza per ogni applicazione, assicurarsi di aggiungere i volumi di dati necessari al gruppo di coerenza.
Configurazione SVM
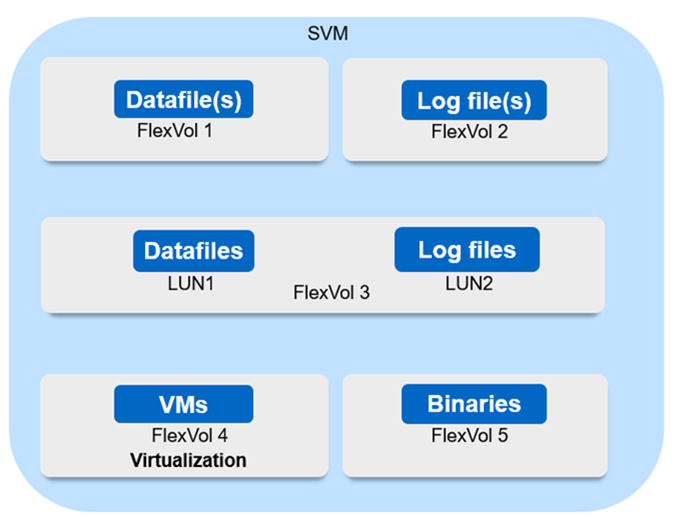
Il diagramma acquisisce la configurazione consigliata di una VM storage (SVM) per la sincronizzazione attiva SnapMirror.
-
Per volumi di dati:
-
I carichi di lavoro random Read sono isolati da scritture sequenziali, pertanto, in base alle dimensioni del database, i file di dati e di log vengono in genere posizionati su volumi separati.
-
Per i database critici di grandi dimensioni, il singolo file di dati si trova in FlexVol 1 e il file di registro corrispondente si trova in FlexVol 2.
-
Per un consolidamento migliore, i database non critici di piccole e medie dimensioni sono raggruppati in modo che tutti i file di dati si trovino in FlexVol 1 e i relativi file di registro si trovino in FlexVol 2. Tuttavia, questo raggruppamento comporta una perdita della granularità a livello di applicazione.
-
-
Un'altra variante è quella di avere tutti i file all'interno dello stesso FlexVol 3, con i file di dati in LUN1 e i relativi file di log in LUN 2.
-
-
Se il tuo ambiente è virtualizzato, tutte le macchine virtuali per diverse applicazioni aziendali dovrebbero essere condivise in un datastore. Generalmente, le macchine virtuali e i file binari delle applicazioni vengono replicati in modo asincrono utilizzando SnapMirror.