

Upgrade manuale e senza interruzioni della ONTAP di una configurazione MetroCluster a quattro o otto nodi tramite la CLI
 Suggerisci modifiche
Suggerisci modifiche
L'aggiornamento manuale di una configurazione MetroCluster a quattro o otto nodi comporta la preparazione per l'aggiornamento, l'aggiornamento delle coppie di DR in ciascuno di uno o due gruppi DR contemporaneamente e l'esecuzione di task post-aggiornamento.
-
Questa attività si applica alle seguenti configurazioni:
-
Configurazioni MetroCluster FC o IP a quattro nodi con ONTAP 9.2 o versione precedente
-
Configurazioni MetroCluster FC a otto nodi, indipendentemente dalla versione di ONTAP
-
-
Se si dispone di una configurazione MetroCluster a due nodi, non utilizzare questa procedura.
-
Le seguenti operazioni si riferiscono alle versioni precedenti e nuove di ONTAP.
-
Durante l'aggiornamento, la versione precedente è una versione precedente di ONTAP, con un numero di versione inferiore rispetto alla nuova versione di ONTAP.
-
Quando si esegue il downgrade, la versione precedente è una versione successiva di ONTAP, con un numero di versione superiore a quello della nuova versione di ONTAP.
-
-
Questa attività utilizza il seguente flusso di lavoro di alto livello:
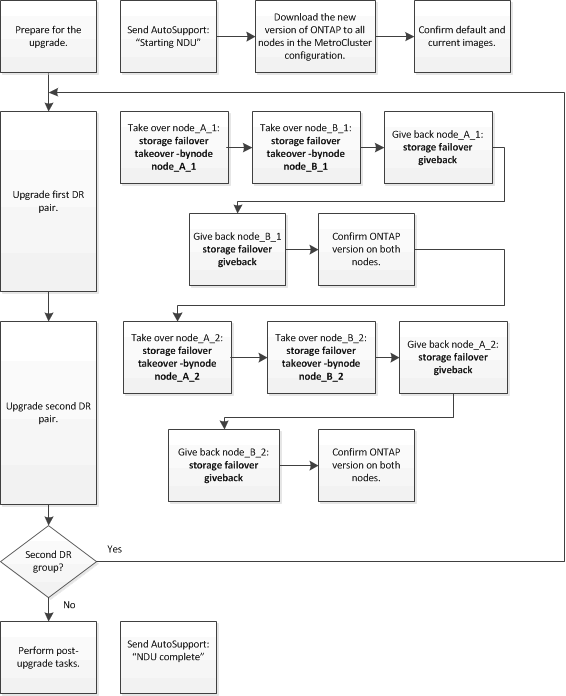
Differenze durante l'aggiornamento del software ONTAP su una configurazione MetroCluster a otto o quattro nodi
Il processo di aggiornamento del software MetroCluster varia a seconda che vi siano otto o quattro nodi nella configurazione MetroCluster.
Una configurazione MetroCluster è costituita da uno o due gruppi DR. Ciascun gruppo di DR è costituito da due coppie ha, una coppia ha per ogni cluster MetroCluster. Un MetroCluster a otto nodi include due gruppi di DR:
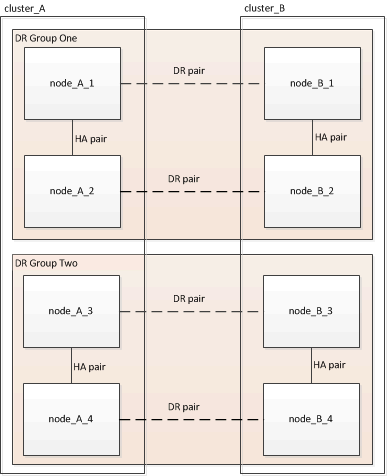
Si aggiorna un gruppo DR alla volta.
-
Aggiornamento DR Gruppo 1:
-
Aggiornare node_A_1 e node_B_1.
-
Aggiornare node_A_2 e node_B_2.
-
-
Aggiornamento DR Gruppo 1:
-
Aggiornare node_A_1 e node_B_1.
-
Aggiornare node_A_2 e node_B_2.
-
-
Aggiornamento del gruppo DR 2:
-
Aggiornare node_A_3 e node_B_3.
-
Aggiornare node_A_4 e node_B_4.
-
Preparazione dell'aggiornamento di un gruppo DR MetroCluster
Prima di aggiornare il software ONTAP sui nodi, è necessario identificare le relazioni di DR tra i nodi, inviare un messaggio AutoSupport che si sta avviando un aggiornamento e confermare la versione di ONTAP in esecuzione su ogni nodo.
Devi avere "scaricato" e. "installato" le immagini del software.
Questa attività deve essere ripetuta su ciascun gruppo di DR. Se la configurazione MetroCluster è composta da otto nodi, sono presenti due gruppi di DR. Pertanto, questa attività deve essere ripetuta su ciascun gruppo di DR.
Gli esempi forniti in questa attività utilizzano i nomi mostrati nell'illustrazione seguente per identificare i cluster e i nodi:
-
Identificare le coppie di DR nella configurazione:
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
Impostare il livello di privilegio da admin a Advanced, immettendo y quando viene richiesto di continuare:
set -privilege advancedIl prompt avanzato (
*>). -
Confermare la versione ONTAP su cluster_A:
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confermare la versione sul cluster_B:
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Attivare una notifica AutoSupport:
autosupport invoke -node * -type all -message "Starting_NDU"Questa notifica AutoSupport include un record dello stato del sistema prima dell'aggiornamento. Salva informazioni utili sulla risoluzione dei problemi in caso di problemi con il processo di aggiornamento.
Se il cluster non è configurato per l'invio di messaggi AutoSupport, una copia della notifica viene salvata localmente.
-
Per ciascun nodo del primo set, impostare l'immagine software ONTAP di destinazione come immagine predefinita:
system image modify {-node nodename -iscurrent false} -isdefault trueQuesto comando utilizza una query estesa per modificare l'immagine software di destinazione, installata come immagine alternativa, come immagine predefinita per il nodo.
-
Verificare che l'immagine software ONTAP di destinazione sia impostata come immagine predefinita su cluster_A:
system image showNell'esempio seguente, image2 è la nuova versione di ONTAP ed è impostata come immagine predefinita su ciascuno dei nodi del primo set:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
Verificare che l'immagine software ONTAP di destinazione sia impostata come immagine predefinita su cluster_B:
system image showL'esempio seguente mostra che la versione di destinazione è impostata come immagine predefinita su ciascuno dei nodi del primo set:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
Determinare se i nodi da aggiornare attualmente servono client due volte per ciascun nodo:
system node run -node target-node -command uptimeIl comando uptime visualizza il numero totale di operazioni eseguite dal nodo per client NFS, CIFS, FC e iSCSI dall'ultimo avvio del nodo. Per ciascun protocollo, è necessario eseguire il comando due volte per determinare se i conteggi delle operazioni sono in aumento. Se sono in aumento, il nodo sta attualmente servendo i client per quel protocollo. Se non sono in aumento, il nodo non sta attualmente servendo client per quel protocollo.

È necessario prendere nota di ciascun protocollo che ha un aumento delle operazioni client in modo che, dopo l'aggiornamento del nodo, sia possibile verificare che il traffico client sia ripreso. Questo esempio mostra un nodo con operazioni NFS, CIFS, FC e iSCSI. Tuttavia, il nodo attualmente serve solo client NFS e iSCSI.
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
Aggiornamento della prima coppia di DR in un gruppo di DR MetroCluster
È necessario eseguire un takeover e un giveback dei nodi nell'ordine corretto per fare in modo che la nuova versione di ONTAP sia la versione corrente del nodo.
Tutti i nodi devono eseguire la vecchia versione di ONTAP.
In questa attività, Node_A_1 e Node_B_1 vengono aggiornati.
Se il software ONTAP è stato aggiornato sul primo gruppo DR e ora si sta aggiornando il secondo gruppo DR in una configurazione MetroCluster A otto nodi, in questa attività si aggiornerà Node_A_3 e Node_B_3.
-
Eseguire la migrazione di tutti i file LIF dei dati lontano dal nodo:
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
Se il software MetroCluster Tiebreaker è abilitato, disattivalo.
-
Per ciascun nodo della coppia ha, disattivare il giveback automatico:
storage failover modify -node target-node -auto-giveback falseQuesto comando deve essere ripetuto per ogni nodo della coppia ha.
-
Verificare che il giveback automatico sia disattivato:
storage failover show -fields auto-givebackQuesto esempio mostra che il giveback automatico è stato disattivato su entrambi i nodi:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
Assicurarsi che l'i/o non superi il ~50% per ogni controller e che l'utilizzo della CPU non superi il ~50% per controller.
-
Avviare un Takeover del nodo di destinazione su cluster_A:
Non specificare il parametro -option immediate, perché è necessario un normale Takeover per i nodi che vengono presi in consegna per avviare la nuova immagine software.
-
Assumere il controllo del partner DR su cluster_A (Node_A_1):
storage failover takeover -ofnode node_A_1Il nodo si avvia allo stato "Waiting for giveback" (in attesa di giveback).
Se AutoSupport è attivato, viene inviato un messaggio AutoSupport che indica che i nodi sono fuori dal quorum del cluster. È possibile ignorare questa notifica e procedere con l'aggiornamento. -
Verificare che l'acquisizione sia riuscita:
storage failover showL'esempio seguente mostra che il rilevamento è riuscito. Node_A_1 si trova nello stato "Waiting for giveback" e Node_A_2 si trova nello stato "in Takeover".
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
Assumere il controllo del partner DR su cluster_B (Node_B_1):
Non specificare il parametro -option immediate, perché è necessario un normale Takeover per i nodi che vengono presi in consegna per avviare la nuova immagine software.
-
Prendere il controllo del nodo_B_1:
storage failover takeover -ofnode node_B_1Il nodo si avvia allo stato "Waiting for giveback" (in attesa di giveback).
Se AutoSupport è attivato, viene inviato un messaggio AutoSupport che indica che i nodi sono fuori dal quorum del cluster. È possibile ignorare questa notifica e procedere con l'aggiornamento. -
Verificare che l'acquisizione sia riuscita:
storage failover showL'esempio seguente mostra che il rilevamento è riuscito. Node_B_1 è nello stato "Waiting for giveback" e Node_B_2 è nello stato "in Takeover".
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
Attendere almeno otto minuti per verificare le seguenti condizioni:
-
Il multipathing client (se implementato) è stabilizzato.
-
I client vengono ripristinati dalla pausa in i/o che si verifica durante il takeover.
Il tempo di ripristino è specifico del client e potrebbe richiedere più di otto minuti a seconda delle caratteristiche delle applicazioni client.
-
-
Restituire gli aggregati ai nodi di destinazione:
Dopo l'aggiornamento delle configurazioni MetroCluster IP a ONTAP 9.5 o versioni successive, gli aggregati si trovano in uno stato degradato per un breve periodo prima di risincronizzare e tornare a uno stato mirrorato.
-
Restituire gli aggregati al partner DR su cluster_A:
storage failover giveback -ofnode node_A_1 -
Restituire gli aggregati al partner DR su cluster_B:
storage failover giveback -ofnode node_B_1L'operazione di giveback restituisce prima l'aggregato root al nodo, quindi, al termine dell'avvio del nodo, restituisce gli aggregati non root.
-
-
Verificare che tutti gli aggregati siano stati restituiti eseguendo il seguente comando su entrambi i cluster:
storage failover show-givebackSe il campo Stato giveback indica che non ci sono aggregati da restituire, tutti gli aggregati sono stati restituiti. Se il giveback viene veto, il comando visualizza l'avanzamento del giveback e il sottosistema che ha veto il giveback.
-
Se non sono stati restituiti aggregati, procedere come segue:
-
Esaminare la soluzione alternativa al veto per determinare se si desidera risolvere la condizione “veto” o ignorare il veto.
-
Se necessario, risolvere la condizione “veto” descritta nel messaggio di errore, assicurandosi che tutte le operazioni identificate vengano terminate correttamente.
-
Immettere nuovamente il comando giveback per il failover dello storage.
Se si decide di eseguire l'override della condizione “veto”, impostare il parametro -override-vetoes su true.
-
-
Attendere almeno otto minuti per verificare le seguenti condizioni:
-
Il multipathing client (se implementato) è stabilizzato.
-
I client vengono ripristinati dalla pausa in i/o che si verifica durante il giveback.
Il tempo di ripristino è specifico del client e potrebbe richiedere più di otto minuti a seconda delle caratteristiche delle applicazioni client.
-
-
Impostare il livello di privilegio da admin a Advanced, immettendo y quando viene richiesto di continuare:
set -privilege advancedIl prompt avanzato (
*>). -
Confermare la versione sul cluster_A:
system image showL'esempio seguente mostra che l'immagine di sistema2 (target ONTAP image) è la versione predefinita e corrente sul nodo_A_1:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confermare la versione sul cluster_B:
system image showL'esempio seguente mostra che l'immagine di sistema2 (immagine ONTAP di destinazione) è la versione predefinita e corrente sul nodo_B_1:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
Aggiornamento della seconda coppia di DR in un gruppo di DR MetroCluster
È necessario eseguire un takeover e un giveback del nodo nell'ordine corretto per fare in modo che la nuova versione di ONTAP sia la versione corrente del nodo.
La prima coppia DR deve essere stata aggiornata (Node_A_1 e Node_B_1).
In questa attività, Node_A_2 e Node_B_2 vengono aggiornati.
Se il software ONTAP è stato aggiornato sul primo gruppo DR e ora si sta aggiornando il secondo gruppo DR in una configurazione MetroCluster A otto nodi, in questa attività si stanno aggiornando node_A_4 e node_B_4.
-
Eseguire la migrazione di tutti i file LIF dei dati lontano dal nodo:
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
Avviare un Takeover del nodo di destinazione su cluster_A:
Non specificare il parametro -option immediate, perché è necessario un normale Takeover per i nodi che vengono presi in consegna per avviare la nuova immagine software.
-
Assumere il controllo del partner DR su cluster_A:
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
Il allow-version-mismatchL'opzione non è richiesta per gli aggiornamenti da ONTAP 9.0 a ONTAP 9.1 o per gli aggiornamenti delle patch.Il nodo si avvia allo stato "Waiting for giveback" (in attesa di giveback).
Se AutoSupport è attivato, viene inviato un messaggio AutoSupport che indica che i nodi sono fuori dal quorum del cluster. È possibile ignorare questa notifica e procedere con l'aggiornamento.
-
Verificare che l'acquisizione sia riuscita:
storage failover showL'esempio seguente mostra che il rilevamento è riuscito. Node_A_2 è nello stato "Waiting for giveback" e Node_A_1 è nello stato "in Takeover".
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Avviare un Takeover del nodo di destinazione su cluster_B:
Non specificare il parametro -option immediate, perché è necessario un normale Takeover per i nodi che vengono presi in consegna per avviare la nuova immagine software.
-
Assumere il controllo del partner DR su cluster_B (Node_B_2):
Se si sta eseguendo l'aggiornamento da… Immettere questo comando… ONTAP 9.2 o ONTAP 9.1
storage failover takeover -ofnode node_B_2ONTAP 9.0 o Data ONTAP 8.3.x
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
Il allow-version-mismatchL'opzione non è richiesta per gli aggiornamenti da ONTAP 9.0 a ONTAP 9.1 o per gli aggiornamenti delle patch.Il nodo si avvia allo stato "Waiting for giveback" (in attesa di giveback).
Se AutoSupport è attivato, viene inviato un messaggio AutoSupport che indica che i nodi non sono al di fuori del quorum del cluster. È possibile ignorare questa notifica e procedere con l'aggiornamento. -
Verificare che l'acquisizione sia riuscita:
storage failover showL'esempio seguente mostra che il rilevamento è riuscito. Node_B_2 è nello stato "Waiting for giveback" e Node_B_1 è nello stato "in Takeover".
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Attendere almeno otto minuti per verificare le seguenti condizioni:
-
Il multipathing client (se implementato) è stabilizzato.
-
I client vengono ripristinati dalla pausa in i/o che si verifica durante il takeover.
Il tempo di ripristino è specifico del client e potrebbe richiedere più di otto minuti a seconda delle caratteristiche delle applicazioni client.
-
-
Restituire gli aggregati ai nodi di destinazione:
Dopo l'aggiornamento delle configurazioni MetroCluster IP a ONTAP 9.5, gli aggregati si trovano in uno stato degradato per un breve periodo prima della risincronizzazione e del ritorno a uno stato mirrorato.
-
Restituire gli aggregati al partner DR su cluster_A:
storage failover giveback -ofnode node_A_2 -
Restituire gli aggregati al partner DR su cluster_B:
storage failover giveback -ofnode node_B_2L'operazione di giveback restituisce prima l'aggregato root al nodo, quindi, al termine dell'avvio del nodo, restituisce gli aggregati non root.
-
-
Verificare che tutti gli aggregati siano stati restituiti eseguendo il seguente comando su entrambi i cluster:
storage failover show-givebackSe il campo Stato giveback indica che non ci sono aggregati da restituire, tutti gli aggregati sono stati restituiti. Se il giveback viene veto, il comando visualizza l'avanzamento del giveback e il sottosistema che ha veto il giveback.
-
Se non sono stati restituiti aggregati, procedere come segue:
-
Esaminare la soluzione alternativa al veto per determinare se si desidera risolvere la condizione “veto” o ignorare il veto.
-
Se necessario, risolvere la condizione “veto” descritta nel messaggio di errore, assicurandosi che tutte le operazioni identificate vengano terminate correttamente.
-
Immettere nuovamente il comando giveback per il failover dello storage.
Se si decide di eseguire l'override della condizione “veto”, impostare il parametro -override-vetoes su true.
-
-
Attendere almeno otto minuti per verificare le seguenti condizioni:
-
Il multipathing client (se implementato) è stabilizzato.
-
I client vengono ripristinati dalla pausa in i/o che si verifica durante il giveback.
Il tempo di ripristino è specifico del client e potrebbe richiedere più di otto minuti a seconda delle caratteristiche delle applicazioni client.
-
-
Impostare il livello di privilegio da admin a Advanced, immettendo y quando viene richiesto di continuare:
set -privilege advancedIl prompt avanzato (
*>). -
Confermare la versione sul cluster_A:
system image showL'esempio seguente mostra che l'immagine di sistema2 (immagine ONTAP di destinazione) è la versione predefinita e corrente sul nodo_A_2:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confermare la versione sul cluster_B:
system image showL'esempio seguente mostra che l'immagine di sistema2 (immagine ONTAP di destinazione) è la versione predefinita e corrente sul nodo_B_2:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Per ciascun nodo della coppia ha, attivare il giveback automatico:
storage failover modify -node target-node -auto-giveback trueQuesto comando deve essere ripetuto per ogni nodo della coppia ha.
-
Verificare che il giveback automatico sia attivato:
storage failover show -fields auto-givebackQuesto esempio mostra che il giveback automatico è stato attivato su entrambi i nodi:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.