

テクノロジの概要
 変更を提案
変更を提案
このセクションでは、 NetAppを使用した OpenSource MLOps のテクノロジの概要に焦点を当てます。
人工知能
AI は、コンピューターが人間の心の認知機能を模倣するようにトレーニングするコンピューター サイエンスの分野です。 AI 開発者は、コンピューターが人間と同様、あるいは人間よりも優れた方法で学習し、問題を解決できるようにトレーニングします。ディープラーニングと機械学習は AI のサブフィールドです。組織は、重要なビジネスニーズをサポートするために AI、ML、DL を導入するケースが増えています。次にいくつかの例を示します。
-
膨大なデータを分析し、これまで知られていなかったビジネスインサイトを発見する
-
自然言語処理を使用して顧客と直接対話する
-
さまざまなビジネスプロセスと機能の自動化
最新の AI トレーニングおよび推論ワークロードには、超並列コンピューティング機能が必要です。そのため、GPU の並列処理能力は汎用 CPU よりもはるかに優れているため、AI 演算の実行に GPU がますます使用されるようになっています。
コンテナ
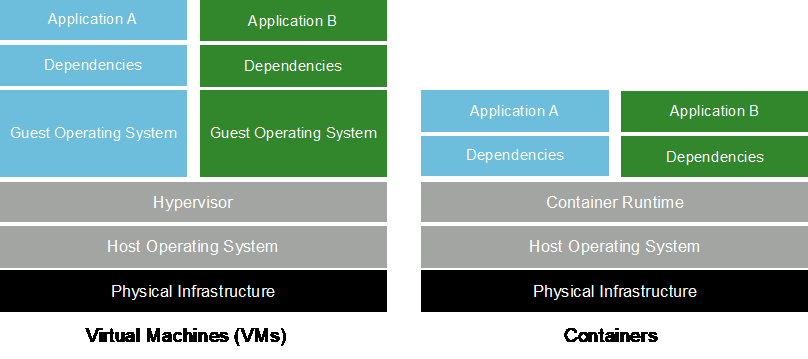
コンテナは、共有ホスト オペレーティング システム カーネル上で実行される分離されたユーザー空間インスタンスです。コンテナの導入が急速に増加しています。コンテナーは、仮想マシン (VM) が提供するのと同じアプリケーション サンドボックスの利点の多くを提供します。ただし、VM が依存するハイパーバイザーとゲスト オペレーティング システム レイヤーが削除されているため、コンテナーははるかに軽量です。次の図は、仮想マシンとコンテナを視覚的に表したものです。
コンテナーを使用すると、アプリケーションの依存関係や実行時間などをアプリケーションに直接効率的にパッケージ化することもできます。最も一般的に使用されるコンテナ パッケージ形式は Docker コンテナです。 Docker コンテナ形式でコンテナ化されたアプリケーションは、Docker コンテナを実行できる任意のマシンで実行できます。すべての依存関係はコンテナー自体にパッケージ化されるため、アプリケーションの依存関係がマシン上に存在しない場合でも、これは当てはまります。詳細については、 "Dockerウェブサイト" 。
Kubernetes
Kubernetes は、もともと Google によって設計され、現在は Cloud Native Computing Foundation (CNCF) によって管理されているオープンソースの分散型コンテナ オーケストレーション プラットフォームです。 Kubernetes を使用すると、コンテナ化されたアプリケーションの展開、管理、スケーリング機能を自動化できます。近年、Kubernetes は主要なコンテナ オーケストレーション プラットフォームとして登場しました。詳細については、 "Kubernetesウェブサイト" 。
NetAppTrident
"Trident"ONTAP (AFF、 FAS、Select、Cloud、 Amazon FSx ONTAP)、 Azure NetApp Filesサービス、 Google Cloud NetApp Volumesなど、パブリック クラウドまたはオンプレミスのすべての一般的なNetAppストレージ プラットフォームにわたるストレージ リソースの使用と管理を可能にします。 Trident は、Kubernetes とネイティブに統合される、Container Storage Interface (CSI) 準拠の動的ストレージ オーケストレーターです。
NetApp DataOps ツールキット
その"NetApp DataOps ツールキット"は、高性能なスケールアウトNetAppストレージを基盤とする開発/トレーニング ワークスペースと推論サーバーの管理を簡素化する Python ベースのツールです。主な機能は次のとおりです。
-
高性能のスケールアウトNetAppストレージを活用した新しい大容量ワークスペースを迅速にプロビジョニングします。
-
実験や迅速な反復を可能にするために、大容量のワークスペースをほぼ瞬時に複製します。
-
バックアップやトレーサビリティ/ベースライン作成のために、大容量のワークスペースのスナップショットをほぼ瞬時に保存します。
-
大容量、高パフォーマンスのデータ ボリュームをほぼ瞬時にプロビジョニング、クローン作成、スナップショット作成します。
Apacheエアフロー
Apache Airflow は、複雑なエンタープライズ ワークフローのプログラムによる作成、スケジュール設定、監視を可能にするオープン ソースのワークフロー管理プラットフォームです。これは、ETL およびデータ パイプライン ワークフローを自動化するためによく使用されますが、これらのタイプのワークフローに限定されません。 Airflow プロジェクトは Airbnb によって開始されましたが、その後業界で非常に人気となり、現在は Apache Software Foundation の管轄下にあります。 Airflow は Python で記述され、Airflow ワークフローは Python スクリプトを介して作成され、Airflow は「コードとしての構成」の原則に基づいて設計されています。現在、多くのエンタープライズ Airflow ユーザーは Kubernetes 上で Airflow を実行しています。
有向非巡回グラフ(DAG)
Airflow では、ワークフローは有向非巡回グラフ (DAG) と呼ばれます。 DAG は、DAG 定義に応じて、順番に、並列に、またはその 2 つの組み合わせで実行されるタスクで構成されます。 Airflow スケジューラは、DAG 定義で指定されたタスク レベルの依存関係に従って、ワーカーの配列で個々のタスクを実行します。 DAG は Python スクリプトによって定義および作成されます。
Jupyterノートブック
Jupyter Notebook は、ライブ コードと説明テキストを含む wiki のようなドキュメントです。 Jupyter Notebook は、AI および ML プロジェクトを文書化、保存、共有する手段として、AI および ML コミュニティで広く使用されています。 Jupyter Notebookの詳細については、 "Jupyterのウェブサイト" 。
Jupyter ノートブック サーバー
Jupyter Notebook サーバーは、ユーザーが Jupyter Notebook を作成できるようにするオープン ソースの Web アプリケーションです。
ジュピターハブ
JupyterHub は、個々のユーザーが独自の Jupyter Notebook サーバーをプロビジョニングしてアクセスできるようにするマルチユーザー アプリケーションです。 JupyterHubの詳細については、 "JupyterHubウェブサイト" 。
MLフロー
MLflow は、人気の高いオープンソースの AI ライフサイクル管理プラットフォームです。 MLflow の主な機能には、AI/ML 実験追跡と AI/ML モデル リポジトリが含まれます。 MLflowの詳細については、 "MLflowウェブサイト" 。
キューブフロー
Kubeflow は、もともと Google によって開発された、Kubernetes 用のオープンソース AI および ML ツールキットです。 Kubeflow プロジェクトは、Kubernetes 上での AI および ML ワークフローのデプロイメントをシンプル、移植可能、かつスケーラブルなものにします。 Kubeflow は Kubernetes の複雑な部分を抽象化し、データ サイエンティストが最も得意とする分野、つまりデータ サイエンスに集中できるようにします。視覚的に表すと次の図を参照してください。 Kubeflow は、オールインワンの MLOps プラットフォームを好む組織にとって優れたオープンソース オプションです。詳細については、 "Kubeflowウェブサイト" 。
Kubeflow パイプライン
Kubeflow Pipelines は Kubeflow の重要なコンポーネントです。 Kubeflow Pipelines は、移植可能でスケーラブルな AI および ML ワークフローを定義およびデプロイするためのプラットフォームおよび標準です。詳細については、 "Kubeflowの公式ドキュメント" 。
Kubeflow ノートブック
Kubeflow は、Kubernetes 上の Jupyter Notebook サーバーのプロビジョニングとデプロイメントを簡素化します。 KubeflowのコンテキストにおけるJupyter Notebookの詳細については、 "Kubeflowの公式ドキュメント" 。
カティブ
Katib は、自動機械学習 (AutoML) のための Kubernetes ネイティブ プロジェクトです。 Katib は、ハイパーパラメータ調整、早期停止、ニューラル アーキテクチャ検索 (NAS) をサポートしています。 Katib は、機械学習 (ML) フレームワークに依存しないプロジェクトです。ユーザーが選択した任意の言語で記述されたアプリケーションのハイパーパラメータを調整でき、TensorFlow、MXNet、PyTorch、XGBoost などの多くの ML フレームワークをネイティブにサポートします。 Katib は、ベイズ最適化、パルゼン木推定量、ランダム検索、共分散行列適応進化戦略、ハイパーバンド、効率的なニューラル アーキテクチャ検索、微分可能アーキテクチャ検索など、さまざまな AutoML アルゴリズムをサポートしています。 KubeflowのコンテキストにおけるJupyter Notebookの詳細については、 "Kubeflowの公式ドキュメント" 。
NetApp ONTAP
NetAppの最新世代のストレージ管理ソフトウェアであるONTAP 9 により、企業はインフラストラクチャを最新化し、クラウド対応のデータセンターに移行できるようになります。 ONTAP は業界をリードするデータ管理機能を活用し、データの保存場所に関係なく、単一のツール セットでデータの管理と保護を可能にします。また、エッジ、コア、クラウドなど、必要な場所にデータを自由に移動することもできます。 ONTAP 9 には、データ管理を簡素化し、重要なデータを高速化および保護し、ハイブリッド クラウド アーキテクチャ全体で次世代のインフラストラクチャ機能を実現する多数の機能が含まれています。
データ管理を簡素化
データ管理は、AI アプリケーションと AI/ML データセットのトレーニングに適切なリソースが使用されるように、企業の IT 運用とデータ サイエンティストにとって非常に重要です。 NetAppテクノロジーに関する次の追加情報は、この検証の範囲外ですが、導入によっては関連する可能性があります。
ONTAPデータ管理ソフトウェアには、運用を合理化および簡素化し、総運用コストを削減するための次の機能が含まれています。
-
インライン データ圧縮と拡張重複排除。データ圧縮によりストレージ ブロック内の無駄なスペースが削減され、重複排除により実効容量が大幅に増加します。これは、ローカルに保存されたデータとクラウドに階層化されたデータに適用されます。
-
最小、最大、および適応型サービス品質 (AQoS)。きめ細かなサービス品質 (QoS) 制御により、高度に共有された環境における重要なアプリケーションのパフォーマンス レベルを維持できます。
-
NetAppFabricPool。 Amazon Web Services (AWS)、Azure、 NetApp StorageGRIDストレージ ソリューションなどのパブリックおよびプライベート クラウド ストレージ オプションへのコールド データの自動階層化を提供します。 FabricPoolの詳細については、以下を参照してください。 "TR-4598: FabricPool のベストプラクティス" 。
データの高速化と保護
ONTAP は優れたレベルのパフォーマンスとデータ保護を提供し、これらの機能を次のように拡張します。
-
パフォーマンスと低レイテンシ。 ONTAP は、可能な限り低いレイテンシで最高のスループットを提供します。
-
データ保護:ONTAP は、すべてのプラットフォームにわたる共通管理を備えた組み込みのデータ保護機能を提供します。
-
NetAppボリューム暗号化 (NVE)。 ONTAP は、オンボードと外部キー管理の両方をサポートするネイティブのボリューム レベルの暗号化を提供します。
-
マルチテナントと多要素認証。 ONTAP は、最高レベルのセキュリティでインフラストラクチャ リソースを共有できるようにします。
将来を見据えたインフラ
ONTAP は、次の機能により、要求が厳しく常に変化するビジネス ニーズへの対応に役立ちます。
-
シームレスなスケーリングと中断のない運用。 ONTAP は、既存のコントローラおよびスケールアウト クラスタへの無停止の容量追加をサポートします。顧客は、コストのかかるデータ移行や停止なしに、最新のテクノロジーにアップグレードできます。
-
クラウド接続。 ONTAP は、すべてのパブリック クラウドのソフトウェア定義ストレージとクラウド ネイティブ インスタンスのオプションを備えた、最もクラウドに接続されたストレージ管理ソフトウェアです。
-
新しいアプリケーションとの統合。 ONTAP は、既存のエンタープライズ アプリケーションをサポートするのと同じインフラストラクチャを使用して、自律走行車、スマート シティ、インダストリー 4.0 などの次世代プラットフォームとアプリケーション向けにエンタープライズ グレードのデータ サービスを提供します。
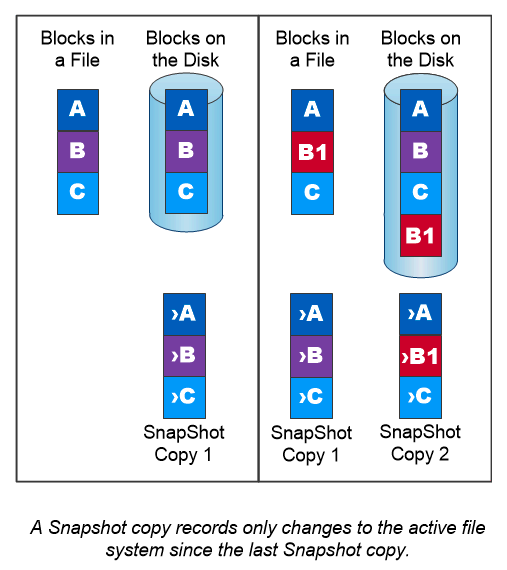
NetAppスナップショットコピー
NetAppスナップショット コピーは、ボリュームの読み取り専用の特定時点のイメージです。次の図に示すように、イメージは最後のスナップショット コピーの作成以降に作成されたファイルの変更のみを記録するため、消費するストレージ スペースは最小限で、パフォーマンスのオーバーヘッドもごくわずかです。
スナップショット コピーの効率性は、 ONTAP のコア ストレージ仮想化テクノロジである Write Anywhere File Layout (WAFL) によって実現されています。WAFLは、データベースのように、メタデータを使用してディスク上の実際のデータ ブロックを参照します。ただし、データベースとは異なり、既存のブロックは上書きされません。更新されたデータは新しいブロックに書き込まれ、メタデータが変更されます。 ONTAP は、データ ブロックをコピーするのではなく、Snapshot コピーを作成するときにメタデータを参照するため、Snapshot コピーは非常に効率的です。こうすることで、他のシステムがコピーするブロックを探すために要するシーク時間と、コピー自体の作成コストが削減されます。
スナップショット コピーを使用すると、個々のファイルまたは LUN を回復したり、ボリュームの内容全体を復元したりできます。Snapshotコピーのポインタ情報をディスク上のデータと比較することで、ダウンタイムや多大なパフォーマンス コストなしで損失オブジェクトや破損オブジェクトが再構築されます。
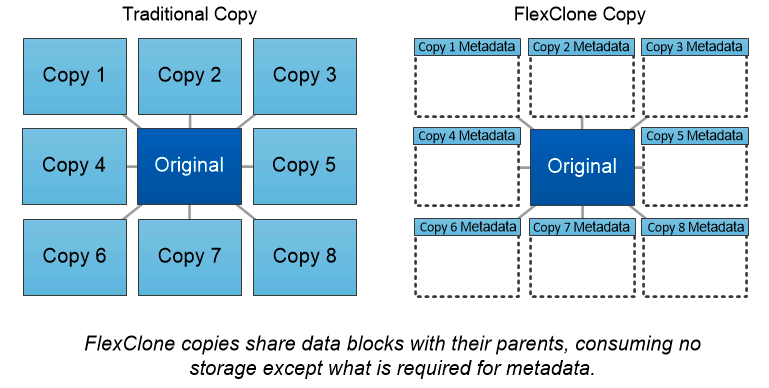
NetApp FlexCloneテクノロジ
NetApp FlexCloneテクノロジーは、スナップショット メタデータを参照して、ボリュームの書き込み可能なポイントインタイム コピーを作成します。コピーは親とデータ ブロックを共有し、次の図に示すように、変更がコピーに書き込まれるまで、メタデータに必要なストレージ以外は消費しません。従来の手法でコピーを作成すると数分から数時間かかりますが、FlexCloneソフトウェアを使用すれば大規模なデータセットのコピーもほぼ瞬時に作成できます。そのため、同一のデータセットの複数のコピー (開発ワークスペースなど) やデータセットの一時的なコピー (本番データセットに対するアプリケーションのテストなど) が必要な状況に最適です。
NetApp SnapMirrorデータレプリケーションテクノロジー
NetApp SnapMirrorソフトウェアは、データ ファブリック全体にわたるコスト効率に優れ、使いやすい統合レプリケーション ソリューションです。 LAN または WAN 経由で高速にデータを複製します。仮想環境と従来の環境の両方で、ビジネスに不可欠なアプリケーションを含むあらゆる種類のアプリケーションに高いデータ可用性と高速なデータ複製を提供します。データを 1 つ以上のNetAppストレージ システムに複製し、セカンダリ データを継続的に更新すると、データは最新の状態に保たれ、必要なときにいつでも利用できるようになります。外部のレプリケーション サーバーは必要ありません。 SnapMirrorテクノロジーを活用したアーキテクチャの例については、次の図を参照してください。
SnapMirrorソフトウェアは、変更されたブロックのみをネットワーク経由で送信することで、 NetApp ONTAPストレージの効率を活用します。 SnapMirrorソフトウェアは、組み込みのネットワーク圧縮機能を使用して、データ転送を高速化し、ネットワーク帯域幅の使用率を最大 70% 削減します。 SnapMirrorテクノロジーを使用すると、1 つのシン レプリケーション データ ストリームを活用して、アクティブ ミラーと以前のポイントインタイム コピーの両方を保持する単一のリポジトリを作成し、ネットワーク トラフィックを最大 50% 削減できます。
NetApp BlueXPコピーと同期
"BlueXPコピーと同期"高速かつ安全なデータ同期を実現するNetAppサービスです。オンプレミスの NFS または SMB ファイル共有、 NetApp StorageGRID、 NetApp ONTAP S3、 Google Cloud NetApp Volumes、 Azure NetApp Files、AWS S3、AWS EFS、Azure Blob、Google Cloud Storage、IBM Cloud Object Storage の間でファイルを転送する必要がある場合でも、 BlueXP Copy and Sync を使用すると、必要な場所にファイルを迅速かつ安全に移動します。
データが転送されると、ソースとターゲットの両方で完全に使用できるようになります。 BlueXP Copy and Sync は、更新がトリガーされたときにオンデマンドでデータを同期したり、事前定義されたスケジュールに基づいて継続的にデータを同期したりできます。いずれにしても、 BlueXP Copy and Sync はデルタのみを移動するため、データ複製にかかる時間とコストは最小限に抑えられます。
BlueXP Copy and Sync は、セットアップと使用が非常に簡単な SaaS (Software as a Service) ツールです。 BlueXP Copy and Sync によってトリガーされるデータ転送は、データ ブローカーによって実行されます。 BlueXPコピーおよび同期データブローカーは、AWS、Azure、Google Cloud Platform、またはオンプレミスにデプロイできます。
NetApp XCP
"NetApp XCP"は、any-to- NetAppおよびNetApp-to- NetAppのデータ移行とファイルシステム分析のためのクライアントベースのソフトウェアです。 XCP は、利用可能なすべてのシステム リソースを活用して大容量のデータセットと高パフォーマンスの移行を処理し、拡張して最大のパフォーマンスを実現するように設計されています。 XCP は、レポートを生成するオプションを使用して、ファイル システムの完全な可視性を得るのに役立ちます。
NetApp ONTAP FlexGroupボリューム
トレーニング データセットは、数十億のファイルのコレクションになる可能性があります。ファイルには、並列に読み取るために保存および処理する必要があるテキスト、オーディオ、ビデオ、およびその他の形式の非構造化データが含まれる場合があります。ストレージ システムは、多数の小さなファイルを保存し、順次およびランダム I/O でそれらのファイルを並列に読み取る必要があります。
FlexGroupボリュームは、次の図に示すように、複数の構成メンバー ボリュームで構成される単一の名前空間です。ストレージ管理者の観点から見ると、 FlexGroupボリュームはNetApp FlexVol volumeのように管理され、動作します。 FlexGroupボリューム内のファイルは個々のメンバー ボリュームに割り当てられ、ボリュームまたはノード間でストライプ化されません。これらにより、次の機能が有効になります。
-
FlexGroupボリュームは、高メタデータ ワークロードに対して、数ペタバイトの容量と予測可能な低レイテンシを提供します。
-
同じ名前空間で最大 4000 億のファイルをサポートします。
-
これらは、CPU、ノード、アグリゲート、および構成するFlexVolボリューム全体にわたる NAS ワークロードでの並列操作をサポートします。
