

運用上のベストプラクティス
 変更を提案
変更を提案
以降のセクションでは、VMware SRMとONTAPストレージの運用に関するベストプラクティスについて説明します。
データストアおよびプロトコル
-
可能であれば、必ず ONTAP ツールを使用してデータストアとボリュームをプロビジョニングしてください。ボリューム、ジャンクションパス、 LUN 、 igroup 、エクスポートポリシーが その他の設定は互換性のある方法で構成されます。
-
SRM では、 ONTAP 9 で iSCSI 、ファイバチャネル、および NFS バージョン 3 をサポートしているのは、 SRA 経由のアレイベースのレプリケーションを使用している場合です。SRM は、従来のデータストアまたは VVOL データストアでの NFS バージョン 4.1 のアレイベースのレプリケーションをサポートしていません。
-
接続を確認するために、 DR サイトの新しいテスト用データストアをデスティネーション ONTAP クラスタからマウントしてアンマウントできることを必ず確認してください。データストアの接続に使用する各プロトコルをテストします。テスト用データストアは SRM の指示に従ってすべてのデータストアの自動化を実行するため、 ONTAP ツールを使用して作成することを推奨します。
-
SAN プロトコルは各サイトで同機種にする必要があります。NFS と SAN を混在させることはできますが、 SAN プロトコルを 1 つのサイト内に混在させないでください。たとえば、サイトAではFCPを使用し、サイトBではiSCSIを使用できます。サイトAではFCPとiSCSIの両方を使用しないでください。
-
以前のガイドでは、データの局所性にLIFを作成することを推奨つまり、必ず、ボリュームを物理的に所有するノード上の LIF を使用してデータストアをマウントします。これは今でもベストプラクティスですが、最新バージョンのONTAP 9では必須ではなくなりました。可能なかぎり、クラスタを対象としたクレデンシャルを指定した場合でも、ONTAPツールではデータに対してローカルなLIF間で負荷を分散するように選択されますが、高可用性やパフォーマンスを確保するための必須要件ではありません。
-
ONTAP 9では、オートサイズが緊急時に十分な容量を提供できない場合に、スペース不足が発生したときにSnapshotを自動的に削除してアップタイムを維持するように設定できます。この機能のデフォルト設定では、SnapMirrorで作成されたSnapshotは自動的に削除されません。SnapMirror Snapshotが削除されると、NetApp SRAは影響を受けたボリュームのレプリケーションを反転および再同期できません。ONTAPでSnapMirrorスナップショットが削除されないようにするには、Snapshotの自動削除機能を「try」に設定します。
snap autodelete modify -volume -commitment try
-
ボリュームのオートサイズは、SANデータストアを含むボリュームの場合は
grow_shrink`に設定し、NFSデータストアの場合はに設定する必要があります `grow。このトピックの詳細については、を"ボリュームのサイズを自動的に拡張および縮小するように設定する"参照してください。 -
SRMは、データストアの数が少なく、保護グループがリカバリプランで最小化されている場合に最適なパフォーマンスを発揮します。したがって、RTOが重要なSRMで保護された環境では、VM密度の最適化を検討する必要があります。
-
Distributed Resource Scheduler(DRS)を使用して、保護対象のESXiクラスタとリカバリESXiクラスタの負荷を分散します。フェイルバックを計画している場合、再保護を実行すると、以前に保護されていたクラスタが新しいリカバリクラスタになります。DRSは、両方向への配置のバランスをとるのに役立ちます。
-
SRMでIPカスタマイズを使用するとRTOが増加する可能性があるため、可能な場合は使用しないでください。
アレイペアについて
アレイペアごとにアレイマネージャが作成されます。SRM ツールと ONTAP ツールでは、クラスタクレデンシャルを使用している場合でも、各アレイペアリングを SVM の範囲で実行します。これにより、管理対象に割り当てられている SVM を基に、各テナント間で DR ワークフローを分割できます。特定のクラスタに対して複数のアレイマネージャを作成し、非対称にすることができます。異なる ONTAP 9 クラスタ間でファンアウトまたはファンインを実行できます。たとえば、クラスタ 1 の SVM A と SVM B をクラスタ 2 の SVM C に、クラスタ 3 の SVM D に、またはその逆にレプリケートできます。
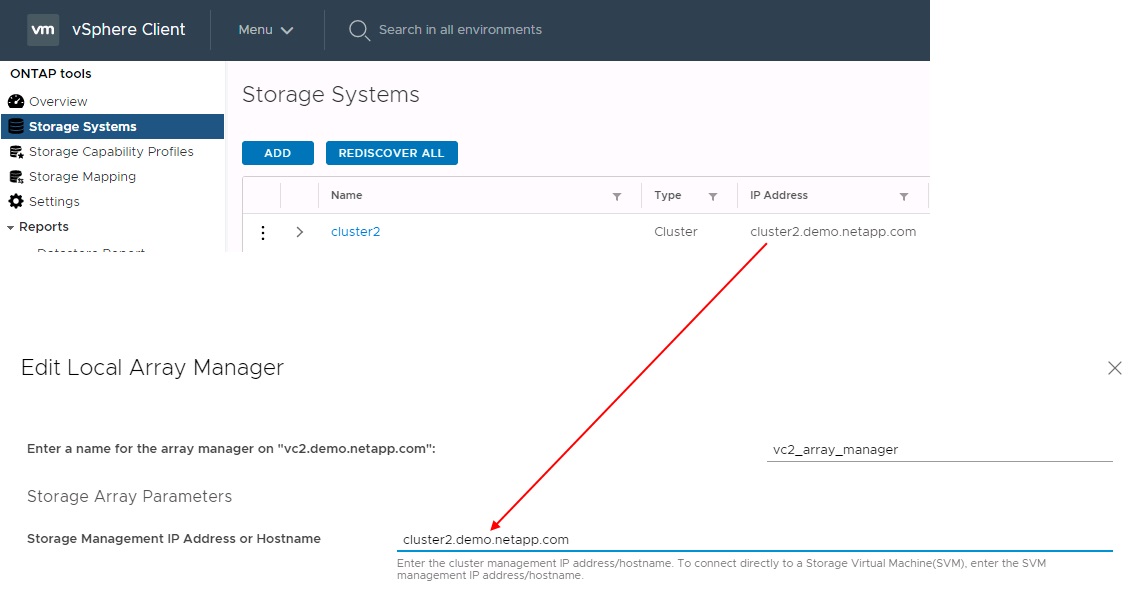
SRM でアレイペアを設定する場合は、 ONTAP ツールに追加するのと同じ方法でアレイペアを SRM に追加する必要があります。つまり、アレイペアは同じユーザ名、パスワード、および管理 LIF を使用する必要があります。これは、 SRA がアレイと正しく通信するための要件です。次のスクリーンショットは、 ONTAP ツールでのクラスタの表示方法と、アレイマネージャへのクラスタの追加方法を示しています。
複製グループについて
レプリケーショングループには、同時にリカバリされる仮想マシンの論理集合が含まれます。ONTAP の SnapMirror レプリケーションはボリュームレベルで実行されるため、ボリューム内のすべての VM が同じレプリケーショングループに属します。
レプリケーショングループについて考慮する必要がある要素と、 FlexVol ボリュームに VM を分散する方法にはいくつかの要素があります。類似するVMを同じボリュームにグループ化すると、アグリゲートレベルの重複排除機能がない古いONTAPシステムでストレージ効率を高めることができますが、グループ化するとボリュームのサイズが大きくなり、ボリュームのI/Oの同時実行数が少なくなります。最新のONTAPシステムでは、同じアグリゲート内のFlexVolボリュームにVMを分散することで、パフォーマンスとストレージ効率の最適なバランスを実現できます。その結果、アグリゲートレベルの重複排除が活用され、複数のボリューム間でI/Oの並列化が促進されます。保護グループ(以下で説明)には複数のレプリケーショングループを含めることができるため、ボリューム内の VM を 1 つにまとめてリカバリできます。このレイアウトの欠点は、SnapMirrorではアグリゲートの重複排除が考慮されていないため、ブロックがネットワーク経由で複数回送信される可能性があることです。
レプリケーショングループの最後の考慮事項の 1 つは、各グループがその性質によって論理整合グループになることです( SRM 整合グループと混同しないようにしてください)。これは、ボリューム内のすべての VM が同じ Snapshot を使用して同時に転送されるためです。したがって、相互に整合性が必要な VM がある場合は、同じ FlexVol に格納することを検討してください。
保護グループについて
保護グループでは、 VM とデータストアをグループ単位で定義し、グループをまとめて保護サイトからリカバリします。保護対象サイトとは、通常の安定状態での運用中、保護グループで構成された VM が存在する場所です。SRM には保護グループの複数のアレイマネージャが表示される場合がありますが、保護グループは複数のアレイマネージャにまたがることはできません。このため、異なる SVM 上の複数のデータストアに VM ファイルをまたがって配置することはできません。
リカバリ・プランについて
リカバリプランでは、同じプロセスでリカバリする保護グループを定義します。同じリカバリプランに複数の保護グループを設定できます。また、リカバリプランの実行オプションを増やすには、 1 つの保護グループを複数のリカバリプランに含めることもできます。
リカバリプランを使用すると、 SRM 管理者は、 VM を優先グループ 1 (最大)から 5 (最小)に割り当てて、リカバリワークフローを定義できます。デフォルトは 3 (中)です。優先度グループ内で、 VM に依存関係を設定できます。
たとえば、データベースにMicrosoft SQL Serverを使用するティア1のビジネスクリティカルなアプリケーションがあるとします。したがって、優先度グループ 1 に VM を配置することにします。優先度グループ 1 では、サービスの提供順序の計画を開始します。Microsoft Windowsドメインコントローラは、アプリケーションサーバの前にオンラインである必要があるMicrosoft SQL Serverよりも先に起動する必要があります。依存関係は特定の優先度グループ内でのみ適用されるため、これらすべてのVMを優先度グループに追加してから依存関係を設定します。
アプリケーションチームと連携してフェイルオーバーシナリオに必要な処理の順序を把握し、それに応じてリカバリ計画を作成することを強く推奨します。
テストフェイルオーバー
ベストプラクティスとして、保護対象のVMストレージの構成を変更した場合は、必ずテストフェイルオーバーを実行することを推奨します。これにより、災害が発生した場合に、Site Recovery Managerが予想されるRTOターゲット内でサービスをリストアできると信頼できます。
特に VM ストレージの再設定後にゲストアプリケーションの機能を確認することを推奨します。
テストリカバリ処理を実行すると、 VM 用の ESXi ホストにプライベートテスト用のバブルネットワークが作成されます。ただし、このネットワークは物理ネットワークアダプタに自動的には接続されないため、 ESXi ホスト間の接続は提供されません。DR テスト時に異なる ESXi ホストで実行されている VM 間の通信を可能にするために、 DR サイトの ESXi ホスト間に物理プライベートネットワークを作成します。テスト用ネットワークがプライベートであることを確認するために、テスト用のバブルネットワークを物理的に分離するか、 VLAN や VLAN タギングを使用して分離します。このネットワークは本番用ネットワークから分離する必要があります。 VM がリカバリされると、実際の本番用システムと競合する可能性のある IP アドレスを持つ本番用ネットワークに配置することはできなくなります。SRM でリカバリプランを作成する際、テスト中に VM を接続するためのプライベートネットワークとして、作成したテストネットワークを選択できます。
テストが検証されて不要になったら、クリーンアップ処理を実行します。クリーンアップを実行すると、保護されている VM が初期状態に戻り、リカバリプランが Ready 状態にリセットされます。
フェイルオーバーに関する考慮事項
サイトのフェイルオーバーに関しては、このガイドに記載されている処理の順序に加えて、その他にもいくつかの考慮事項があります。
競合する問題の 1 つに、サイト間のネットワークの違いがあります。環境によっては、プライマリサイトと DR サイトで同じネットワーク IP アドレスを使用できる場合があります。この機能は、拡張仮想 LAN ( VLAN )または拡張ネットワークセットアップと呼ばれます。それ以外の環境では、プライマリサイトと DR サイトで別々のネットワーク IP アドレス(異なる VLAN など)を使用する必要があります。
VMware では、この問題を解決する方法をいくつか提供しています。1 つは、 VMware NSX -T Data Center のようなネットワーク仮想化テクノロジーです。ネットワークスタック全体を運用環境からレイヤ 2 ~ 7 に抽象化し、より移植性の高いソリューションを実現します。の詳細を確認してください "SRMでのNSX-Tオプション"。
SRM では、リカバリ時に VM のネットワーク設定を変更することもできます。この再設定には、IPアドレス、ゲートウェイアドレス、DNSサーバ設定などの設定が含まれます。リカバリ時に個 々 のVMに適用されるさまざまなネットワーク設定は、リカバリプランのVMのプロパティ設定で指定できます。
VMware の dr-ip-customizer というツールを使用すると、リカバリプランで複数の VM のプロパティを個別に編集しなくても、 SRM で VM ごとに異なるネットワーク設定を適用できます。このユーティリティの使用方法については、を参照してください。 "VMwareのドキュメント"。
再保護
リカバリ後、リカバリサイトが新しい本番用サイトになります。リカバリ処理によって SnapMirror レプリケーションが解除されたため、新しい本番用サイトは今後の災害から保護されません。新しい本番用サイトは、リカバリ後すぐに別のサイトで保護することを推奨します。元の本番サイトが運用されている場合、 VMware 管理者は、元の本番サイトを新しいリカバリサイトとして使用して新しい本番サイトを保護できるため、保護の方向を実質的に変えることができます。再保護は、致命的でない障害でのみ使用できます。そのため、元の vCenter Server 、 ESXi サーバ、 SRM サーバ、および対応するデータベースを最終的にリカバリ可能な状態にする必要があります。使用できない場合は、新しい保護グループと新しいリカバリプランを作成する必要があります。
フェイルバック
フェイルバック処理は、基本的に以前とは異なる方向のフェイルオーバーです。ベストプラクティスとして、フェイルバックを実行する前に、元のサイトが許容可能なレベルの機能に戻っていること、つまり元のサイトにフェイルオーバーしていることを確認することを推奨します。元のサイトが侵害されたままの場合は、障害が十分に修正されるまでフェイルバックを遅らせる必要があります。
フェイルバックのもう 1 つのベストプラクティスとして、再保護の完了後、および最終フェイルバックの実行前に、常にテストフェイルオーバーを実行することがあります。これにより、元のサイトに配置されたシステムで処理が完了できるかどうかを確認できます。
元のサイトを再保護する
フェイルバック後、再保護を再度実行する前に、すべての関係者にサービスが正常に戻ったことを確認する必要があります。
フェイルバック後の再保護を実行すると、基本的に環境は最初の状態に戻り、 SnapMirror レプリケーションが本番用サイトからリカバリサイトに再度実行されます。