

VMware vSphere解決策の概要
 変更を提案
変更を提案
vCenter Server Appliance (VCSA) は、管理者が ESXi クラスターを効果的に操作できるようにする、vSphere 用の強力な集中管理システムおよび単一管理画面です。VM のプロビジョニング、vMotion 操作、高可用性 (HA)、分散リソース スケジューラ (DRS)、 VMware vSphere Kubernetes Service (VKS) などの主要な機能を容易に実現します。これは VMware クラウド環境に不可欠なコンポーネントであり、サービスの可用性を考慮して設計する必要があります。
vSphereの高可用性
VMwareのクラスタテクノロジは、ESXiサーバを仮想マシン用の共有リソースプールにグループ化し、vSphere High Availability(HA;高可用性)を提供します。vSphere HAは、仮想マシンで実行されるアプリケーションに使いやすく高可用性を提供します。クラスタでHA機能を有効にすると、いずれかのESXiホストが応答しなくなったり分離されたりした場合に、各ESXiサーバが他のホストとの通信を維持します。 HAクラスタは、そのESXiホストで実行されていた仮想マシンのリカバリを、クラスタ内の残りのホスト間でネゴシエートできます。ゲストOSに障害が発生した場合、vSphere HAは影響を受ける仮想マシンを同じ物理サーバ上で再起動できます。vSphere HAを使用すると、計画的ダウンタイムの削減、計画外ダウンタイムの防止、およびシステム停止からの迅速なリカバリが可能になります。
障害が発生したサーバーから VM を復旧する vSphere HA クラスタ。
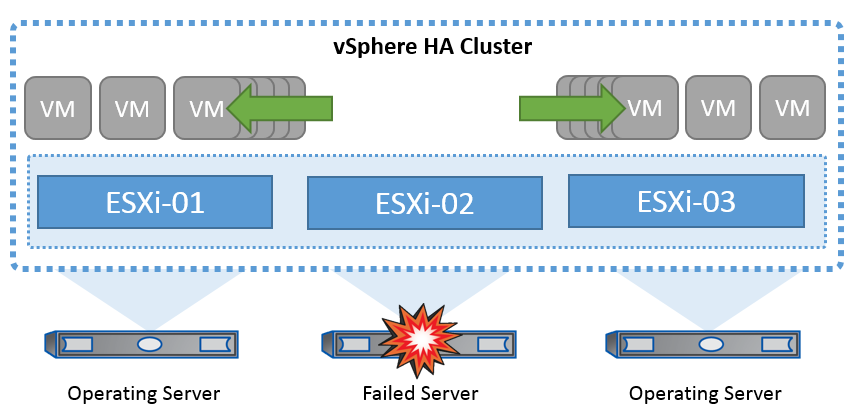
VMware vSphereはNetApp MetroClusterまたはSnapMirrorのアクティブ同期を認識しないため、vSphereクラスタ内のすべてのESXiホストが、ホストおよびVMグループのアフィニティ構成に応じてHAクラスタ処理の対象となるホストとして認識されることを理解しておくことが重要です。
ホスト障害の検出
HA クラスターが作成されるとすぐに、クラスター内のすべてのホストが選出に参加し、ホストの 1 つがマスターになります。各スレーブはマスターに対してネットワーク ハートビートを実行し、マスターはすべてのスレーブ ホストに対してネットワーク ハートビートを実行します。vSphere HA クラスタのマスター ホストは、スレーブ ホストの障害を検出する役割を担います。
検出された障害のタイプによっては、ホストで実行されている仮想マシンのフェイルオーバーが必要になる場合があります。
vSphere HAクラスタでは、次の3種類のホスト障害が検出されます。
-
障害-ホストが機能を停止しました。
-
分離-ホストがネットワークから分離されます。
-
パーティション-ホストとマスターホストとのネットワーク接続が失われます。
マスターホストは、クラスタ内のスレーブホストを監視します。この通信は、1秒ごとにネットワークハートビートを交換して行われます。マスターホストは、スレーブホストからのハートビートの受信を停止すると、ホストの稼働状況を確認してから、ホストに障害が発生したことを宣言します。マスターホストが実行する活性チェックでは、スレーブホストがいずれかのデータストアとハートビートを交換しているかどうかを確認します。また、マスターホストは、管理IPアドレスに送信されたICMP pingにホストが応答するかどうかをチェックして、単にマスターノードから隔離されているか、ネットワークから完全に隔離されているかを検出します。これは、デフォルトゲートウェイに対してpingを実行することによって行われます。隔離アドレスを手動で指定することで、隔離検証の信頼性を高めることができます。

|
NetAppでは、隔離アドレスを少なくとも2つ追加し、各アドレスをサイトローカルにすることを推奨しています。これにより、隔離検証の信頼性が向上します。 |
ホスト隔離時の対応
隔離対応は、vSphere HA クラスタ内のホストが管理ネットワーク接続を失ったが実行を継続している場合に仮想マシンでトリガーされるアクションを決定する vSphere HA の設定です。この設定には、「無効」、「VM をシャットダウンして再起動する」、「VM の電源をオフにして再起動する」の 3 つのオプションがあります。
「シャットダウン」は、最新の変更をディスクにフラッシュしたり、トランザクションをコミットしたりしない「電源オフ」よりも優れています。仮想マシンが 300 秒以内にシャットダウンしない場合は、電源がオフになります。待機時間を変更するには、詳細オプション das.isolationshutdowntimeout を使用します。
HAは隔離時の対応を開始する前に、vSphere HAマスターエージェントがVM構成ファイルが格納されたデータストアを所有しているかどうかを確認します。そうでない場合、VMを再起動するマスターがないため、ホストは隔離時の対応をトリガーしません。ホストはデータストアの状態を定期的にチェックして、マスターロールを持つvSphere HAエージェントがデータストアを要求しているかどうかを判断します。
|
|
NetAppでは、[Host Isolation Response]を[Disabled]に設定することを推奨しています。 |
ホストがvSphere HAマスターホストから分離またはパーティショニングされ、ハートビートデータストアまたはpingを介してマスターと通信できなくなると、スプリットブレイン状態が発生することがあります。マスターは、隔離されたホストの停止を宣言し、クラスタ内の他のホスト上のVMを再起動します。仮想マシンのインスタンスが2つ実行され、そのうちの1つだけが仮想ディスクの読み取りまたは書き込みを実行できるため、スプリットブレイン状態が発生します。VM Component Protection(VMCP)を設定することで、スプリットブレイン状態を回避できるようになりました。
VMコンポーネント保護(VMCP)
vSphere 6で強化されたHA関連機能の1つにVMCPがあります。VMCPは、ブロック(FC、iSCSI、FCoE)とファイルストレージ(NFS)のAll Paths Down(APD)状態とPermanent Device Loss(PDL)状態からの保護を強化します。
Permanent Device Loss(PDL)
PDL は、ストレージ デバイスが恒久的に故障した場合、または管理上削除されて復旧が期待されない場合に発生する状態です。NetAppストレージ アレイは、デバイスが永久に失われたことを宣言する SCSI センス コードを ESXi に発行します。vSphere HA の「障害条件と VM 応答」セクションでは、PDL 条件が検出された後の応答を設定できます。
|
|
NetApp、「PDL を含むデータストアの応答」を「VM の電源をオフにして再起動する」に設定することを推奨しています。この状態が検出されると、vSphere HA クラスタ内の正常なホスト上で VM が即座に再起動されます。 |
すべてのパスがダウン(APD)
APD は、ストレージ デバイスがホストにアクセスできなくなり、アレイへのパスが利用できなくなるときに発生する状態です。ESXi はこれをデバイスの一時的な問題と見なし、デバイスが再び利用可能になると予想しています。
APD状態が検出されると、タイマーが開始されます。140秒後、APD状態が正式に宣言され、デバイスはAPDタイムアウトとしてマークされます。140秒が経過すると、[Delay for VM Failover APD]で指定された分数がカウントされます。指定した時間が経過すると、影響を受ける仮想マシンが再起動されます。必要に応じて異なる方法([Disabled]、問題Events]、[Power Off and Restart VMs])で応答するようにVMCPを設定できます。
|
|
|
NetApp SnapMirror Active SyncのためのVMware DRSの実装
VMware DRSは、クラスタ内のホストリソースを集約する機能で、主に仮想インフラストラクチャ内のクラスタ内での負荷分散に使用されます。VMware DRSは、クラスタ内でロードバランシングを実行するために、主にCPUリソースとメモリリソースを計算します。vSphereはストレッチクラスタリングを認識しないため、両方のサイトのすべてのホストをロードバランシングの対象とします。
NetApp MetroCluster向けVMware DRSの実装
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. クラスタ用のDRSアフィニティルールを作成する場合は、仮想マシンのフェイルオーバー時にvSphereがそのルールを適用する方法を指定できます。
vSphere HA フェイルオーバー動作に指定できるルールには 2 つの種類があります。
-
VMの非アフィニティルールでは、フェイルオーバー処理中に指定した仮想マシンが分離されたままになります。
-
VMホストアフィニティルールは、フェイルオーバー処理中に、指定した仮想マシンを特定のホストまたは定義されたホストグループのメンバーに配置します。
VMware DRSのVMホストアフィニティルールを使用すると、サイトAとサイトBを論理的に分離して、特定のデータストアのプライマリ読み取り/書き込みコントローラとして設定されたアレイと同じサイトのホストでVMを実行できます。また、VMホストアフィニティルールを使用すると、仮想マシンはストレージに対してローカルなままになり、サイト間でネットワーク障害が発生した場合に仮想マシンの接続が確保されます。
次に、VMホストグループとアフィニティルールの例を示します。
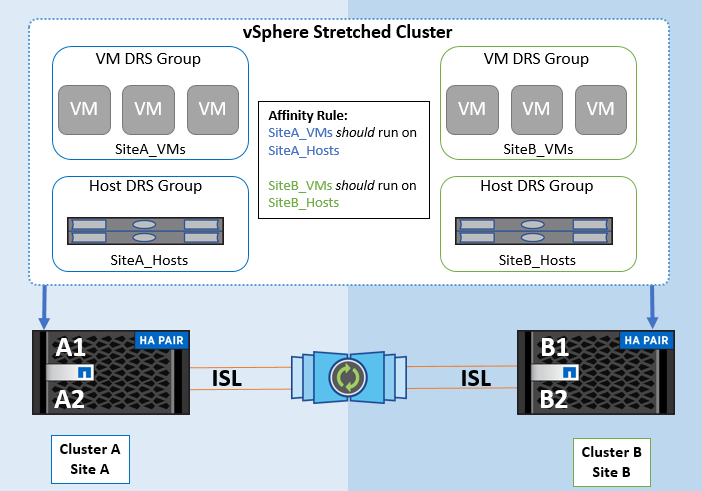
ベストプラクティス
NetAppでは、障害が発生した場合にvSphere HAによって違反されるため、「must」ルールではなく「should」ルールを実装することを推奨しています。「must」ルールを使用すると、サービスが停止する可能性があります。
サービスの可用性は常にパフォーマンスよりも優先される必要があります。データセンター全体に障害が発生するシナリオでは、「必須」ルールによって VM ホスト アフィニティ グループからホストを選択する必要があり、データセンターが使用できない場合は仮想マシンは再起動しません。
NetApp MetroClusterでのVMware Storage DRSの実装
VMware Storage DRS機能を使用すると、データストアを1つのユニットに集約し、Storage I/O Control(SIOC)のしきい値を超えた場合に仮想マシンディスクのバランスを調整できます。
Storage I/O Controlは、Storage DRS対応のDRSクラスタではデフォルトで有効になっています。Storage I/O Controlを使用すると、I/Oの輻輳時に仮想マシンに割り当てるストレージI/Oの量を管理者が制御できるため、重要度の高い仮想マシンを優先してI/Oリソースを割り当てることができます。
Storage DRSは、Storage vMotionを使用して、データストアクラスタ内の別のデータストアに仮想マシンを移行します。NetApp MetroCluster環境では、仮想マシンの移行をそのサイトのデータストア内で制御する必要があります。たとえば、サイトAのホストで実行されている仮想マシンAを移行する場合は、サイトAのSVMのデータストア内で移行するのが理想的です。そうしないと、仮想ディスクの読み取り/書き込みはサイト間リンクを介してサイトBから行われるため、仮想マシンは引き続き動作しますが、パフォーマンスは低下します。
|
|
|