

NetApp AFX アーキテクチャと統合 ONTAP の違い
 変更を提案
変更を提案
NetApp AFXは、統合型ONTAPとは大きく異なるアーキテクチャを採用しています。ストレージの提供方法、ノードとディスクの相互作用方法、および容量管理方法において。
以前は、統一されたONTAPアーキテクチャが、直接接続されたHAペアを介してファイル、オブジェクト、およびブロックデータのストレージを提供する方法の全体像を示しました。HAペアはそれぞれ独自のディスクセットを所有し、ディスクの集合体を介して物理容量を提供します。このセクションでは、統合されたONTAPとNetApp AFXアーキテクチャの主な違いについて、さらに詳しく説明します。
システムが NetApp AFX を実行しているかどうかを確認する方法
システムが NetApp AFX を実行しているかどうかを確認する主な方法は、次のコマンドを実行することです:
AFX::> node show -fields personality node personality ---------------- ----------- afx-01 AFX afx-02 AFX
もう1つの手がかりは新しいストレージ可用性ゾーンですが、これもまたNetAppオールSANアレイ(ASA)で利用可能な概念です。そのコマンドを使えば、容量を確認できます。
AFX::> storage availability-zone show
Availability Zone Name: storage_availability_zone_0
Availability Zone UUID: 545cb59f-32e9-11f1-a2f5-d039eabdd925
Total Size: 69.59TB
Physical Used: 837.1GB
Physical Used Percent: 1%
Available: 68.77TB
Metadata Used: 837.1GB
Log and Recovery Metadata: 834.6GB
Delayed Frees: 2.50GB
Physical User Data Without Snapshot Copies: 17.24MB
Logical User Data Without Snapshot Copies: 17.24MB
Efficiency Ratio Without Snapshot Copies: 1.00:1
Space Full Threshold Percent: 98%
Space Nearly Full Threshold Percent: 95%
ノードとディスクの関係
統一された ONTAP アーキテクチャでは、読み取りと書き込みは特定のディスクのサブセットに振り分けられます。つまり、24 ノードのクラスタに 24 個のディスク シェルフ(ノードごとに 1 つのシェルフ)があったとしても、各ノードが直接アクセスできるのは一度に 1 つのディスク シェルフのみであり、クラスタで利用可能な容量とパフォーマンスが制限されることになります。

さらに、NVRAMはHAペア間で直接接続されているため、ノードは物理的に隣接している必要があり、フェイルオーバーのターゲットとしてより密接に結合されています。例えば、あるノードがパートナーノードにフェイルオーバーした場合、物理的にアクセスできるディスクは、HAペアドメイン内のディスクのみとなります。
HAフェイルオーバー中の統一ONTAPクラスタ

NetApp AFXでは、ディスクがコンピュートノードに提示される方法にいくつかの大きな変化があります。
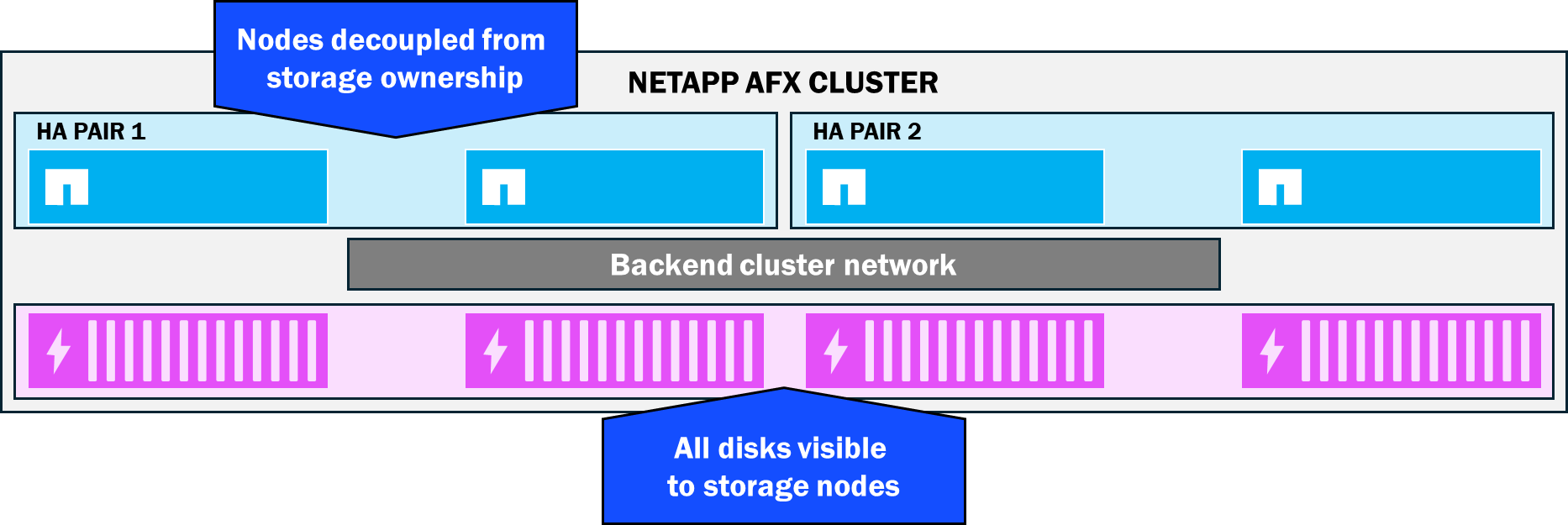
すべてのディスクはすべてのストレージノードから参照可能—ディスクの所有権なし
NetApp AFXでは、ノードとシェルフがすべて同じバックエンドスイッチに接続されているため、ONTAPはディスクの全体的な可視性ドメインをスタック全体に拡張できます。その結果、どのノードも特定のディスクを所有しません。むしろ、すべてのディスクはStorage Availability Zoneと呼ばれる単一の容量プールに参加し、容量管理の簡素化とパフォーマンスの向上(利用可能なディスクが多いほど、利用可能なパフォーマンスも向上する)を実現します。
NetApp AFXストレージアベイラビリティゾーン
物理アグリゲートは不要
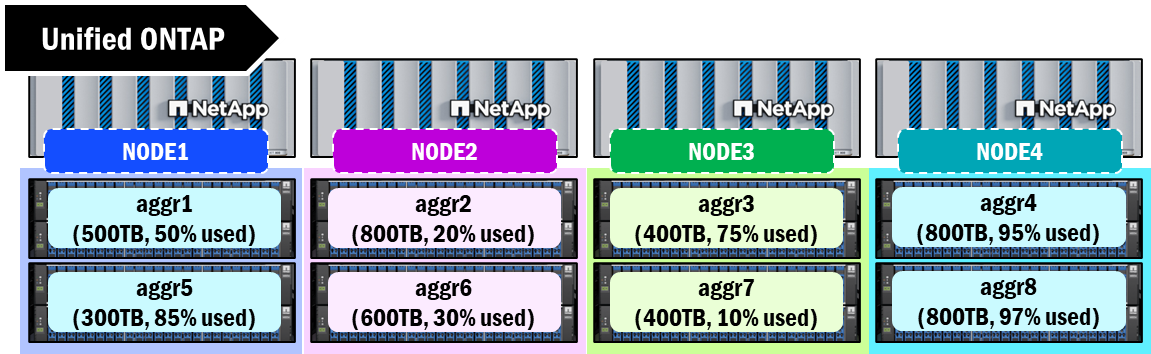
統合 ONTAP は、ディスクを RAID グループにまとめ、それらをアグリゲートと呼ばれる容量構造に結合します。このアグリゲートは、ストレージに対して物理的な容量を提示する方法であり、エンドユーザーにデータを提供するボリュームを作成するために利用可能なスペースの境界となります。各ノードには少なくとも 1 つのアグリゲートが割り当てられている必要があり、これらのアグリゲートの現在の制限は 800TB です。その制限に達すると、それ以上の書き込みのための空き容量はなくなります。
物理アグリゲートは、容量管理においていくつかの課題をもたらす可能性があります。ストレージ管理者は、クラスタノード間で容量のバランスを維持するために、ボリュームを手動で移動する必要が生じることがあります。これらの課題は、スケールアウトボリュームアーキテクチャ(FlexGroupボリュームなど)を活用する場合に、さらに大きくなる可能性があります。アグリゲートは、サイズ、ディスク数、ディスクタイプなども異なる場合があり、ノード間を移動する際にパフォーマンスの違いが生じることもあります。
統合ONTAP内のアグリゲート
NetApp AFXは、物理的なアグリゲートの概念を仮想化し、ONTAPで管理できるようにし、さらに新しいStorage Availability Zoneを介して、物理容量管理をノード単位の方法からクラスタ単位の方法へと移行します。この単一の容量プールにより、スペース管理において「見たままが得られる」というアプローチが可能になります。
NetApp AFXストレージアベイラビリティゾーン

NVRAMが直接接続からスイッチド レプリケーションに移行
ONTAP は NVRAM をステージングとして使用し、クラスタへの受信書き込みを保護します。ONTAP クラスタ内の各ノードには、バッテリ バックアップ式 NVRAM カードがあります。クライアントからボリュームに書き込みが送信されると、最初に NVRAM に格納されます。NVRAM の内容は、NVRAM がいっぱいになるか、10 秒のタイマーが期限切れになると(いずれか早い方)、ディスクにフラッシュされます。これは整合性ポイントと呼ばれます。
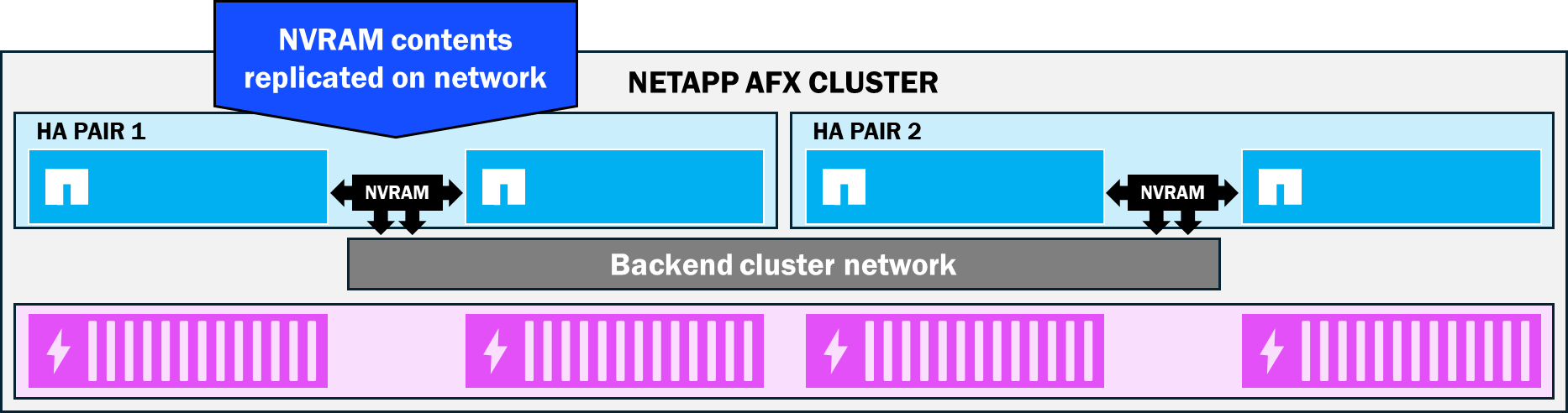
NVRAM の内容は HA ペア間で常に複製されるため、ノード障害が発生した場合でも NVRAM の内容は存続ノードに保存されてディスクにコミットされるため、データの整合性の保護に役立ちます。
統合 ONTAP クラスタでは、HA ペア間の NVRAM カードが相互に直接接続されます。NetApp AFX は、NVRAM レプリケーションをバックエンド クラスタ ネットワークに移動します。その結果、HA パートナー ノードには、ノード間の距離に関するそれほど厳密な要件は課されません。その代わりに、HA ペアはイーサネットの最大距離まで分離することができます。
NetApp AFX NVRAM レプリケーション
アベイラビリティゾーン内の任意の(およびすべての)ディスクに書き込まれたデータ
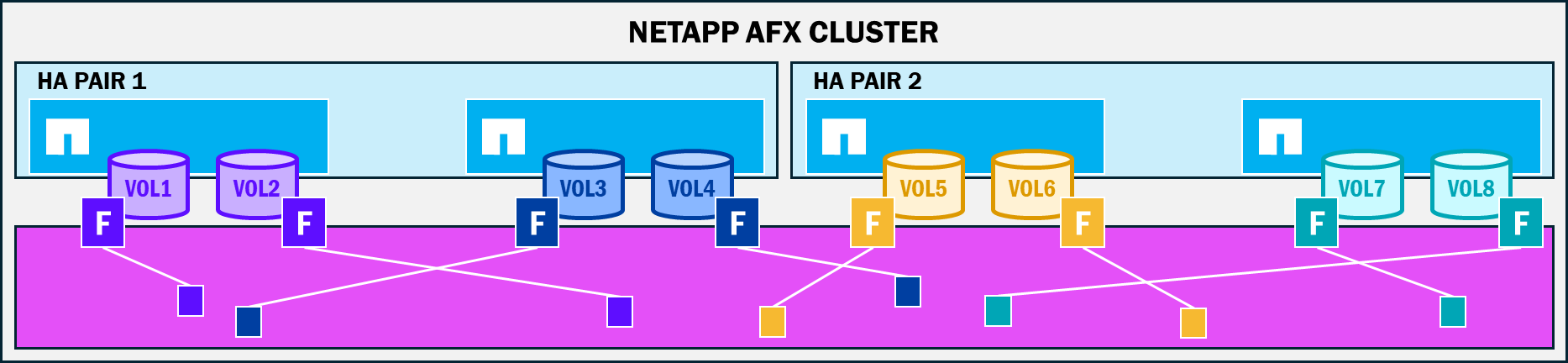
NetApp AFXはディスク所有権の概念を排除し、物理アグリゲート構造をONTAPで管理される仮想化アプローチに移行します。これにより、クラスタ用に購入した容量はすべて、クラスタに接続されているノードで利用可能になります。AFXでは、ノード:ボリュームの所有権に関係なく、すべてのノードがStorage Availability Zone内のすべてのディスクに書き込むことができます。書き込みは依然としてNVRAMを経由するパスを通るため、ノードには依然としてボリューム所有権の概念がありますが、そのデータは利用可能な容量内のどこにでも格納される可能性があります。これは、より多くのディスクが単一のワークロードに参加できることを意味し、パフォーマンスの向上につながります。
ストレージ可用性ゾーンにデータが格納される仕組み
容量ノードとコンピュート ノードの独立したスケーリング
ハードウェア リソースがNetApp AFXアーキテクチャで分離されているため、ノードに関連付けられたディスクを並行して追加する必要がなくなりました。クラスタでRAM、CPU、ネットワークスループットなどのパフォーマンス関連リソースが不足している場合は、ストレージノードのみをクラスタに追加すればよく、既存のStorage Availability Zoneを活用できます。逆に、容量が必要な場合は、シェルフを追加するだけで済みます。この柔軟性により、必要なリソースのみを購入できるため、過剰なプロビジョニングを回避できます。
NetApp AFX – 独立スケール
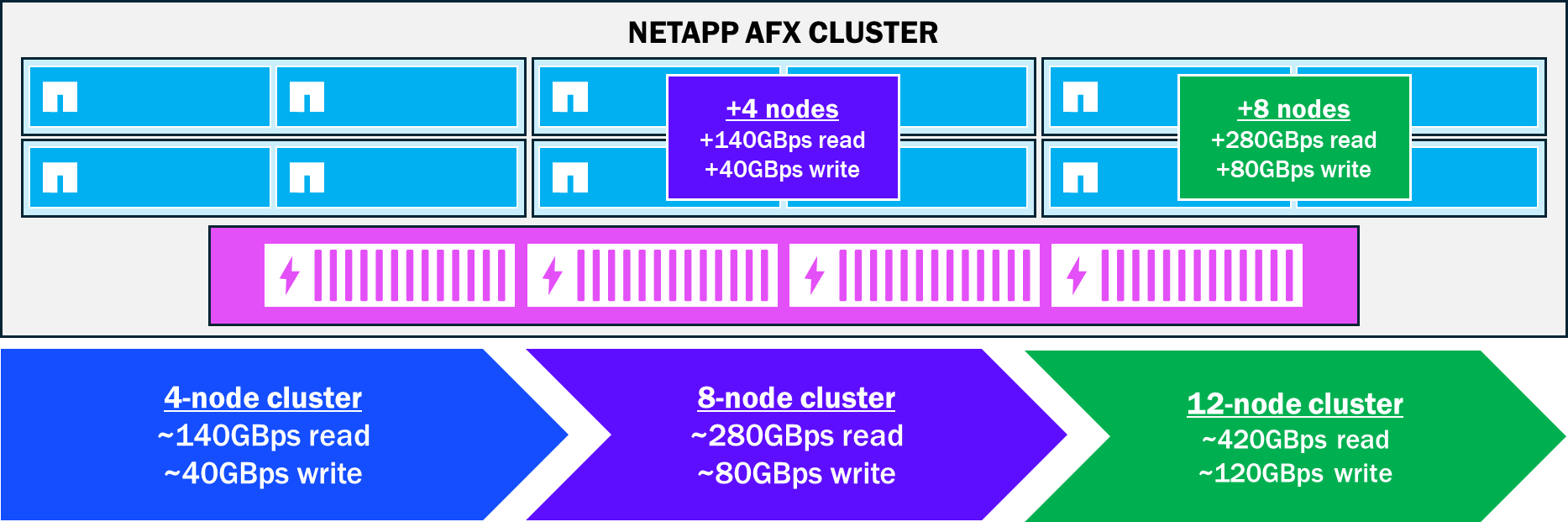
ノード性能の線形スケーリング
AFX クラスタにノードが追加されると、より多くの CPU 、 RAM 、ネットワーク リソースがワークロードに導入されます。これらのリソースが環境に組み込まれると、パフォーマンスの向上は線形になります。次の図は、ノードの追加に伴ってパフォーマンスがどのように向上するかを示しています。
NetApp AFX ノードの追加による線形パフォーマンスの向上
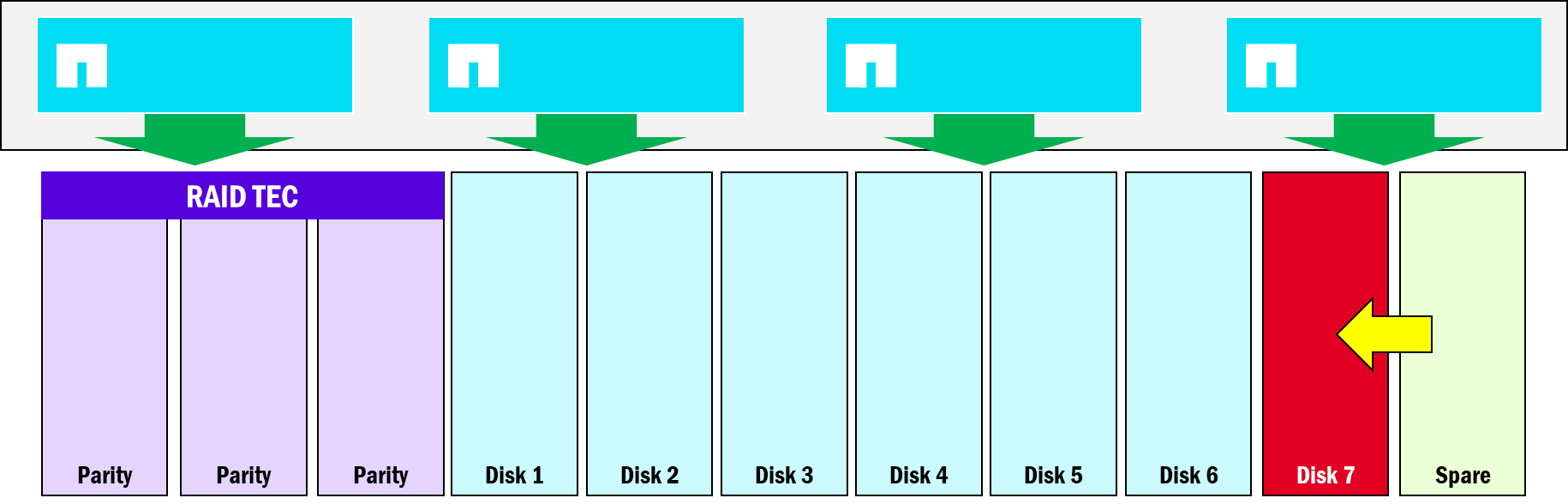
RAIDグループを大きくし、パリティドライブの数を減らす
ONTAPは、RAIDグループ(特にRAID-TEC)を介してディスクのデータ保護とパフォーマンスを両立させます。RAID-TECは、ディスク障害発生時に三重パリティ保護を提供します。RAID-TECは、RAIDグループ内で最大3台のドライブが同時に故障しても耐えることができます。統合ONTAPでは、RAIDグループのディスク数は最大28台で、そのうち3台はパリティ用、1台は予備として予約されます。その結果、28台のドライブのうち24台がデータ処理/RAIDストライプに使用されます。
統一ONTAP RAIDグループ

NetApp AFXは引き続きRAID-TECを活用しますが、必要なパリティドライブは3台、スペアドライブは1台のみでありながら、RAIDグループのサイズを96ドライブに拡張します。より大規模なRAIDグループは全体的なパフォーマンスを向上させますが、SSDの低い障害率、より多くのドライブセット全体にわたるより均等に分散された処理、およびNetApp AFXにおけるパリティからのデータドライブの再構築の改善の組み合わせにより、ドライブ障害のリスクは最小限に抑えられます。
NetApp AFX Storage Availability Zone RAIDグループ

以下の表は、統合型 ONTAP および NetApp AFX における 84 ディスクの使用可能な生容量の概算値を、ドライブ サイズ別に示しています。
おおよその生容量比較、84 台のドライブ – Unified ONTAP および NetApp AFX
| ドライブ容量 | おおよその生容量(Unified) | 概算生容量(AFX) |
|---|---|---|
7.6 TB |
~547.2TB |
約608TB(+60.8TB) |
15.3 TB |
~1101.6TB |
約1224TB(+122.4TB) |
30.6 TB |
~2203.2TB |
約2448TB(+244.7TB) |
60.1 TB |
~4327.2TB |
~4808TB(+480.8TB) |
ディスク障害の再構築時間の短縮
統合 ONTAP では、各ノードがストレージ スタック内のディスクのサブセットを所有します。つまり、そのノードはそれらのディスクにのみ書き込みを行いますが、ディスク障害が発生した場合、ディスクの再構築は単一のノードによってのみ処理されます。
NetApp AFX はディスク所有権を必要としません。その結果、必要に応じて単一のノードからすべてのドライブに書き込みを行うことができます。つまり、ドライブをパリティから再構築する必要がある場合、クラスタ内のすべてのノードが参加するため、単一のノードが単独で行う場合よりも迅速にドライブの再構築を行うことができます。
NetApp AFX でのディスク再構築
重複排除ドメイン
重複排除機能により、ストレージシステムはファイルシステム内の重複ブロックを検出し、単一のブロックへのポインタを作成することで、使用容量の総量を削減できます。統合ONTAPでは、重複排除は削減できるブロックに関して特定の境界に従います。これらの境界は、使用されている重複排除のタイプによって異なります。一般的に:
-
ボリュームベースの重複排除 → ボリューム境界
-
ボリューム間重複排除 → アグリゲート境界
統一 ONTAP 重複排除ドメイン

以下の表は、統合された ONTAP のさまざまなシナリオにおける重複データの容量挙動を示しています。ファイルコピーがノードやアグリゲート(つまり重複排除ドメイン)にまたがる場合、節約できる容量は減少します。
同一の10GBファイルに対するさまざまなシナリオでの重複排除動作 – 統合ONTAP
| シナリオ | 使用済みスペース |
|---|---|
同じ10GBファイルの4つのコピー、同じボリューム(ボリューム重複排除) |
10 GB |
同じ10GBファイルの4つのコピー、異なるボリューム、同じアグリゲート(ボリューム間重複排除が有効) |
10 GB |
同じ10GBファイルのコピーが4つ、4つの異なるボリューム、4つの異なるアグリゲート(ボリューム間重複排除が有効) |
40 GB |
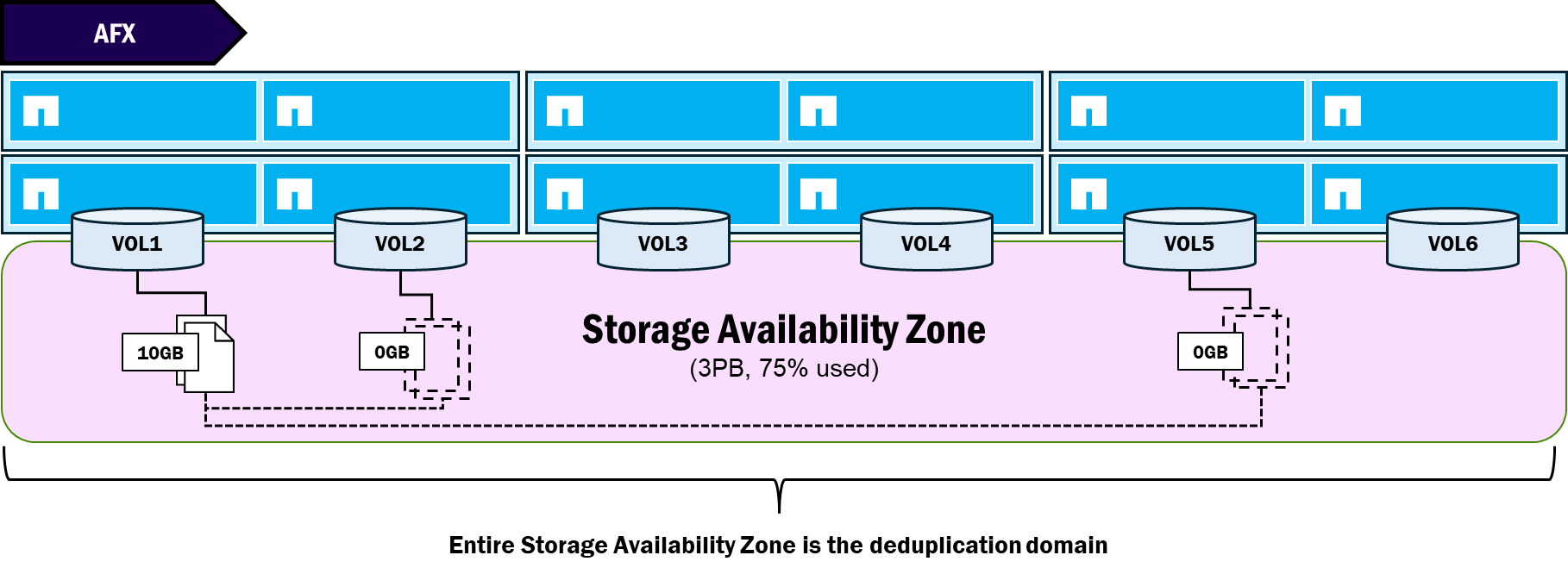
NetApp AFXでは物理アグリゲートが削除され、容量管理が新しいStorage Availability Zoneに移行されるため、重複排除ドメインの境界も変更されます。AFXでは、重複排除ドメインはボリュームレベル(統合ONTAPと同様)および9.19.1より前のノード(アグリゲートではなく)にあります。
ONTAP 9.19.1以降、AFXはStorage Availability Zoneレベルでグローバル重複排除ドメインをサポートしているため、クラスタストレージプール内のすべての重複ブロックは同じように扱われます。
NetApp AFX – グローバル重複排除ドメイン(ONTAP 9.19.1)
以下の表は、NetApp AFXのさまざまなシナリオにおける重複データの容量動作を示しています。
同一の10GBファイルに対するさまざまなシナリオでの重複排除動作 – NetApp AFX
| シナリオ | 使用済みスペース |
|---|---|
同じ10GBファイルの4つのコピー、同じボリューム(ボリューム重複排除) |
10GB (9.18.1) 10GB (9.19.1) |
同じ10GBファイルの4つのコピー、異なるボリューム、同じノード(ボリューム間重複排除が有効) |
10GB (9.18.1) 10GB (9.19.1) |
同じ10GBファイルのコピーが4つ、4つの異なるボリューム、4つの異なるノード(ボリューム間重複排除が有効) |
40GB(9.18.1)10GB(9.19.1) |
削除された機能/サポート対象外となった機能
NetApp AFXは、ハイパフォーマンスNASおよびオブジェクトワークロード、特に(ただしこれに限定されない)AIトレーニングおよび推論領域のワークロード向けに設計されています。NetApp AFXの設計により、ONTAPの一部の機能を無効にする決定が行われました。
-
ハイパフォーマンス NAS とオブジェクトに焦点を当てているため、ブロック ワークロードは NetApp AFX ソリューションから削除されました。FCP、iSCSI、NVMe のデータ プロトコルはサポートされておらず、ブロック プロトコルを追加する予定もありません。
-
Disaggregated とは de-aggregated と同義であり、アグリゲート(少なくとも物理ストレージ管理の概念として)が削除されたことを意味します。物理アグリゲートを削除すると、ONTAP での容量管理が簡素化されるだけでなく、単一の容量プールを可能にするメカニズムも提供されます。
-
アグリゲートが削除されるということは、アグリゲート固有の機能も削除されることを意味します。たとえば、MetroClusterは、サイトフェイルオーバー機能のために、アグリゲートレベルのミラーリングを活用しています。そのため、MetroClusterもNetApp AFXから削除されます。サイトフェイルオーバー機能は、代わりにONTAP 9.19.1GAで提供される新しいSnapMirror Active-Sync for NAS機能によって提供されます。
-
FabricPoolと呼ばれるコールドデータ階層化機能も、アグリゲート固有であるため、現在NetApp AFXでは利用できません。
-
新しい容量アーキテクチャにより、NetApp AFXではコピーベースのボリューム移動も不要になりました。詳細については、ゼロコピーボリューム移動を参照してください。
-
機能の削除は、一部のCLI/GUI/REST APIの変更も意味するため、サポートされなくなった機能のコマンドやAPI呼び出しもすべて削除されます。
-
ZAPI は現在 NetApp AFX では利用できません。
-
仮想化向けのNFSコピー オフロード(粒度データ分布のみのFlexGroupボリューム)
ONTAPの管理の変更
一般的に、NetApp AFX管理は、クラスターを管理するために使用されるメカニズムを変更するものではありません。管理者は引き続き、CLI、GUI、およびREST APIを利用してクラスターにログインし、構成を行うことができます。しかし、NetApp AFXは、ストレージ管理業務の実施方法の一部を改善する機会を提供しました。
よりシンプルな容量管理
NetApp AFX Storage Availability Zoneは、管理エンドポイントをノードおよびアグリゲートベースのアプローチから、クラスタ全体で利用可能な単一の容量プールに削減します。ボリュームが拡張および縮小すると、ONTAPは自動的にStorage Availability Zoneとの間で容量を借用および返却します。
このため、ストレージ管理者は、最大24個のノードと場合によっては数百個のアグリゲートにわたる利用可能な空き容量の場所を特定し、管理する必要がなくなります。その代わりに、容量の管理と確認ができる場所は1箇所だけです。
例えば、統合された ONTAP の CLI では、クラスターの物理容量の合計情報を確認したい場合は、「aggregate show-space」を使用します。これにより、すべてのアグリゲートエントリが出力されます。NetApp AFX では、「cluster space show」というコマンドがあり、これを実行すると単一のストレージ可用性ゾーンのみが表示されます。
統合 ONTAP と NetApp AFX における容量 CLI コマンドの並列比較

Unified ONTAP System Manager の GUI では、容量を示すために階層が使用されます。実際、GUI は合計値を算出してクラスター全体の容量を包括的に表示しようと試みていますが、それでもアグリゲート単位での全体的な使用状況が表示されます。
System Managerの容量ビュー - 統合ONTAP
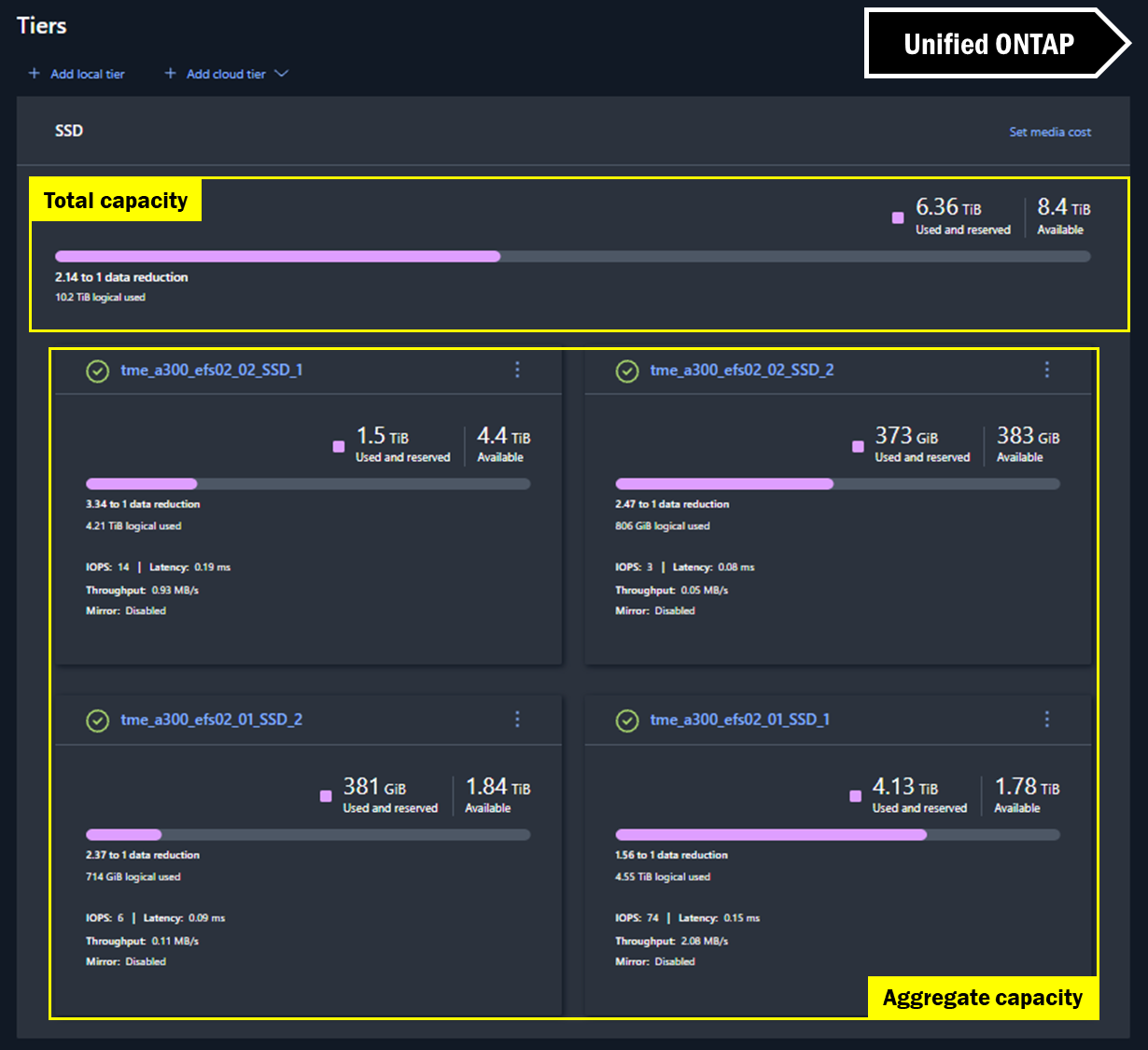
NetApp AFX System Managerでは、クラスタスペースの表示はほぼ同じですが、アグリゲートがないため、追加の計算は不要です。表示されている容量が、実際に得られる容量です。
System Manager の容量ビュー – NetApp AFX
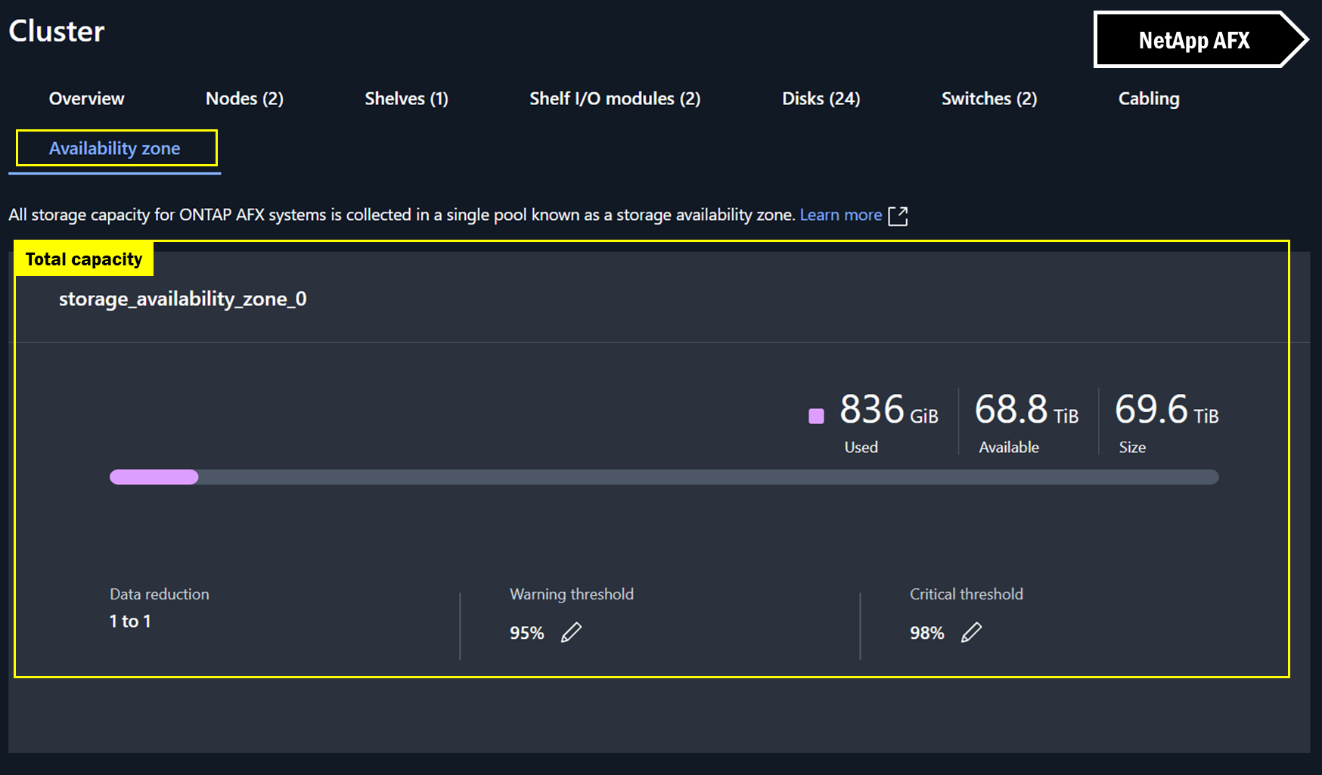
FlexGroup ボリューム管理の機能拡張
FlexGroupボリュームは、クラスター内の複数のノードとアグリゲートにまたがって作成された複数の基盤となるFlexVol構成ボリュームで構成され、NASクライアントに対して単一の大きな名前空間として提示されます。FlexGroupボリュームは、ハイパフォーマンスワークロードに対して、パフォーマンス、スケール、ロード バランシング、およびファイル数のメリットを提供します。ただし、ノードとアグリゲート間で連携するため、アグリゲートが提供する独立したファイルシステムにもそれぞれ独立した容量使用量と制限があるため、容量がいっぱいになり始めると、物理的な制約に直面することがあります。たとえば、FlexGroupボリューム構成要素を持つアグリゲートがクラスター内の他のアグリゲートよりも先にいっぱいになり始めると、FlexGroup全体が容量またはパフォーマンスの問題に直面する可能性があります。
その結果、ストレージ管理者は、基盤となるFlexGroupインフラストラクチャについて過度に心配することになり、環境の他の側面の維持への関心が低下する可能性があります。
FlexGroupボリュームレイアウト - 統合ONTAPアグリゲート
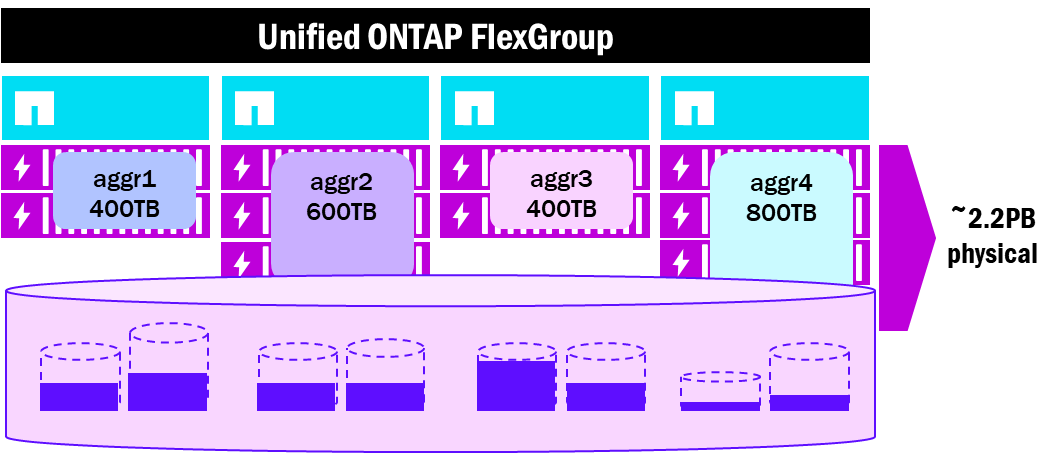
NetApp AFXは単一のStorage Availability Zoneで容量を提示します。これは、FlexGroupボリュームの動作方法をより忠実に反映しています。サイズが異なる可能性のある複数の異なるアグリゲートにまたがる複数の構成ボリュームではなく、すべてのボリュームが同じ容量プールに存在するため、FlexGroupボリュームを使用する際の全体的な管理オーバーヘッドが大幅に簡素化されます。
さらに、AFXはデフォルトでFlexGroupボリュームのAdvanced Capacity Balancingを有効にし、ボリューム内の大きなファイルをより適切に分散させることができます。これにより、FlexGroupボリュームの構成要素は管理概念としての側面が薄れ、バックグラウンドで静かに機能するようになります。
FlexGroup ボリュームレイアウト - NetApp AFX
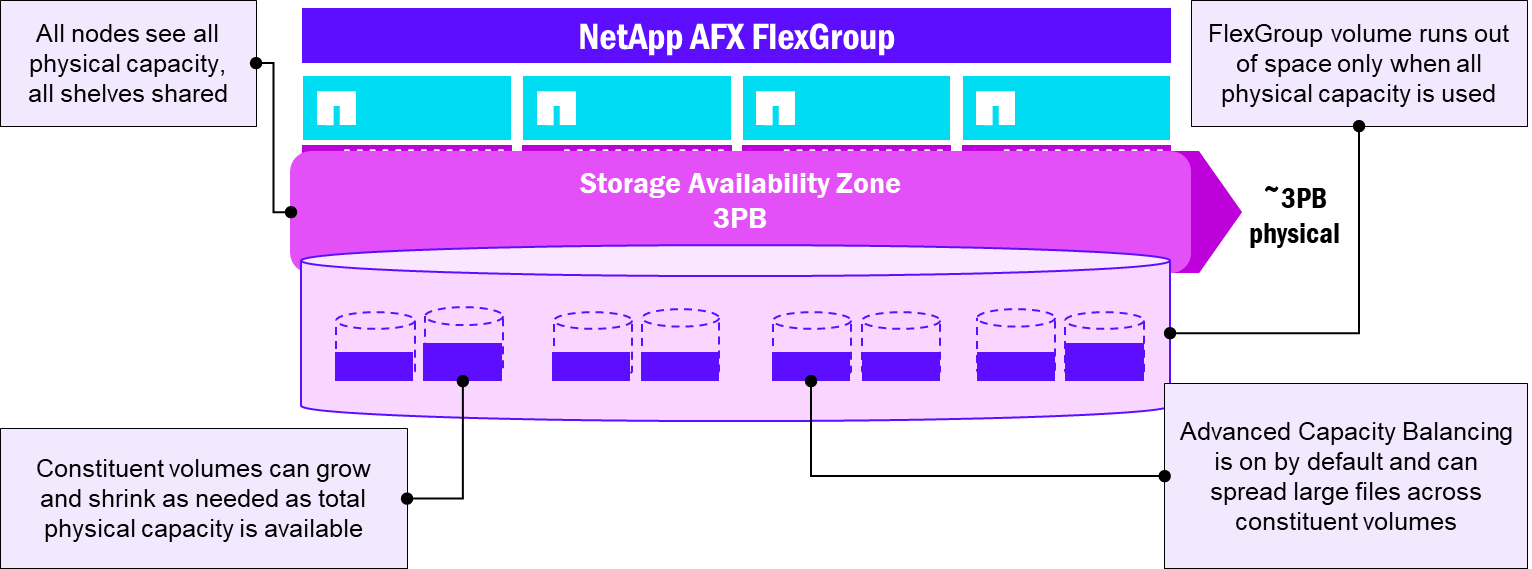
ストレージ管理タスクの自動化
NetApp AFX のストレージ可用性ゾーンでは、すべての容量がすべてのノード間で共有されます。ノードは引き続きボリュームを所有しますが、ONTAP は各ノードの容量使用量を、その時点での各ノードのニーズに基づいて容量を借用および解放することで自動的に管理します。つまり、ストレージ管理者は、使用可能なスペースのバランスを最適に取る方法について心配する必要がなくなります。
さらに、RAID グループ管理は ONTAP によって自動化されており、新しく追加されたディスクは、管理者の介入なしに既存または新規の RAID グループに追加されます。ONTAP は、データをコピーすることなく、ノード間でのボリュームの移動も管理します。
ゼロコピーボリューム移動
統合ONTAPは、クラスタ全体のパフォーマンスと容量使用状況を管理する方法として、ボリュームをノード間またはアグリゲート間で無停止で移動する方法を提供します。
ボリューム移動が開始されると、次のことが起こります:
-
指定されたデスティネーションアグリゲートに新しい空のボリュームが作成されます
-
ボリュームメタデータ(ストレージ効率情報、ファイルハンドルなど)は、新しい宛先ボリュームに複製されます
-
ボリュームデータは、SnapMirrorテクノロジを介してバックエンドクラスタネットワーク経由で宛先ボリュームにレプリケートされます。移動先のアグリゲートには移動に使用可能な空きスペースが必要です。使用可能な空きスペースがない場合、移動ジョブは失敗します
-
ボリュームレプリケーションが再度実行され、両方のボリュームがデータの変更と整合していることを確認します
-
カットオーバー プロセスが開始され、元のボリュームがオフラインになり、デスティネーション ボリュームがクライアントの新しいオリジン ボリュームとして昇格されます
-
切り替え中はクライアントI/Oに一時的な停止が発生しますが、再マウントは不要です
NetApp AFXでは、Storage Availability Zoneがすべての容量をすべてのノードに提供し、すべてのノードがそのプール内の任意のディスクに書き込むことができます。データが配置されると、ボリュームが移動されても、データは配置された場所に留まります。つまり、データのコピーは不要です。ボリューム移動プロセスは、SnapMirrorを介したデータのレプリケーションが不要である点を除いて、統合ONTAPと同じです。追加の容量は必要ありません。
NetApp AFX でのゼロコピーボリューム移動
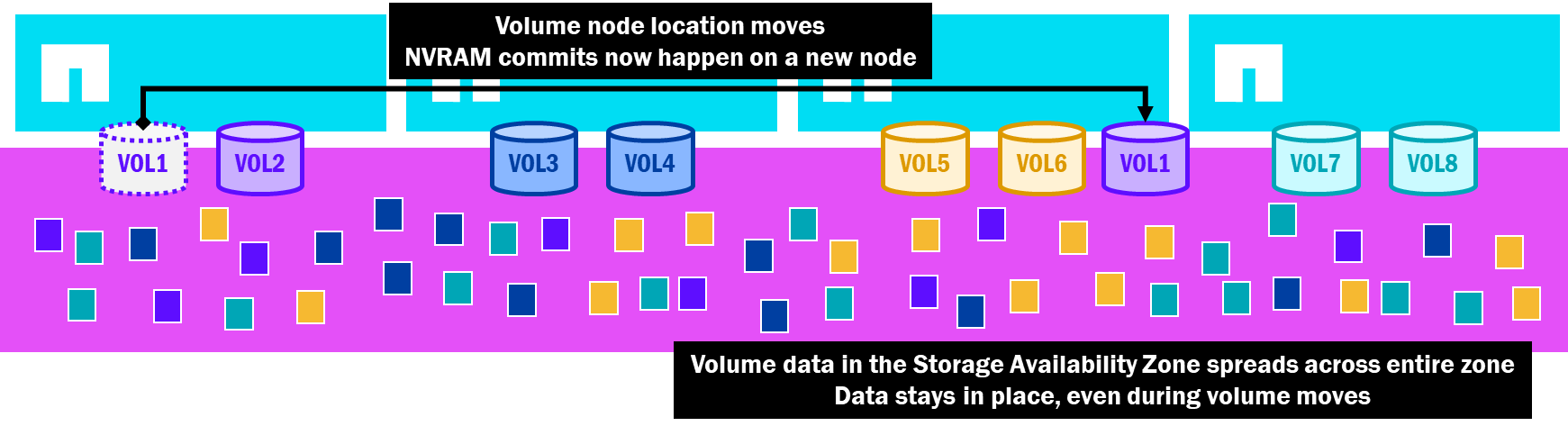
軽量ボリュームモビリティにより、AFX はパフォーマンスや容量の制約なしに多くの管理タスクを自動化でき、これらのボリューム移動は、以下のトピックで説明する NetApp AFX が提供するいくつかの新機能で使用されます。
HA フェイルオーバー動作
統合 ONTAP では、ノードがディスクとアグリゲートを所有し、データはボリュームを介して提供されます。書き込みは、ローカルノードの NVRAM を使用して、ノードが所有するディスクにフラッシュされます。ノードが再起動または障害が発生した場合、ONTAP は障害が発生したノードのリソースのテイクオーバーをトリガーし、ディスクとアグリゲートの所有権がパートナーノードに転送されます。ネットワークインターフェイスも IP スペース内のポートにフェイルオーバーされ、NVRAM の内容は HA ペア全体で常にレプリケートされているため、ノードは NVRAM の内容をフラッシュして、障害が発生したノードの書き込みをディスクにコミットします。その後、ノードのギブバックが発生するまで、存続しているノードが障害が発生したノードのアグリゲートとボリュームを所有します。つまり、フェイルオーバーの問題が解決されるまで、これらのボリュームへのすべてのトラフィック、および存続しているノードがすでに所有しているボリュームへのトラフィックは、単一のノードで処理されます。
初期の統合 ONTAP クラスタ導入の一環として、単一ノードがパートナーに過負荷をかけることを避けるために、フェイルオーバーを事前に計画しておくことを推奨します。それ自体が課題となります。なぜなら、どのボリュームがパフォーマンスの妨げになるかを予測するのは難しいからですが、無停止ボリューム移動やボリュームのサービス品質ポリシーなどの機能が緩和に役立ちます。
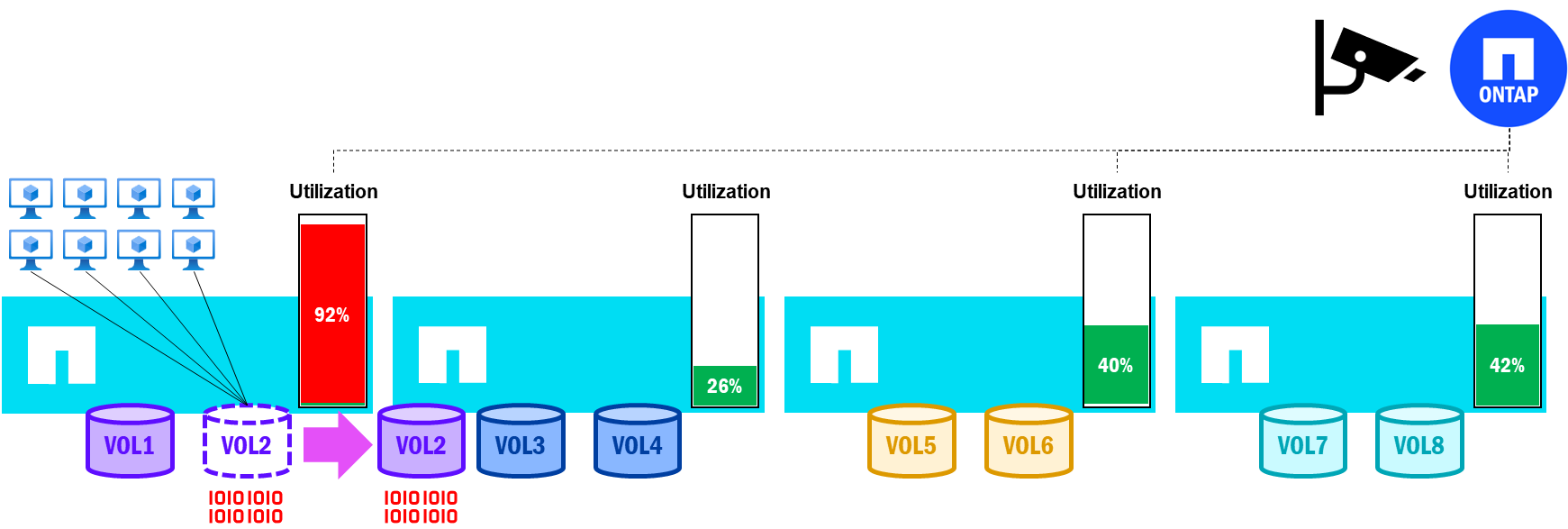
以下の画像は、統合された ONTAP クラスタでノード間のパフォーマンス バランスが不均一になる可能性があること、およびフェイルオーバーによって場合によってはパフォーマンスの低下が発生する可能性があることを示しています。
Unified ONTAP – ノード利用率の潜在的な不均衡
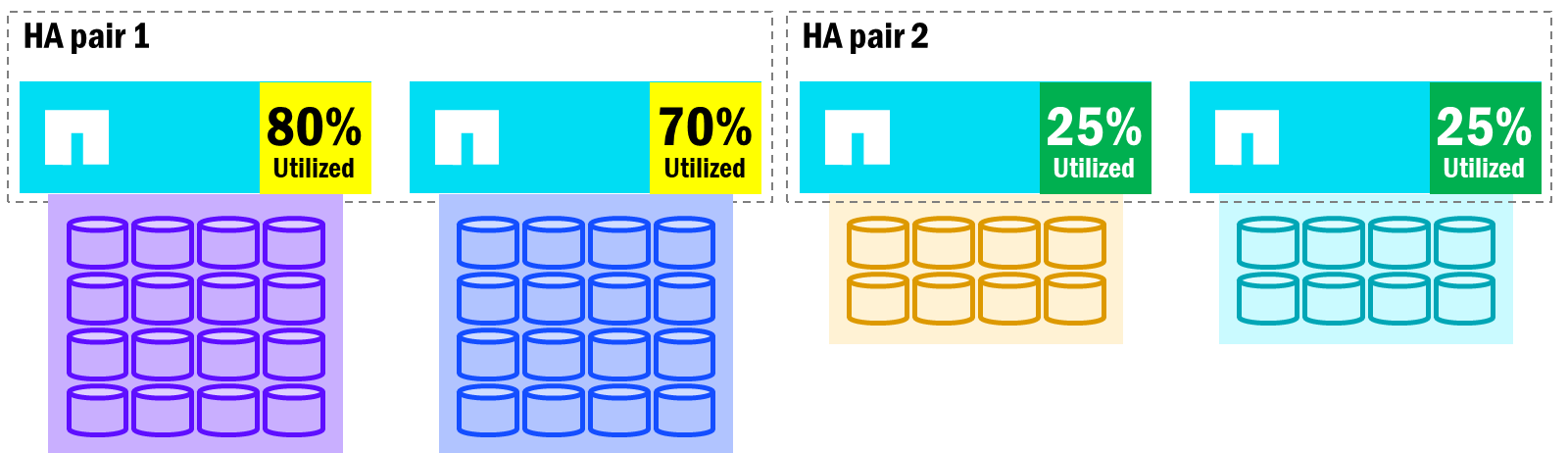
HA ペアのノードのボリューム数とパフォーマンス利用率のバランスが崩れると、ノードのフェイルオーバーは全体的なパフォーマンスに影響を与えます。なぜなら、生き残ったノードが、障害が発生したノードのすべてのボリュームを所有することになるからです。一方、クラスター内の他のノードには、追加の作業を引き受ける余地があるかもしれません。
統一ONTAP –フェイルオーバーがノード利用率に与える影響
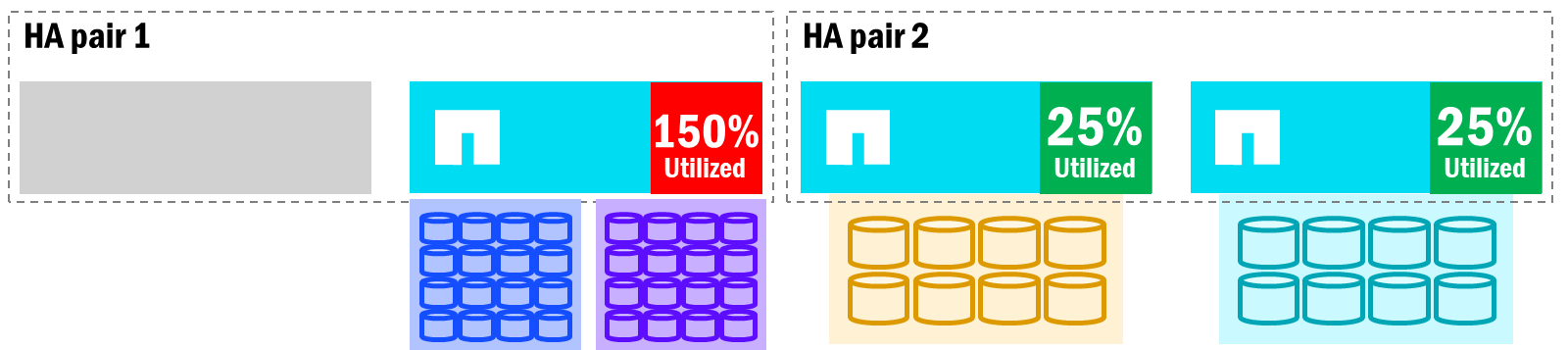
上記のように、HAパートナーが追加の作業を引き受けなければならない場合、過負荷状態になり、そのノード上のすべてのボリュームのパフォーマンスに影響を与える可能性があります。ボリュームの移動は状況の緩和に役立ちますが、これにはノード間でのコピーが必要であり(利用可能な空き容量が必要)、その所要時間はノードがフェイルバックするまでの時間を超える可能性があります。さらに、ボリュームを再配置しても、元のノードにフェイルバックすることはありません。その代わりに、移動先のノードにそのまま残ります。
NetApp AFXでは、ノードのフェイルオーバー時にいくつかの異なる動作が見られます。
-
ノードはディスクを所有しておらず、物理アグリゲートも存在しないため、ノードのフェイルオーバーではこれらのリソースの転送は不要です。その代わりに、ネットワークインターフェイスとボリュームの所有権のみが他のノードに転送されます。
-
NVRAMコミットは引き続き行われますが、直接接続ではなくHAネットワークを介して行われます。
-
ボリュームがパートナー ノードへの初期フェイルオーバーを実行すると、AFXはクラスタ内の他の生存ノードにボリュームを再分配します。これは、ゼロコピー ボリューム移動によって可能になります。
-
ノードが復旧すると、ボリュームは元のノードに戻ります。
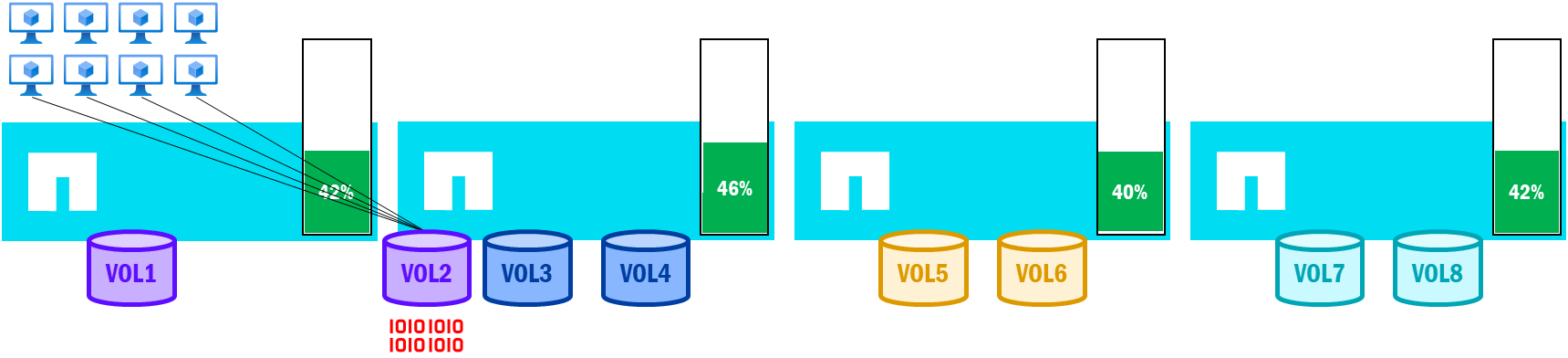
NetApp AFXは既にクラスタ内のノード間でパフォーマンスのバランスを維持し、比較的均一な利用率を保つように設計されているため、フェイルオーバーが発生してボリュームが再バランスされると、クラスタ全体でノードの利用率はほぼ同じになるはずです。
NetApp AFX - フェイルオーバー後のボリューム再バランス
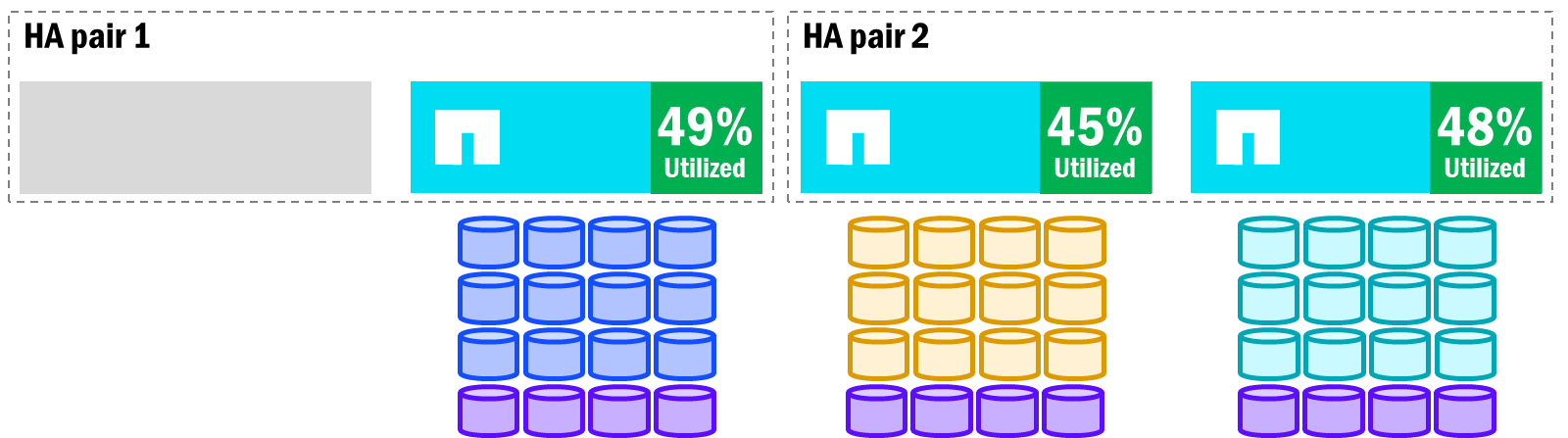
ノードの追加と削除
統合ONTAPとNetApp AFXの両方で、クラスタへのノードの追加と削除が可能です。ただし、アーキテクチャ上の違いがあるため、ノードの追加と削除のプロセスは若干異なります。
統合ONTAPでのノードの追加/削除
ユニファイド ONTAP では、ノードとディスクの所有権が直接結び付けられており、すべてのノードにディスクがいくつか存在し、少なくとも 1 つのアグリゲートが接続されている必要があることはすでに学習しました。これを踏まえると、追加と削除に関しては次のことが当てはまります。
-
統合されたONTAPでのノードの追加には追加の手順は必要ありませんが、すべてのノード(新しいノードを含む)でバランスの取れたパフォーマンスを実現するには、ボリュームを新しいノードに移動する必要があります。これには、既存のボリュームとそのワークロードの事前分析、移動するボリュームの決定、そして実際のボリューム移動が必要となります。そして、その移動には、バックエンドクラスタネットワーク全体にわたるデータのコピーが必要となります。
-
統合ONTAPでのノードの削除では、ノード上の既存のボリュームを手動で退避させる必要があります。つまり、均一なパフォーマンスを維持するために、どのノードがどのボリュームをホストできるかを特定し、それらのボリュームを移動するための十分な空き容量を確保する必要があります。空き容量が不足している場合は、クラスタ内でワークロードを少し再配置するために、追加のボリューム移動が必要になる場合があります。ノードの削除はHAペアの削除も伴うため、作業量は2倍になります。ノードはディスクを所有しているため、それらのノードについてもディスク全体の再初期化が必要となります。これらの要素はすべて、本来比較的簡単なはずの作業に時間と労力を追加することになります。
NetApp AFXでのノードの追加/削除
また、NetApp AFXは標準のノードとディスクの所有権を利用せず、物理アグリゲートを使用してクラスタに容量を提供しないことも学びました。そのため、ノードの追加と削除の動作は若干異なります。
-
NetApp AFXでのノード追加では、事前のボリューム分析は不要であり、各ノードのボリュームが均等になるようにするための管理上の介入も不要です。その代わり、ONTAPは新しく追加されたノード間でボリューム数を自動的にバランス調整し、比較的均一なパフォーマンスプロファイルを維持します。ONTAPはボリュームをコピーすることなくノード間で自動的に移動させるため、クラスターにノードを追加する際に必要な時間、容量、労力を削減できます。
-
NetApp AFXでのノードの削除も、手動による介入をほとんど、あるいは全く必要としません。ノードが削除対象としてタグ付けされると、ONTAPは削除されるノードからデータを解放するために、ボリュームをノード間で自動的に移動します(コピーは行いません)。また、ノードが所有するディスクが存在しないため、ノードを削除した後にディスクを再初期化する必要はありません。これにより、AFXのノードはモジュール構造となり、容易にスケールアップまたはスケールダウンが可能になります。
目標達成ベースのボリューム移動
NetApp AFXのゼロコピーボリューム移動機能により、データのコピーを行わずに必要に応じてボリュームのバランス調整が可能となり、迅速な処理と追加容量を必要としない運用を実現します。これは、ボリューム移動がONTAPクラスタで利用可能な自動ロード バランシングのより大きな部分を占めることができることを意味します。ボリュームの移動にほとんどコストがかからなくなったため、ONTAPはこの貴重なツールを活用して、目標達成ベースのボリュームのロード バランシングなどの機能を組み込むことができます。
NetApp AFX で ONTAP 9.18.1 以降を実行している場合、ノード、 HA ペア、およびボリュームの使用率が継続的に監視され、パフォーマンス データが収集および分析されます。ノードの使用率が定義されたしきい値を超えた場合、 ONTAP はクラスタ全体のパフォーマンスのバランスを保つために、使用率の低いノードに移動するボリュームを自動的に選択します。
NetApp AFXにおけるパフォーマンス重視のボリューム移動 – 高い利用率がボリューム移動をトリガーする
NetApp AFXにおけるパフォーマンス重視のボリューム移動 – ボリューム移動後のバランスの取れたノード利用率
クラスタの規模と拡張
統合ONTAPクラスタは最大24ノードをサポートし、追加される各ノードにはディスク(システム機能とデータサービスの両方のため)も追加する必要があります。ディスクシェルフはクラスタに追加できますが、クラスタの規模が24ノードであっても、常に単一のHAペアに接続され、単一のノードのみが所有します。これは、パフォーマンスのみが求められる場合でもクラスタに容量が追加されることを意味し、パフォーマンスの向上は主に新しいノードが所有する特定のディスクセットに限定されます。その結果、必ずしも必要ではない余剰容量を抱えてしまう可能性があります。
Unified ONTAP – スケールに関する考慮事項を追加
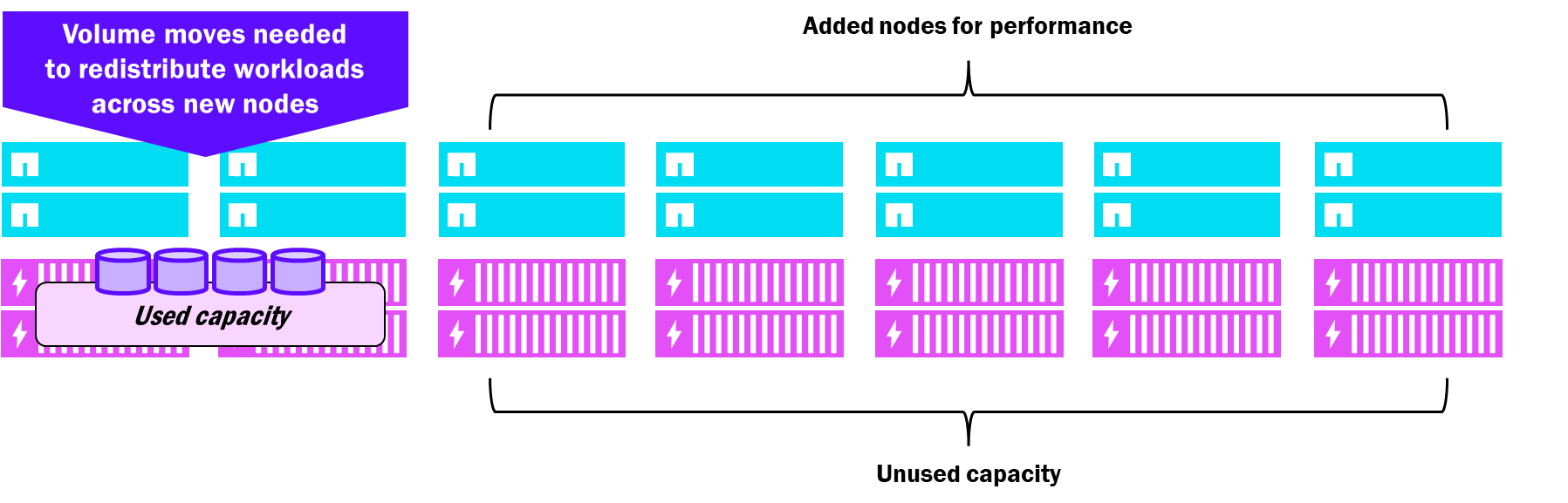
NetApp AFXは、より大規模なクラスター構成に対応しています。バージョン9.19.1以降、AFXクラスターは1つのクラスター内で最大32ノードまで構成できるようになりました。すべてのノードがすべてのディスクを認識してアクセスできるため、パフォーマンスと容量(ONTAP 9.19.1時点で最大32PB)を共有できるので、リソースが無駄になることはありません。ボリューム移動にはコピーは必要ないため、ONTAPはボリュームを新しく追加されたノードに自動的に移動してノードの利用率を均等に分散させることができ、一方で容量はStorage Availability Zoneを介して均等に分散されます。
NetApp AFX – スケールに関する追加検討事項

ルートボリュームの変更
NetApp ONTAPでは、各ノードにルートボリュームが割り当てられます。このボリュームは、ログファイル、ブートイメージ、コアファイル、クラスタデータベースなど、システム固有のファイルや機能に使用されます。
統合ONTAPでは、これらのルートボリュームは物理ルートアグリゲート上に存在していました。ルートアグリゲートが使用する容量を削減するため、Advanced Disk Partitioning(ADP)を使用して、データドライブのパーティションをまたいでルートアグリゲートが作成されました。
NetApp AFXは物理アグリゲートを排除するため、ルートアグリゲートやADPを使用する必要がなくなります。ルートボリュームは依然として概念として存在しますが、現在は容量プールの仮想化領域に存在し、追加の設定は不要です。さらに、ルートボリュームの機能も変更されます。ブートイメージと複製されたクラスタデータベースは、ストレージ スタックから移動され、各AFXノードに搭載されているオンボードブートメディアに配置されます。これにより、ストレージ スタックへのアクセスが失われても、ノードは起動してクラスタの適格性を維持できるため、トラブルシューティングの複雑さが軽減されます。
オンボード ブート メディア
NetApp AFXノードは、オンボードのブートメディアとして、約3.8TBの容量を持つNVMe接続のM.2デバイスを活用します。これらのブートデバイスには、ストレージエンクロージャとは別にブートイメージファイルと複製されたデータベースが含まれており、ディスクアクセスに問題が発生した場合に冗長性を高めます。ブートメディアに障害が発生した場合、ノードはHAパートナーによって引き継がれ、ブートメディアを交換できます。交換後、新しいONTAPイメージはストレージ管理者によってデバイスにロードされ、ONTAPがクラスタデータベースを自動的に再構築し、完全な機能を復元します。