사용 사례 2: 클라우드에서 온프레미스로의 백업 및 재해 복구
 변경 제안
변경 제안
이 사용 사례는 아래 그림에서 볼 수 있듯이 클라우드 기반 분석 데이터를 온프레미스 데이터 센터에 백업해야 하는 방송 고객을 기반으로 합니다.
대본
이 시나리오에서는 IoT 센서 데이터가 클라우드로 수집되어 AWS 내의 오픈 소스 Apache Spark 클러스터를 사용하여 분석됩니다. 필요한 것은 클라우드에서 처리된 데이터를 온프레미스로 백업하는 것입니다.
요구 사항 및 과제
이 사용 사례에 대한 주요 요구 사항과 과제는 다음과 같습니다.
-
데이터 보호를 활성화해도 클라우드의 프로덕션 Spark/Hadoop 클러스터의 성능에 영향이 없어야 합니다.
-
클라우드 센서 데이터는 효율적이고 안전한 방식으로 온프레미스로 이동되고 보호되어야 합니다.
-
온디맨드, 즉각적, 클러스터 부하가 적은 시간 등 다양한 조건에 따라 클라우드에서 온프레미스로 데이터를 전송할 수 있는 유연성이 있습니다.
해결책
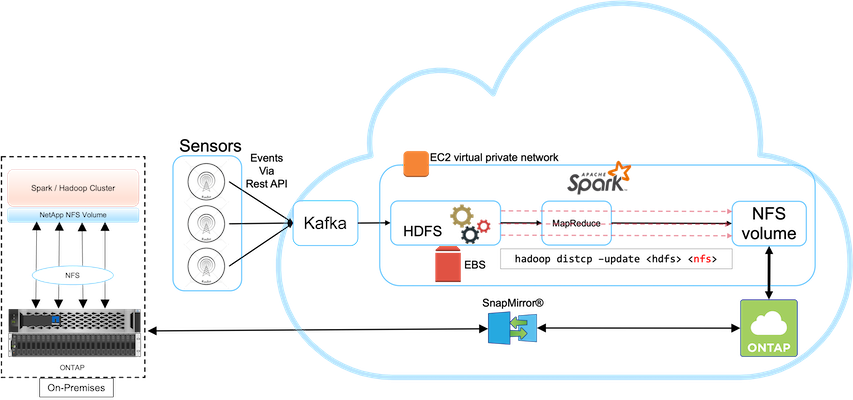
고객은 Spark 클러스터 HDFS 스토리지로 AWS Elastic Block Store(EBS)를 사용하여 Kafka를 통해 원격 센서로부터 데이터를 수신하고 수집합니다. 따라서 HDFS 저장소는 백업 데이터의 소스 역할을 합니다.
이러한 요구 사항을 충족하기 위해 NetApp ONTAP Cloud를 AWS에 배포하고 Spark/Hadoop 클러스터의 백업 대상으로 사용할 NFS 공유를 생성합니다.
NFS 공유가 생성된 후 HDFS EBS 스토리지에서 ONTAP NFS 공유로 데이터를 복사합니다. 데이터가 ONTAP 클라우드의 NFS에 저장된 후, SnapMirror 기술을 사용하여 필요에 따라 안전하고 효율적인 방식으로 클라우드의 데이터를 온프레미스 스토리지로 미러링할 수 있습니다.
이 이미지는 클라우드에서 온프레미스 솔루션으로의 백업 및 재해 복구를 보여줍니다.