

사용 사례 4: 데이터 보호 및 멀티클라우드 연결
 변경 제안
변경 제안
이 사용 사례는 고객의 빅데이터 분석 데이터에 대한 멀티클라우드 연결을 제공하는 업무를 맡은 클라우드 서비스 파트너에게 적합합니다.
대본
이 시나리오에서는 다양한 소스에서 AWS로 수신된 IoT 데이터가 NPS의 중앙 위치에 저장됩니다. NPS 스토리지는 AWS와 Azure에 있는 Spark/Hadoop 클러스터에 연결되어 여러 클라우드에서 실행되는 빅데이터 분석 애플리케이션이 동일한 데이터에 액세스할 수 있도록 합니다.
요구 사항 및 과제
이 사용 사례에 대한 주요 요구 사항과 과제는 다음과 같습니다.
-
고객은 여러 클라우드를 사용하여 동일한 데이터에 대한 분석 작업을 실행하려고 합니다.
-
데이터는 다양한 센서와 허브를 통해 온프레미스, 클라우드 등 다양한 소스에서 수신되어야 합니다.
-
해결책은 효율적이고 비용 효과적이어야 합니다.
-
가장 큰 과제는 온프레미스와 다양한 클라우드 간에 하이브리드 분석 서비스를 제공하는 비용 효율적이고 효과적인 솔루션을 구축하는 것입니다.
해결책
이 이미지는 데이터 보호 및 멀티클라우드 연결 솔루션을 보여줍니다.
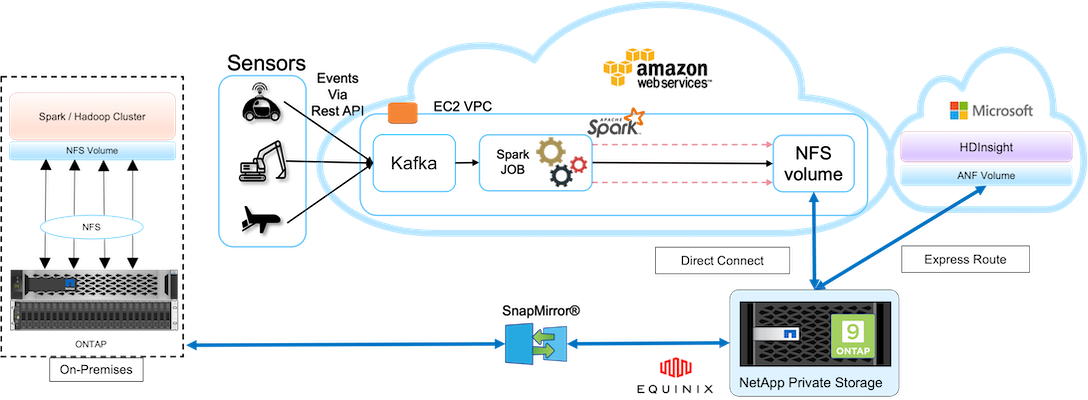
위 그림에서 볼 수 있듯이, 센서의 데이터는 Kafka를 통해 AWS Spark 클러스터로 스트리밍되고 수집됩니다. 데이터는 클라우드 제공자 외부의 Equinix 데이터 센터 내에 있는 NPS에 있는 NFS 공유에 저장됩니다. NetApp NPS는 Direct Connect와 Express Route 연결을 통해 Amazon AWS와 Microsoft Azure에 연결되어 있으므로 고객은 Amazon과 AWS 분석 클러스터 모두에서 NFS 데이터에 액세스할 수 있습니다. 이 접근 방식은 여러 하이퍼스케일러에서 클라우드 분석을 수행하는 문제를 해결합니다.
따라서 온프레미스와 NPS 스토리지 모두 ONTAP 소프트웨어를 실행하므로 SnapMirror NPS 데이터를 온프레미스 클러스터로 미러링하여 온프레미스와 여러 클라우드에서 하이브리드 클라우드 분석을 제공할 수 있습니다.
최상의 성능을 위해 NetApp 일반적으로 여러 네트워크 인터페이스와 직접 연결/고속 경로를 사용하여 클라우드 인스턴스의 데이터에 액세스할 것을 권장합니다.