

NetApp Spark 솔루션 개요
 변경 제안
변경 제안
NetApp FAS/ AFF, E-Series, Cloud Volumes ONTAP 세 가지 스토리지 포트폴리오가 있습니다. 우리는 Apache Spark를 기반으로 Hadoop 솔루션을 위한 ONTAP 스토리지 시스템을 갖춘 AFF 와 E-시리즈를 검증했습니다.
NetApp 이 제공하는 데이터 패브릭은 아래 그림에서 볼 수 있듯이 데이터 액세스, 제어, 보호 및 보안을 위한 데이터 관리 서비스와 애플리케이션(빌딩 블록)을 통합합니다.
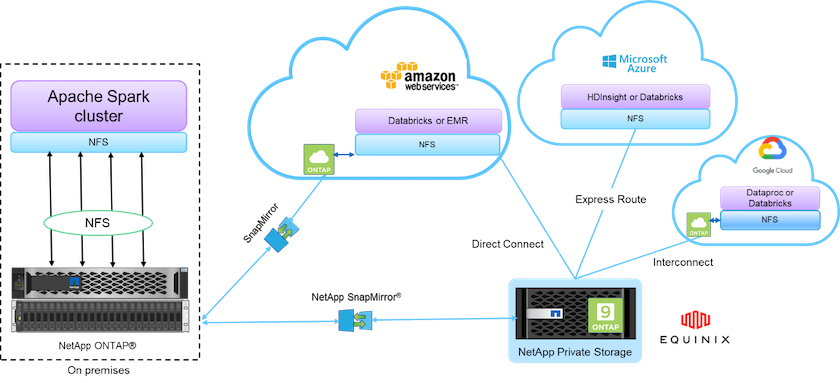
위 그림의 구성 요소는 다음과 같습니다.
-
* NetApp NFS 직접 액세스.* 추가 소프트웨어나 드라이버가 필요하지 않고 최신 Hadoop 및 Spark 클러스터에서 NetApp NFS 볼륨에 직접 액세스할 수 있습니다.
-
* NetApp Cloud Volumes ONTAP 및 Google Cloud NetApp Volumes.* Amazon Web Services(AWS)에서 실행되는 ONTAP 또는 Microsoft Azure 클라우드 서비스의 Azure NetApp Files (ANF) 기반의 소프트웨어 정의 연결 스토리지입니다.
-
* NetApp SnapMirror 기술.* 온프레미스와 ONTAP Cloud 또는 NPS 인스턴스 간의 데이터 보호 기능을 제공합니다.
-
클라우드 서비스 제공자. 이러한 공급업체로는 AWS, Microsoft Azure, Google Cloud, IBM Cloud가 있습니다.
-
PaaS. AWS의 Amazon Elastic MapReduce(EMR) 및 Databricks, Microsoft Azure HDInsight 및 Azure Databricks와 같은 클라우드 기반 분석 서비스입니다.
다음 그림은 NetApp 스토리지를 사용한 Spark 솔루션을 보여줍니다.
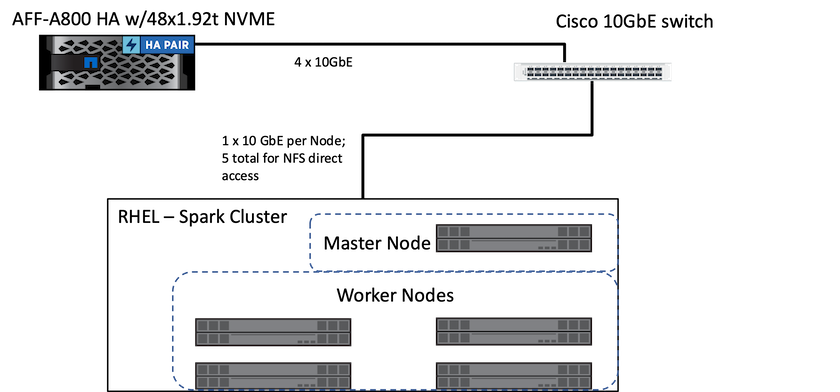
ONTAP Spark 솔루션은 기존 프로덕션 데이터에 대한 액세스를 활용하여 현장 분석 및 AI, ML, DL 워크플로를 위한 NetApp NFS 직접 액세스 프로토콜을 사용합니다. Hadoop 노드에서 사용할 수 있는 프로덕션 데이터는 현장 분석 및 AI, ML, DL 작업을 수행하는 데 내보내집니다. NetApp NFS 직접 액세스를 사용하거나 사용하지 않고도 Hadoop 노드에서 처리할 데이터에 액세스할 수 있습니다. Spark에서 독립형 또는 yarn 클러스터 관리자를 사용하여 NFS 볼륨을 구성할 수 있습니다. file://<target_volume> . 우리는 서로 다른 데이터 세트를 사용하여 세 가지 사용 사례를 검증했습니다. 이러한 검증에 대한 세부 사항은 "테스트 결과" 섹션에 나와 있습니다. (xref)
다음 그림은 NetApp Apache Spark/Hadoop 스토리지 포지셔닝을 보여줍니다.
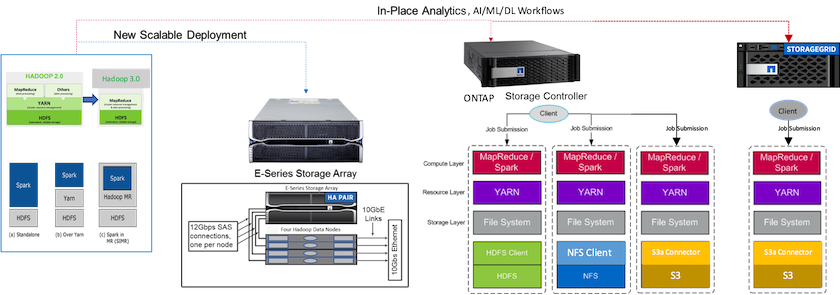
우리는 E-Series Spark 솔루션, AFF/ FAS ONTAP Spark 솔루션, StorageGRID Spark 솔루션의 고유한 기능을 파악하고 자세한 검증 및 테스트를 수행했습니다. 당사의 관찰에 따르면 NetApp 그린필드 설치 및 새로운 확장형 배포의 경우 E-Series 솔루션을, 기존 NFS 데이터를 사용하는 현장 분석, AI, ML, DL 워크로드의 경우 AFF/ FAS 솔루션을, 객체 스토리지가 필요한 경우 AI, ML, DL 및 최신 데이터 분석의 경우 StorageGRID 권장합니다.
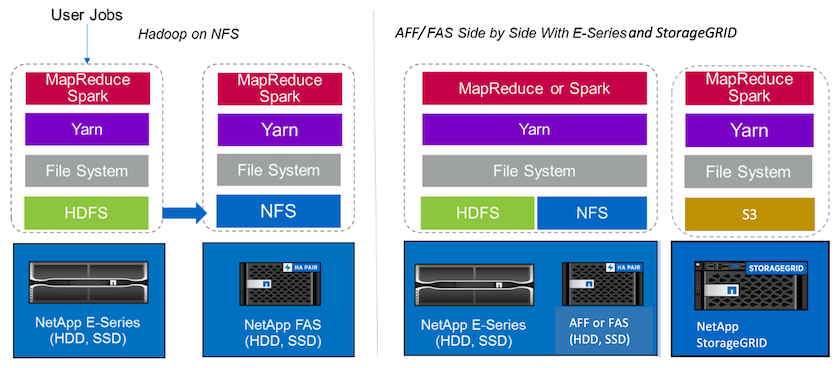
데이터 레이크는 분석, AI, ML, DL 작업에 사용할 수 있는 기본 형태의 대규모 데이터 세트를 저장하는 저장소입니다. 우리는 E-Series, AFF/ FAS, StorageGRID SG6060 Spark 솔루션을 위한 데이터 레이크 저장소를 구축했습니다. E-시리즈 시스템은 Hadoop Spark 클러스터에 HDFS 액세스를 제공하는 반면, 기존 프로덕션 데이터는 Hadoop 클러스터에 대한 NFS 직접 액세스 프로토콜을 통해 액세스됩니다. 개체 스토리지에 있는 데이터 세트의 경우 NetApp StorageGRID S3 및 S3a 보안 액세스를 제공합니다.