

벡터 데이터베이스
 변경 제안
변경 제안
이 섹션에서는 NetApp AI 솔루션에서 벡터 데이터베이스의 정의와 사용에 대해 다룹니다.
벡터 데이터베이스
벡터 데이터베이스는 머신 러닝 모델의 임베딩을 사용하여 비정형 데이터를 처리, 인덱싱, 검색하도록 설계된 특수한 유형의 데이터베이스입니다. 데이터를 기존의 표 형식으로 구성하는 대신, 벡터 임베딩이라고도 하는 고차원 벡터로 데이터를 정리합니다. 이 독특한 구조 덕분에 데이터베이스는 복잡하고 다차원적인 데이터를 보다 효율적이고 정확하게 처리할 수 있습니다.
벡터 데이터베이스의 주요 기능 중 하나는 생성적 AI를 사용하여 분석을 수행하는 것입니다. 여기에는 데이터베이스가 주어진 입력과 유사한 데이터 포인트를 식별하는 유사성 검색과, 표준에서 크게 벗어나는 데이터 포인트를 발견할 수 있는 이상 감지가 포함됩니다.
더욱이 벡터 데이터베이스는 시간 데이터나 타임스탬프가 있는 데이터를 처리하는 데 적합합니다. 이러한 유형의 데이터는 IT 시스템 내에서 발생한 '무엇'이 언제 발생했는지에 대한 정보를 순서대로, 그리고 다른 모든 이벤트와 비교하여 제공합니다. 시간적 데이터를 처리하고 분석하는 이러한 기능 덕분에 벡터 데이터베이스는 시간 경과에 따른 이벤트를 이해해야 하는 애플리케이션에 특히 유용합니다.
ML 및 AI를 위한 벡터 데이터베이스의 장점:
-
고차원 검색: 벡터 데이터베이스는 AI 및 ML 애플리케이션에서 자주 생성되는 고차원 데이터를 관리하고 검색하는 데 탁월합니다.
-
확장성: 대량의 데이터를 처리하도록 효율적으로 확장할 수 있어 AI 및 ML 프로젝트의 성장과 확장을 지원합니다.
-
유연성: 벡터 데이터베이스는 높은 수준의 유연성을 제공하여 다양한 데이터 유형과 구조를 수용할 수 있습니다.
-
성능: AI와 ML 작업의 속도와 효율성에 중요한 고성능 데이터 관리 및 검색 기능을 제공합니다.
-
사용자 정의 가능한 인덱싱: 벡터 데이터베이스는 사용자 정의 가능한 인덱싱 옵션을 제공하여 특정 요구 사항에 따라 최적화된 데이터 구성 및 검색이 가능합니다.
벡터 데이터베이스와 사용 사례.
이 섹션에서는 다양한 벡터 데이터베이스와 해당 사용 사례에 대한 세부 정보를 제공합니다.
파이스와 스카NN
이들은 벡터 검색 영역에서 중요한 도구 역할을 하는 라이브러리입니다. 이러한 라이브러리는 벡터 데이터를 관리하고 검색하는 데 도움이 되는 기능을 제공하므로 데이터 관리의 특수 분야에서 매우 귀중한 리소스입니다.
엘라스틱서치
널리 사용되는 검색 및 분석 엔진이며, 최근 벡터 검색 기능을 통합했습니다. 이 새로운 기능은 기능성을 향상시켜 벡터 데이터를 보다 효과적으로 처리하고 검색할 수 있게 해줍니다.
솔방울
이는 고유한 기능을 갖춘 강력한 벡터 데이터베이스입니다. 인덱싱 기능에서 밀집 벡터와 희소 벡터를 모두 지원하므로 유연성과 적응성이 향상됩니다. 이 솔루션의 주요 장점 중 하나는 기존 검색 방법과 AI 기반 고밀도 벡터 검색을 결합하여 두 가지의 장점을 모두 활용하는 하이브리드 검색 방식을 만드는 능력입니다.
Pinecone은 주로 클라우드 기반으로, 머신 러닝 애플리케이션용으로 설계되었으며 GCP, AWS, Open AI, GPT-3, GPT-3.5, GPT-4, Catgut Plus, Elasticsearch, Haystack 등 다양한 플랫폼과 잘 통합됩니다. Pinecone은 폐쇄형 소스 플랫폼이며 SaaS(Software as a Service) 형태로 제공된다는 점에 유의하는 것이 중요합니다.
고급 기능을 갖춘 Pinecone은 사이버 보안 산업에 특히 적합합니다. 고차원 검색 및 하이브리드 검색 기능을 효과적으로 활용하여 위협을 탐지하고 대응할 수 있습니다.
크로마
4가지 주요 기능을 갖춘 Core-API를 갖춘 벡터 데이터베이스로, 그 중 하나에는 메모리 내 문서 벡터 저장소가 포함됩니다. 또한, Face Transformers 라이브러리를 활용하여 문서를 벡터화하여 기능성과 다양성을 향상시켰습니다. Chroma는 클라우드와 온프레미스 모두에서 작동하도록 설계되었으며, 사용자 요구 사항에 따라 유연성을 제공합니다. 특히 오디오 관련 애플리케이션에 탁월하여 오디오 기반 검색 엔진, 음악 추천 시스템 및 기타 오디오 관련 사용 사례에 매우 적합한 선택입니다.
위비에이트
사용자가 내장 모듈이나 사용자 정의 모듈을 사용하여 콘텐츠를 벡터화할 수 있는 다용도 벡터 데이터베이스로, 특정 요구 사항에 따라 유연성을 제공합니다. 다양한 배포 환경 설정에 맞춰 완전 관리형 솔루션과 자체 호스팅 솔루션을 모두 제공합니다.
Weaviate의 주요 특징 중 하나는 벡터와 객체를 모두 저장할 수 있는 기능으로, 이를 통해 데이터 처리 기능이 향상됩니다. 이는 ERP 시스템의 의미 검색 및 데이터 분류를 포함한 다양한 응용 분야에 널리 사용됩니다. 전자상거래 부문에서는 검색 및 추천 엔진을 구동합니다. Weaviate는 이미지 검색, 이상 감지, 자동 데이터 조화, 사이버 보안 위협 분석에도 사용되어 여러 도메인에 걸친 다재다능함을 보여줍니다.
레디스
Redis는 빠른 인메모리 스토리지로 유명한 고성능 벡터 데이터베이스로, 읽기-쓰기 작업에 대한 낮은 지연 시간을 제공합니다. 따라서 빠른 데이터 액세스가 필요한 추천 시스템, 검색 엔진, 데이터 분석 애플리케이션에 매우 적합합니다.
Redis는 목록, 집합, 정렬된 집합을 포함하여 벡터에 대한 다양한 데이터 구조를 지원합니다. 또한 벡터 간의 거리를 계산하거나 교집합과 합집합을 찾는 등의 벡터 연산도 제공합니다. 이러한 기능은 특히 유사성 검색, 클러스터링, 콘텐츠 기반 추천 시스템에 유용합니다.
확장성과 가용성 측면에서 Redis는 높은 처리량 작업 부하를 처리하는 데 탁월하며 데이터 복제 기능을 제공합니다. 또한 기존의 관계형 데이터베이스(RDBMS)를 포함한 다른 데이터 유형과도 잘 통합됩니다. Redis에는 실시간 업데이트를 위한 게시/구독(Pub/Sub) 기능이 포함되어 있어 실시간 벡터를 관리하는 데 유용합니다. 게다가 Redis는 가볍고 사용하기 간편하여 벡터 데이터를 관리하는 데 사용하기 편리한 솔루션입니다.
밀버스
MongoDB와 매우 비슷하게 문서 저장소와 같은 API를 제공하는 다용도 벡터 데이터베이스입니다. 다양한 데이터 유형을 지원한다는 점에서 두드러지며, 이로 인해 데이터 과학 및 머신 러닝 분야에서 인기 있는 선택이 되었습니다.
Milvus의 독특한 기능 중 하나는 다중 벡터화 기능으로, 사용자는 런타임에 검색에 사용할 벡터 유형을 지정할 수 있습니다. 더욱이 Faiss와 같은 다른 라이브러리 위에 있는 라이브러리인 Knowwhere를 활용하여 쿼리와 벡터 검색 알고리즘 간의 통신을 관리합니다.
Milvus는 PyTorch 및 TensorFlow와의 호환성 덕분에 머신 러닝 워크플로우와의 원활한 통합을 제공합니다. 이로 인해 이 도구는 전자상거래, 이미지 및 비디오 분석, 객체 인식, 이미지 유사성 검색, 콘텐츠 기반 이미지 검색을 포함한 다양한 응용 분야에 매우 적합합니다. 자연어 처리 분야에서 Milvus는 문서 클러스터링, 의미 검색, 질의응답 시스템에 사용됩니다.
이 솔루션의 경우, 솔루션 검증을 위해 milvus를 선택했습니다. 성능을 위해 milvus와 postgres(pgvecto.rs)를 모두 사용했습니다.
이 솔루션을 위해 왜 Milvus를 선택했을까요?
-
오픈 소스: Milvus는 커뮤니티 중심의 개발과 개선을 장려하는 오픈 소스 벡터 데이터베이스입니다.
-
AI 통합: 유사성 검색과 AI 애플리케이션을 내장하여 벡터 데이터베이스 기능을 강화합니다.
-
대용량 처리: Milvus는 딥 신경망(DNN) 및 머신 러닝(ML) 모델에서 생성된 10억 개 이상의 임베딩 벡터를 저장, 색인화하고 관리할 수 있는 역량을 갖추고 있습니다.
-
사용자 친화적: 사용하기 쉽고, 설정하는 데 1분도 걸리지 않습니다. Milvus는 또한 다양한 프로그래밍 언어에 대한 SDK를 제공합니다.
-
속도: 일부 대안보다 최대 10배 빠른 매우 빠른 검색 속도를 제공합니다.
-
확장성 및 가용성: Milvus는 필요에 따라 확장 및 축소할 수 있는 옵션을 갖추고 있어 확장성이 매우 뛰어납니다.
-
풍부한 기능: 다양한 데이터 유형, 속성 필터링, 사용자 정의 함수(UDF) 지원, 구성 가능한 일관성 수준 및 이동 시간을 지원하므로 다양한 애플리케이션에 적합한 다재다능한 도구입니다.
Milvus 아키텍처 개요
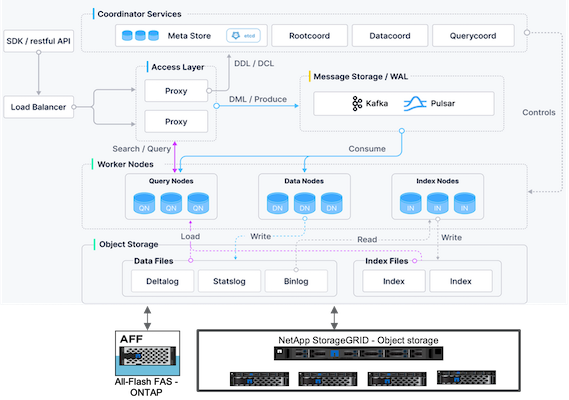
이 섹션에서는 Milvus 아키텍처에서 사용되는 상위 레벨 구성 요소와 서비스를 제공합니다. * 액세스 계층 – 상태 비저장 프록시 그룹으로 구성되며 시스템의 프런트 계층이자 사용자의 엔드포인트 역할을 합니다. * 코디네이터 서비스 – 작업자 노드에 작업을 할당하고 시스템의 두뇌 역할을 합니다. 세 가지 코디네이터 유형이 있습니다: 루트 좌표, 데이터 좌표, 쿼리 좌표. * 워커 노드: 코디네이터 서비스의 지시를 따르고 사용자가 트리거한 DML/DDL 명령을 실행합니다. 쿼리 노드, 데이터 노드, 인덱스 노드와 같이 세 가지 유형의 워커 노드가 있습니다. * 저장소: 데이터 지속성을 담당합니다. 여기에는 메타 스토리지, 로그 브로커, 객체 스토리지가 포함됩니다. ONTAP 및 StorageGRID 와 같은 NetApp 스토리지는 Milvus에 고객 데이터와 벡터 데이터베이스 데이터 모두를 위한 객체 스토리지와 파일 기반 스토리지를 제공합니다.