

Google Cloud NetApp Volumes를 사용하여 SQL Server Always On 가용성 그룹 구성
 변경 제안
변경 제안
Google Cloud NetApp Volumes iSCSI 블록 스토리지를 사용하여 단일 서브넷 내 Google Compute Engine 인스턴스에서 SQL Server Always On 가용성 그룹을 구성하는 방법을 알아보세요. 컴퓨팅 인스턴스 설정, NetApp 볼륨 구성, 장애 조치 클러스터링 설정, 고가용성 및 재해 복구를 위한 가용성 그룹 배포 방법을 설명합니다.
필수 조건
진행하기 전에 Google Cloud 문서에 나와 있는 구성 필수 단계를 완료하세요.
시작하기 전에
다음 요구 사항을 완료했는지 확인하십시오.
-
컴퓨팅, 네트워크, IAM 및 스토리지에 대한 관리자 권한이 있는 Google Cloud 프로젝트
-
리전 설정을 위한 서브넷이 있는 VPC 네트워크
-
지역에서 사용 가능한 Active Directory 및 DNS 설정
-
필요한 포트를 허용하도록 구성된 방화벽 규칙
-
SQL Server Always On 가용성 그룹 및 장애 조치 클러스터링에 대한 이해

|
새로운 Google Cloud 사용자는 "무료 평가판 크레딧"을(를) 받을 수 있습니다. |
목표
SQL Server Always On 가용성 그룹 구성에는 다음과 같은 주요 작업이 포함됩니다.
-
Compute Engine 인스턴스와 NetApp 스토리지 볼륨을 설정합니다.
-
두 노드 모두에 SQL Server를 설정합니다
-
Windows Server 장애 조치 클러스터 설정
-
파일 공유 감시자를 사용하여 클러스터 쿼럼 설정
-
SQL Server 가용성 그룹 설정
-
리스너 액세스를 위한 분산 네트워크 이름(DNN) 설정
비용 고려 사항
이 튜토리얼에서는 "Compute Engine 인스턴스" 및 "Google Cloud NetApp Volumes" 스토리지 등 Google Cloud의 유료 구성 요소를 사용합니다.
"가격 계산기"를 사용하여 컴퓨팅 및 스토리지 요구 사항에 따른 비용 추정치를 생성할 수 있습니다. 예시 구성은 SQL Server Always On 가용성 그룹 설정을 위해 N4-SKU 컴퓨팅 인스턴스와 NetApp Flex 서비스 수준 스토리지를 사용합니다.
도메인 계정 구성
Active Directory에 두 개의 계정을 구성합니다. 하나는 설치 계정(관리자 계정)이고 다른 하나는 두 SQL Server VM 모두에 대한 서비스 계정입니다.
예를 들어 계정에 다음 표의 값을 사용합니다.
|
|
이 예에서는 `cvsdemo`을(를) 도메인 이름으로 사용합니다. 이 절차 전체에서 `cvsdemo`을(를) 실제 도메인 이름으로 바꾸십시오. |
| 계정 | VM | 전체 도메인 이름 | 설명 |
|---|---|---|---|
<your account> |
둘 다(sqlnode1 및 sqlnode2) |
cvsdemo\DomainAdmin |
VM에 로그인하여 클러스터 및 가용성 그룹을 구성하는 관리자 계정 |
sqlsvc |
둘 다(sqlnode1 및 sqlnode2) |
cvsdemo\sqlsvc |
두 SQL Server VM 모두에서 SQL Server 및 SQL Server Agent에 대한 서비스 계정 |
SQL Server용 Compute Engine VM 생성
가용성 그룹 복제본을 호스팅하기 위해 Windows Server 2025에 SQL Server 2022 Enterprise가 사전 설치된 Google Compute Engine VM 인스턴스 두 개를 생성합니다.
-
Google Cloud 콘솔에서 "인스턴스 생성" 페이지로 이동합니다.
자세한 내용은 "Google Cloud 문서"를 참조하십시오.
-
*이름*에는 `sqlnode1`을 입력하세요.
-
시스템 구성 섹션에서:
-
*General Purpose*를 선택하세요
-
Series 목록에서 *N4*를 선택합니다
-
머신 유형 목록에서 *n4-highmem-8 (8 vCPU, 64 GB memory)*을 선택하십시오.
-
-
VPC를 생성한 리전을 선택합니다(예: region=us-west1, zone=us-west1-a).
-
부팅 디스크 섹션에서 *변경*을 클릭합니다.
-
공용 이미지 탭의 운영 체제 목록에서 *Windows Server의 SQL Server*를 선택합니다.
-
Version 목록에서 *SQL Server 2022 Enterprise on Windows Server 2025 Datacenter*를 선택합니다.
-
부팅 디스크 유형 목록에서 *Hyperdisk Balanced*를 선택합니다.
-
크기(GB) 필드에 50 GB를 입력하십시오.
-
*선택*을 클릭하여 부팅 디스크 구성을 저장합니다.
-
-
네트워킹 섹션에서 네트워크 인터페이스를 편집하여 올바른 VPC 및 서브넷을 선택하십시오. VPC 네트워크가 하나만 있는 경우 기본적으로 선택됩니다.
-
네트워크 인터페이스 카드에서 *gVNIC*를 선택하십시오.
-
"네트워크 서비스 계층"의 경우 중요 업무에는 *Premium*을, 비용 최적화에는 *Standard*를 선택하십시오.
-
-
VM을 생성하려면 *생성*을 클릭합니다.
-
다음 단계를 반복하여 `sqlnode2`을(를) 생성하십시오.
서버를 도메인에 연결합니다
VM을 생성한 후 Active Directory 도메인에 가입시키고 페일오버 클러스터링 및 iSCSI 연결에 필요한 Windows 기능을 설치하십시오.
-
로컬 관리자 계정으로 가상 시스템에 원격으로 연결합니다.
-
서버 관리자에서 *로컬 서버*를 선택하십시오.
-
WORKGROUP 링크를 선택합니다.
-
컴퓨터 이름 섹션에서 *변경*을 선택합니다.
-
도메인 확인란을 선택하고 텍스트 상자에 도메인(예:
cvsdemo.internal)을 입력하십시오. -
*확인*을 클릭합니다.
-
Windows 보안 대화 상자에서 기본 도메인 관리자 계정의 자격 증명을 지정합니다(예:
cvsdemo\DomainAdmin). -
"Welcome to the cvsdemo.internal domain" 메시지가 표시되면 *OK*를 클릭합니다.
-
*닫기*를 클릭한 다음 대화 상자에서 *지금 다시 시작*을 선택합니다.
-
서버가 재시작되면
sqlsvc계정을 Administrators 그룹에 추가하십시오.
|
|
SQL 인스턴스는 클러스터링 및 페일오버 설정에 필요한 sqlsvc 계정을 사용하여 실행됩니다. |
필요한 Windows 기능 설치
서버 관리자 또는 PowerShell을 사용하여 두 SQL Server VM에 장애 조치 클러스터링 및 MPIO를 설치합니다.
-
서버 관리자에서 관리 > *역할 및 기능 추가*를 선택합니다.
-
*역할 기반 또는 기능 기반 설치*를 선택하고 *다음*을 클릭합니다.
-
서버를 선택하고 *다음*을 클릭합니다.
-
Features 페이지에서 *Failover Clustering*과 *Multipath I/O*를 선택합니다.
-
관리 도구를 포함하라는 메시지가 나타나면 *기능 추가*를 클릭하십시오.
-
마법사를 완료하고 메시지가 표시되면 다시 시작하십시오.
PowerShell을 관리자 권한으로 실행하고 다음 명령을 실행하십시오.
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShelliSCSI 이니시에이터 이름을 가져옵니다.
iSCSI 이니시에이터 GUI 또는 PowerShell을 사용하여 호스트 그룹에 포함할 각 SQL Server VM의 iSCSI 정규화된 이름(IQN)을 가져옵니다.
-
Win+R 키를 누르거나 Windows 검색 표시줄을 사용하여 `iscsicpl`을(를) 엽니다.
-
iSCSI 이니시에이터 속성 대화 상자에서 구성 탭으로 이동합니다.
-
이니시에이터 이름 값을 복사하여 호스트 그룹에 포함시키세요.
예:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
PowerShell에서 다음 명령을 실행합니다.
Get-InitiatorPort | Select-Object NodeAddressNetApp 블록 스토리지 볼륨을 생성합니다
Google Cloud NetApp Volumes를 사용하여 iSCSI 블록 스토리지 볼륨을 생성하면 SQL Server 데이터베이스에 고성능 공유 스토리지를 제공할 수 있습니다. 이 과정에는 호스트 그룹, 스토리지 풀 그리고 데이터, 로그, 임시 및 백업용 개별 볼륨 생성이 포함됩니다.
호스트 그룹을 생성합니다
-
두 SQL 노드의 iSCSI 이니시에이터를 모두 포함하는 호스트 그룹을 생성합니다.
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTION자세한 내용은 "호스트 그룹을 생성합니다" 설명서를 참조하십시오.
-
다음 값을 바꾸십시오:
-
HOST_GROUP_NAME: 호스트 그룹의 이름(예:demosql) -
LOCATION: 지역(예:us-west1) -
HOSTS: sqlnode1과 sqlnode2의 IQN을 쉼표로 구분한 목록예:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE: 운영 체제 유형(예:WINDOWS) -
DESCRIPTION: 호스트 그룹에 대한 선택적 설명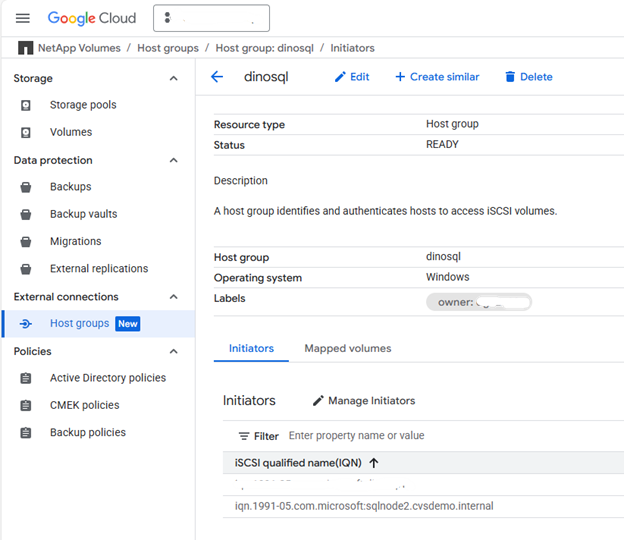
-
스토리지 풀 생성
-
적절한 용량과 성능을 갖춘 스토리지 풀을 생성합니다.
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGE자세한 내용은 "스토리지 풀 생성" 설명서를 참조하십시오.
-
다음 값을 바꾸십시오:
-
POOL_NAME: 풀 이름(예:sqltest) -
PROJECT_ID: Google Cloud 프로젝트 이름 -
LOCATION: 컴퓨팅 인스턴스와 동일한 위치(예:us-west1-b) -
CAPACITY: 풀 용량(GiB) (예:1024) -
SERVICE_LEVEL: 서비스 수준(예:Flex) -
VPC_NAME: VPC 네트워크 이름 -
PSA_RANGE: Private Services Access 범위(예:xx.xxx.xxx.0/20) -
THROUGHPUT: MiBps 단위의 선택적 처리량(예:64) -
IOPS: 선택적 IOPS(예:1024)
-
볼륨 생성
-
데이터, 로그, 임시 및 백업용 볼륨을 생성합니다. 각 볼륨 유형에 대해 다음 명령을 실행하십시오.
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=false자세한 내용은 "볼륨을 생성합니다" 설명서를 참조하십시오.
-
다음 값을 바꾸십시오:
-
VOLUME_NAME: 각 볼륨의 고유한 이름(예:node1data,node1log,node1temp,node1backup) -
PROJECT_ID: Google Cloud 프로젝트 이름 -
LOCATION: 스토리지 풀과 동일한 위치(예:us-west1-b) -
POOL_NAME: 스토리지 풀 이름(예:sqltest) -
CAPACITY: GiB 단위의 볼륨 용량(예:200) -
HOST_GROUP_PATH: 호스트 그룹에 대한 전체 리소스 경로(예:projects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
여러 호스트 그룹을 # 기호로 구분하여 지정할 수 있습니다. |
|
|
데이터, 로그, 임시 및 백업 등 각 볼륨 유형에 대해 이 단계를 반복하십시오. |
iSCSI 볼륨 마운트
각 SQL 인스턴스에 공유되지 않는 iSCSI 볼륨을 마운트합니다.
-
Google Cloud 콘솔에서 NetApp 볼륨 > *볼륨*으로 이동합니다.
-
SQL 인스턴스에 대해 생성된 볼륨을 선택합니다(예:
node1data). -
iSCSI 타겟의 두 IP 주소를 복사합니다(예:
10.165.128.216및10.165.128.217). -
sqlnode1에서 `iscsicpl`을 실행하거나 PowerShell을 사용합니다.
-
Discover 탭을 클릭한 다음 *Discover Portal*을 클릭합니다.
-
획득한 각 IP 주소를 추가하고 기본 포트 3260은 그대로 두십시오.
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }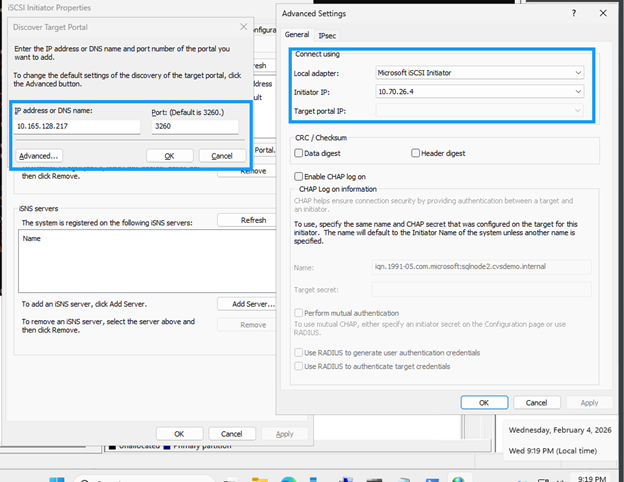
-
대상에 연결 대화 상자에서 다중 경로를 사용하는 경우 *다중 경로 사용*을 선택하십시오.
-
*고급*을 클릭하고 드롭다운에서 타겟 포털 IP를 선택합니다.
-
*확인*을 클릭하여 연결합니다.
-
iSCSI 디바이스에 대한 MPIO 구성
-
제어판 또는 서버 관리자에서 MPIO를 엽니다.
-
다중 경로 검색 탭을 클릭합니다.
-
* iSCSI 장치 지원 추가 * 를 선택하고 * 추가 * 를 클릭하십시오.
-
메시지가 표시되면 재부팅합니다.
-
*디스크 드라이브*에서 장치 관리자의 다중 경로 구성을 확인하십시오.
-
-
볼륨 초기화 및 포맷
-
컴퓨터 관리(`compmgmt.msc`를 실행하고 *디스크 관리*를 선택하십시오.
-
각 디스크를 64K 할당 단위로 초기화, 파티션 및 포맷합니다.
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
드라이브 문자를 할당합니다(예: Data용 D:, Log용 E:, Backup용 F:, Temp용 G:).
-
SQL Server용 디렉터리 구조를 생성합니다.
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
SQL Server 구성
두 노드 모두에서 SQL Server가 도메인 서비스 계정을 사용하도록 구성하고, 기본 경로를 NetApp 볼륨을 사용하도록 업데이트하고, 시스템 데이터베이스를 새 스토리지 위치로 이동합니다.
-
클러스터 인증 및 페일오버 지원을 위해 SQL Server 및 SQL Server Agent 서비스가 도메인 서비스 계정으로 실행되도록 업데이트하십시오.
-
각 SQL 인스턴스에서 `services.msc`을(를) 엽니다.
-
SQL Server 및 SQL Server Agent 서비스의 *Log on as*를 `domain\sqlsvc`로 업데이트하세요.
-
SQL Server Management Studio(SSMS)를 열고 도메인 계정으로 연결합니다.
연결에 실패하면 SSMS를 `<local computer>\Administrator`로 실행하십시오. 사용자 및 그룹에서 Administrator 계정이 적절한 암호로 활성화되어 있는지 확인하십시오.
-
-
필요한 권한을 가진 도메인 계정 로그인을 생성합니다.
다음 SQL 명령에서 `CVSDEMO`을(를) 실제 도메인 이름으로 바꾸십시오. USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
기본 경로를 OS 드라이브 대신 NetApp 볼륨을 사용하도록 업데이트하십시오.
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
시스템 데이터베이스(model, msdb, tempdb 및 master)를 운영 체제 드라이브에서 NetApp 볼륨으로 이동하여 성능과 관리를 개선하십시오.
-
현재 경로를 확인하십시오.
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
새로운 위치로 업데이트:
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
SQL Server를 중지하고, 파일을 이전 위치에서 새 경로로 수동으로 이동한 다음 SQL Server를 다시 시작하십시오.
-
tempdb 데이터베이스 이동
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
변경 사항을 적용하려면 SQL Server를 다시 시작하십시오.
Restart-Service -Name "MSSQLSERVER" -Force
-
-
마스터 데이터베이스 이동
-
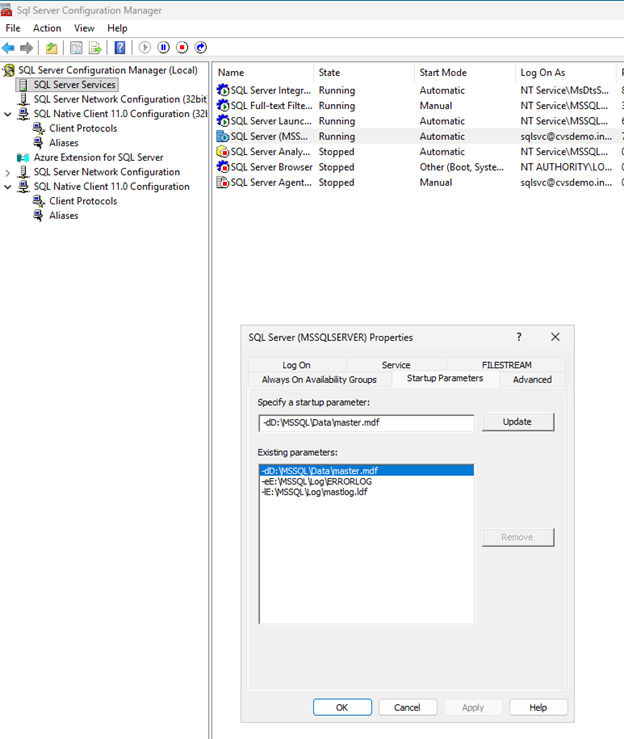
*SQL Server 구성 매니저*를 엽니다.
-
*SQL Server Services*로 이동하여 *SQL Server (MSSQLSERVER)*를 마우스 오른쪽 버튼으로 클릭하고 *Properties*를 선택합니다.
-
시작 매개변수 탭을 클릭합니다.
-
*기존 매개변수*에서
-d,-e및 `-l`로 시작하는 매개변수를 찾습니다. -
기존 매개변수를 제거하고 새 매개변수를 추가합니다.
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG
-
*확인*을 클릭합니다.
-
-
SQL Server 서비스를 중지합니다.
-
`master.mdf`와 `mastlog.ldf`를 이전 위치에서 새 경로로 수동으로 이동합니다.
-
오류 로그 경로를 업데이트했다면
ERRORLOG파일도 함께 이동하십시오. -
SQL Server 서비스를 시작합니다.
장애 조치 클러스터 설정
SQL Server의 고가용성을 제공하기 위해 Windows Server 장애 조치 클러스터링을 설정하십시오. 자세한 내용은 "Windows Server 장애 조치 클러스터링 설명서"을 참조하십시오.
방화벽 규칙 구성
클러스터 통신, SQL Server 연결 및 가용성 그룹 복제를 활성화하려면 두 SQL 노드 모두에서 필요한 네트워크 포트를 엽니다.
-
클러스터 통신을 위해 두 SQL 노드 모두에서 필요한 포트를 엽니다.
필수 포트는 UDP 3343, TCP 3343, TCP 1433, TCP 5022, TCP 135, TCP 445, TCP 49152-65535(동적 RPC)입니다.
-
방화벽을 통해 SQL Server와 클러스터 통신을 허용하려면 두 서버 모두에서 다음 체크포인트를 실행하십시오.
사용자 지정 구성이 있는 경우 포트 번호를 조정하십시오.
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022자세한 방화벽 요구 사항은 "Windows Server 서비스 및 네트워크 포트 요구 사항"을(를) 참조하십시오.
-
클러스터를 생성하기 전에 두 노드 모두에서 유효성 검사를 실행하십시오.
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
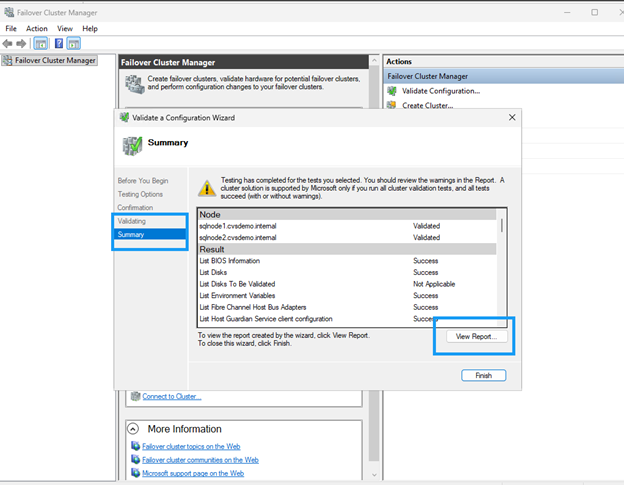
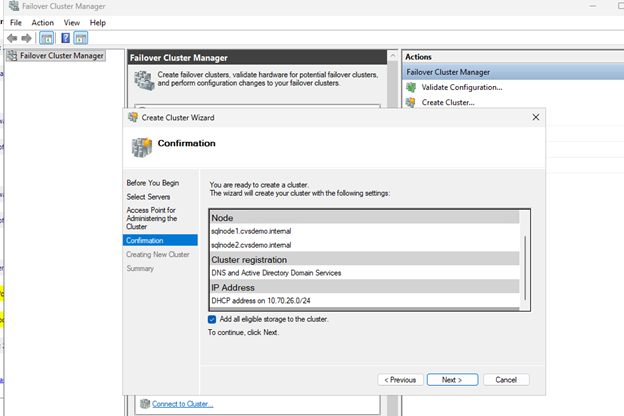
페일오버 클러스터를 생성합니다
고가용성 및 자동 페일오버 기능을 사용하도록 설정하려면 두 SQL Server 노드를 모두 사용하여 Windows Server Failover Cluster를 생성합니다.
-
서버 관리자에서 페일오버 클러스터 관리자를 실행 `cluadmin.msc`하거나 엽니다.
-
*클러스터 생성*을 선택합니다.
-
두 SQL 노드(sqlnode1, sqlnode2)를 모두 추가합니다.
-
유효성 검사를 실행하고 모든 검사가 통과하는지 확인하십시오. 진행하기 전에 모든 경고 사항을 검토하고 수정하십시오.
-
클러스터 이름을 제공합니다(예:
sqlcluwest1). -
클러스터 생성을 완료합니다.
파일 공유 감시자를 사용하여 클러스터 쿼럼 구성
2노드 클러스터 구성에서 쿼럼을 유지하기 위해 파일 공유 감시를 구성합니다. 감시 서버는 추가 투표권을 제공하여 스플릿 브레인 시나리오를 방지하고 클러스터 가용성을 보장합니다.
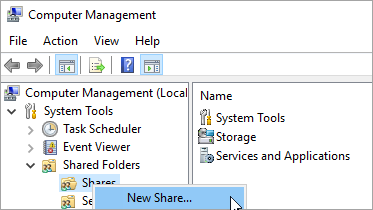
파일 공유 생성
네트워크 연결이 가능하고 동일한 Active Directory 도메인 내에 있는 다른 영역 또는 지역의 VM에 파일 공유를 생성합니다.
-
파일 공유 감시 서버 VM에 연결합니다.
-
서버 관리자에서 도구 > *컴퓨터 관리*를 선택합니다.
-
*공유 폴더*를 선택하고 *공유*를 마우스 오른쪽 버튼으로 클릭한 다음 *새 공유*를 선택합니다.
-
*공유 폴더 만들기 마법사*를 사용하여 공유를 생성합니다
\\servername\share. -
폴더 경로 페이지에서 *찾아보기*를 선택합니다.
-
공유 폴더의 경로를 찾거나 생성한 다음 *다음*을 선택합니다.
-
Name, Description, and Settings 페이지에서 공유 이름과 경로를 확인한 다음 *Next*를 선택합니다.
-
공유 폴더 권한 페이지에서 *권한 사용자 지정*을 선택하고 *사용자 지정*을 클릭합니다
-
권한 사용자 지정 대화 상자에서 *추가*를 선택하여 클러스터 계정을 추가합니다.
클러스터를 생성하는 데 사용되는 계정(sqlcluwest1$)에 모든 권한이 있는지 확인합니다.
-
권한을 저장하려면 *확인*을 클릭합니다.
-
공유 폴더 권한 페이지에서 *완료*를 선택한 다음 *완료*를 다시 선택합니다.
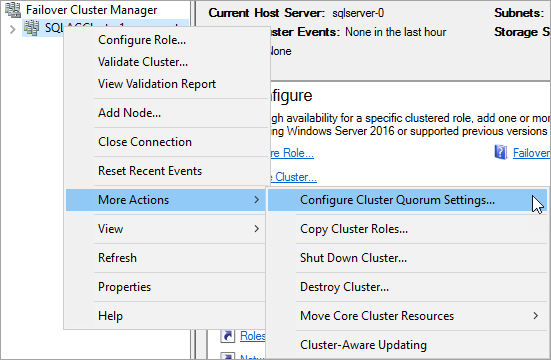
쿼럼 설정 구성
클러스터가 쿼럼 투표에 파일 공유 감시를 사용하도록 구성합니다.
-
페일오버 클러스터 관리자에서 클러스터를 마우스 오른쪽 버튼으로 클릭하고 추가 작업 > *클러스터 쿼럼 설정 구성*을 선택합니다.
-
클러스터 쿼럼 구성 마법사에서 *다음*을 클릭합니다.
-
Select Quorum Configuration 페이지에서 *Select the quorum witness*를 선택하고 *Next*를 클릭합니다.
-
쿼럼 증인 선택 페이지에서 *파일 공유 증인 구성*을 선택합니다.
-
파일 공유 감시 구성 페이지에서 *파일 공유 감시 구성*을 선택합니다.
-
생성한 공유의 경로를 입력하고(예:
\\servername\share) *다음*을 클릭합니다. -
확인 페이지에서 설정을 확인하고 *다음*을 클릭합니다.
-
*완료*를 클릭합니다.
이제 클러스터 코어 리소스에 파일 공유 감시자가 구성되었습니다.
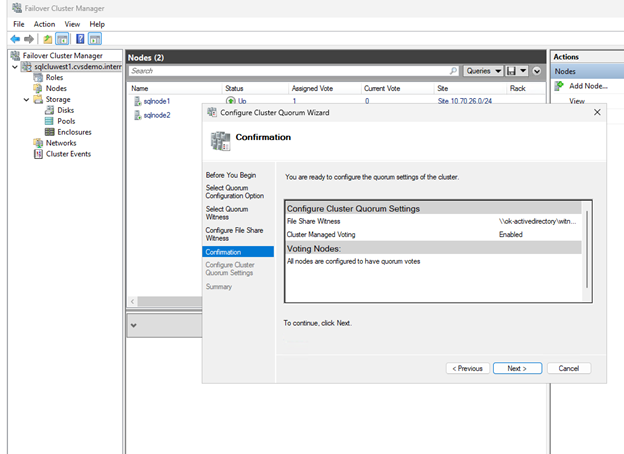
Always On 가용성 그룹 활성화
두 SQL Server VM 모두에서 Always On 가용성 그룹을 활성화합니다.
-
시작 메뉴에서 *SQL Server 구성 매니저*를 엽니다.
-
브라우저 트리에서 *SQL Server Services*를 선택합니다.
-
*SQL Server (MSSQLSERVER)*를 마우스 오른쪽 버튼으로 클릭하고 *속성*을 선택합니다.
-
Always On High Availability 탭을 선택합니다.
-
*Always On 가용성 그룹 활성화*를 선택합니다.
-
*적용*을 클릭한 다음 메시지가 표시되면 SQL Server 서비스를 다시 시작합니다.
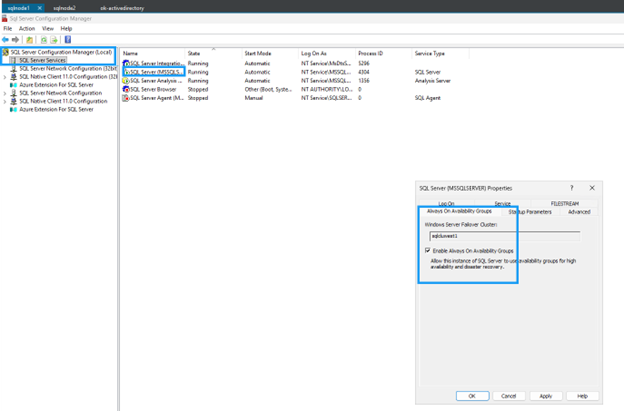
-
두 번째 SQL Server 인스턴스에 대해 반복합니다.
첫 번째 SQL Server 인스턴스에 데이터베이스를 생성합니다
첫 번째 SQL Server 인스턴스에 데이터베이스를 생성합니다.
-
sysadmin 고정 서버 역할의 구성원인 도메인 계정으로 첫 번째 SQL Server VM에 연결합니다.
-
SQL Server Management Studio를 열고 첫 번째 SQL Server 인스턴스에 연결합니다.
-
*Object Explorer*에서 *Databases*를 마우스 오른쪽 버튼으로 클릭하고 *New Database*를 선택합니다.
-
데이터베이스 이름(예:
MyDB1)을 입력하고 *확인*을 클릭합니다. -
데이터베이스 복구 모드를 Full로 설정하십시오.
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
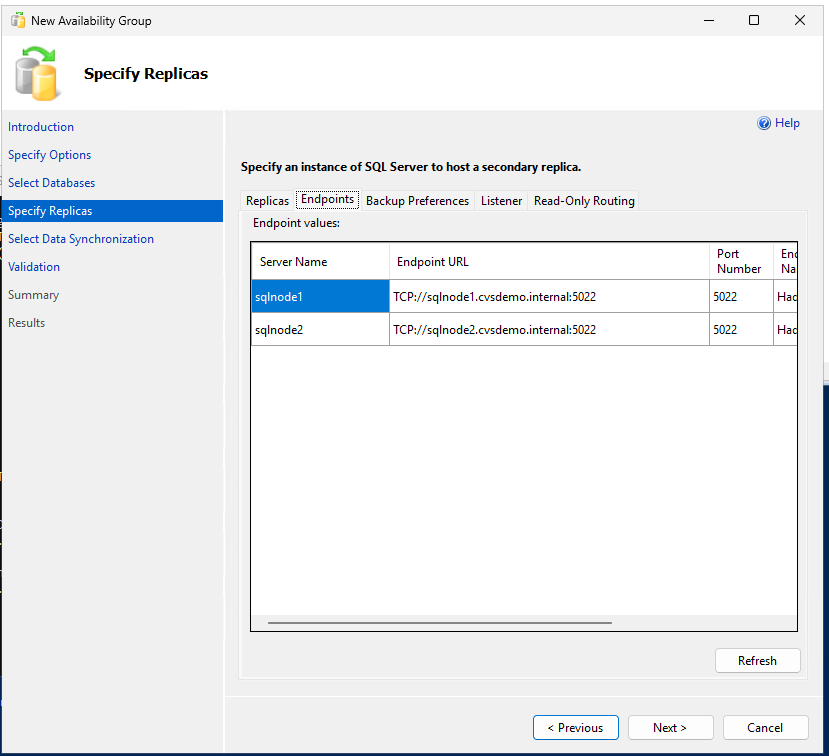
가용성 그룹 생성 및 구성
SQL Server 데이터베이스에 고가용성을 제공하기 위해 동기식 커밋 및 자동 페일오버 기능을 갖춘 Always On 가용성 그룹을 생성하십시오.
-
데이터베이스의 전체 백업과 트랜잭션 로그 백업을 모두 수행하십시오.
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
백업 파일을 두 번째 SQL Server 인스턴스로 복사한 다음 NORECOVERY를 사용하여 복원합니다.
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
동기식 커밋, 자동 페일오버 및 읽기 가능한 보조 복제본을 사용하여 가용성 그룹을 생성합니다.
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
가용성 그룹 마법사를 사용하여 가용성 그룹을 생성합니다.
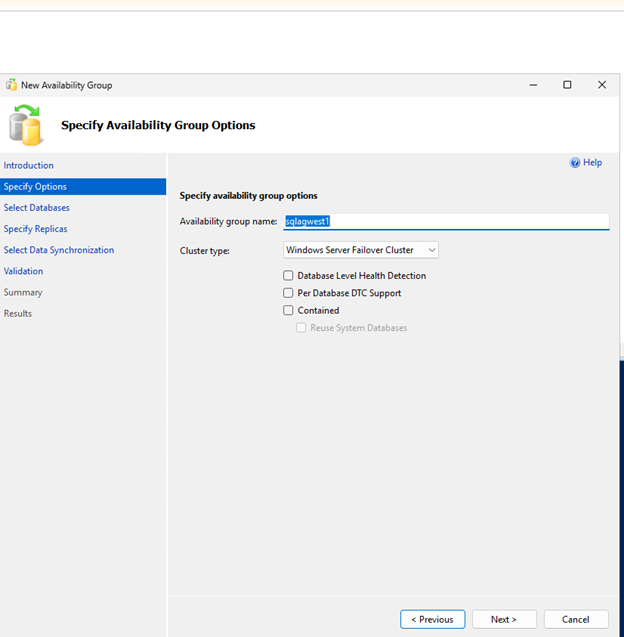
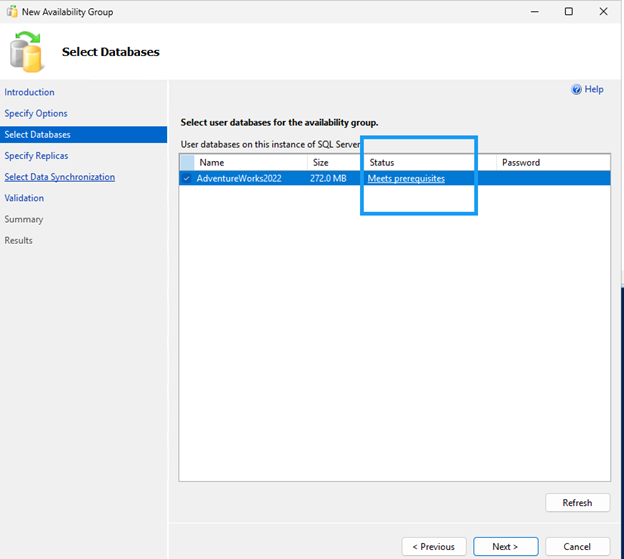

두 SQL 노드 모두에서 방화벽 포트 5022가 허용되어 있는지 확인하십시오. 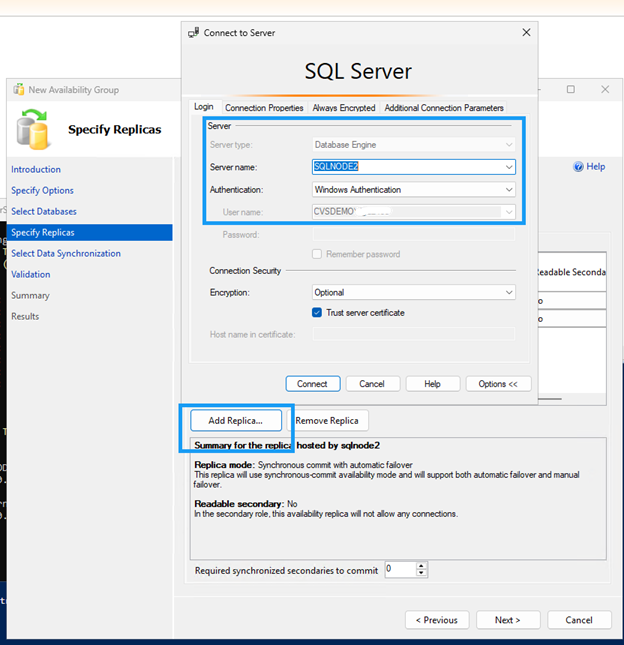
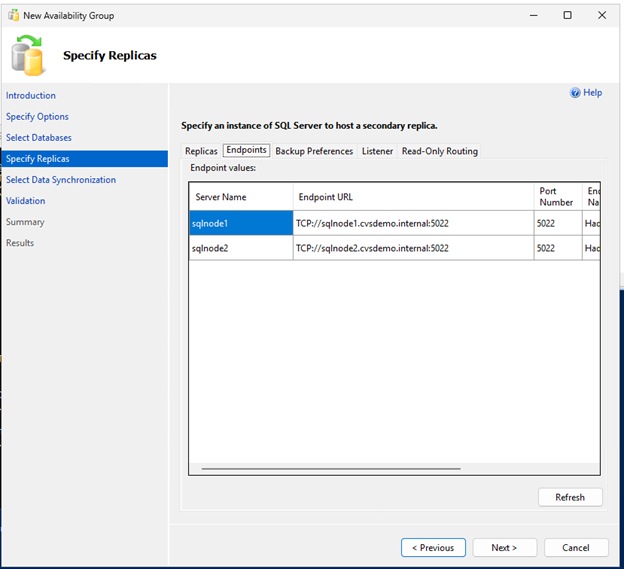
DNN 리스너 리소스 생성
로드 밸런서 없이도 트래픽을 적절한 클러스터 리소스로 라우팅할 수 있도록 DNN(Distributed Network Name) 리스너를 생성합니다.
PowerShell을 사용하여 DNN 리소스를 생성합니다.
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"가능한 소유자 구성
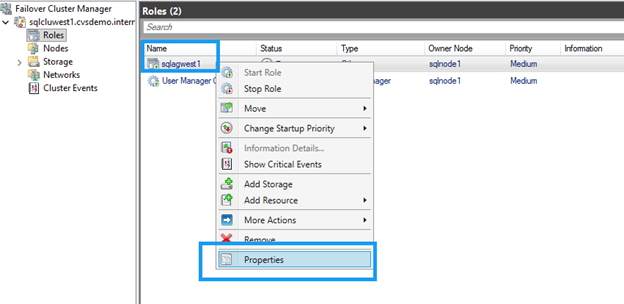
기본적으로 클러스터는 DNN DNS 이름을 모든 노드에 바인딩합니다. 가용성 그룹에 참여하지 않는 노드는 제외하십시오.
-
페일오버 클러스터 관리자에서 DNN 리소스를 찾습니다.
-
DNN 리소스를 마우스 오른쪽 버튼으로 클릭하고 *속성*을 선택합니다.
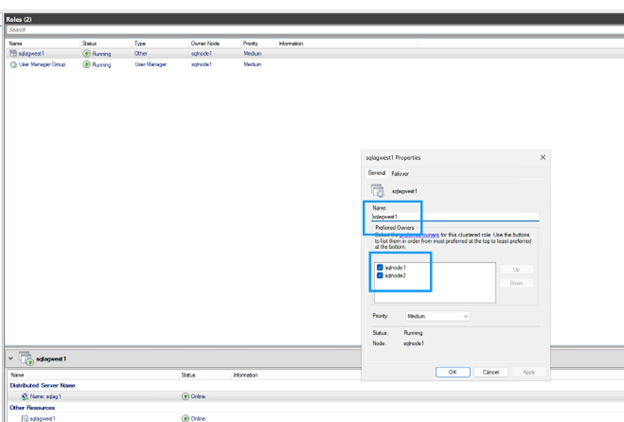
-
가용성 그룹에 참여하지 않는 노드의 확인란을 선택 해제하십시오.
-
설정을 저장하려면 *확인*을 클릭합니다.
애플리케이션 연결 문자열 업데이트
DNN 리스너 이름을 사용하고 MultiSubnetFailover=True 매개변수를 포함하도록 연결 문자열을 업데이트하세요.
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
클라이언트가 MultiSubnetFailover 매개변수를 지원하지 않으면 DNN과 호환되지 않습니다. |
페일오버 테스트
가용성 그룹 구성을 확인하고 페일오버를 테스트하여 노드 간 자동 페일오버가 올바르게 작동하는지 확인하십시오.
-
복제본에서 다음 명령을 실행하여 가용성 그룹 구성을 확인합니다.
두 복제본 모두 가용성 모드에 대해 `SYNCHRONOUS_COMMIT`를 표시하고 페일오버 모드에 대해 `AUTOMATIC`를 표시해야 하며, 이를 통해 자동 페일오버 중에 데이터 손실이 발생하지 않습니다.
SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');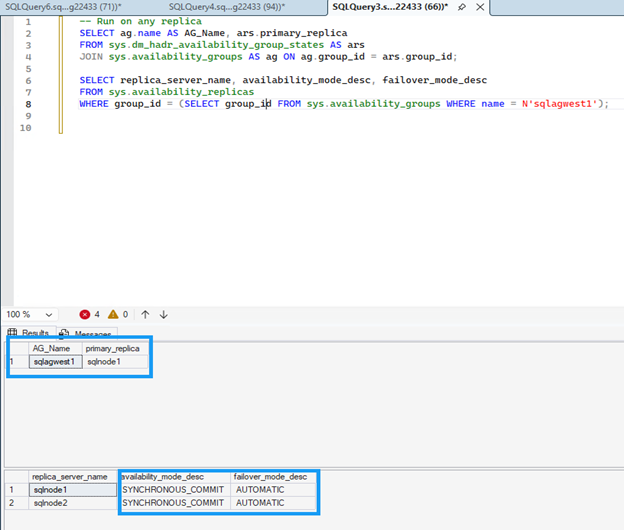
-
페일오버를 시작하려면 보조 노드에서 다음 명령을 실행하십시오.
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
연결 대상이 새 기본 대상으로 전환되었는지 확인합니다.
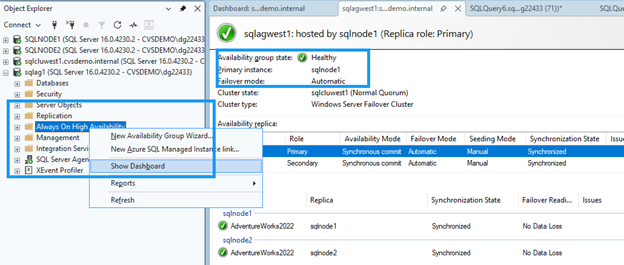
-- SELECT @@SERVERNAME AS NowPrimary;SSMS에서 가용성 그룹 노드를 확장하고 *Always On High Availability*를 마우스 오른쪽 버튼으로 클릭한 다음 *대시보드 표시*를 선택합니다.
대시보드에는 두 노드 모두 정상 상태로 표시되고 페일오버가 확인되어야 합니다.
리소스 정리
튜토리얼을 완료한 후에는 추가 요금이 발생하지 않도록 생성한 리소스를 삭제하세요.
-
Compute Engine 인스턴스(sqlnode1, sqlnode2) 삭제
-
Google Cloud NetApp Volumes(볼륨, 스토리지 풀, 호스트 그룹) 삭제
-
이 튜토리얼을 위해 특별히 생성된 경우 VPC 및 네트워킹 리소스를 삭제합니다
-
해당되는 경우 파일 공유 감시 서버 삭제
리소스 삭제에 대한 자세한 단계는 "Google Cloud NetApp Volumes 설명서" 및 "Google Compute Engine 문서"를 참조하십시오.
추가 정보를 찾을 수 있는 곳
NetApp 스토리지를 사용하는 Google Cloud의 SQL Server에 대한 자세한 내용은 다음 문서를 참조하십시오.