

운영 모범 사례
 변경 제안
변경 제안
다음 섹션에서는 VMware SRM 및 ONTAP 스토리지에 대한 운영 Best Practice를 간략히 설명합니다.
데이터 저장소 및 프로토콜
-
가능하면 항상 ONTAP 툴을 사용하여 데이터 저장소와 볼륨을 프로비저닝하십시오. 이렇게 하면 볼륨, 접합 경로, LUN, igroup, 엑스포트 정책이 및 기타 설정은 호환되는 방식으로 구성됩니다.
-
SRM은 SRA를 통해 어레이 기반 복제를 사용할 때 ONTAP 9를 통해 iSCSI, 파이버 채널 및 NFS 버전 3을 지원합니다. SRM은 기존 데이터 저장소 또는 VVOL 데이터 저장소를 사용하는 NFS 버전 4.1에 대한 어레이 기반 복제를 지원하지 않습니다.
-
접속을 확인하려면 항상 대상 ONTAP 클러스터에서 DR 사이트의 새 테스트 데이터 저장소를 마운트하고 마운트 해제할 수 있는지 확인하십시오. 데이터 저장소 연결에 사용할 각 프로토콜을 테스트합니다. 모범 사례는 ONTAP 툴을 사용하여 테스트 데이터 저장소를 생성하는 것입니다. 이는 SRM의 지시에 따라 모든 데이터 저장소 자동화를 수행하기 때문입니다.
-
SAN 프로토콜은 각 사이트에서 동종이어야 합니다. NFS와 SAN을 혼합할 수 있지만 SAN 프로토콜을 사이트 내에서 혼합하면 안 됩니다. 예를 들어, 사이트 A에는 FCP를, 사이트 B에는 iSCSI를 사용할 수 있습니다. 사이트 A에서는 FCP와 iSCSI를 모두 사용하면 안 됩니다
-
이전 가이드에서는 데이터 지역성에 LIF를 생성하는 것이 권장되었습니다. 다시 말해, 볼륨을 물리적으로 소유한 노드에 있는 LIF를 사용하여 데이터 저장소를 항상 마운트합니다. 이것이 모범 사례이기는 하지만, 최신 버전의 ONTAP 9에서는 더 이상 필요하지 않습니다. 가능한 한 언제든지, 클러스터 범위 자격 증명이 있을 경우 ONTAP 툴은 데이터를 로컬에 있는 LIF 간 로드 밸런싱을 계속 선택하지만 고가용성 또는 성능이 필요하지 않습니다.
-
자동 크기 조정이 필요한 비상 용량을 충분히 제공할 수 없는 경우 공간이 부족한 경우 가동 시간을 유지하기 위해 스냅샷을 자동으로 제거하도록 ONTAP 9를 구성할 수 있습니다. 이 기능의 기본 설정은 SnapMirror에 의해 생성된 스냅샷을 자동으로 삭제하지 않습니다. SnapMirror 스냅샷이 삭제된 경우 NetApp SRA는 영향을 받는 볼륨에 대해 복제를 역순으로 재동기화할 수 없습니다. ONTAP가 SnapMirror 스냅샷을 삭제하지 못하도록 하려면 스냅샷 자동 삭제 기능을 '시도'로 구성합니다.
snap autodelete modify -volume -commitment try
-
SAN 데이터 저장소가 포함된 볼륨 및 NFS 데이터 저장소에 대해
grow_shrink볼륨 자동 크기 조정을 로grow설정해야 합니다. 이 주제에 대한 자세한 내용은 을 "크기를 자동으로 확대 및 축소하도록 볼륨을 구성합니다"참조하십시오. -
SRM은 데이터 저장소 수를 최소화하여 복구 계획에서 보호 그룹을 최소화할 때 가장 잘 작동합니다. 따라서 RTO가 중요한 SRM 보호 환경에서 VM 밀도 최적화를 고려해야 합니다.
-
DRS(Distributed Resource Scheduler)를 사용하여 보호 및 복구 ESXi 클러스터의 로드 균형을 조정합니다. 페일백을 계획하는 경우 재보호 를 실행하면 이전에 보호된 클러스터가 새 복구 클러스터가 됩니다. DRS는 양방향으로 진행되는 배치의 균형을 유지하는 데 도움이 됩니다.
-
가능하면 SRM에서 IP 사용자 지정을 사용하지 마십시오. 이렇게 하면 RTO가 증가할 수 있습니다.
스토리지 쌍 정보
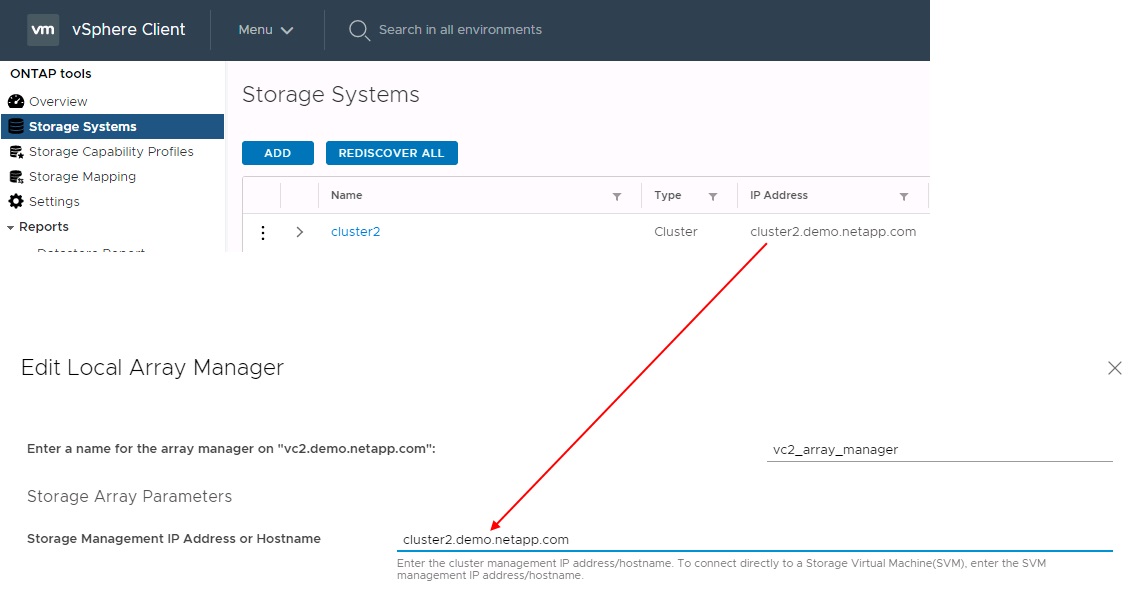
각 스토리지 쌍에 대해 스토리지 관리자가 생성됩니다. SRM 및 ONTAP 툴을 사용하면 클러스터 자격 증명을 사용해도 SVM의 범위에서 각 어레이 페어링을 수행할 수 있습니다. 따라서 각 테넌트가 관리하기 위해 할당된 SVM에 따라 테넌트 간에 DR 워크플로우를 분할할 수 있습니다. 특정 클러스터에 대해 여러 어레이 관리자를 생성할 수 있으며 비대칭적일 수 있습니다. 서로 다른 ONTAP 9 클러스터 간에 팬아웃 또는 팬할 수 있습니다. 예를 들어, 클러스터 1의 SVM-A 및 SVM-B를 클러스터 2의 SVM-C, 클러스터 3의 SVM-D 또는 그 반대로 복제할 수 있습니다.
SRM에서 어레이 쌍을 구성할 때는 항상 ONTAP 툴에 추가한 것과 같은 방법으로 SRM에 어레이 쌍을 추가해야 합니다. 즉, 이들은 동일한 사용자 이름, 암호 및 관리 LIF를 사용해야 합니다. 이 요구 사항은 SRA가 어레이와 제대로 통신하도록 보장합니다. 다음 스크린샷은 ONTAP 툴에 클러스터가 표시되는 방식과 이를 어레이 관리자에 추가하는 방법을 보여 줍니다.
복제 그룹 정보
복제 그룹에는 함께 복구되는 가상 머신의 논리적 컬렉션이 포함됩니다. ONTAP SnapMirror 복제는 볼륨 레벨에서 수행되기 때문에 볼륨의 모든 VM이 동일한 복제 그룹에 속해 있습니다.
복제 그룹과 FlexVol 볼륨 간에 VM을 배포하는 방법은 여러 가지 요소를 고려해야 합니다. 동일한 볼륨에서 유사한 VM을 그룹화하면 집계 수준 중복 제거 기능이 없는 기존 ONTAP 시스템에서 스토리지 효율성이 향상될 수 있지만 그룹화하면 볼륨 크기가 증가하고 볼륨 I/O 동시성이 줄어듭니다. 최신 ONTAP 시스템에서는 동일한 애그리게이트의 FlexVol 볼륨에 VM을 분산하여 애그리게이트 레벨 중복제거를 활용하고 여러 볼륨에서 더 많은 I/O 병렬화를 수행하여 성능과 스토리지 효율성의 균형을 최적으로 유지할 수 있습니다. 아래에 설명된 보호 그룹에 여러 복제 그룹이 포함될 수 있으므로 볼륨에서 VM을 함께 복구할 수 있습니다. 이 레이아웃의 단점은 SnapMirror가 애그리게이트 중복제거 기능을 고려하지 않기 때문에 블록을 유선으로 여러 번 전송할 수 있다는 것입니다.
복제 그룹에 대한 마지막 고려 사항은 각 그룹이 기본적으로 논리적 정합성 보장 그룹이라는 점입니다(SRM 정합성 보장 그룹과 혼동하지 마십시오). 볼륨의 모든 VM이 동일한 스냅샷을 사용하여 함께 전송되기 때문입니다. 따라서 VM이 서로 일치해야 하는 경우 동일한 FlexVol에 VM을 저장하는 것이 좋습니다.
보호 그룹 정보
보호 그룹은 보호 사이트에서 함께 복구되는 그룹으로 VM 및 데이터 저장소를 정의합니다. 보호 사이트는 정상적인 정상 상태 작업 중에 보호 그룹에 구성된 VM이 존재하는 곳입니다. SRM이 보호 그룹에 대해 여러 스토리지 관리자를 표시할 수 있지만 보호 그룹은 여러 스토리지 관리자를 포괄할 수 없습니다. 따라서 서로 다른 SVM의 데이터 저장소에 VM 파일을 확장해서는 안 됩니다.
복구 계획에 대해 설명합니다
복구 계획은 동일한 프로세스에서 복구할 보호 그룹을 정의합니다. 동일한 복구 계획에서 여러 보호 그룹을 구성할 수 있습니다. 또한 복구 계획 실행을 위한 추가 옵션을 사용하기 위해 단일 보호 그룹을 여러 복구 계획에 포함할 수 있습니다.
복구 계획을 사용하면 SRM 관리자가 우선 순위 그룹에 VM을 1(가장 높음)에서 5(가장 낮음)까지 할당하고 3(중간)을 기본값으로 지정하여 복구 워크플로를 정의할 수 있습니다. 우선 순위 그룹 내에서 VM을 종속성에 맞게 구성할 수 있습니다.
예를 들어, 데이터베이스에 Microsoft SQL Server를 사용하는 계층 1 비즈니스 크리티컬 애플리케이션을 가질 수 있습니다. 따라서 우선 순위 그룹 1에 VM을 배치하기로 결정합니다. 우선 순위 그룹 1 내에서 서비스를 가져오기 위한 주문 계획을 시작합니다. Microsoft Windows 도메인 컨트롤러를 Microsoft SQL Server보다 먼저 부팅하고, 응용 프로그램 서버보다 먼저 온라인 상태여야 하는 경우가 있습니다. 이러한 모든 VM을 우선 순위 그룹에 추가한 다음 종속성이 지정된 우선 순위 그룹 내에서만 적용되기 때문에 종속성을 설정합니다.
NetApp은 애플리케이션 팀과 협력하여 페일오버 시나리오에 필요한 운영 순서를 파악하고 그에 따라 복구 계획을 수립하는 것이 좋습니다.
테스트 대체 작동
가장 좋은 방법은 보호된 VM 스토리지의 구성이 변경될 때마다 항상 테스트 대체 작동을 수행하는 것입니다. 이렇게 하면 재해 발생 시 Site Recovery Manager가 예상 RTO 목표 내에서 서비스를 복구할 수 있다는 것을 신뢰할 수 있습니다.
또한, 특히 VM 스토리지를 재구성한 후에는 게스트 내 애플리케이션 기능을 확인하는 것이 좋습니다.
테스트 복구 작업이 수행되면 VM에 대한 전용 테스트 버블 네트워크가 ESXi 호스트에 생성됩니다. 그러나 이 네트워크는 물리적 네트워크 어댑터에 자동으로 연결되지 않으므로 ESXi 호스트 간에 연결을 제공하지 않습니다. DR 테스트 중에 서로 다른 ESXi 호스트에서 실행 중인 VM 간의 통신을 허용하기 위해 DR 사이트의 ESXi 호스트 간에 물리적 전용 네트워크가 생성됩니다. 테스트 네트워크가 전용인지 확인하기 위해 테스트 버블 네트워크를 물리적으로 또는 VLAN 또는 VLAN 태깅을 사용하여 분리할 수 있습니다. VM이 복구될 때 실제 운영 시스템과 충돌할 수 있는 IP 주소를 사용하여 운영 네트워크에 배치할 수 없으므로 이 네트워크를 운영 네트워크와 분리해야 합니다. SRM에서 복구 계획을 생성할 때 생성된 테스트 네트워크를 테스트 중에 VM을 연결할 전용 네트워크로 선택할 수 있습니다.
테스트를 검증하고 더 이상 필요하지 않은 후에는 정리 작업을 수행합니다. 정리 작업을 실행하면 보호된 VM이 초기 상태로 돌아가고 복구 계획이 준비 상태로 재설정됩니다.
페일오버 고려 사항
이 가이드에 언급된 작업 순서 외에 사이트 장애 조치 시 몇 가지 다른 고려 사항이 있습니다.
사이트 간 네트워크 차이는 문제가 될 수 있습니다. 일부 환경에서는 운영 사이트와 DR 사이트 모두에서 동일한 네트워크 IP 주소를 사용할 수 있습니다. 이러한 기능을 확장 가상 LAN(VLAN) 또는 확장 네트워크 설정이라고 합니다. 다른 환경에서는 DR 사이트와 관련하여 운영 사이트에서 서로 다른 네트워크 IP 주소(예: VLAN)를 사용해야 할 수 있습니다.
VMware는 이 문제를 해결할 수 있는 여러 가지 방법을 제공합니다. VMware NSX-T Data Center와 같은 네트워크 가상화 기술은 운영 환경의 계층 2에서 계층 7까지 전체 네트워킹 스택을 추상화하여 보다 휴대성이 뛰어난 솔루션을 제공합니다. 에 대해 자세히 알아보십시오 "SRM의 NSX-T 옵션".
또한 SRM은 VM이 복구될 때 VM의 네트워크 구성을 변경할 수 있는 기능을 제공합니다. 이러한 재구성에는 IP 주소, 게이트웨이 주소 및 DNS 서버 설정과 같은 설정이 포함됩니다. 개별 VM이 복구될 때 개별 VM에 적용되는 다양한 네트워크 설정은 복구 계획에서 VM의 속성 설정에서 지정할 수 있습니다.
복구 계획에서 각 VM의 속성을 편집하지 않고도 여러 VM에 서로 다른 네트워크 설정을 적용하도록 SRM을 구성하려면 VMware에서 DR-IP-customizer라는 도구를 제공합니다. 이 유틸리티를 사용하는 방법은 을 참조하십시오 "VMware 설명서".
재보호
복구 후에는 복구 사이트가 새 운영 사이트가 됩니다. 복구 작업이 SnapMirror 복제를 중단했기 때문에 새 프로덕션 사이트는 이후의 재해로부터 보호되지 않습니다. 모범 사례는 복구 후 즉시 새 프로덕션 사이트를 다른 사이트로 보호하는 것입니다. 원래 운영 사이트가 작동 중인 경우 VMware 관리자는 원래 운영 사이트를 새 복구 사이트로 사용하여 새 운영 사이트를 보호할 수 있으므로 보호 방향을 효과적으로 바꿀 수 있습니다. 재보호는 비치명적인 오류에서만 사용할 수 있습니다. 따라서 원래 vCenter Server, ESXi Server, SRM Server 및 해당 데이터베이스를 최종적으로 복구할 수 있어야 합니다. 사용할 수 없는 경우 새 보호 그룹과 새 복구 계획을 생성해야 합니다.
장애 복구
장애 복구 작업은 기본적으로 이전과 다른 방식으로 장애 조치입니다. 모범 사례로서, 원래 사이트가 장애 복구를 시도하기 전에 허용 가능한 수준의 기능으로 복구되었는지 또는 다시 말해 원래 사이트로 장애 조치를 수행하는 것이 좋습니다. 원래 사이트가 여전히 손상된 경우 장애가 충분히 해결될 때까지 페일백을 지연해야 합니다.
또 다른 장애 복구 모범 사례는 재보호 완료 후 그리고 최종 장애 복구를 수행하기 전에 항상 테스트 장애 조치를 수행하는 것입니다. 이렇게 하면 원래 사이트에 있는 시스템이 작업을 완료할 수 있는지 확인합니다.
원래 사이트를 다시 보호합니다
장애 복구 후 다시 보호 기능을 실행하기 전에 모든 이해 관계자에게 서비스가 정상으로 돌아왔는지 확인해야 합니다.
페일백 후 재보호를 실행하면 기본적으로 환경이 원래 상태로 전환되며, 이때 SnapMirror 복제가 운영 사이트에서 복구 사이트로 다시 실행됩니다.