

성능
 변경 제안
변경 제안
NetApp AFX는 성능과 확장성을 염두에 두고 설계되었으며, 특히 높은 읽기 및 쓰기 처리량이 필요하고 간단하고 선형적인 확장이 가능한 워크로드에 적합합니다.
노드별 성능
각 NetApp AFX 스토리지 노드는 읽기 및 쓰기에 대해 특정 처리량을 제공합니다. 클러스터에 노드가 추가됨에 따라 성능이 선형적으로 증가하며, 이는 이 문서의 "노드 성능의 선형 확장" 섹션에서 설명합니다.
현재 노드 유형은 "AFX 1K"이며 아래와 같이 읽기 및 쓰기 처리량을 제공합니다. NetApp AFX에 새로운 하드웨어가 추가되면 이러한 제한 사항이 변경될 수 있습니다. 참고: 최대 성능은 아래 "벤치마크 결과" 섹션에 표시된 것처럼 여러 클라이언트가 여러 파일을 읽고 쓰는 환경에서 달성되었습니다.
노드당 성능 예상치
| 노드 유형 | 최대 읽기 성능 | 최대 쓰기 성능 |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
최신 성능 예상치는 NetApp 영업팀에 문의하십시오. |
쉘프별 성능
각 셸프에는 16개의 100GB 이더넷 포트를 갖춘 고성능 셸프 모듈이 포함되어 있으며, 클러스터의 컴퓨팅 노드와 고대역폭 스토리지 상호 작용을 위해 RoCEv2 통신을 활용합니다. 모든 물리적 리소스와 마찬가지로 이러한 셸프에도 달성할 수 있는 최대 성능이 있으며, 특히 NetApp AFX는 동일한 디스크 세트를 가리키는 여러 노드를 구성할 수 있기 때문에 더욱 그렇습니다. 다음 표는 TLC 및 QLC 드라이브에 대한 단일 셸프의 예상 최대 읽기 및 쓰기 성능을 보여줍니다. TLC와 QLC의 차이점에 대한 자세한 내용은 "TLC와 QLC"를 참조하십시오.
셸프당 성능 예상치
| 쉘프 모듈 유형 | 최대 읽기 성능 | 최대 쓰기 성능 |
|---|---|---|
NSM 140 |
140GB/s (TLC 및 QLC) |
70GB/s TLC 35GB/s QLC |
|
|
최신 성능 예상치는 NetApp 영업팀에 문의하십시오. |
성능 밀도
분산형 ONTAP 아키텍처에서 스토리지 노드와 셸프를 분리하면 더 많은 노드가 더 적은 셸프로 트래픽을 전송할 수 있으므로 필요한 용량만으로 최대 성능을 얻는 데 필요한 전체 데이터 센터 공간을 줄일 수 있습니다.
이러한 "성능 밀도" 개념을 통해 스토리지 관리자는 스토리지 환경을 과도하게 프로비저닝할 필요 없이 보유한 하드웨어를 최대한 활용할 수 있습니다.
예를 들어, 통합 ONTAP 클러스터에서는 각 노드가 자체 디스크 세트를 가지므로 성능은 해당 노드가 소유한 디스크에만 집중됩니다. 또한 하나의 노드만 하나의 디스크 세트에 접근할 수 있기 때문에 사용 가능한 디스크를 완전히 활용하여 최대 성능을 달성하지 못할 수도 있습니다.
Unified ONTAP – 성능 분배 방식
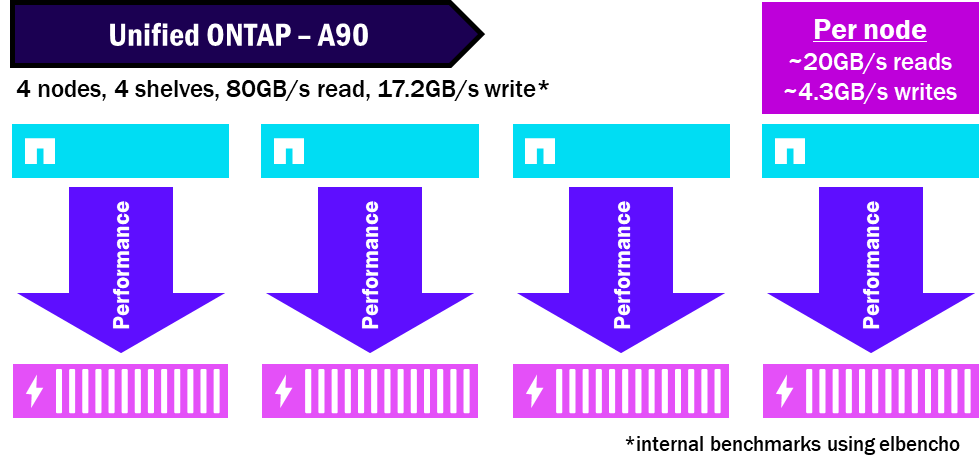
NetApp AFX는 모든 디스크를 단일 스토리지 가용 영역으로 통합하여 모든 노드가 모든 디스크를 활용할 수 있도록 합니다. 또한 디스크와 노드가 분리되어 있으므로 동일한 성능을 얻기 위해 필요한 쉘프 수가 줄어듭니다. 이를 통해 성능이 집중되고 쉘프의 최대 성능 잠재력을 극대화할 수 있습니다.
NetApp AFX – 성능 밀도
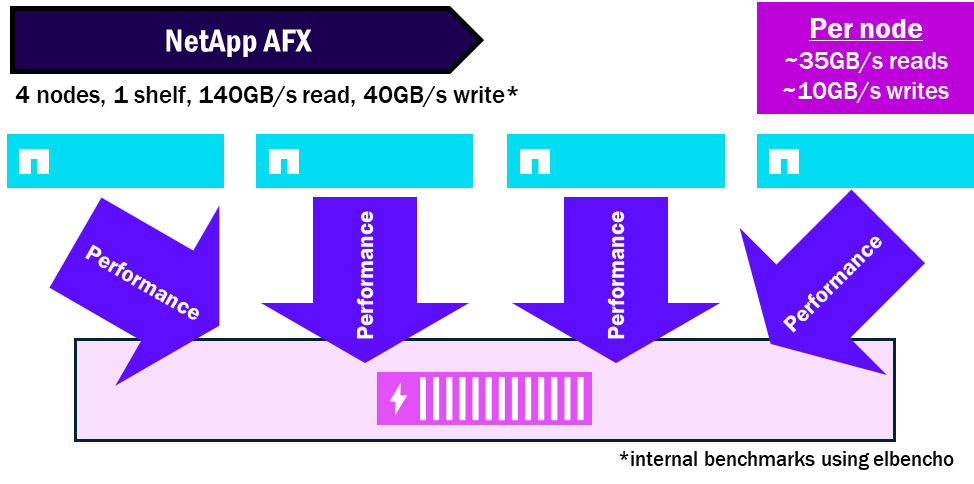
노드 대 쉘프 비율
Unified ONTAP 노드는 노드당 최소 한 세트의 디스크가 필요하며, 단일 노드에 여러 개의 셸프를 연결할 수 있습니다. 따라서 자체 디스크 용량을 충분히 활용하지 못하는 단일 노드에서 성능 병목 현상이 발생할 수 있습니다.
NetApp AFX는 모든 디스크 셸프를 모든 노드에 제공합니다. 각 셸프에는 16개의 100GB RoCE 지원 인터페이스가 있는 모듈이 포함되어 있어 셸프당 허용되는 총 성능을 향상시킵니다. 따라서 여러 노드가 동일한 디스크 세트에 읽기/쓰기 작업을 수행하여 단일 셸프의 성능을 최대한 활용할 수 있습니다.
ONTAP 9.19.1 버전 기준으로 노드 대 쉘프 포화 비율은 약 4:1입니다.
벤치마크 결과
다음 섹션에서는 아래 구성 매개변수를 사용하는 NetApp AFX 클러스터의 벤치마크 결과를 다룹니다.
-
4개 노드, 4개 데이터 인터페이스
-
2개의 쉘프(7.6TB 드라이브)
-
ONTAP 9.19.1
-
NFSv4.2(pNFS, 세션 트렁킹)
-
FlexGroup 볼륨
-
"ElBencho" 벤치마크
-
쓰기: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
읽기: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
Cisco C240 M8 서버 4대, 2포트 * 200GbE CX-7 카드, 80개 스레드
-
NFS 마운트 옵션: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
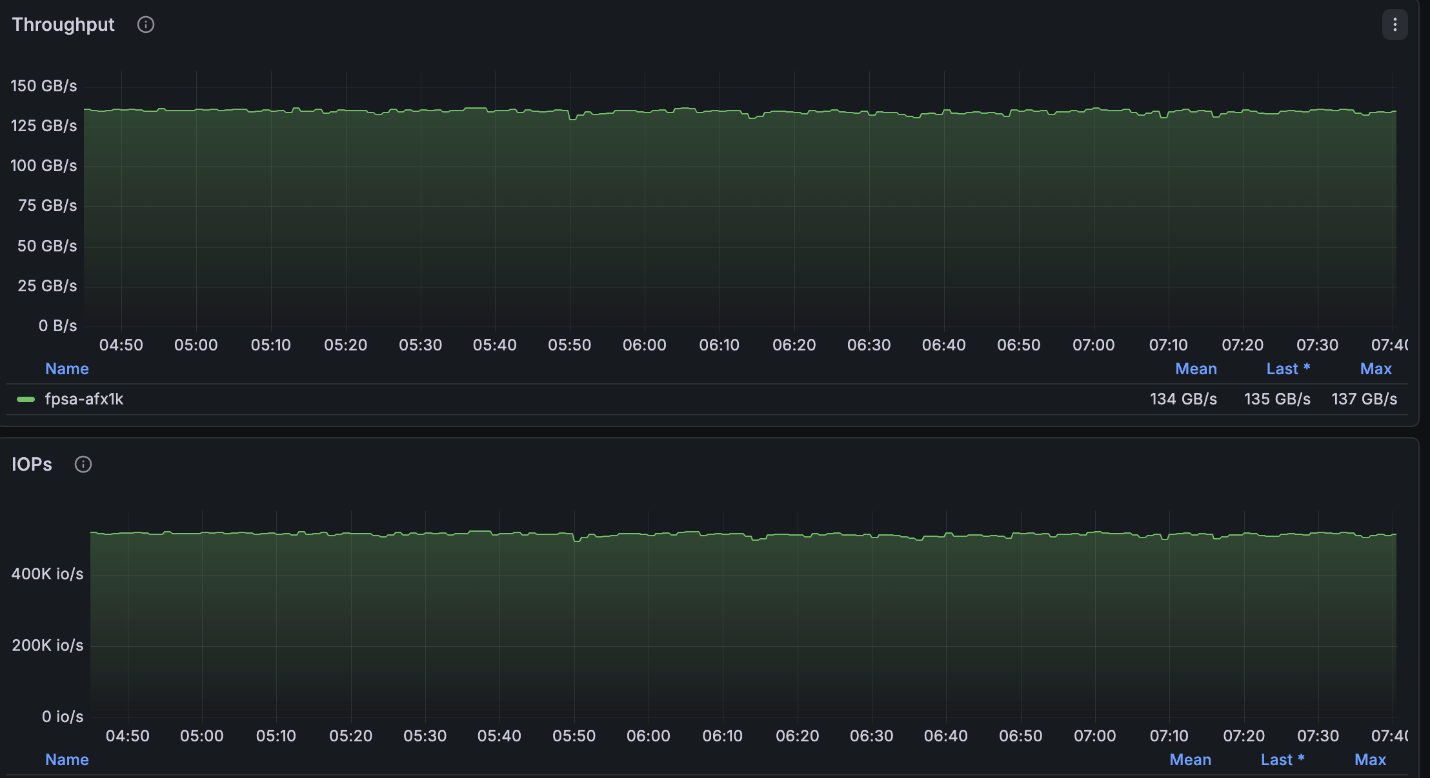
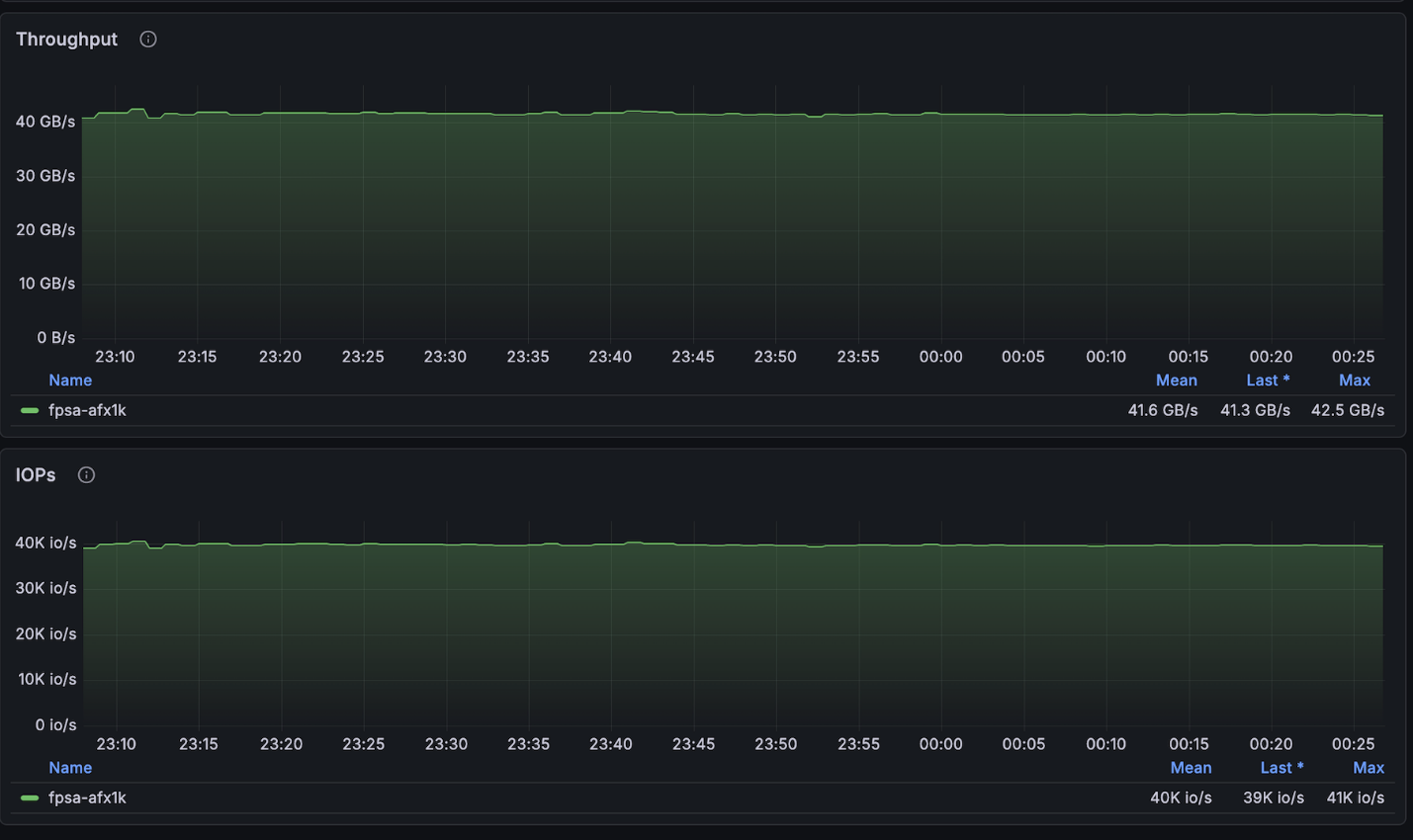
위 구성은 4노드 클러스터에서 사용 가능한 최대 읽기 속도(~134GB/s)에 매우 근접했으며, 노드당 허용된 최대 쓰기 속도(40GB/s)에 정확히 도달했습니다.
NetApp AFX – ElBencho 읽기 성능, 4개 노드
NetApp AFX – ElBencho 쓰기 성능, 4개 노드
적극적인 사전 읽기
미디어 스트리밍 워크로드에서 4K 영화는 종종 수만 개의 파일로 분할되며, 각 파일의 크기는 일반적으로 50MB에서 250MB 사이입니다. 각 파일은 프레임을 나타내며, 애플리케이션은 단일 요청으로 전체 프레임을 읽습니다. 버퍼링 없이 매끄럽고 끊김 없는 스트림을 유지하려면 이러한 프레임 읽기가 끊김 없이 완료되어야 합니다.
ONTAP는 (`-aggressive-readahead-mode`이러한 워크로드를 최적화하기 위한 볼륨 수준 옵션을 제공합니다. ONTAP 9.19.1부터 유사한 파일 유형(예: 미디어 렌더링 및 스트리밍)에서 예측 가능한 I/O 패턴을 가진 워크로드를 가속화하기 위해 적극적인 미리 읽기를 위한 새로운 `cross_file_sequential_read`모드가 AFX에 도입되었습니다.
cross_file_sequential_read는 파일 이름을 기반으로 다음에 읽을 파일을 예측하고 클라이언트가 읽기 호출을 하기 전에 해당 파일들을 미리 읽어옵니다. 이 예측 로직은 디렉터리 내의 모든 파일이 단조롭게 증가하는 숫자 접미사(예: file1, file2, file3)를 사용하는 명명 패턴을 따른다고 가정합니다. 디렉터리 내의 모든 파일은 십진수 또는 16진수 번호를 사용하여 이 패턴을 따라야 합니다. 파일 이름은 최대 255자까지 가능합니다. 이 로직은 파일 확장자에 관계없이 현재 파일 이름만을 기반으로 현재 디렉터리에서 다음에 읽을 파일 이름 세트를 생성합니다. 이전에 10진수 번호로 생성된 파일 이름이 디렉터리에 존재하지 않으면 16진수 번호로 다시 생성됩니다. 생성된 파일 이름 중 어느 것도 존재하지 않으면 해당 세트에 대한 프리페칭은 수행되지 않습니다. 프리페칭은 다음 클라이언트 읽기 호출이 발생하면 재개됩니다.
이러한 옵션을 활성화하면 "frametest" 성능 벤치마크에서 30개 클라이언트(NFSv3 및 SMB3)와 34개 클라이언트(NFSv4.1)를 사용하여 초당 30프레임으로 30,000개의 4K 프레임을 읽을 수 있었으며, 프레임 손실은 단 한 건도 발생하지 않았습니다.
파일 간 순차 읽기는 주로 미디어 워크로드를 위해 설계되었지만, AI 학습 및 추론과 같이 액세스 패턴과 파일 이름이 예측 가능한 다른 읽기 중심 워크로드에서도 이점을 얻을 수 있습니다.
고려 사항 및 주의 사항
-
공유 버퍼 캐시 - 적극적인 읽기 미리 읽기 기능은 노드의 다른 볼륨과 동일한 버퍼 캐시를 사용합니다. 이 기능을 활성화하면 해당 노드의 다른 볼륨에 대한 읽기 성능에 영향을 줄 수 있습니다.
-
기본 스토리지 성능 – 파일 읽기 속도가 충분히 빠르지 않으면(예: HDD 기반 FAS 시스템) 클라이언트 읽기가 발생하기 전에 캐시된 데이터가 제거되어 미리 읽기의 이점이 상쇄될 수 있습니다.
-
액세스 패턴 요구 사항 – 워크로드의 읽기 패턴이 순차적이지 않거나 디렉터리의 파일 이름이 순차적으로 증가하는 순서로 지정되지 않은 경우 cross_file_sequential_read의 적극적인 미리 읽기 모드는 의미 있는 이점을 제공하지 않습니다.
NFSv4.x 성능 향상
NFS 버전 3은 1995년 공식 출시 이후 수십 년 동안 NFS 애플리케이션의 표준으로 자리 잡았습니다. 뛰어난 성능과 안정성 덕분에 최신 NFS 버전으로의 전환이 어려운 이유도 충분합니다.
하지만 NFSv3에도 한계가 있습니다. 프로토콜의 무상태성은 성능 향상과 스토리지 장애 조치 시 중단 최소화에는 좋지만, 데이터 일관성 및 잠금 관리에는 적합하지 않습니다. NFS 서버는 잠금 상태를 추적하지 않기 때문에 장애 발생 시 NFS 서버가 잠금을 해제할 수도 있고 해제하지 않을 수도 있으며, NFS 클라이언트는 파일이 잠겨 있는지 여부를 알 수 없을 수 있습니다.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). NFSv4.x는 20년 이상 존재해 왔지만, 몇 가지 이유로 아직 널리 채택되지 못했습니다.
-
ID 관리의 복잡성: 많은 환경에서 NFSv4.x의 이름 문자열 및 Kerberos 보안 요구 사항을 제대로 활용하기 위한 네임 서비스 인프라가 구축되어 있지 않습니다.
-
최신 NFS 클라이언트의 필요성: NFSv4가 처음 출시된 시점으로부터 시간이 흐른 지금과 같이 현대적인 NFS 환경에서는 이 문제가 덜 중요해졌습니다. 현재 사용되는 거의 모든 운영 체제에는 NFSv4를 완벽하게 지원하는 NFS 클라이언트가 포함되어 있지만, 필요한 NFSv4.x 패키지가 없는 레거시 시스템도 여전히 존재합니다. 실제로 일부 애플리케이션은 여전히 이전 버전의 NFS를 사용해야 합니다.
-
"고장 나지 않았으면 고치지 마라"는 사고방식: 기업 IT 조직은 새로운 기술, 심지어 20년 이상 된 기술조차 도입하는 데 있어 매우 보수적인 것으로 악명이 높습니다. 현재 NFS 버전이 잘 작동하고 있다면 왜 바꿔야 할까요?
-
성능 문제: NFSv4.x와 같은 상태 저장 프로토콜의 성능은 지난 20년 동안 대부분 상태 비저장 NFSv3에 비해 뒤처져 왔습니다. 과거에는 성능 영향이 NFSv4.x의 장점을 상쇄하는 경우가 많았습니다.
AFX를 사용한 ONTAP 9.18.1의 NFSv4.x 개선 사항
ONTAP의 일부 아키텍처 변경으로 NFS의 전반적인 성능이 크게 향상되었으며, NFSv4.x의 성능 개선에도 상당한 진전이 있었습니다.
다음은 이러한 변경 사항 중 일부를 간략하게 요약한 것입니다.
순차 읽기 향상: NFSv4.1이 NFSv3보다 30% 우수
ONTAP 9.18.1은 NFSv4.1을 사용한 다중 경로 IO 지원을 도입했습니다. MPIO는 WAFL 파일 시스템에서 읽기 작업을 처리하는 대신, 읽기 작업을 네트워크 도메인으로 이동시켜 다중 경로 안전 방식으로 처리합니다. 이 접근 방식은 컨텍스트 스위치를 줄여 순차 읽기 트래픽에서 전반적인 병렬성을 향상시키고, WAFL을 우회하여 버퍼 관리의 오버헤드를 줄입니다.
FlexGroup 볼륨의 임의 읽기 향상: NFSv4.1이 NFSv3의 7% 이내
FlexGroup 볼륨은 여러 개의 하위 구성 볼륨을 하나의 통합 네임스페이스로 제공하는 볼륨입니다. AFX에서 FlexGroup 볼륨은 기본적으로 고급 용량 균형 조정(Advanced Capacity Balancing)이 활성화되어 있어 10GB보다 큰 파일은 여러 구성 볼륨에 멀티파트 파일로 분산하여 기록됩니다. 이러한 파일 파트가 원격 위치에 저장되기 때문에, 기존 NFSv4.x 환경에서는 임의 읽기 성능이 다소 떨어지는 문제가 있었습니다(NFSv3보다 약 18% 낮음). ONTAP 9.18.1 버전에서는 이러한 문제를 해결하기 위해 NFSv4.x 환경에서 멀티파트 읽기에 대한 캐시된 IO 지원을 도입했습니다. 참고: 이 변경 사항은 FlexVol 볼륨에는 적용되지 않습니다.
순차 쓰기: 이전 릴리스 대비 +10% 향상
HA 페일오버 기능에 사용되는 NVLOG 데이터 복제 방식이 개선되어 NetApp AFX 시스템의 전반적인 순차 쓰기 성능이 향상되었습니다.
메타데이터 작업: EDA 벤치마크에서 NFSv3 대비 15% 이내의 성능
NFSv4.1은 전통적으로 모든 OPEN 및 CLOSE 작업을 직렬화하여 클러스터 노드가 네트워크에서 WAFL로 전송되기 전에 한 번에 하나씩 처리합니다. ONTAP 9.18.1에서는 동시 열림/닫힘(COC) 기능을 도입하여 경쟁 조건 해결 방식을 변경함으로써 네트워크 직렬화를 없애고 이전 릴리스에서 발생했던 OPEN/CLOSE 병목 현상을 해결합니다.
이러한 모든 변경 사항은 AFX에서 이루어진 아키텍처 변경 사항과 함께 ONTAP 9.18.1에서 전반적인 NFSv4.1 성능을 향상시킬 수 있게 했습니다.
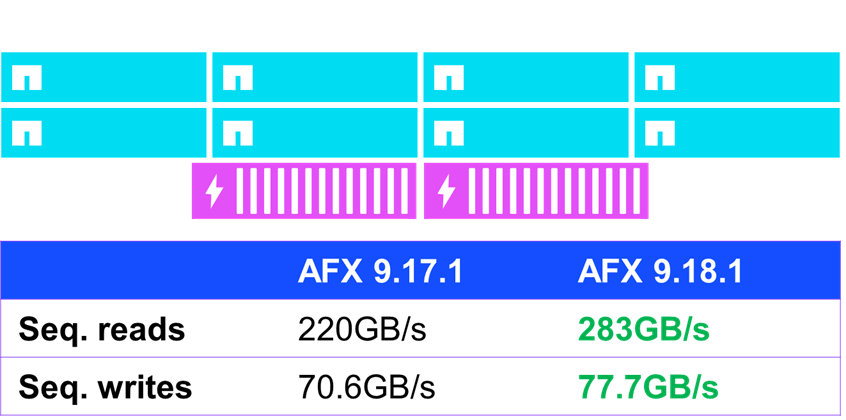
순차 IO 결과
성능이 다소 향상된 부분 중 하나는 순차 I/O(즉, 예측 가능하고 순차적으로 발행되는 I/O)였습니다. fio를 사용한 표준 성능 테스트에서 ONTAP 9.18.1을 실행하는 AFX는 순차 읽기 성능을 거의 30%, 순차 쓰기 성능을 10% 향상시켰습니다.
NetApp AFX – ONTAP 9.18.1에서의 NFSv4.1 순차 IO 성능
메타데이터 비중이 높은 워크로드 결과
NFSv4.x의 주요 성능 저하 요인 중 하나인 메타데이터 처리 성능이 더욱 인상적으로 개선되었습니다. 메타데이터는 파일 소유자 및 속성 관리, 파일 생성 및 목록 조회 등에 사용되는 일반적으로 4K 범위의 랜덤 IO입니다. NFSv4.x의 상태 유지 특성으로 인해 이러한 유형의 작업은 CPU 및 지연 시간 측면에서 더 많은 비용이 소요되며, 이는 결과적으로 전반적인 성능을 저하시킵니다.
AFX ONTAP 9.18.1의 변경 사항으로 이러한 유형의 워크로드에 대한 NFSv4.x 성능이 크게 향상되어 NFSv3 성능과의 격차를 15% 이내로 좁혔습니다.
저희 성능 엔지니어링 팀은 표준 AI 이미지, EDA 및 소프트웨어 빌드 벤치마크의 성능을 비교한 결과 이전 ONTAP 릴리스 대비 상당한 성능 향상을 발견했습니다.
NetApp AFX – ONTAP 9.18.1에서의 NFSv4.1 메타데이터 IO 성능
