

CLI를 사용하여 4 또는 8노드 MetroCluster 구성의 무중단 ONTAP를 수동으로 업그레이드
 변경 제안
변경 제안
4노드 또는 8노드 MetroCluster 구성을 수동으로 업그레이드하려면 업데이트 준비, 1개 또는 2개의 각 DR 그룹에서 동시에 DR 쌍 업데이트, 업그레이드 후 작업 수행이 포함됩니다.
-
이 작업은 다음 구성에 적용됩니다.
-
ONTAP 9.2 이하를 실행하는 4노드 MetroCluster FC 또는 IP 구성
-
ONTAP 버전에 상관없이 8노드 MetroCluster FC 구성
-
-
2노드 MetroCluster 구성이 있는 경우 이 절차를 사용하지 마십시오.
-
다음 작업은 ONTAP의 이전 버전과 새 버전을 나타냅니다.
-
업그레이드할 때 이전 버전은 ONTAP의 이전 버전이며, 새 버전의 ONTAP보다 버전 번호가 낮습니다.
-
다운그레이드할 때 이전 버전은 최신 버전의 ONTAP로, 새 버전의 ONTAP보다 높은 버전 번호가 있습니다.
-
-
이 작업은 다음과 같은 고급 워크플로를 사용합니다.
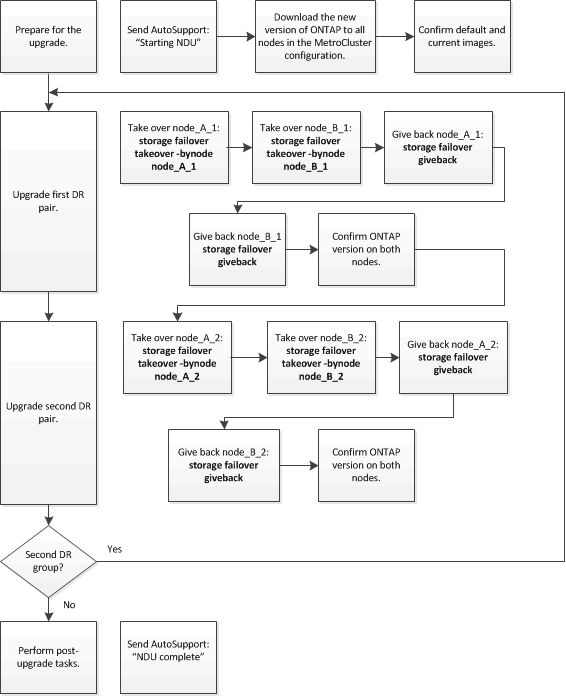
8노드 또는 4노드 MetroCluster 구성에서 ONTAP 소프트웨어를 업데이트할 때의 차이점
MetroCluster 소프트웨어 업그레이드 프로세스는 MetroCluster 구성에 8개 또는 4개 노드가 있는지에 따라 다릅니다.
MetroCluster 구성은 1개 또는 2개의 DR 그룹으로 구성됩니다. 각 DR 그룹은 2개의 HA 쌍으로 구성되며, 각 MetroCluster 클러스터에 하나의 HA 쌍이 있습니다. 8노드 MetroCluster에는 2개의 DR 그룹이 포함되어 있습니다.
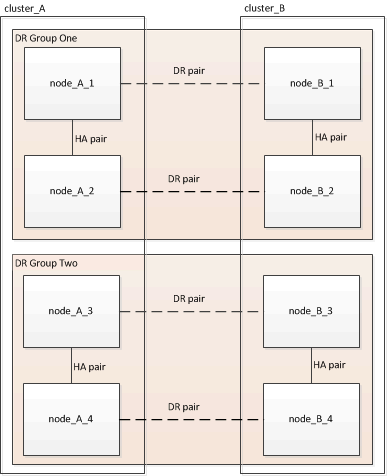
한 번에 하나의 DR 그룹을 업그레이드합니다.
-
DR 그룹 1 업그레이드:
-
node_A_1 및 node_B_1을 업그레이드합니다.
-
node_A_2 및 node_B_2를 업그레이드합니다.
-
-
DR 그룹 1 업그레이드:
-
node_A_1 및 node_B_1을 업그레이드합니다.
-
node_A_2 및 node_B_2를 업그레이드합니다.
-
-
DR 그룹 2 업그레이드:
-
node_A_3 및 node_B_3을 업그레이드합니다.
-
node_A_4 및 node_B_4를 업그레이드합니다.
-
MetroCluster DR 그룹 업그레이드 준비 중
노드에서 ONTAP 소프트웨어를 업그레이드하기 전에 노드 간의 DR 관계를 식별하고 업그레이드를 시작한다는 AutoSupport 메시지를 전송하고 각 노드에서 실행 중인 ONTAP 버전을 확인해야 합니다.
이(가) 있어야 합니다 "다운로드되었습니다" 및 "설치되어 있습니다" 소프트웨어 이미지
이 작업은 각 DR 그룹에서 반복해야 합니다. MetroCluster 구성이 8개 노드로 구성된 경우 2개의 DR 그룹이 있습니다. 따라서 이 작업은 각 DR 그룹에서 반복해야 합니다.
이 작업에 제공된 예제에서는 다음 그림에 표시된 이름을 사용하여 클러스터와 노드를 식별합니다.
-
구성에서 DR 페어를 식별합니다.
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
권한 수준을 admin에서 advanced로 설정하고 계속할지 묻는 메시지가 표시되면 * y * 를 입력합니다.
set -privilege advanced고급 프롬프트('*>')가 나타납니다.
-
cluster_A에서 ONTAP 버전을 확인합니다.
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_B에서 버전을 확인합니다.
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
AutoSupport 알림 트리거:
autosupport invoke -node * -type all -message "Starting_NDU"이 AutoSupport 알림에는 업그레이드 전의 시스템 상태 기록이 포함됩니다. 업그레이드 프로세스에 문제가 있는 경우 유용한 문제 해결 정보를 저장합니다.
클러스터가 AutoSupport 메시지를 전송하도록 구성되지 않은 경우 알림 복사본이 로컬에 저장됩니다.
-
첫 번째 세트의 각 노드에 대해 대상 ONTAP 소프트웨어 이미지를 기본 이미지로 설정합니다.
system image modify {-node nodename -iscurrent false} -isdefault true이 명령은 확장 쿼리를 사용하여 대체 이미지로 설치된 대상 소프트웨어 이미지를 노드의 기본 이미지로 변경합니다.
-
cluster_a에서 타겟 ONTAP 소프트웨어 이미지가 기본 이미지로 설정되어 있는지 확인합니다.
system image show다음 예제에서 image2는 새 ONTAP 버전이며 첫 번째 집합의 각 노드에서 기본 이미지로 설정됩니다.
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
cluster_B에서 타겟 ONTAP 소프트웨어 이미지가 기본 이미지로 설정되어 있는지 확인합니다.
system image show다음 예에서는 타겟 버전이 첫 번째 세트의 각 노드에서 기본 이미지로 설정되었음을 보여 줍니다.
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
업그레이드할 노드가 현재 각 노드에 대해 두 번 클라이언트를 제공하는지 확인합니다.
system node run -node target-node -command uptimeUptime 명령은 노드가 마지막으로 부팅된 이후 NFS, CIFS, FC 및 iSCSI 클라이언트에 대해 노드에서 수행한 총 작업 수를 표시합니다. 각 프로토콜에 대해 명령을 두 번 실행하여 작업 수가 증가하는지 여부를 확인해야 합니다. 노드가 증가하면 현재 해당 프로토콜에 대한 클라이언트를 제공하고 있는 것입니다. 증가되지 않는 경우 노드는 현재 해당 프로토콜에 대한 클라이언트를 제공하지 않습니다.

노드가 업그레이드된 후 클라이언트 트래픽이 다시 시작되었는지 확인할 수 있도록 클라이언트 작업이 증가하는 각 프로토콜을 기록해 두어야 합니다. 이 예에서는 NFS, CIFS, FC 및 iSCSI 작업이 있는 노드를 보여 줍니다. 하지만 노드는 현재 NFS 및 iSCSI 클라이언트만 제공하고 있습니다.
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
MetroCluster DR 그룹의 첫 번째 DR 쌍을 업데이트합니다
새로운 버전의 ONTAP를 노드의 현재 버전으로 만들려면 노드에 대해 테이크오버 및 반환을 올바른 순서로 수행해야 합니다.
모든 노드에서 이전 버전의 ONTAP를 실행해야 합니다.
이 작업에서는 node_A_1 및 node_B_1이 업그레이드됩니다.
첫 번째 DR 그룹에서 ONTAP 소프트웨어를 업그레이드하고 현재 8노드 MetroCluster 구성에서 두 번째 DR 그룹을 업그레이드하는 경우 이 작업에서 node_A_3과 node_B_3을 업데이트합니다.
-
다음 노드에서 모든 데이터 LIF를 마이그레이션:
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
MetroCluster Tiebreaker 소프트웨어가 활성화되어 있으면 비활성화하십시오.
-
HA Pair의 각 노드에 대해 자동 반환 비활성화:
storage failover modify -node target-node -auto-giveback false이 명령은 HA 쌍의 각 노드에 대해 반복해야 합니다.
-
자동 반환이 비활성화되었는지 확인:
storage failover show -fields auto-giveback이 예제는 두 노드에서 자동 반환이 사용되지 않도록 설정되었음을 보여 줍니다.
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
I/O가 각 컨트롤러에 대해 ~50%를 초과하지 않고 CPU 활용률이 컨트롤러당 ~50%를 초과하지 않는지 확인합니다.
-
cluster_A에서 타겟 노드의 테이크오버 시작:
즉시 실행 매개 변수를 지정하지 마십시오. 새 소프트웨어 이미지로 부팅하기 위해 테이크오버가 수행되는 노드에 일반 테이크오버가 필요합니다.
-
cluster_A(node_A_1)에서 DR 파트너 인수:
storage failover takeover -ofnode node_A_1노드가 "Waiting for 반환" 상태로 부팅됩니다.
AutoSupport가 활성화된 경우 노드가 클러스터 쿼럼을 벗어났음을 나타내는 AutoSupport 메시지가 전송됩니다. 이 알림을 무시하고 업그레이드를 진행할 수 있습니다. -
테이크오버가 성공했는지 확인:
storage failover show다음 예제는 Takeover가 성공했음을 보여줍니다. node_a_1은 "반환 대기 중" 상태이고 node_a_2는 "인수 중" 상태입니다.
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
cluster_B(node_B_1)에서 DR 파트너를 인수합니다.
즉시 실행 매개 변수를 지정하지 마십시오. 새 소프트웨어 이미지로 부팅하기 위해 테이크오버가 수행되는 노드에 일반 테이크오버가 필요합니다.
-
node_B_1 인수:
storage failover takeover -ofnode node_B_1노드가 "Waiting for 반환" 상태로 부팅됩니다.
AutoSupport가 활성화된 경우 노드가 클러스터 쿼럼을 벗어났음을 나타내는 AutoSupport 메시지가 전송됩니다. 이 알림을 무시하고 업그레이드를 진행할 수 있습니다. -
테이크오버가 성공했는지 확인:
storage failover show다음 예제는 Takeover가 성공했음을 보여줍니다. node_B_1은 "반환 대기 중" 상태이고 node_B_2는 "인수 중" 상태입니다.
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
다음 조건이 충족되도록 8분 이상 기다리십시오.
-
클라이언트 다중 경로(배포된 경우)가 안정화됩니다.
-
테이크오버가 수행되는 동안 입출력이 일시 중지되어 클라이언트가 복구됩니다.
복구 시간은 클라이언트에 따라 다르며 클라이언트 애플리케이션의 특성에 따라 8분 이상 걸릴 수 있습니다.
-
-
애그리게이트를 타겟 노드로 반환:
MetroCluster IP 구성을 ONTAP 9.5 이상으로 업그레이드한 후, 애그리게이트는 짧은 기간 동안 성능 저하 상태가 된 후에 재동기화되어 미러링된 상태로 돌아갑니다.
-
cluster_A의 DR 파트너에게 애그리게이트를 반환합니다.
storage failover giveback -ofnode node_A_1 -
cluster_B의 DR 파트너에게 애그리게이트를 반환합니다.
storage failover giveback -ofnode node_B_1반환 작업은 먼저 루트 애그리게이트를 노드로 반환한 다음, 노드가 부팅을 완료한 후 루트가 아닌 애그리게이트를 반환합니다.
-
-
두 클러스터에서 다음 명령을 실행하여 모든 애그리게이트가 반환되었는지 확인합니다.
storage failover show-givebackGiveStatus 필드에 반환할 애그리게이트가 없다고 표시되면 모든 애그리게이트가 반환된 것입니다. Giveback이 거부되면 명령은 반환 진행률을 표시하고 어떤 서브시스템이 Giveback을 거부하는지 표시합니다.
-
애그리게이트가 반환되지 않은 경우 다음을 수행합니다.
-
거부권을 행사할 수 있는 대안을 검토하여 "받는 사람" 조건을 해결할지 또는 거부권을 무시할지 여부를 결정합니다.
-
필요한 경우 오류 메시지에 설명된 "받는 사람" 조건을 해결하여 식별된 작업이 정상적으로 종료되도록 합니다.
-
스토리지 페일오버 반환 명령을 다시 입력합니다.
만약 "to" 조건을 무시하기로 결정했다면 -override-vetoes 매개변수를 TRUE로 설정하십시오.
-
-
다음 조건이 충족되도록 8분 이상 기다리십시오.
-
클라이언트 다중 경로(배포된 경우)가 안정화됩니다.
-
클라이언트는 반환 중에 발생하는 I/O의 일시 중지로부터 복구됩니다.
복구 시간은 클라이언트에 따라 다르며 클라이언트 애플리케이션의 특성에 따라 8분 이상 걸릴 수 있습니다.
-
-
권한 수준을 admin에서 advanced로 설정하고 계속할지 묻는 메시지가 표시되면 * y * 를 입력합니다.
set -privilege advanced고급 프롬프트('*>')가 나타납니다.
-
cluster_A에서 버전을 확인합니다.
system image show다음 예에서는 시스템 image2(타겟 ONTAP 이미지)가 node_A_1의 기본 및 현재 버전임을 보여 줍니다.
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_B에서 버전을 확인합니다.
system image show다음 예에서는 시스템 image2(타겟 ONTAP 이미지)가 node_B_1의 기본 및 현재 버전임을 보여 줍니다.
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
MetroCluster DR 그룹의 두 번째 DR 쌍을 업데이트합니다
새 버전의 ONTAP를 노드의 현재 버전으로 만들려면 노드에 대해 테이크오버 및 반환을 올바른 순서로 수행해야 합니다.
첫 번째 DR 쌍(node_A_1 및 node_B_1)을 업그레이드해야 합니다.
이 작업에서는 node_A_2와 node_B_2가 업그레이드됩니다.
첫 번째 DR 그룹에서 ONTAP 소프트웨어를 업그레이드하고 현재 8노드 MetroCluster 구성에서 두 번째 DR 그룹을 업데이트하는 경우 이 작업에서 node_A_4 및 node_B_4를 업데이트합니다.
-
다음 노드에서 모든 데이터 LIF를 마이그레이션:
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
cluster_A에서 타겟 노드의 테이크오버 시작:
즉시 실행 매개 변수를 지정하지 마십시오. 새 소프트웨어 이미지로 부팅하기 위해 테이크오버가 수행되는 노드에 일반 테이크오버가 필요합니다.
-
cluster_A에서 DR 파트너를 인수합니다.
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
ONTAP 9.0에서 ONTAP 9.1 또는 패치 업그레이드에는 "버전 불일치 허용" 옵션이 필요하지 않습니다. 노드가 "Waiting for 반환" 상태로 부팅됩니다.
AutoSupport가 활성화된 경우 노드가 클러스터 쿼럼을 벗어났음을 나타내는 AutoSupport 메시지가 전송됩니다. 이 알림을 무시하고 업그레이드를 진행할 수 있습니다.
-
테이크오버가 성공했는지 확인:
storage failover show다음 예제는 Takeover가 성공했음을 보여줍니다. node_a_2가 "반환 대기 중" 상태이고 node_a_1이 "인수 중" 상태입니다.
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
cluster_B에서 타겟 노드의 테이크오버 시작:
즉시 실행 매개 변수를 지정하지 마십시오. 새 소프트웨어 이미지로 부팅하기 위해 테이크오버가 수행되는 노드에 일반 테이크오버가 필요합니다.
-
cluster_B(node_B_2)에서 DR 파트너를 인수합니다.
에서 업그레이드하는 경우… 이 명령을 입력하십시오… ONTAP 9.2 또는 ONTAP 9.1
storage failover takeover -ofnode node_B_2ONTAP 9.0 또는 Data ONTAP 8.3.x
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
ONTAP 9.0에서 ONTAP 9.1 또는 패치 업그레이드에는 "버전 불일치 허용" 옵션이 필요하지 않습니다. 노드가 "Waiting for 반환" 상태로 부팅됩니다.
AutoSupport가 활성화된 경우 노드가 클러스터 쿼럼을 벗어났음을 나타내는 AutoSupport 메시지가 전송됩니다. 이 알림을 무시해도 되고 업그레이드를 진행할 수 있습니다. -
테이크오버가 성공했는지 확인:
storage failover show다음 예제는 Takeover가 성공했음을 보여줍니다. node_B_2가 "반환 대기 중" 상태이고 node_B_1이 "인수 중" 상태입니다.
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
다음 조건이 충족되도록 8분 이상 기다리십시오.
-
클라이언트 다중 경로(배포된 경우)가 안정화됩니다.
-
테이크오버가 수행되는 동안 입출력이 일시 중지되어 클라이언트가 복구됩니다.
복구 시간은 클라이언트에 따라 다르며 클라이언트 애플리케이션의 특성에 따라 8분 이상 걸릴 수 있습니다.
-
-
애그리게이트를 타겟 노드로 반환:
MetroCluster IP 구성을 ONTAP 9.5로 업그레이드한 후 재동기화하여 미러링된 상태로 되돌리기 전에 잠시 동안 애그리게이트가 성능 저하 상태가 됩니다.
-
cluster_A의 DR 파트너에게 애그리게이트를 반환합니다.
storage failover giveback -ofnode node_A_2 -
cluster_B의 DR 파트너에게 애그리게이트를 반환합니다.
storage failover giveback -ofnode node_B_2반환 작업은 먼저 루트 애그리게이트를 노드로 반환한 다음, 노드가 부팅을 완료한 후 루트가 아닌 애그리게이트를 반환합니다.
-
-
두 클러스터에서 다음 명령을 실행하여 모든 애그리게이트가 반환되었는지 확인합니다.
storage failover show-givebackGiveStatus 필드에 반환할 애그리게이트가 없다고 표시되면 모든 애그리게이트가 반환된 것입니다. Giveback이 거부되면 명령은 반환 진행률을 표시하고 어떤 서브시스템이 Giveback을 거부하는지 표시합니다.
-
애그리게이트가 반환되지 않은 경우 다음을 수행합니다.
-
거부권을 행사할 수 있는 대안을 검토하여 "받는 사람" 조건을 해결할지 또는 거부권을 무시할지 여부를 결정합니다.
-
필요한 경우 오류 메시지에 설명된 "받는 사람" 조건을 해결하여 식별된 작업이 정상적으로 종료되도록 합니다.
-
스토리지 페일오버 반환 명령을 다시 입력합니다.
만약 "to" 조건을 무시하기로 결정했다면 -override-vetoes 매개변수를 TRUE로 설정하십시오.
-
-
다음 조건이 충족되도록 8분 이상 기다리십시오.
-
클라이언트 다중 경로(배포된 경우)가 안정화됩니다.
-
클라이언트는 반환 중에 발생하는 I/O의 일시 중지로부터 복구됩니다.
복구 시간은 클라이언트에 따라 다르며 클라이언트 애플리케이션의 특성에 따라 8분 이상 걸릴 수 있습니다.
-
-
권한 수준을 admin에서 advanced로 설정하고 계속할지 묻는 메시지가 표시되면 * y * 를 입력합니다.
set -privilege advanced고급 프롬프트('*>')가 나타납니다.
-
cluster_A에서 버전을 확인합니다.
system image show다음 예에서는 시스템 image2(타겟 ONTAP 이미지)가 node_A_2의 기본 및 현재 버전임을 보여 줍니다.
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
cluster_B에서 버전을 확인합니다.
system image show다음 예에서는 시스템 image2(타겟 ONTAP 이미지)가 node_B_2의 기본 및 현재 버전임을 보여 줍니다.
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
HA 쌍의 각 노드에 대해 자동 반환을 활성화합니다.
storage failover modify -node target-node -auto-giveback true이 명령은 HA 쌍의 각 노드에 대해 반복해야 합니다.
-
자동 반환이 활성화되었는지 확인:
storage failover show -fields auto-giveback이 예에서는 두 노드에서 자동 반환이 설정되었음을 보여 줍니다.
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.