

Crie um plano de replicação no NetApp Disaster Recovery
 Sugerir alterações
Sugerir alterações
Após adicionar recursos e sites, crie um plano de replicação para gerenciar a proteção de dados. A criação do plano de replicação envolve designar os sites de origem e destino, selecionar os grupos de recursos e escolher como os aplicativos devem ser restaurados e ligados. Por exemplo, você pode agrupar máquinas virtuais (VMs) associadas a um aplicativo ou pode agrupar aplicativos que tenham níveis semelhantes.
Ao criar um plano de replicação, você também pode editar agendamentos para conformidade e testes, realizando testes de failover sem impactar seus dados de produção.
Função de console NetApp necessária A função de Super admin, Disaster recovery admin, Disaster recovery failover admin ou Disaster recovery application admin é necessária para executar esta tarefa. "Saiba mais sobre funções e permissões de usuário no NetApp Disaster Recovery". "Saiba mais sobre as funções de acesso do NetApp Console para todos os serviços".
Sobre planos de replicação
Você pode proteger várias VMs em vários armazenamentos de dados. O NetApp Disaster Recovery cria grupos de consistência ONTAP para todos os volumes ONTAP que hospedam armazenamentos de dados de VM protegidos.
Você só pode ativar a proteção se o plano de replicação estiver em um dos seguintes estados:
-
Preparar
-
Failback confirmado
-
Falha de teste confirmada
Instantâneos do plano de replicação
A recuperação de desastres mantém o mesmo número de instantâneos nos clusters de origem e destino. Por padrão, o serviço executa um processo de reconciliação de instantâneos a cada 24 horas para garantir que o número de instantâneos nos clusters de origem e destino seja o mesmo.
As seguintes situações podem fazer com que o número de instantâneos seja diferente entre os clusters de origem e de destino:
-
Algumas situações podem fazer com que operações ONTAP fora da Recuperação de Desastres adicionem ou removam instantâneos do volume:
-
Se houver snapshots ausentes no site de origem, os snapshots correspondentes no site de destino poderão ser excluídos, dependendo da política padrão do SnapMirror para o relacionamento.
-
Se houver instantâneos ausentes no site de destino, o serviço poderá excluir os instantâneos correspondentes no site de origem durante o próximo processo de reconciliação de instantâneos agendado, dependendo da política padrão do SnapMirror para o relacionamento.
-
-
Uma redução na contagem de retenção de snapshots do plano de replicação pode fazer com que o serviço exclua os snapshots mais antigos nos sites de origem e de destino para atender ao número de retenção recém-reduzido.
Nesses casos, o Disaster Recovery remove snapshots mais antigos dos clusters de origem e destino na próxima verificação de consistência. Ou o administrador pode executar uma limpeza instantânea imediata selecionando Ações*![]() ícone no plano de replicação e selecionando *Limpar instantâneos.
ícone no plano de replicação e selecionando *Limpar instantâneos.
A Recuperação de Desastres realiza verificações de simetria de snapshots a cada 24 horas.
Antes de começar
-
Antes de criar um relacionamento SnapMirror , configure o cluster e o peering SVM fora do Disaster Recovery.
-
Se você configurar mapeamentos de rede no nível do vCenter, o Disaster Recovery reconhece esses mapeamentos quando você cria o plano de replicação. Se você modificar ou adicionar o mapeamento de rede no nível do vCenter após criar o plano de replicação, o Disaster Recovery reconhece esses mapeamentos quando você edita manualmente o plano de replicação.
-
Com o Google Cloud, você só pode adicionar um volume ou armazenamento de dados a um plano de replicação.

|
Organize suas VMs ou clusters Kubernetes antes de implantar NetApp Disaster Recovery para minimizar a dispersão. Coloque os recursos que precisam de proteção em um subconjunto de datastores e os recursos que não serão protegidos em outro subconjunto de datastores. Para organizar os grupos de recursos antes de criar o plano de replicação, consulte "Criar um grupo de recursos". |
Crie o plano de replicação
Um assistente guia você por estas etapas:
-
Selecione servidores vCenter.
-
Selecione os recursos (VMs, datastore, namespaces) que deseja replicar e atribua grupos de recursos.
-
Mapeie como os recursos do ambiente de origem são mapeados para o destino.
-
Defina a frequência com que o plano é executado, execute um script hospedado pelo convidado, defina a ordem de inicialização e selecione o objetivo do ponto de recuperação.
-
Revise o plano.
Ao criar o plano, siga estas diretrizes:
-
Use as mesmas credenciais para todas as VMs ou clusters Kubernetes no plano.
-
Use o mesmo script para todas as VMs ou clusters Kubernetes no plano.
-
Use a mesma sub-rede, DNS e gateway para todas as VMs ou clusters Kubernetes no plano.
Selecione servidores vCenter
Primeiro, selecione o vCenter de origem e depois selecione o vCenter de destino.
-
Na navegação à esquerda do NetApp Console , selecione Proteção > Recuperação de desastres.
-
No menu NetApp Disaster Recovery , selecione Planos de replicação.
-
No menu suspenso, escolha o tipo de recurso para o qual deseja criar um plano de replicação: Kubernetes ou vCenter.
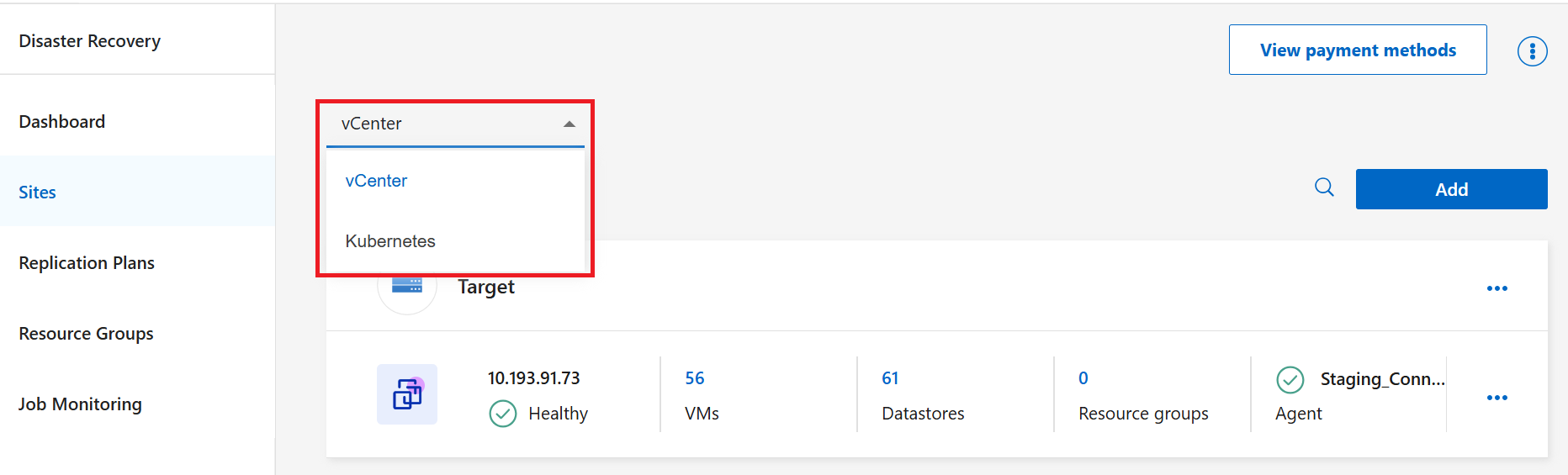
-
Selecione Adicionar.
-
Insira um nome para o plano de replicação.
-
Para Origem, selecione o vCenter ou o cluster Kubernetes para designar como origem.
-
Em Origem vCenter, selecione o vCenter onde os dados existem no menu suspenso. Em Destino, selecione o vCenter ou cluster Kubernetes a ser usado como destino de recuperação de desastres.
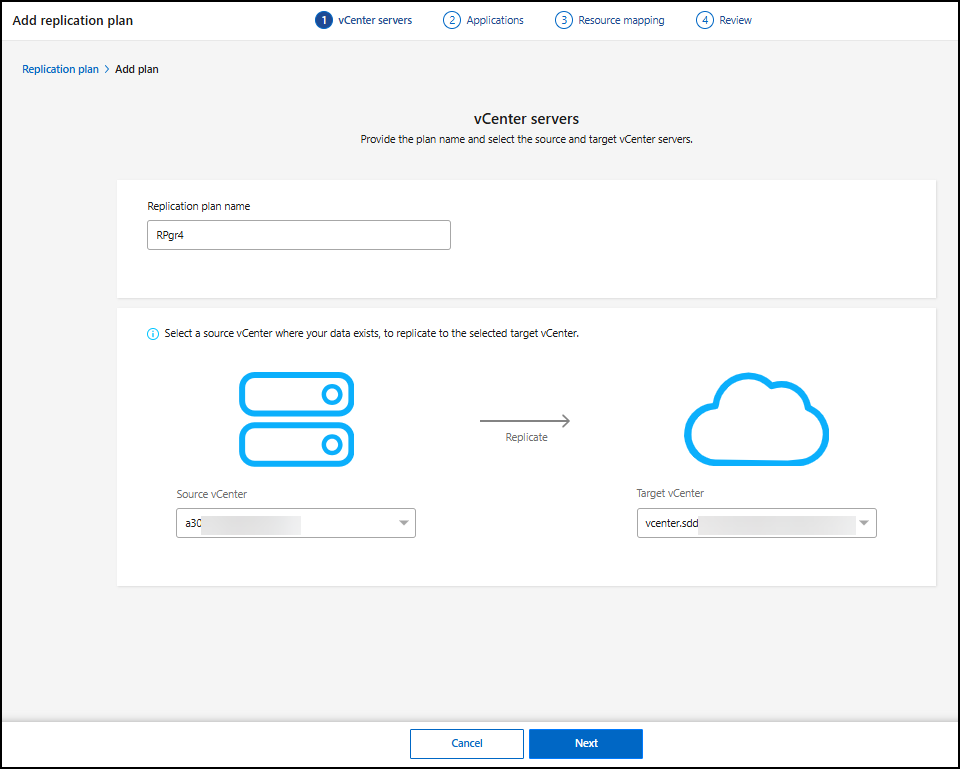
-
Selecione Avançar.
Selecione aplicativos para replicar e atribuir grupos de recursos
O próximo passo é agrupar as VMs, datastores ou clusters Kubernetes necessários em grupos de recursos funcionais. Os grupos de recursos permitem proteger um conjunto de recursos, como um cluster Kubernetes ou uma VM, com um snapshot comum.
Ao criar grupos de recursos, considere as seguintes questões:
-
Antes de adicionar recursos a grupos de recursos, inicie uma descoberta manual ou uma descoberta agendada primeiro. Isso garante que os recursos sejam descobertos e listados no grupo de recursos.
-
Certifique-se de que haja pelo menos uma máquina virtual (VM) no armazenamento de dados. Se não houver VMs no armazenamento de dados, o armazenamento de dados não será descoberto.
-
Um único armazenamento de dados não deve hospedar VMs protegidas por mais de um plano de replicação.
-
Não hospede recursos protegidos e não protegidos no mesmo datastore. Se recursos protegidos e não protegidos forem hospedados no mesmo datastore, você poderá encontrar estes problemas:
-
A capacidade utilizada desse volume pode contribuir para o cálculo do licenciamento porque o Disaster Recovery utiliza SnapMirror, ou seja, o sistema replica volumes ONTAP inteiros. Nesse caso, o espaço do volume consumido por recursos protegidos e não protegidos seria incluído nesse cálculo.
-
Caso o grupo de recursos e seus recursos associados precisem ser transferidos para o site de recuperação de desastres, quaisquer recursos desprotegidos deixarão de existir no site de origem após o processo de failover, resultando na falha desses recursos no site de origem. Além disso, NetApp Disaster Recovery não iniciará esses recursos desprotegidos no site de failover.
-
|
|
Crie um conjunto separado de mapeamentos dedicados para seus testes de failover a fim de evitar que os recursos sejam conectados às redes de produção usando os mesmos endereços IP. |
-
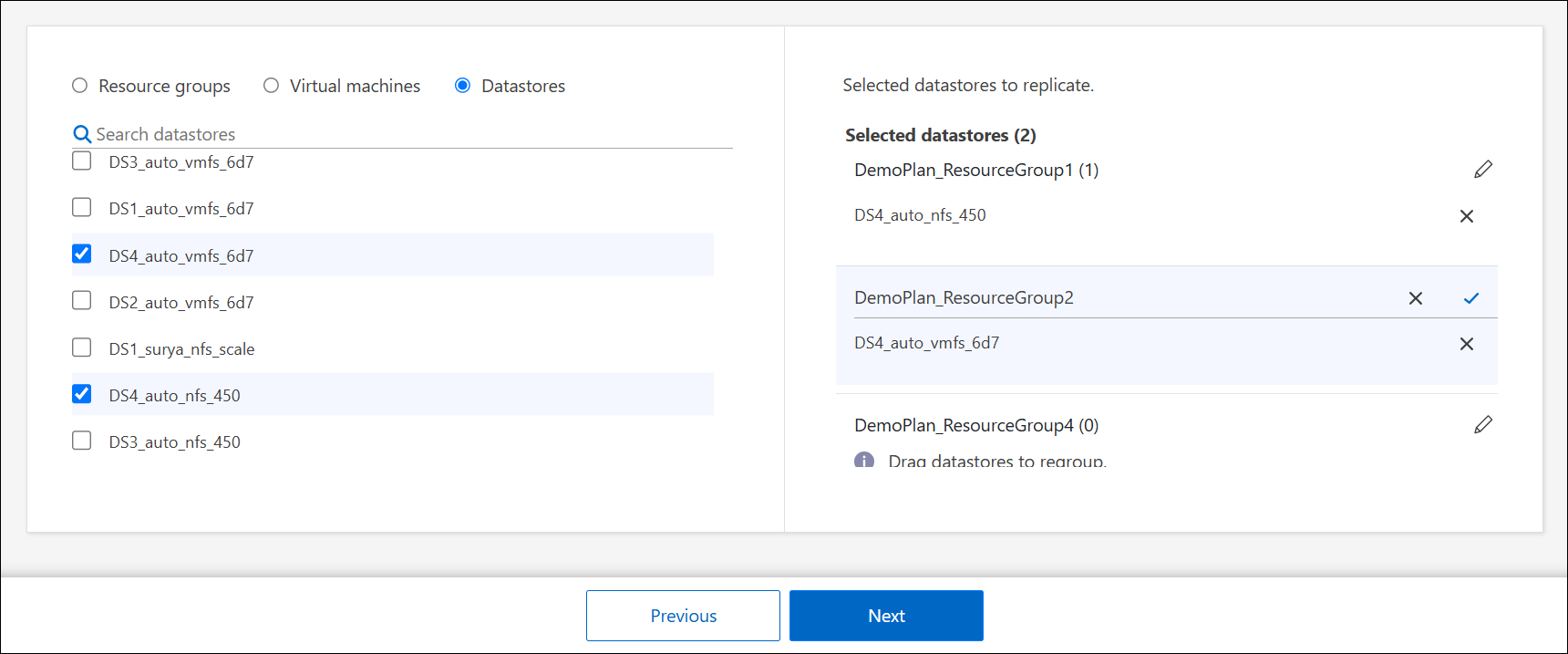
Se você já possui grupos de recursos, selecione Resource groups, escolha o grupo de recursos e clique em Next.
Se você não tiver grupos de recursos existentes ou precisar adicionar recursos a um, selecione Virtual machines ou Datastores.
-
Selecione as máquinas virtuais ou datastores que deseja adicionar ao plano de replicação na lista gerada automaticamente. Para máquinas virtuais, você pode filtrar pelo datastore. Quando você seleciona um datastore ou máquina virtual, ele é adicionado automaticamente a um grupo de recursos.
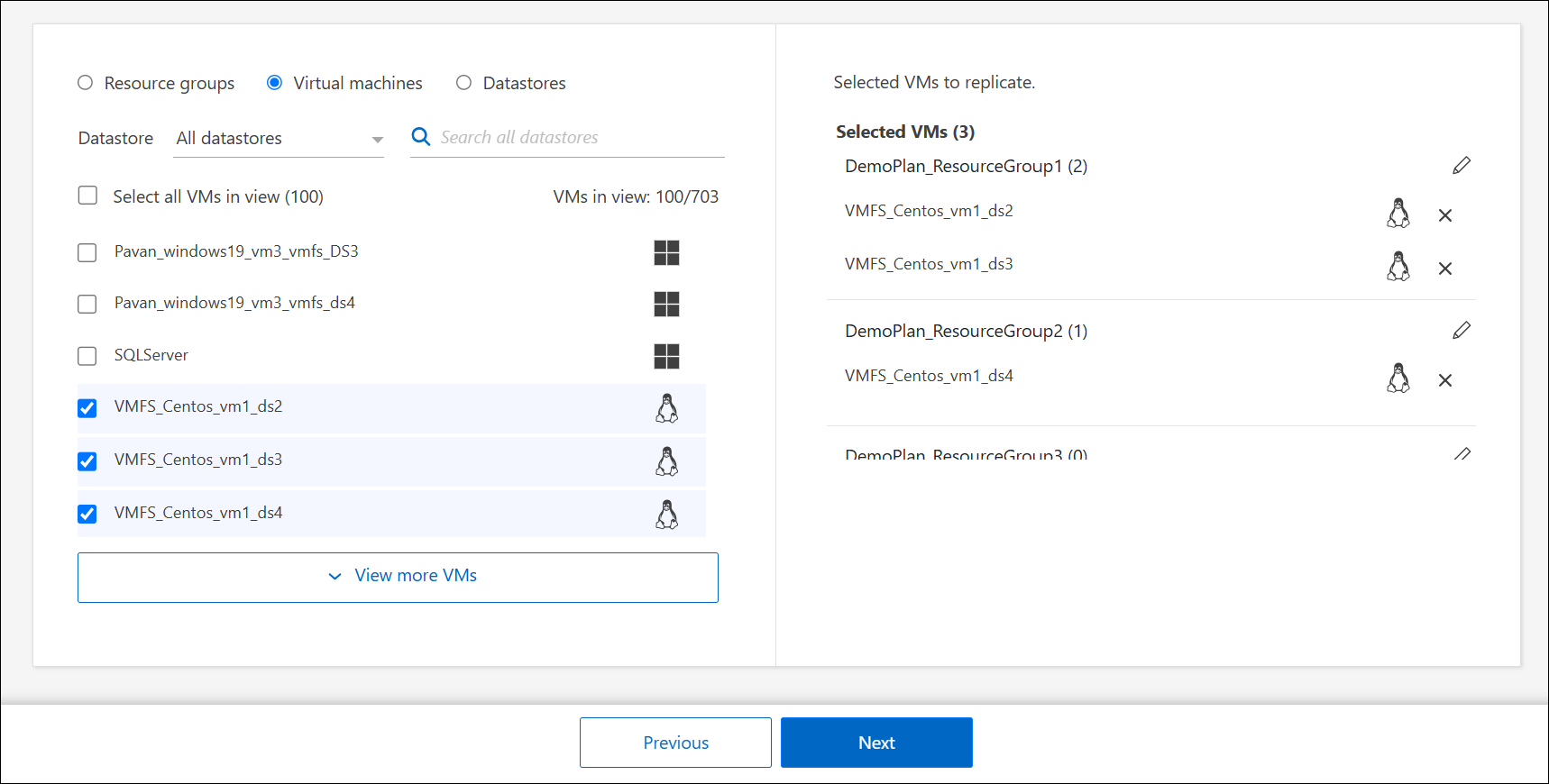
-
Na metade direita da página, revise as VMs ou datastores selecionados.
-
Para remover uma VM ou datastore, passe o cursor sobre o nome da data source e selecione X.
-
Para organizar os recursos em vários grupos de recursos, selecione Clique para adicionar outro grupo de recursos. Depois de adicionar o grupo de recursos, você pode arrastar e soltar recursos entre grupos. Selecione o ícone de lápis* para editar o nome do grupo de recursos.
-
-
Selecione Avançar.
Ao criar um plano de replicação para clusters Kubernetes, os namespaces do Kubernetes em um grupo de recursos devem pertencer ao mesmo cluster ONTAP.
-
Se você já possui grupos de recursos, selecione-os na lista.
Se você não tiver grupos de recursos existentes ou precisar adicionar recursos a um, selecione + Criar novo grupo de recursos. Siga as instruções para "Adicionar namespaces a um grupo de recursos".
Ao nomear um grupo de recursos, os únicos caracteres suportados são letras minúsculas e números.
-
Na coluna alternativa, revise os grupos de recursos selecionados.
-
Selecione Próximo.
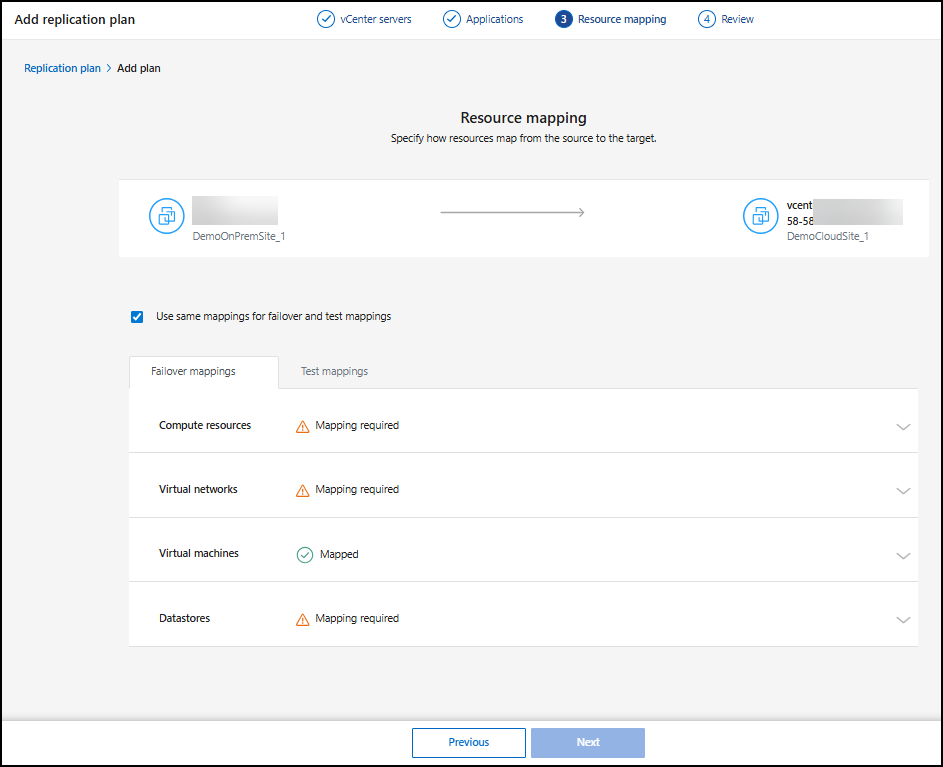
Mapear recursos de origem para o destino
Na etapa Mapeamento de recursos, especifique como os recursos do ambiente de origem devem ser mapeados para o destino. Ao criar um plano de replicação, você pode definir um atraso e uma ordem de inicialização para cada VM no plano. Isso permite que você defina uma sequência para as VMs iniciarem.
Se você planeja executar failovers de teste como parte do seu plano de DR, forneça um conjunto de mapeamentos de failover de teste para garantir que as VMs iniciadas durante o teste de failover não interfiram nas VMs de produção. Você pode fazer isso fornecendo VMs de teste com endereços IP diferentes ou mapeando as NICs virtuais das VMs de teste para uma rede diferente que esteja isolada da produção, mas que tenha a mesma configuração de IP (chamada de bolha ou rede de teste).
Se você quiser criar um relacionamento SnapMirror neste serviço, o cluster e seu peering SVM já deverão ter sido configurados fora do NetApp Disaster Recovery.
-
Na página de mapeamento de recursos, marque a caixa para usar os mesmos mapeamentos tanto para operações de failover quanto para operações de teste.
-
Na guia Mapeamentos de failover, selecione a seta para baixo à direita de cada recurso e mapeie os recursos em cada seção:
-
Recursos de computação
-
Redes virtuais
-
Máquinas virtuais
-
Armazenamentos de dados
-
-
Escolha os mapeamentos de namespace para cada namespace em cada grupo de recursos. Por padrão, o Disaster Recovery seleciona o destino para ser o mesmo que a origem. Você pode escolher um namespace diferente no cluster de destino.
-
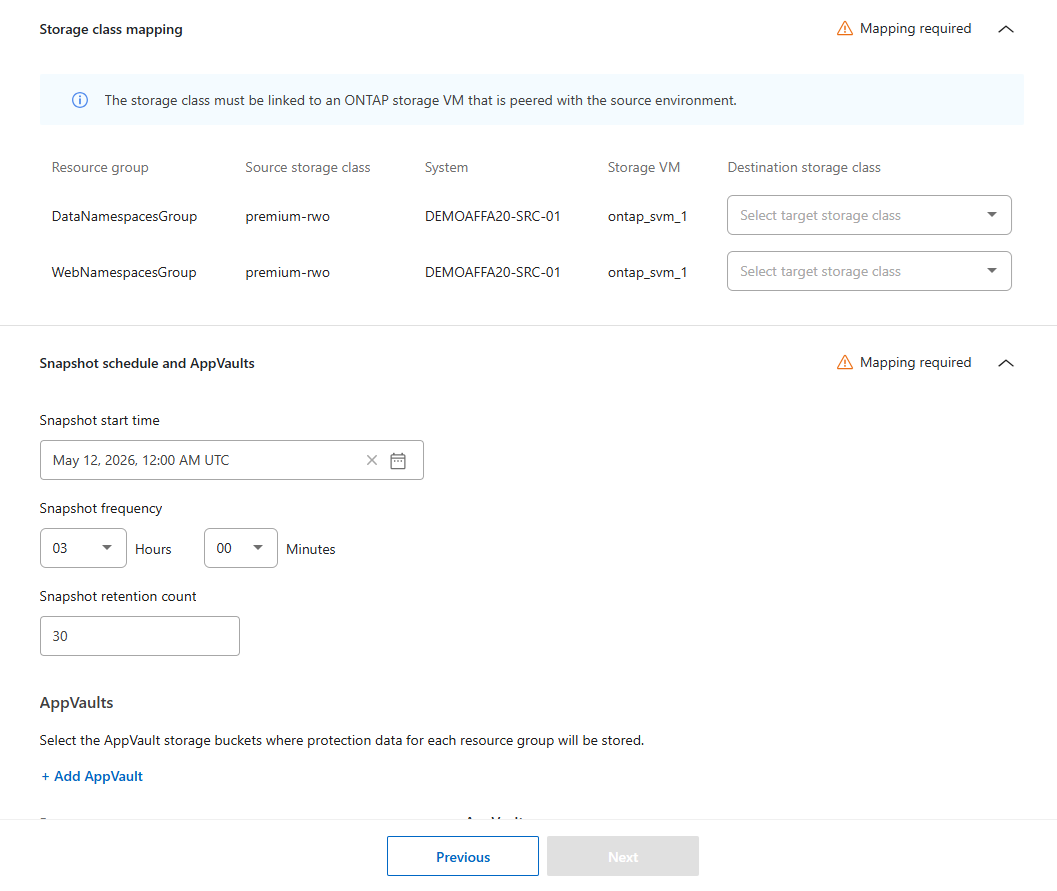
Defina o mapeamento da classe de armazenamento para cada grupo de recursos. A classe de armazenamento deve estar vinculada a uma VM de armazenamento ONTAP emparelhada com o ambiente de origem. A classe de armazenamento padrão do cluster é usada se você não definir uma.
Execute o comando da CLI kubectl get pvc -n <namespace>no namespace para visualizar a classe de armazenamento. -
Defina a programação de snapshots:
Escolha o Horário de início dos Snapshots e da retenção (data e hora do calendário), a Frequência de Snapshots e retenção (com que frequência os snapshots são iniciados) e a Quantidade de retenção de Snapshots (quantos snapshots são salvos).
Ao definir a frequência de Snapshot, o mínimo permitido é de cinco minutos.
-
Selecione Adicionar AppVault para criar o AppVault onde os dados de proteção serão salvos.
-
Insira um Nome e selecione o Agente do Console ao qual o AppVault deve ser conectado.
-
Selecione o provedor de nuvem para hospedar o AppVault.
-
Com base no provedor selecionado, o Disaster Recovery preenche as assinaturas de cloud configuradas existentes. Escolha a Subscription, o Resource group e a Storage account para o cloud provider.
-
Selecione Adicionar.
-
-
Selecione Próximo.
-
Analise os mapeamentos de failover e selecione Add para criar o plano de replicação.
Após selecionar Adicionar, você poderá monitorar as diferentes tarefas em Monitoramento de tarefas.

|
Para o Kubernetes, este é o passo final para criar uma replicação. Para vCenters, continue para o Seção de recursos computacionais. |
Seção de recursos computacionais
A seção Recursos de computação define onde as VMs serão restauradas após um failover. Mapeie o data center e o cluster do vCenter de origem para um data center e cluster de destino.
Opcionalmente, as VMs podem ser reiniciadas em um host vCenter ESXi específico. Se o VMWare DRS estiver habilitado, você poderá mover a VM para um host alternativo automaticamente, se necessário, para atender à política de DR configurada.
Opcionalmente, você pode colocar todas as VMs neste plano de replicação em uma pasta exclusiva com o vCenter. Isso fornece uma maneira fácil de organizar rapidamente VMs com failover no vCenter.
Selecione a seta para baixo ao lado de Recursos de computação.
-
Datacenters de origem e destino
-
Grupo alvo
-
Host de destino (opcional): Depois de selecionar o cluster, você pode definir essas informações.
-
Pasta (opcional)
|
|
Se um vCenter tiver um Distributed Resource Scheduler (DRS) configurado para gerenciar vários hosts em um cluster, você não precisará selecionar um host. Se você selecionar um host, o NetApp Disaster Recovery colocará todas as VMs no host selecionado. * Pasta da VM de destino (opcional): Crie uma nova pasta raiz para armazenar as VMs selecionadas. |
Redes virtuais
As VMs usam NICs virtuais conectadas a redes virtuais. No processo de failover, o serviço conecta essas NICs virtuais às redes virtuais definidas no ambiente VMware de destino. Para cada rede virtual de origem usada pelas VMs no grupo de recursos, o serviço requer uma atribuição de rede virtual de destino.
|
|
Esta seção é obrigatória apenas para vCenters. Você não precisa preenchê-la para Kubernetes. |
|
|
Você pode atribuir várias redes virtuais de origem à mesma rede virtual de destino. No entanto, isso pode criar conflitos de configuração de rede IP. Você pode mapear várias redes de origem para uma única rede de destino para garantir que todas as redes de origem tenham a mesma configuração. |
Na guia Mapeamentos de failover, selecione a seta para baixo ao lado de Redes virtuais. Selecione a LAN virtual de origem e a LAN virtual de destino.
Selecione o mapeamento de rede para a LAN virtual apropriada. As LANs virtuais já devem estar provisionadas, então selecione a LAN virtual apropriada para mapear a VM.
Máquinas virtuais
Você pode configurar cada VM no grupo de recursos protegido pelo plano de replicação para se adequar ao ambiente virtual vCenter de destino, definindo qualquer uma das seguintes opções:
-
O número de CPUs virtuais
-
A quantidade de DRAM virtual
-
A configuração do endereço IP
-
A capacidade de executar scripts de shell do sistema operacional convidado como parte do processo de failover
-
A capacidade de alterar nomes de VMs com failover usando um prefixo e sufixo exclusivos
-
A capacidade de definir a ordem de reinicialização durante o failover da VM
Na guia Mapeamentos de failover, selecione a seta para baixo ao lado de Máquinas virtuais.
O padrão para as VMs é mapeado. O mapeamento padrão usa as mesmas configurações que as VMs usam no ambiente de produção (mesmo endereço IP, máscara de sub-rede e gateway).
Se você fizer alguma alteração nas configurações padrão, deverá alterar o campo IP de destino para "Diferente da origem".
|
|
Se você alterar as configurações para "Diferente da origem", precisará fornecer as credenciais do sistema operacional convidado da VM. |
Esta seção pode exibir campos diferentes dependendo da sua seleção.
Você pode aumentar ou diminuir o número de CPUs virtuais atribuídas a cada VM com failover. No entanto, cada VM requer pelo menos uma CPU virtual. Você pode alterar o número de CPUs virtuais e DRAM virtuais atribuídas a cada VM. O motivo mais comum pelo qual você pode querer alterar as configurações padrão da CPU virtual e da DRAM virtual é se os nós do cluster vCenter de destino não tiverem tantos recursos disponíveis quanto o cluster vCenter de origem.
|
|
Alterne as configurações avançadas para adicionar as configurações Scripts e Consistência do aplicativo. |
Configurações de rede O Disaster Recovery oferece suporte a um amplo conjunto de opções de configuração para redes de máquinas virtuais. Pode ser necessário alterar essas opções se o site de destino tiver redes virtuais que utilizam configurações TCP/IP diferentes das redes virtuais de produção no site de origem.
No nível mais básico (e padrão), as configurações simplesmente usam as mesmas configurações de rede TCP/IP para cada VM no site de destino usadas no site de origem. Isso requer que você configure as mesmas configurações de TCP/IP nas redes virtuais de origem e destino.
O serviço oferece suporte a configurações de rede de IP estático ou DHCP (Dynamic Host Configuration Protocol) para VMs. O DHCP fornece um método baseado em padrões para configurar dinamicamente as configurações TCP/IP de uma porta de rede host. O DHCP deve fornecer, no mínimo, um endereço TCP/IP e também pode fornecer um endereço de gateway padrão (para roteamento para uma conexão de internet externa), uma máscara de sub-rede e um endereço de servidor DNS. O DHCP é comumente usado para dispositivos de computação de usuários finais, como desktops, laptops e conexões de celulares de funcionários, mas também pode ser usado para qualquer dispositivo de computação em rede, como servidores.
-
Opção Usar a mesma máscara de sub-rede, DNS e configurações de gateway: como essas configurações geralmente são as mesmas para todas as VMs conectadas às mesmas redes virtuais, pode ser mais fácil configurá-las uma vez e deixar que o Disaster Recovery use as configurações para todas as VMs no grupo de recursos protegido pelo plano de replicação. Se algumas VMs usarem configurações diferentes, você precisará desmarcar esta caixa e fornecer essas configurações para cada VM.
-
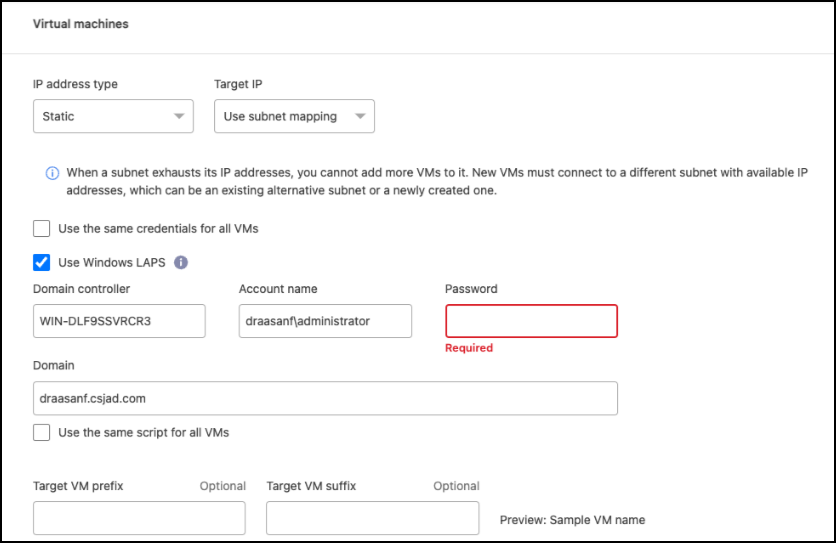
Tipo de endereço IP: Reconfigure as VMs para corresponder aos requisitos da rede virtual de destino. O NetApp Disaster Recovery oferece duas opções: DHCP ou IP estático. Para IPs estáticos, configure a máscara de sub-rede, o gateway e os servidores DNS. Além disso, insira credenciais para VMs.
-
DHCP: Selecione esta configuração se quiser que suas VMs obtenham informações de configuração de rede de um servidor DHCP. Se você escolher esta opção, fornecerá apenas as credenciais para a VM.
-
IP estático: selecione esta configuração se quiser especificar informações de configuração de IP manualmente. Você pode selecionar uma das seguintes opções: igual à origem, diferente da origem ou mapeamento de sub-rede. Se você escolher o mesmo que a fonte, não precisará inserir credenciais. Por outro lado, se você optar por usar informações diferentes da fonte, poderá fornecer as credenciais, o endereço IP da VM, a máscara de sub-rede, o DNS e as informações do gateway. As credenciais do sistema operacional convidado da VM devem ser fornecidas no nível global ou em cada nível de VM.
Isso pode ser muito útil ao recuperar grandes ambientes para clusters de destino menores ou para conduzir testes de recuperação de desastres sem precisar provisionar uma infraestrutura física VMware individual.
-
-
Scripts: Você pode incluir scripts personalizados hospedados no sistema operacional convidado nos formatos .sh, .bat ou .ps1 como pós-processos. Com scripts personalizados, a Recuperação de Desastres pode executar seu script após processos de failover, failback e migração. Por exemplo, você pode usar um script personalizado para retomar todas as transações do banco de dados após a conclusão do failover. O serviço pode executar scripts em máquinas virtuais com Microsoft Windows ou qualquer variante Linux compatível com parâmetros de linha de comando. Você pode atribuir um script a VMs individuais ou a todas as VMs no plano de replicação.
Para habilitar a execução de scripts com o sistema operacional convidado da máquina virtual, as seguintes condições devem ser atendidas:
-
O VMware Tools deve ser instalado na VM.
-
Credenciais de usuário apropriadas devem ser fornecidas com privilégios adequados do sistema operacional convidado para executar o script.
-
Opcionalmente, inclua um valor de tempo limite em segundos para o script.
VMs executando Microsoft Windows: podem executar scripts em lote do Windows (.bat) ou do PowerShell (ps1). Os scripts do Windows podem usar argumentos de linha de comando. Formate cada argumento no
arg_name$valueformato, ondearg_nameé o nome do argumento e$valueé o valor do argumento e um ponto e vírgula separa cadaargument$valuepar.
VMs executando Linux: podem executar qualquer script de shell (.sh) suportado pela versão do Linux usada pela VM. Os scripts do Linux podem usar argumentos de linha de comando. Forneça argumentos em uma lista de valores separados por ponto e vírgula. Argumentos nomeados não são suportados. Adicione cada argumento ao
Arg[x]lista de argumentos e faz referência a cada valor usando um ponteiro paraArg[x]matriz, por exemplo,value1;value2;value3. -
-
Reduzir a versão do hardware da VM e registrá-la: Selecione esta opção se a versão do host ESX de destino for anterior à de origem, para que correspondam durante o registro.
-
Manter a hierarquia de pastas original: Por padrão, a Recuperação de Desastres mantém a hierarquia de inventário da VM (estrutura de pastas) em caso de failover. Se o destino da recuperação não tiver a hierarquia de pastas original, a Recuperação de Desastres a criará.
Desmarque esta caixa para ignorar a hierarquia de pastas original.
-
Prefixo e sufixo da VM de destino: nos detalhes das máquinas virtuais, você pode, opcionalmente, adicionar um prefixo e um sufixo a cada nome de VM com failover. Isso pode ser útil para diferenciar as VMs com failover das VMs de produção em execução no mesmo cluster do vCenter. Por exemplo, você pode adicionar um prefixo "DR-" e um sufixo "-failover" ao nome da VM. Algumas pessoas adicionam um segundo vCenter de produção para hospedar VMs temporariamente em um site diferente no caso de um desastre. Adicionar um prefixo ou sufixo pode ajudar você a identificar rapidamente VMs com failover. Você também pode usar o prefixo ou sufixo em scripts personalizados.
Você pode usar o método alternativo de definir a pasta da VM de destino na seção Recursos de computação.
-
CPU e Memória (GB): nas configurações da máquina virtual, você pode, opcionalmente, redimensionar a CPU e memória.
Você pode configurar a DRAM em gigabytes (GiB) ou megabytes (MiB). Embora cada VM exija pelo menos um MiB de RAM, a quantidade real deve garantir que o sistema operacional convidado da VM e quaisquer aplicativos em execução possam operar com eficiência. -
Ordem de inicialização: Você pode modificar a ordem de inicialização após um failover para todas as máquinas virtuais selecionadas nos grupos de recursos. Por padrão, todas as VMs inicializam juntas em paralelo; no entanto, você pode fazer alterações nesta fase. Isso é útil para garantir que todas as suas VMs de prioridade um estejam em execução antes que as VMs de prioridade subsequentes sejam iniciadas.
A Recuperação de Desastres inicializa em paralelo quaisquer máquinas virtuais com o mesmo número de ordem de inicialização.
-
Inicialização sequencial: atribua a cada VM um número exclusivo para inicializar na ordem atribuída, por exemplo, 1,2,3,4,5.
-
Inicialização simultânea: atribua o mesmo número a todas as VMs para inicializá-las ao mesmo tempo, por exemplo, 1,1,1,1,2,2,3,4,4.
-
-
Atraso na inicialização: ajuste o atraso em minutos da ação de inicialização, indicando a quantidade de tempo que a VM aguardará antes de iniciar o processo de inicialização. Insira um valor de 0 a 10 minutos.
-
Consistência do aplicativo: indique se deseja criar cópias de snapshot consistentes com o aplicativo. O serviço irá suspender o aplicativo e, em seguida, criar um snapshot para obter um estado consistente do aplicativo. Este recurso é compatível com Oracle em execução no Windows e Linux e SQL Server em execução no Windows. Veja mais detalhes a seguir.
Você deve alternar a opção Advance settings para esta configuração. Se você ativar a consistência do aplicativo, você deve fornecer credenciais na forma de nome de usuário e senha.
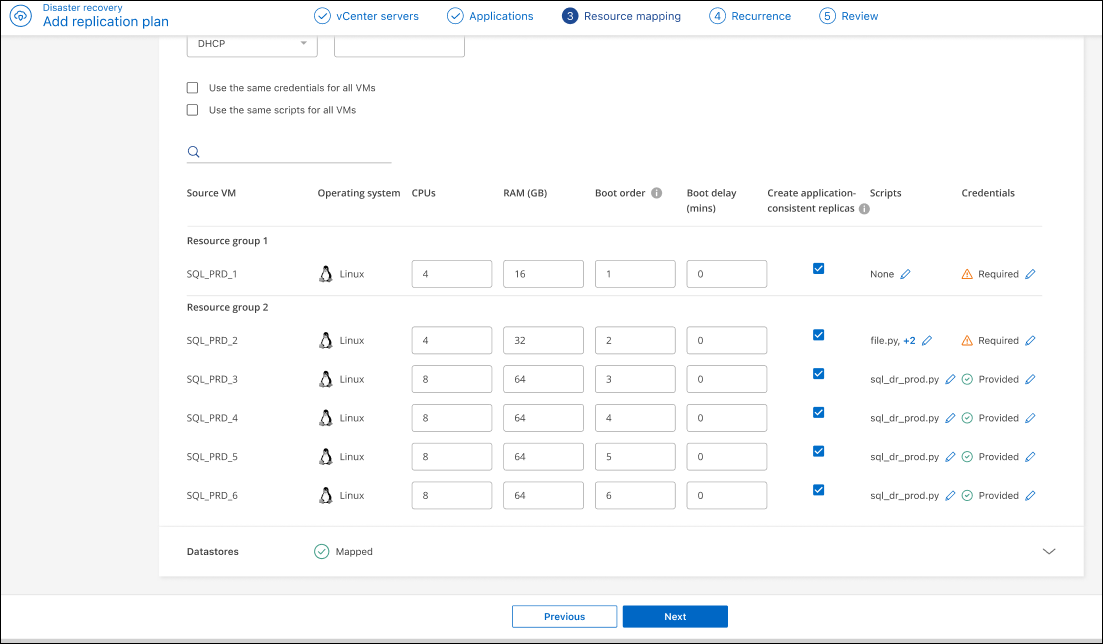
Crie réplicas consistentes com o aplicativo
Muitas VMs hospedam servidores de banco de dados como Oracle ou Microsoft SQL Server. Esses servidores de banco de dados exigem instantâneos consistentes com o aplicativo para garantir que o banco de dados esteja em um estado consistente quando o instantâneo for tirado.
Snapshots consistentes com o aplicativo garantem que o banco de dados esteja em um estado consistente quando o snapshot é tirado. Isso é importante porque garante que o banco de dados possa ser restaurado para um estado consistente após uma operação de failover ou failback.
Os dados gerenciados pelo servidor de banco de dados podem ser hospedados no mesmo armazenamento de dados que a VM que hospeda o servidor de banco de dados ou podem ser hospedados em um armazenamento de dados diferente. A tabela a seguir mostra as configurações suportadas para snapshots consistentes com o aplicativo na Recuperação de Desastres:
| Localização dos dados | Suportado | Notas |
|---|---|---|
No mesmo armazenamento de dados do vCenter que a VM |
Sim |
Como o servidor de banco de dados e o banco de dados residem no mesmo armazenamento de dados, tanto o servidor quanto os dados estarão sincronizados no failover. |
Dentro de um armazenamento de dados vCenter diferente da VM |
Não |
O Disaster Recovery não consegue identificar quando os dados de um servidor de banco de dados estão em um armazenamento de dados diferente do vCenter. O serviço não pode replicar os dados, mas pode replicar a VM do servidor de banco de dados. Embora os dados do banco de dados não possam ser replicados, o serviço garante que o servidor de banco de dados execute todas as etapas necessárias para garantir que o banco de dados esteja inativo no momento do backup da VM. |
Dentro de uma fonte de dados externa |
Não |
Se os dados residirem em um LUN montado no convidado ou em um compartilhamento NFS, o Disaster Recovery não poderá replicar os dados, mas poderá replicar a VM do servidor de banco de dados. Embora os dados do banco de dados não possam ser replicados, o serviço garante que o servidor de banco de dados execute todas as etapas necessárias para garantir que o banco de dados esteja inativo no momento do backup da VM. |
Durante um backup agendado, o Disaster Recovery desativa o servidor de banco de dados e, em seguida, tira um instantâneo da VM que hospeda o servidor de banco de dados. Isso garante que o banco de dados esteja em um estado consistente quando o instantâneo for tirado.
-
Para VMs do Windows, o serviço usa o Microsoft Volume Shadow Copy Service (VSS) para coordenar com qualquer servidor de banco de dados.
-
Para VMs Linux, o serviço usa um conjunto de scripts para colocar o servidor Oracle no modo de backup.
Para habilitar réplicas consistentes com o aplicativo das VMs e seus armazenamentos de dados de hospedagem, marque a caixa ao lado de Criar réplicas consistentes com o aplicativo para cada VM e forneça credenciais de login de convidado com os privilégios apropriados.
Seção de datastores
Os datastores VMware são hospedados em volumes ONTAP FlexVol ou em LUNs ONTAP iSCSI ou FC usando VMware VMFS. Use a seção Datastores para definir o cluster ONTAP de destino, a máquina virtual de armazenamento (SVM) e o volume ou LUN para replicar os dados no disco para o destino.
Selecione a seta para baixo ao lado de Datastores. Com base na seleção de VMs, os mapeamentos de armazenamento de dados são selecionados automaticamente.
Esta seção pode ser ativada ou desativada dependendo da sua seleção.
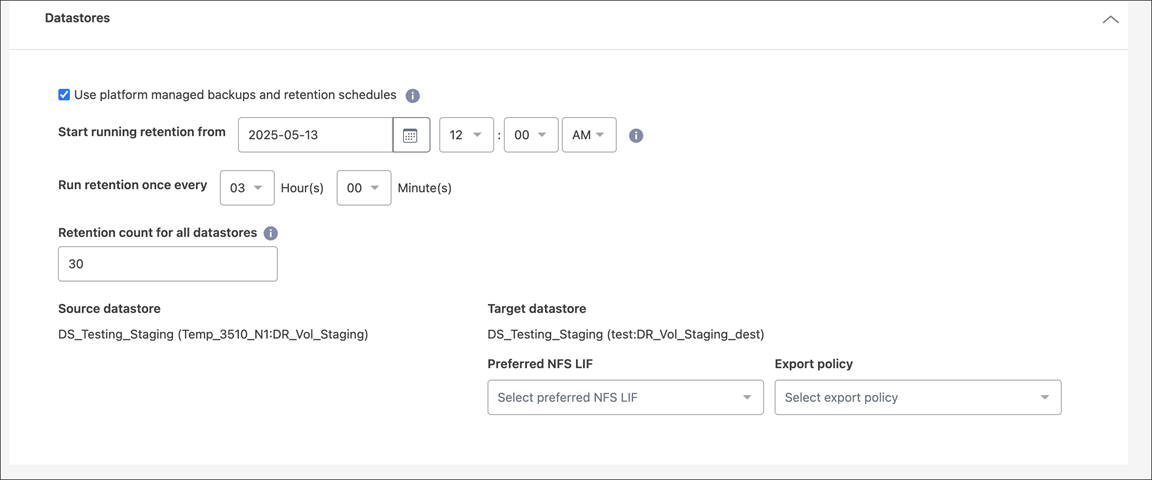
-
Usar backups gerenciados pela plataforma e agendamentos de retenção: se estiver usando uma solução externa de gerenciamento de snapshots, marque esta caixa. O NetApp Disaster Recovery oferece suporte ao uso de soluções externas de gerenciamento de snapshots, como o agendador de políticas nativo ONTAP SnapMirror ou integrações de terceiros. Se cada armazenamento de dados (volume) no plano de replicação já tiver um relacionamento SnapMirror que esteja sendo gerenciado em outro lugar, você poderá usar esses instantâneos como pontos de recuperação no NetApp Disaster Recovery.
Quando esta opção é selecionada, o NetApp Disaster Recovery não configura um agendamento de backup. No entanto, você ainda precisa configurar um cronograma de retenção porque snapshots ainda podem ser tirados para operações de teste, failover e failback.
Depois que isso for configurado, o serviço não fará nenhum snapshot agendado regularmente, mas dependerá da entidade externa para tirar e atualizar esses snapshots.
-
Horário de início dos backups e da retenção: insira a data e a hora em que deseja que os backups e a retenção comecem a ser executados.
-
Frequência de backups e retenção: Insira o intervalo de tempo em horas e minutos. Por exemplo, se você inserir 1 hora, o serviço fará um snapshot a cada hora.
-
Retenção para todos os datastores: Insira o número de snapshots que você deseja reter.
O número de instantâneos retidos, juntamente com a taxa de alteração de dados entre cada instantâneo, determina a quantidade de espaço de armazenamento consumido na origem e no destino. Quanto mais instantâneos você retém, mais espaço de armazenamento é consumido. -
Datastores de origem e destino: Se houver vários relacionamentos SnapMirror (fan-out), você poderá selecionar o destino a ser usado. Se um volume já tiver um relacionamento SnapMirror estabelecido, os armazenamentos de dados de origem e destino correspondentes serão exibidos. Se um volume não tiver um relacionamento SnapMirror , você poderá criar um agora selecionando um cluster de destino, selecionando um SVM de destino e fornecendo um nome de volume. O serviço criará o volume e o relacionamento do SnapMirror .
Se você quiser criar um relacionamento SnapMirror neste serviço, o cluster e seu peering SVM já deverão ter sido configurados fora do NetApp Disaster Recovery. -
Se as VMs forem do mesmo volume e do mesmo SVM, o serviço executará um snapshot ONTAP padrão e atualizará os destinos secundários.
-
Se as VMs forem de volumes diferentes e do mesmo SVM, o serviço criará um instantâneo do grupo de consistência incluindo todos os volumes e atualizará os destinos secundários.
-
Se as VMs forem de volumes diferentes e SVMs diferentes, o serviço executará um instantâneo da fase de início do grupo de consistência e da fase de confirmação, incluindo todos os volumes no mesmo cluster ou em um cluster diferente e atualizando os destinos secundários.
-
Durante o failover, você pode selecionar qualquer snapshot. Se você selecionar o snapshot mais recente, o serviço criará um backup sob demanda, atualizará o destino e usará esse snapshot para o failover.
-
Adicionar mapeamentos de failover de teste
-
Para definir mapeamentos diferentes para o ambiente de teste, desmarque a caixa e selecione a aba Mapeamentos de teste.
-
Percorra cada aba como antes, mas desta vez para o ambiente de teste.
Na guia Mapeamentos de teste, os mapeamentos de máquinas virtuais e armazenamentos de dados estão desabilitados.
Você pode testar o plano completo mais tarde. Agora, você está configurando os mapeamentos para o ambiente de teste.
Revise o plano de replicação
Por fim, reserve alguns minutos para revisar o plano de replicação.
|
|
Mais tarde, você pode desabilitar ou excluir o plano de replicação. |
-
Revise as informações em cada guia: Detalhes do plano, Mapeamento de failover e VMs.
-
Selecione Adicionar plano.
O plano é adicionado à lista de planos.
Modificar um plano de replicação
Você pode modificar o agendamento de um plano de replicação para testar a conformidade e garantir que os testes de failover sejam concluídos com sucesso.
-
Impacto no tempo de conformidade: quando um plano de replicação é criado, o serviço cria um cronograma de conformidade por padrão. O tempo de conformidade padrão é de 30 minutos. Para alterar esse horário, você pode editar o agendamento no plano de replicação.
-
Impacto do failover de teste: Você pode testar um processo de failover sob demanda ou por meio de um agendamento. Isso permite que você teste o failover de máquinas virtuais para um destino especificado em um plano de replicação.
Um failover de teste cria um volume FlexClone , monta o armazenamento de dados e move a carga de trabalho para esse armazenamento de dados. Uma operação de failover de teste não afeta as cargas de trabalho de produção, o relacionamento SnapMirror usado no site de teste e as cargas de trabalho protegidas que devem continuar operando normalmente.
Com base no cronograma, o teste de failover é executado e garante que as cargas de trabalho sejam movidas para o destino especificado pelo plano de replicação.
-
No menu NetApp Disaster Recovery , selecione Planos de replicação.
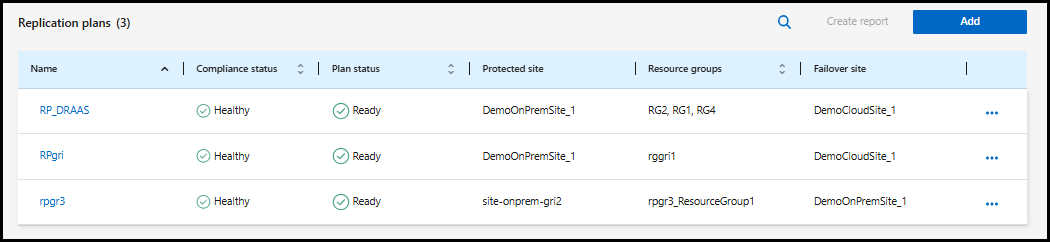
-
Selecione as Ações*
 ícone e selecione *Editar agendamentos.
ícone e selecione *Editar agendamentos. -
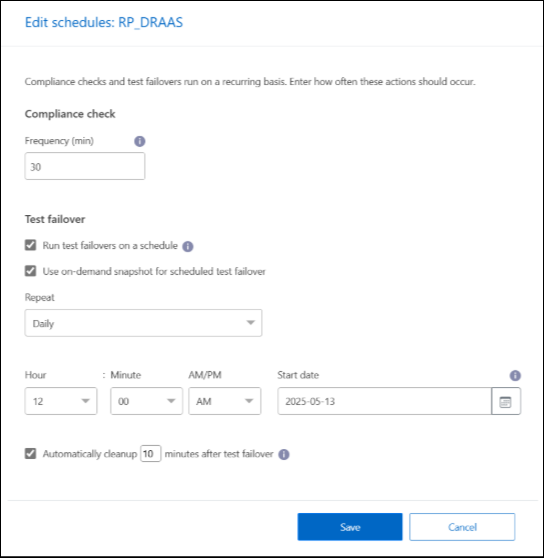
Insira com que frequência, em minutos, você deseja que o NetApp Disaster Recovery verifique a conformidade do teste.
-
Para verificar se seus testes de failover estão íntegros, marque Executar failovers em uma programação mensal.
-
Selecione o dia do mês e a hora em que deseja que esses testes sejam executados.
-
Insira a data no formato aaaa-mm-dd em que você deseja que o teste comece.
-
-
Usar snapshot sob demanda para failover de teste agendado: Para tirar um novo snapshot antes de iniciar o failover de teste automatizado, marque esta caixa.
-
Para limpar o ambiente de teste após a conclusão do teste de failover, marque Limpar automaticamente após o failover do teste e insira o número de minutos que você deseja aguardar antes que a limpeza comece.
Este processo cancela o registro das VMs temporárias do local de teste, exclui o volume FlexClone que foi criado e desmonta os armazenamentos de dados temporários. -
Selecione Salvar.