

Validação da solução - cenários validados
 Sugerir alterações
Sugerir alterações
A solução FlexPod Datacenter SM-BC protege os serviços de dados para uma variedade de cenários de ponto único de falha, bem como para um desastre no local. O design redundante implementado em cada local fornece alta disponibilidade, e a implementação SM-BC com replicação síncrona de dados entre locais protege os serviços de dados de um desastre em todo o site de um local. A solução implantada é validada para as funções de solução desejadas e vários cenários de falha para os quais a solução foi projetada para proteger.
Validação das funções da solução
Uma variedade de casos de teste são usados para verificar as funções da solução e simular cenários de falha parcial e completa do local. Para minimizar a duplicação com os testes já realizados nas soluções de datacenter FlexPod existentes no Programa de Design validado da Cisco, o foco deste relatório é nos aspetos relacionados à SM-BC da solução. Algumas validações gerais do FlexPod são incluídas para que os profissionais passem por suas validações de implementação.
Para a validação da solução, uma máquina virtual do Windows 10 por host ESXi foi criada em todos os hosts ESXi em ambos os sites. A ferramenta Iometer foi instalada e usada para gerar e/S para dois discos de dados virtuais que são mapeados a partir dos armazenamentos de dados iSCSI locais compartilhados. Os parâmetros de carga de trabalho do Iometer configurados foram I/o de 8 KB, 75% leitura e 50% aleatória, com 8 comandos de e/S pendentes para cada disco de dados. Para a maioria dos cenários de teste realizados, a continuação do Iometer I/o serve como uma indicação de que o cenário não causou uma interrupção do serviço de dados.
Como o SM-BC é essencial para aplicativos empresariais, como servidores de banco de dados, a instância do Microsoft SQL Server 2019 em uma máquina virtual do Windows Server 2022 também foi incluída como parte do teste para confirmar que o aplicativo continua a ser executado quando o armazenamento em seu local local não está disponível e o serviço de dados é retomado no armazenamento do local remoto sem interrupções do aplicativo.
Teste de inicialização da SAN iSCSI do host ESXi
Os hosts ESXi na solução são configurados para inicializar a partir de SAN iSCSI. O uso da inicialização SAN simplifica o gerenciamento do servidor ao substituir um servidor, pois o perfil de serviço do servidor pode ser associado a um novo servidor para que ele seja inicializado sem fazer alterações adicionais de configuração.
Além de inicializar um host ESXi localizado em um local a partir de seu LUN de inicialização iSCSI local, testes também foram realizados para inicializar o host ESXi quando seu controlador de armazenamento local estiver em um estado de aquisição ou quando seu cluster de armazenamento local estiver completamente indisponível. Esses cenários de validação garantem que os hosts ESXi estejam configurados adequadamente por design e possam ser inicializados durante um cenário de manutenção de armazenamento ou desastre para recuperação de desastres para fornecer continuidade de negócios.
Antes de configurar a relação de grupo de consistência SM-BC, um iSCSI LUN hospedado por um par de HA de controladora de storage tem quatro caminhos, dois por cada malha iSCSI, com base na implementação de práticas recomendadas. Um host pode chegar ao LUN através das duas VLANs/malhas iSCSI para o controlador de hospedagem LUN, bem como através do parceiro de alta disponibilidade do controlador.
Depois que a relação de grupo de consistência SM-BC é configurada e os LUNs espelhados são mapeados adequadamente para os iniciadores, a contagem de caminho para o LUN dobra. Para essa implementação, passa de ter dois caminhos ativos/otimizados e dois caminhos ativos/não otimizados para ter dois caminhos ativos/otimizados e seis caminhos ativos/não otimizados.
A figura a seguir ilustra os caminhos que um host ESXi pode levar para acessar um LUN, por exemplo, LUN 0. Como o LUN é anexado ao site Um controlador 01, apenas os dois caminhos que acessam diretamente o LUN por meio desse controlador são ativos/otimizados e todos os seis caminhos restantes são ativos/não otimizados.
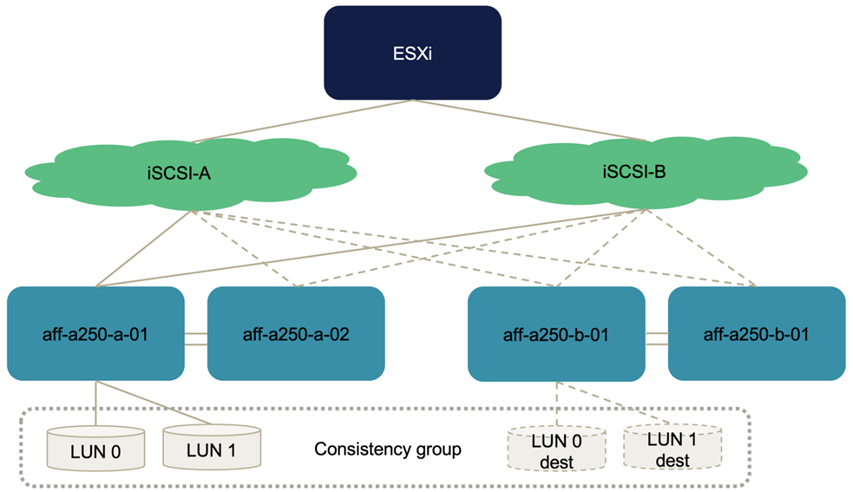
A captura de tela a seguir das informações de caminho do dispositivo de armazenamento mostra como o host ESXi vê os dois tipos de caminhos de dispositivo. Os dois caminhos ativos/otimizados são mostrados como tendo active (I/O) o status do caminho, enquanto os seis caminhos ativos/não otimizados são mostrados apenas active como . Observe também que a coluna destino mostra os dois destinos iSCSI e os respetivos endereços IP iSCSI LIF para chegar aos destinos.
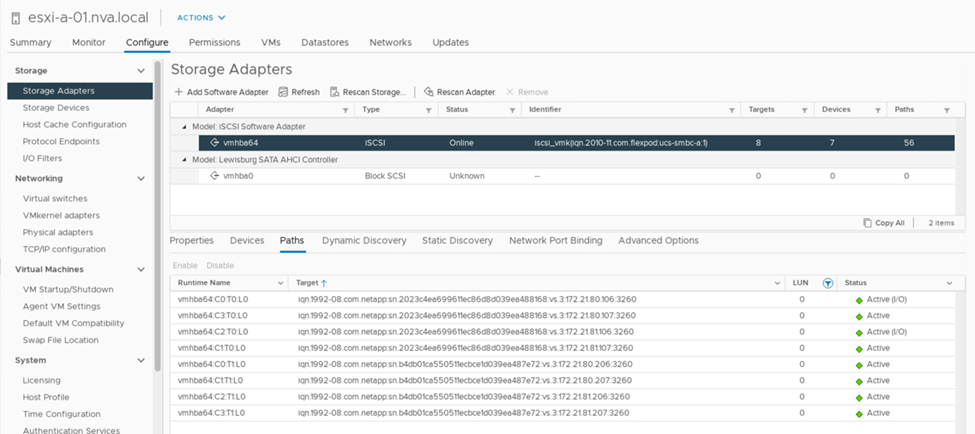
Quando um dos controladores de storage está inativo para manutenção ou atualização, os dois caminhos que alcançam o controlador inativo não estão mais disponíveis e aparecem com o status do caminho dead.
Se um failover do grupo de consistência ocorrer no cluster de storage primário, seja devido a testes de failover manual ou failover automático, o cluster de storage secundário continuará a fornecer serviços de dados para as LUNs no grupo de consistência SM-BC. Como as identidades LUN são preservadas e os dados foram replicados de forma síncrona, todos os LUNs de inicialização do host ESXi protegidos por grupos de consistência SM-BC permanecem disponíveis no cluster de armazenamento remoto.
Teste de afinidade de VM/host e VMware vMotion
Embora uma solução genérica de data center VMware FlexPod ofereça suporte a vários protocolos, como FC, iSCSI, NVMe e NFS, o recurso da solução FlexPod SM-BC oferece suporte a protocolos SAN FC e iSCSI, normalmente usados para soluções essenciais aos negócios. Esta validação utiliza apenas armazenamentos de dados baseados em protocolo iSCSI e arranque SAN iSCSI.
Para permitir que máquinas virtuais usem serviços de armazenamento de qualquer local SM-BC, os armazenamentos de dados iSCSI de ambos os locais devem ser montados por todos os hosts do cluster para permitir a migração de máquinas virtuais entre os dois locais e para cenários de failover de desastres.
Para aplicações executadas na infraestrutura virtual que não exigem a proteção do grupo de consistência SM-BC nos locais, o protocolo NFS e os datastores NFS também podem ser usados. Nesse caso, deve ser observado cuidado ao alocar o storage para VMs para que as aplicações essenciais aos negócios estejam usando adequadamente os datastores SAN protegidos pelo grupo de consistência SM-BC para fornecer continuidade dos negócios.
A captura de tela a seguir mostra que os hosts estão configurados para montar armazenamentos de dados iSCSI de ambos os sites.
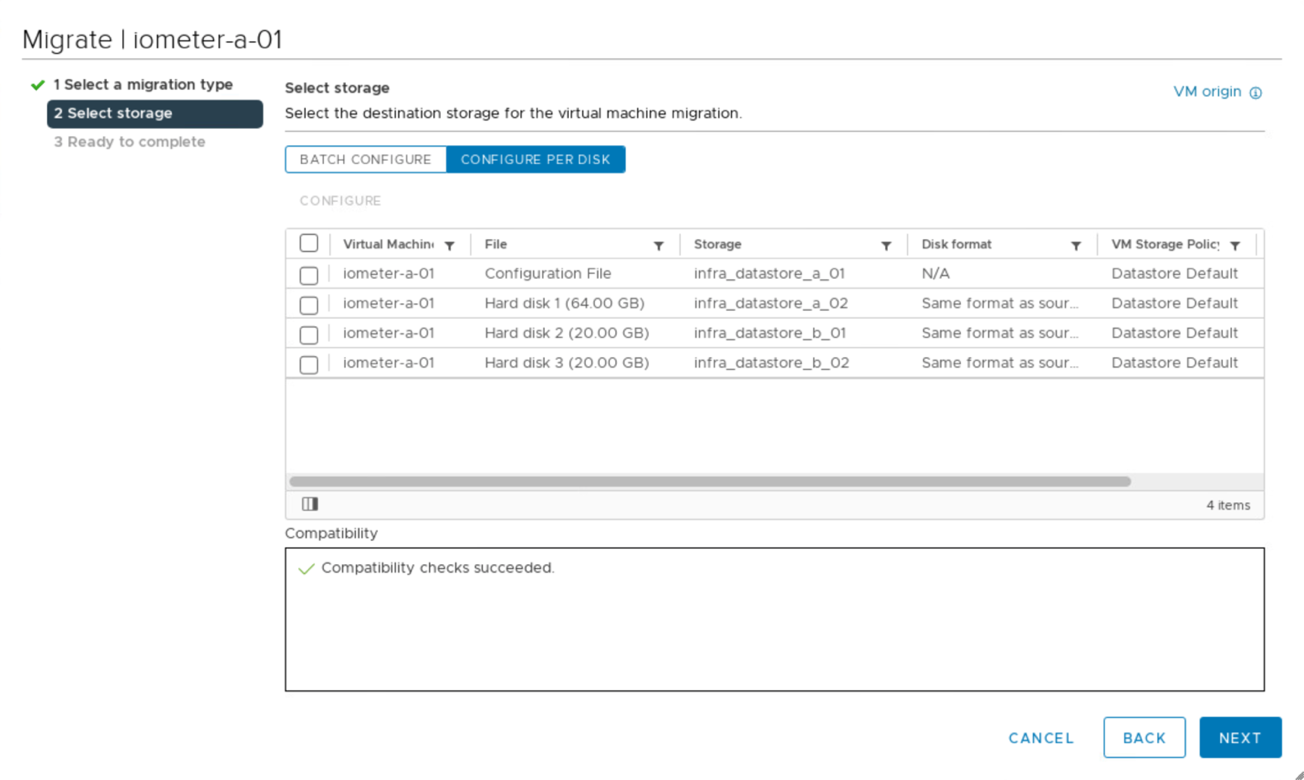
Você tem a opção de migrar discos de máquina virtual entre armazenamentos de dados iSCSI disponíveis de ambos os sites, como mostrado na figura a seguir. Para considerações de desempenho, é ótimo ter máquinas virtuais que usam storage de seu cluster de storage local para reduzir as latências de e/S de disco. Isto é especialmente verdadeiro quando os dois locais estão localizados a algumas distâncias distante devido à latência física da distância de ida e volta de aproximadamente 1msm por 100kmm de distância.
Testes de vMotion de máquinas virtuais para um host diferente no mesmo site, bem como em todos os sites foram realizados e foram bem-sucedidos. Depois de migrar manualmente uma máquina virtual entre sites, a regra de afinidade VM/Host ativa e migra a máquina virtual de volta para o grupo onde ela pertence sob a condição normal.
Failover de storage planejado
As operações de failover de armazenamento planejadas devem ser executadas na solução após a configuração inicial para determinar se a solução está funcionando corretamente após o failover de armazenamento. Os testes podem ajudar a identificar quaisquer problemas de conetividade ou configuração que possam levar a interrupções de e/S. Testar e resolver regularmente quaisquer problemas de conetividade ou configuração ajuda a fornecer serviços de dados ininterruptos quando ocorre um desastre no local real. O failover de armazenamento planejado também pode ser usado antes de uma atividade de manutenção de armazenamento agendada para que os serviços de dados possam ser atendidos a partir do local não afetado.
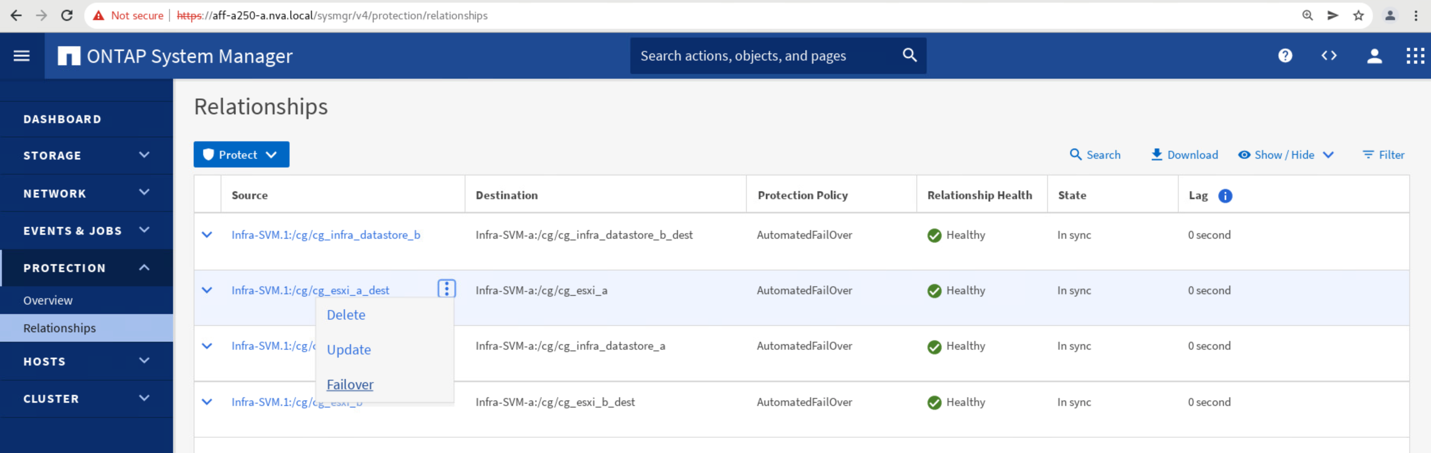
Para iniciar um failover manual dos serviços de dados de armazenamento do local A para o local B, você pode usar o local B ONTAP System Manager para executar a ação.
-
Navegue até a tela proteção > relacionamentos para confirmar se o estado da relação do grupo de consistência é
In Sync. Se ele ainda estiverSynchronizingno estado, aguarde até que o estado se torneIn Syncantes de executar um failover. -
Expanda os pontos ao lado do nome da fonte e clique em failover.
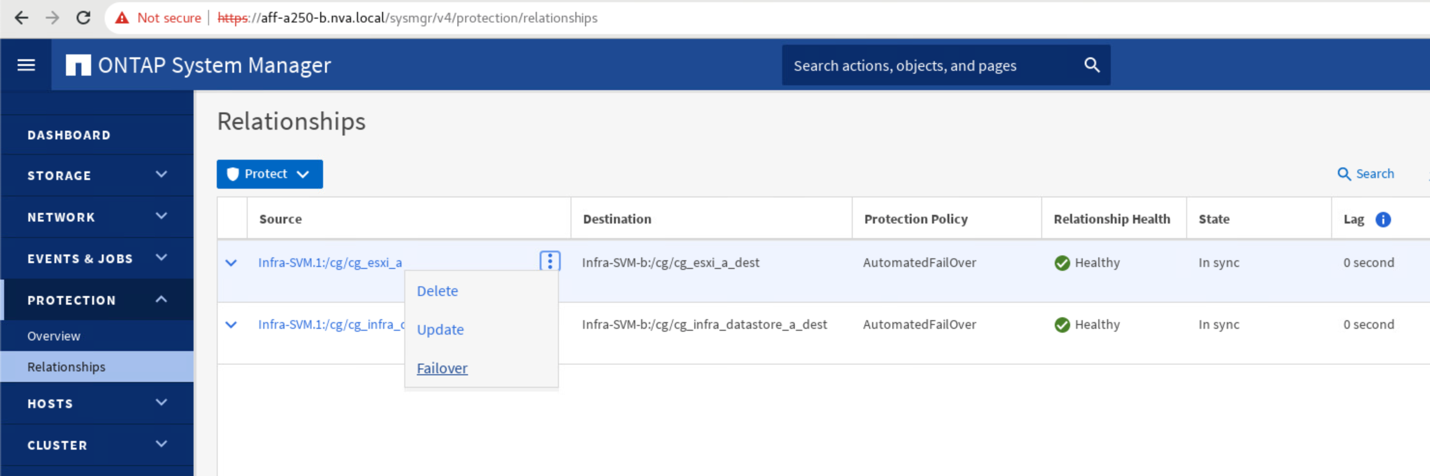
-
Confirme o failover para que a ação seja iniciada.
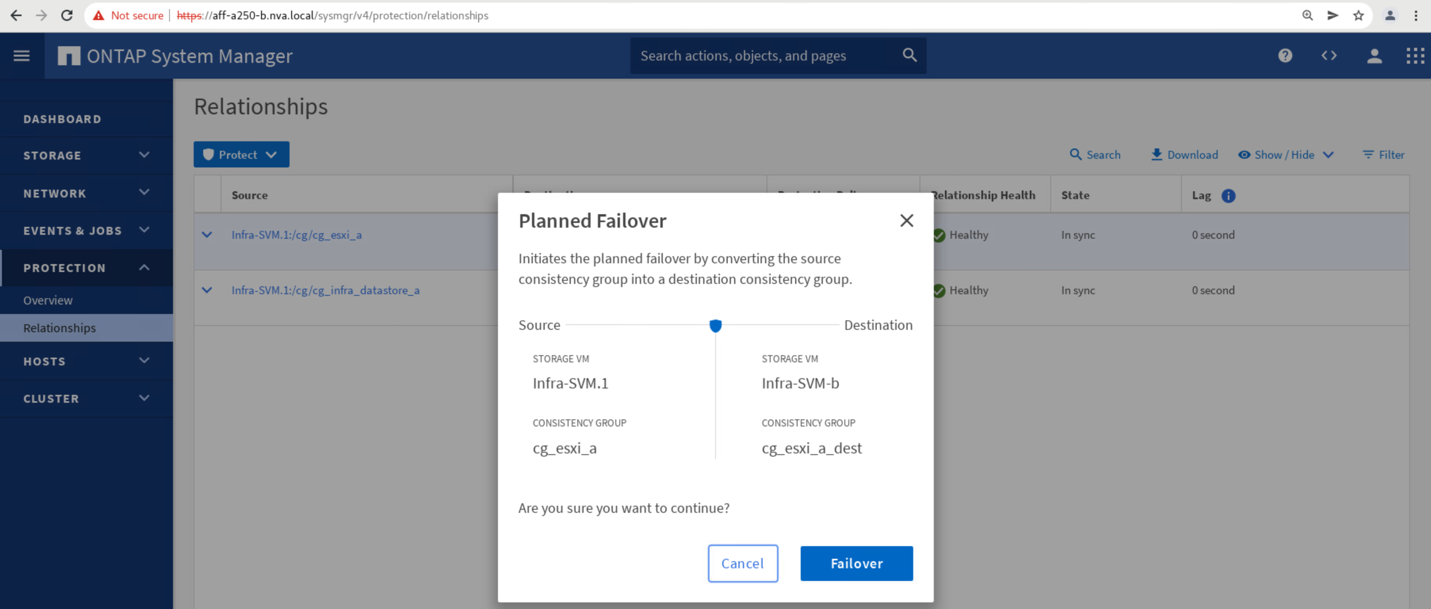
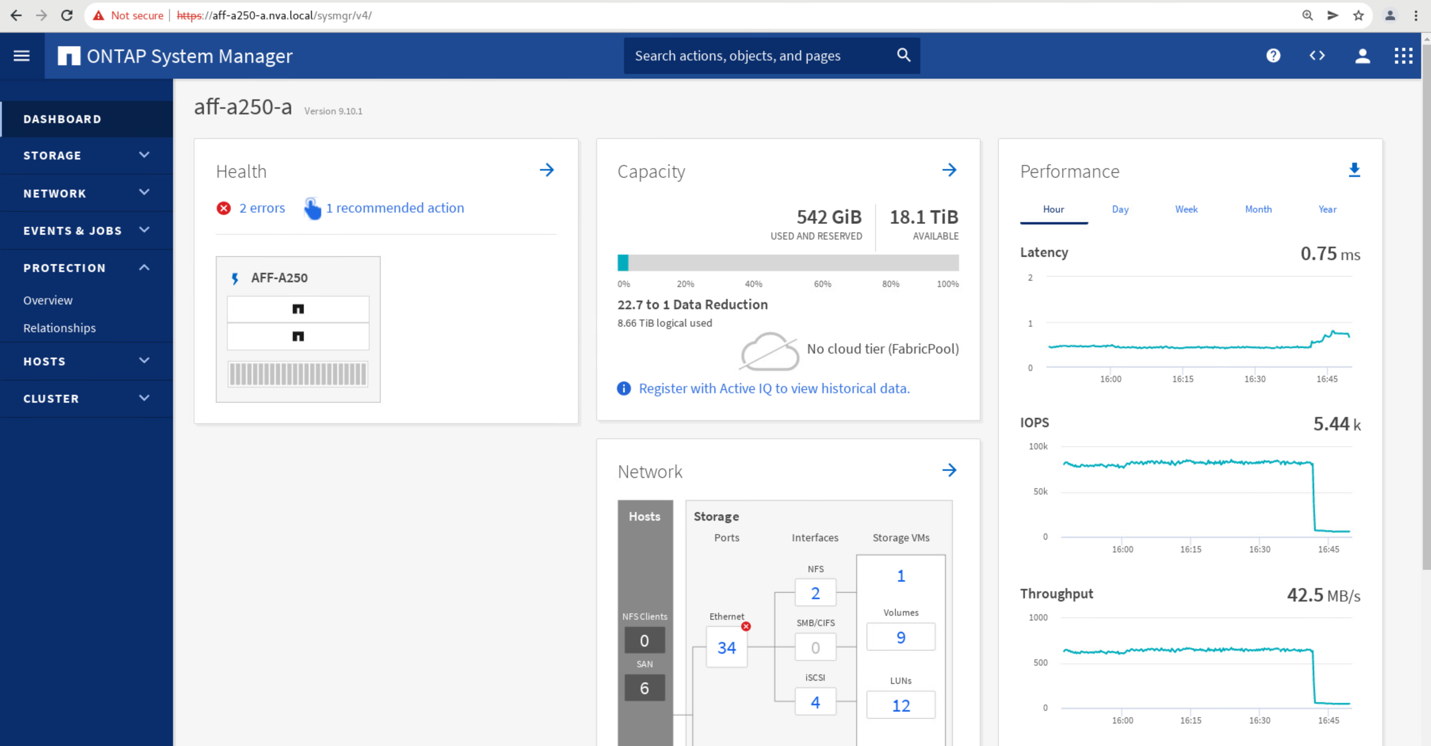
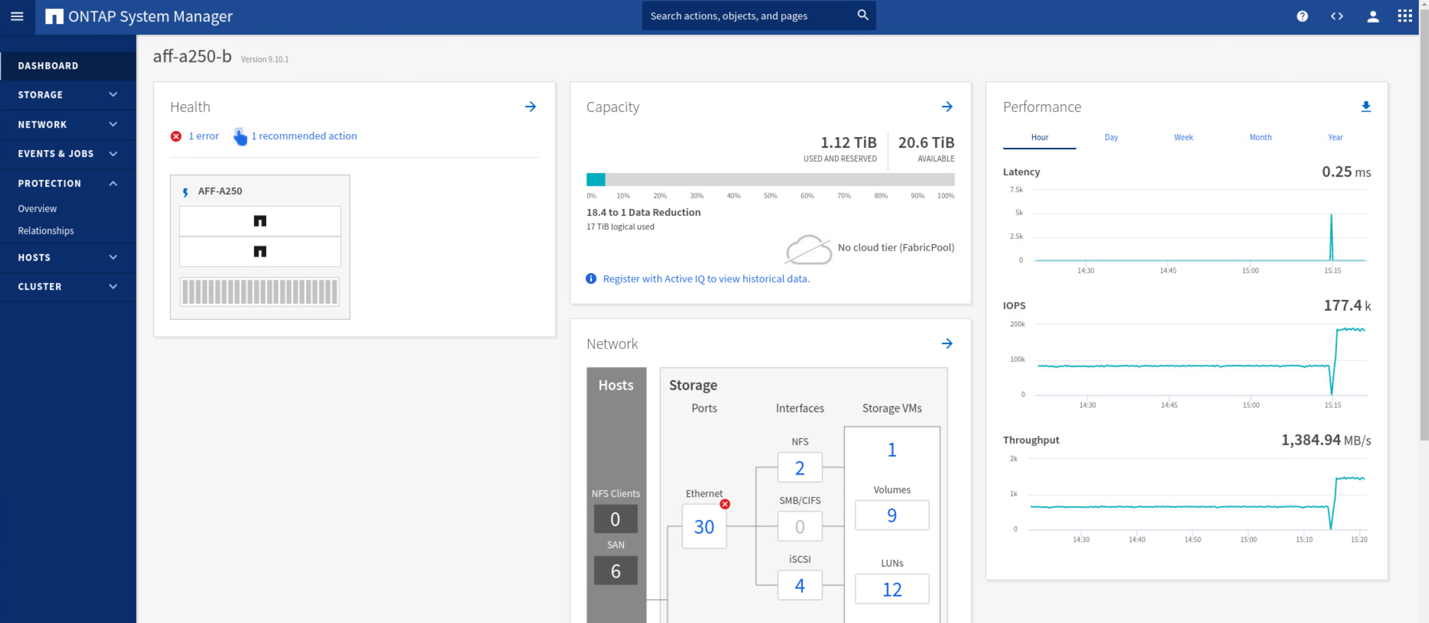
Pouco depois de iniciar o failover dos dois grupos de consistência cg_esxi_a e cg_infra_datastore_a, no local B System Manager GUI, o Site A I/o que atende esses dois grupos de consistência passou para o local B. como resultado, a I/o no local A reduziu significativamente, conforme mostrado no site A Painel De desempenho do System Manager.
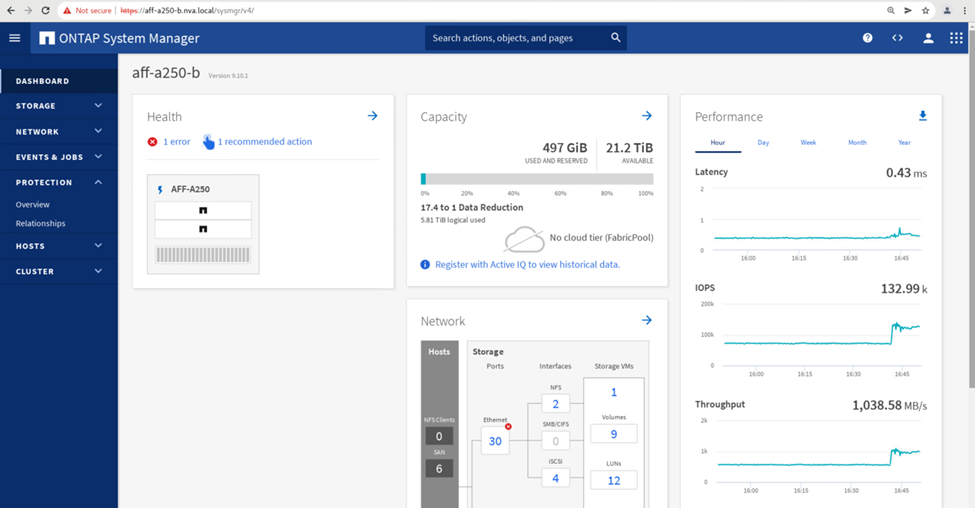
Por outro lado, o painel desempenho do painel do site B System Manager mostra um aumento significativo de IOPs, devido ao fornecimento de e/S adicionais transferidas do local A para cerca DE 130k IOPs e a uma taxa de transferência de aproximadamente 1GB GB/s, mantendo uma latência de e/S inferior a 1 milissegundos.
Com a e/S migrada de forma transparente do local A para o local B, os controladores de armazenamento do local A podem agora ser suspensos para manutenção programada. Depois que o trabalho de manutenção ou teste for concluído e o local Um cluster de armazenamento for colocado de volta e operacional, verifique e aguarde que o estado de proteção do grupo de consistência mude para In sync antes de executar um failover para retornar a e/S do local B ao local A. tenha em atenção que quanto mais tempo um local for retirado para manutenção ou teste, mais tempo demora antes de os dados serem sincronizados e o grupo de consistência for devolvido ao In sync estado.
Failover de storage não planejado
Um failover de storage não planejado pode ocorrer quando um desastre real acontece ou durante uma simulação de desastre. Por exemplo, veja a figura a seguir em que o sistema de storage no local A experimenta uma falha de energia, um failover de storage não planejado é acionado e os serviços de dados para LUNs do local A, protegidos pelas relações SM-BC, continuam do local B.
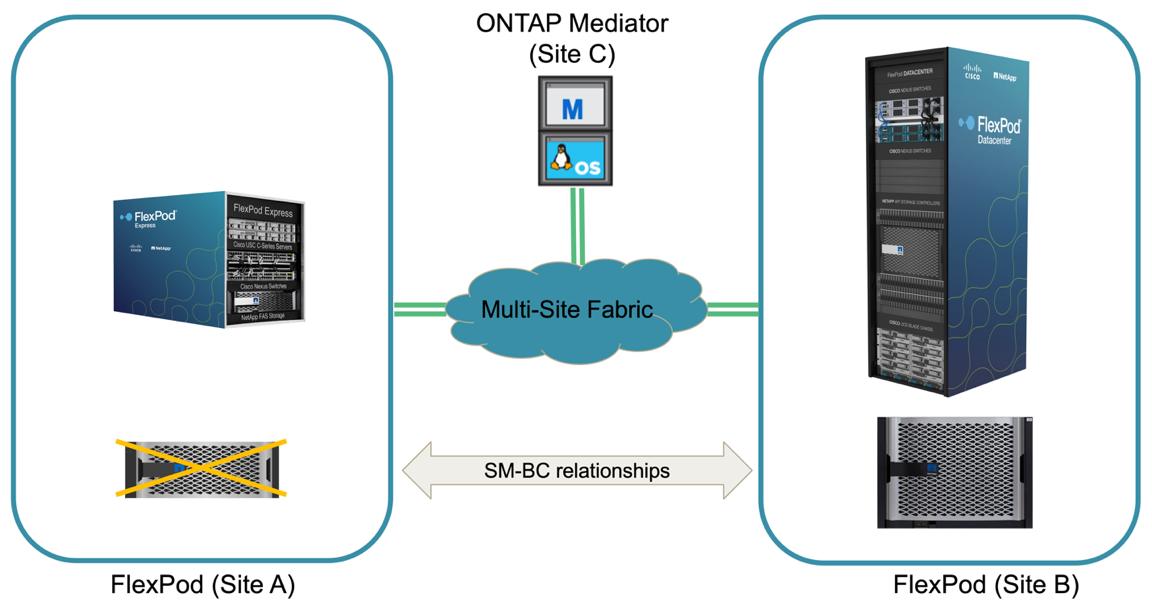
Para simular um desastre de armazenamento no local A, ambos os controladores de armazenamento no local A podem ser desligados desligando fisicamente o interrutor de alimentação para interromper o fornecimento de energia para os controladores, ou usando o comando de gerenciamento de energia do sistema dos processadores de serviços de armazenamento para desligar os controladores.
Quando o cluster de armazenamento no local perde energia, há uma parada repentina dos serviços de dados fornecidos pelo local Um cluster de armazenamento. Em seguida, o Mediador ONTAP, que monitora a solução SM-BC de um terceiro local, deteta Uma condição de falha de armazenamento do local e permite que a solução SM-BC execute um failover automatizado não planejado. Isso permite que os controladores de storage do local B continuem os serviços de dados para as LUNs configuradas nas relações de grupo de consistência SM-BC com o local A.
Do ponto de vista do aplicativo, os serviços de dados param brevemente enquanto o sistema operacional verifica o status do caminho para os LUNs e, em seguida, recomeça a e/S nos caminhos disponíveis para os controladores de storage do local B sobreviventes.
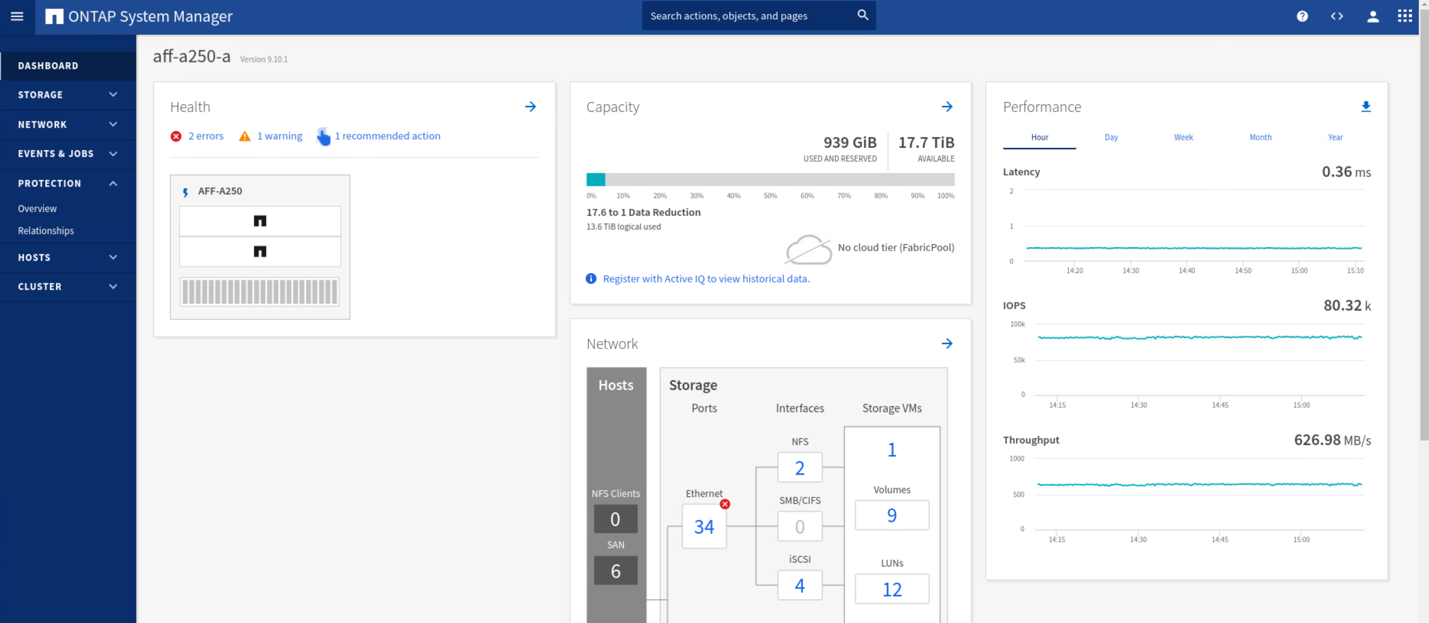
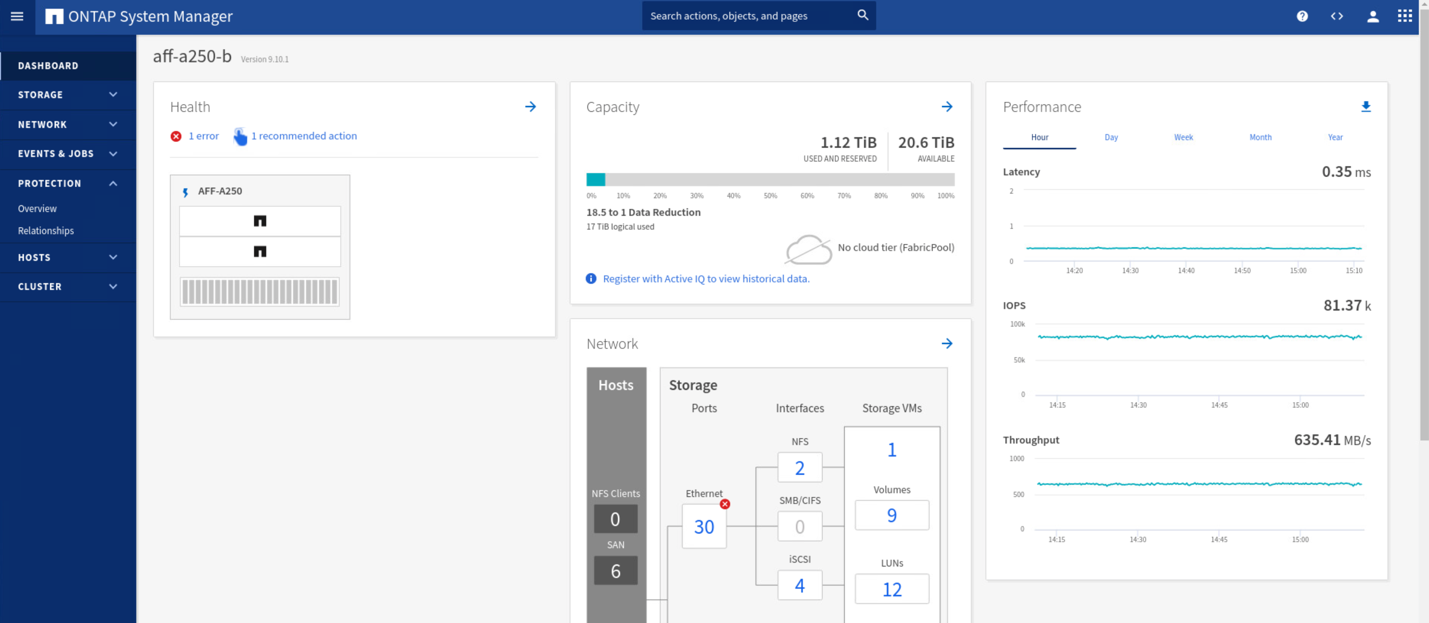
Durante os testes de validação, a ferramenta Iometer nas VMs em ambos os locais gera e/S para seus datastores locais. Após o local Um cluster foi desligado, e/S parou brevemente e, em seguida, retomou posteriormente. Veja as duas figuras a seguir para os painéis do cluster de armazenamento no local A e no local B, respetivamente, antes do desastre, que mostram aproximadamente 80k IOPS e 600 MB/s de taxa de transferência em cada local.
Depois de desligar os controladores de armazenamento no local A, podemos validar visualmente que a e/S do controlador de armazenamento local B aumentou drasticamente para fornecer serviços de dados adicionais em nome do local A (veja a figura a seguir). Além disso, a GUI das VMs do Iometer também mostrou que a e/S continuou apesar da interrupção do cluster de storage no local. Observe que, se houver datastores adicionais com suporte de LUNs não protegidos por relacionamentos SM-BC, esses datastores não estarão mais acessíveis quando o desastre do storage ocorrer. Portanto, é importante avaliar as necessidades de negócios dos vários dados de aplicativos e colocá-los adequadamente em datastores protegidos por relacionamentos SM-BC para fornecer continuidade de negócios.
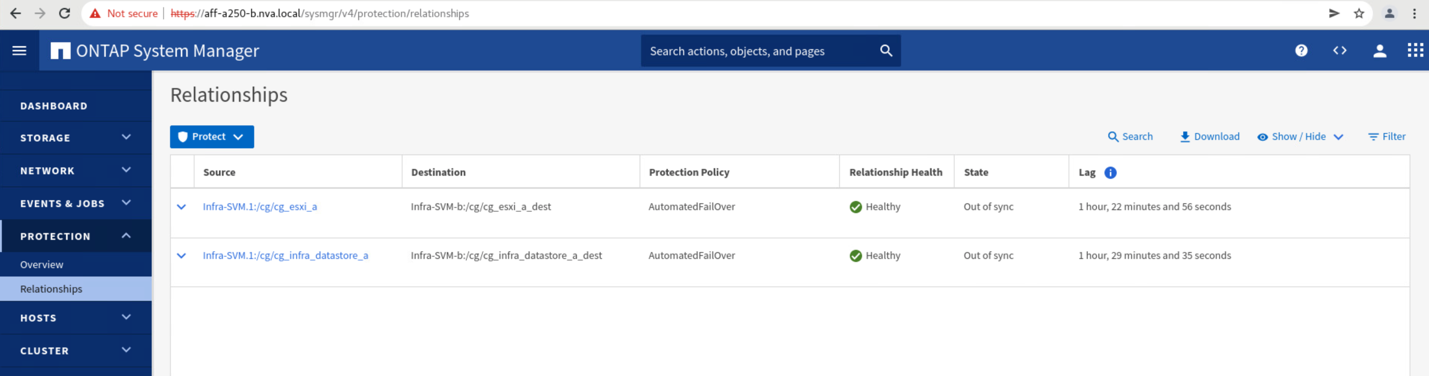
Enquanto o Site Um cluster está inativo, as relações dos grupos consistentes mostram Out of sync o status como mostrado na figura a seguir. Depois que a energia é ligada novamente para os controladores de armazenamento no local A, o cluster de armazenamento é inicializado e a sincronização de dados entre o local A e o local B acontece automaticamente.
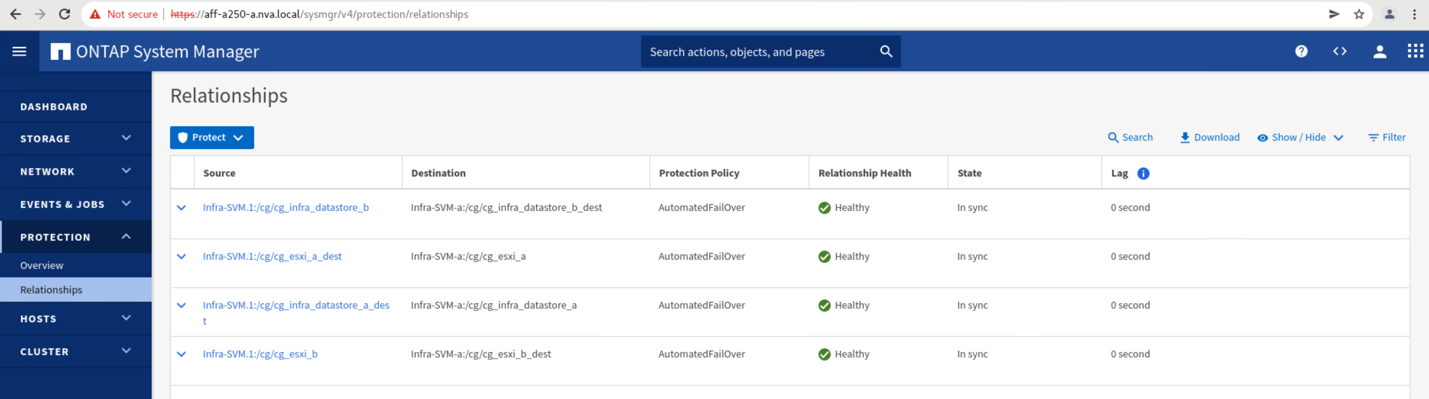
Antes de retornar os serviços de dados do site B de volta ao site A, você deve verificar o site A System Manager e garantir que as relações SM-BC sejam alcançadas e o status estejam de volta em sincronia. Depois de confirmar que os grupos de consistência estão sincronizados, uma operação de failover manual pode ser iniciada para retornar serviços de dados nos relacionamentos do grupo de consistência de volta ao local A.
Manutenção completa do local ou falha do local
Um local pode precisar de manutenção do local, experimentar perda de energia ou pode ser afetado por um desastre natural, como um furacão ou um Terremoto. Portanto, é crucial que você exerça cenários planejados e não planejados de falha do local para ajudar a garantir que sua solução FlexPod SM-BC esteja configurada adequadamente para sobreviver a essas falhas em todos os seus aplicativos e serviços de dados essenciais aos negócios. Os seguintes cenários relacionados ao local foram validados.
-
Cenário de manutenção do local planejado migrando máquinas virtuais e serviços de dados críticos para o outro site
-
Cenário de falha não planejada no local desligando servidores e controladores de storage para simulação de desastres
Para preparar um local para a manutenção planejada do local, é necessária uma combinação de migração de máquinas virtuais afetadas fora do local com o vMotion e um failover manual das relações do grupo de consistência SM-BC para migrar máquinas virtuais e serviços de dados críticos para o site alternativo. Os testes foram realizados em duas ordens diferentes: O VMotion primeiro seguido pelo failover SM-BC e o failover SM-BC primeiro seguido pelo vMotion, para confirmar que as máquinas virtuais continuam sendo executadas e os serviços de dados não são interrompidos.
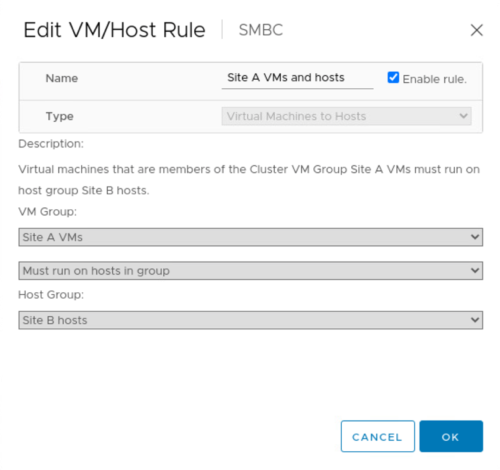
Antes de executar a migração planejada, atualize a regra de afinidade VM/host para que as VMs que estão sendo executadas no site sejam migradas automaticamente para fora do site que está sendo submetido a manutenção. A captura de tela a seguir mostra um exemplo de modificação do site De Uma regra de afinidade de VM/host para que as VMs migrem do local A para o local B automaticamente. Em vez de especificar que as VMs agora precisam ser executadas no local B, você também pode optar por desativar a regra de afinidade temporariamente para que as VMs possam ser migradas manualmente.
Depois que as máquinas virtuais e os serviços de armazenamento tiverem sido migrados, você poderá desligar servidores, controladores de armazenamento, compartimentos de discos e switches e executar as atividades de manutenção necessárias do local. Quando a manutenção do site for concluída e a instância do FlexPod for reativada, você poderá alterar a afinidade do grupo de hosts para que as VMs voltem ao site original. Depois disso, você deve alterar a regra de afinidade do site VM/Host "deve ser executada em hosts no grupo" para "deve ser executada em hosts no grupo" para que as máquinas virtuais possam ser executadas em hosts no outro local caso ocorra um desastre. Para os testes de validação, todas as máquinas virtuais foram migradas com sucesso para o outro site e os serviços de dados continuaram sem problemas após a execução de um failover para as relações SM-BC.
Para a simulação não planejada de desastre no local, os servidores e os controladores de storage foram desligados para simular um desastre no local. O recurso VMware HA deteta as máquinas virtuais descarregadas e reinicia essas máquinas virtuais no site sobrevivente. Além disso, o Mediador ONTAP em execução em um terceiro local deteta a falha do local e o local sobrevivente inicia um failover e começa a fornecer serviços de dados para o local inativo conforme esperado.
A captura de tela a seguir mostra que a CLI do processador de serviços dos controladores Storge foi usada para desligar o site De Um cluster abruptamente para simular um desastre de armazenamento no local.
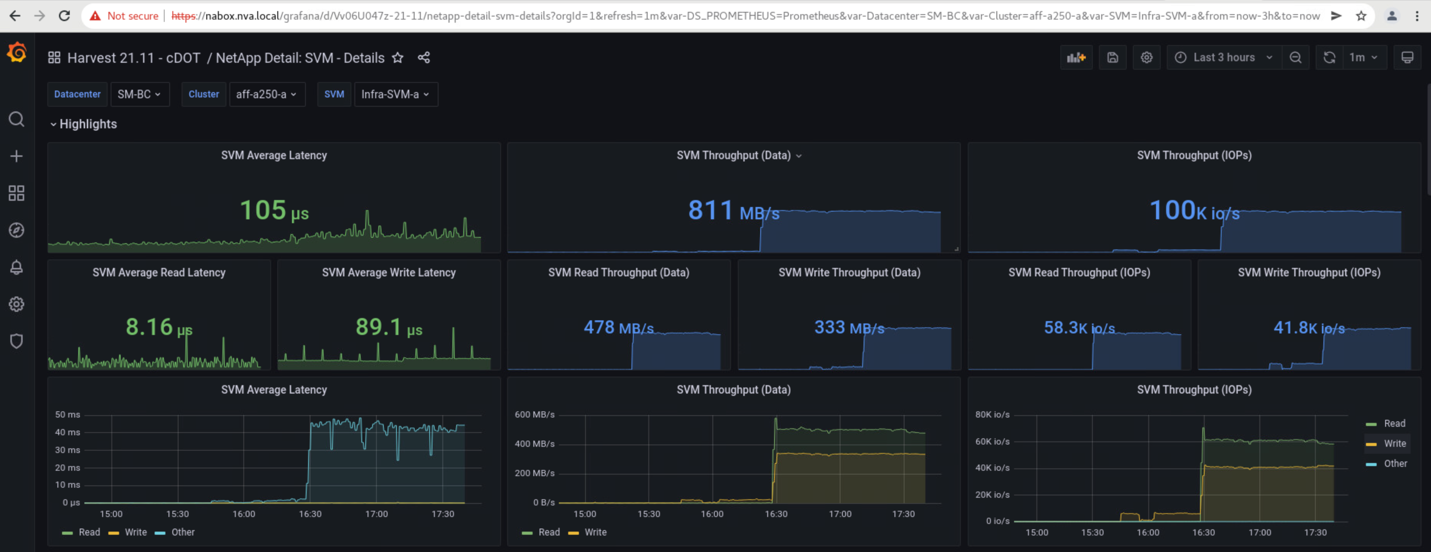
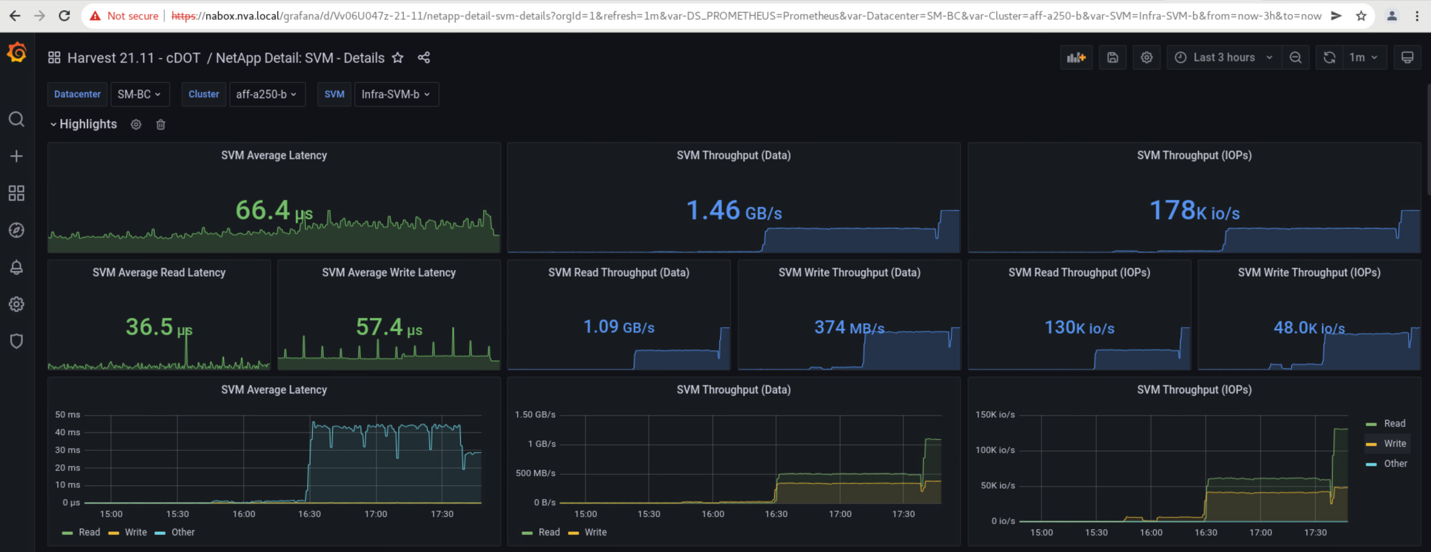
Os dashboards de máquina virtual de armazenamento dos clusters de armazenamento, conforme capturados pela ferramenta de coleta de dados NetApp Harvest e exibidos no painel Grafana na ferramenta de monitoramento NAbox, são mostrados nas duas capturas de tela a seguir. Como pode ser visto no lado direito dos gráficos IOPS e throughputs, o cluster do local B pega o Cluster De Uma carga de trabalho de armazenamento imediatamente depois que o local Em Que Um cluster cai.
Microsoft SQL Server
O Microsoft SQL Server é uma plataforma de banco de dados amplamente adotada e implantada para TI corporativa. A versão do Microsoft SQL Server 2019 traz muitos novos recursos e melhorias para seus mecanismos relacionais e analíticos. Ele dá suporte a workloads com aplicações executadas no local, na nuvem e híbridas podem usar uma combinação das duas. Além disso, ele pode ser implantado em várias plataformas, incluindo Windows, Linux e containers.
Como parte da validação de carga de trabalho crítica para os negócios da solução FlexPod SM-BC, o Microsoft SQL Server 2019 instalado em uma VM do Windows Server 2022 está incluído junto com as VMs Iometer para testes de failover de armazenamento planejados e não planejados do SM-BC. Na VM do Windows Server 2022, o SQL Server Management Studio é instalado para gerenciar o servidor SQL. Para testes, a ferramenta de banco de dados HammerDB é usada para gerar transações de banco de dados.
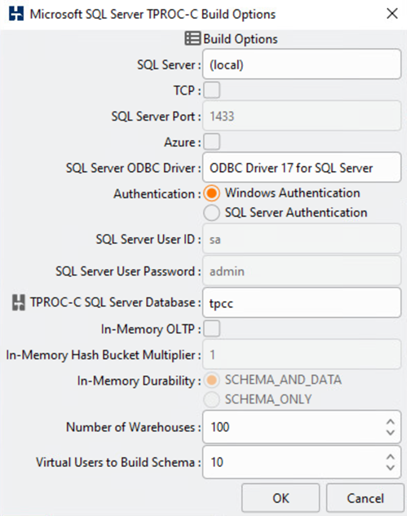
A ferramenta de teste de banco de dados HammerDB foi configurada para teste com a carga de trabalho Microsoft SQL Server TPROC-C. Para as configurações de compilação do esquema, as opções foram atualizadas para usar 100 armazéns com 10 usuários virtuais, como mostrado na captura de tela a seguir.
Depois que as opções de compilação do esquema foram atualizadas, o processo de compilação do esquema foi iniciado. Alguns minutos depois, uma falha não planejada simulada do cluster de armazenamento local B foi introduzida desligando ambos os nós do cluster de armazenamento AFF A250 de dois nós ao mesmo tempo usando comandos CLI do processador do sistema.
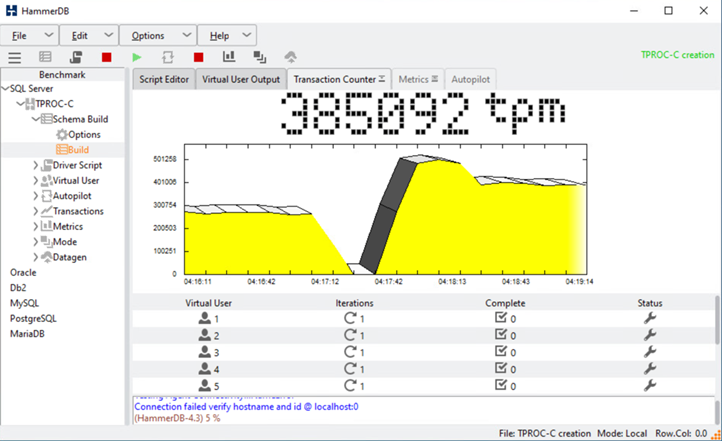
Após uma breve pausa das transações de banco de dados, o failover automatizado para a correção de desastres foi iniciado e as transações foram retomadas. A captura de tela a seguir mostra a captura de tela do HammerDB Transaction Counter naquela época. Como o banco de dados do Microsoft SQL Server normalmente reside no cluster de armazenamento do site B, a transação parou brevemente quando o armazenamento no local B foi desativado e, em seguida, retomado após o failover automatizado aconteceu.
As métricas de cluster de armazenamento foram capturadas usando a ferramenta NAbox com a ferramenta de monitoramento de colheita NetApp instalada. Os resultados são exibidos nos painéis Grafana predefinidos para a máquina virtual de armazenamento e outros objetos de armazenamento. O dashboard fornece metrics para latência, taxa de transferência, IOPS e detalhes adicionais com estatísticas de leitura e gravação separadas para o local B e o local A.
Esta captura de tela mostra o painel de desempenho do NAbox Grafana para o cluster de armazenamento local B.
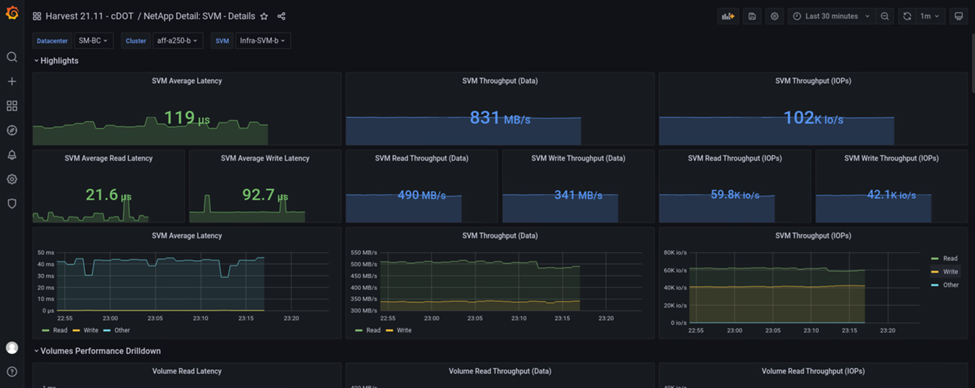
O IOPS do cluster de storage do local B era de cerca de 100K mil IOPS antes da introdução do desastre. Em seguida, as métricas de desempenho mostraram uma queda acentuada para zero no lado direito dos gráficos devido ao desastre. Como o cluster de armazenamento do local B estava inativo, nada poderia ser coletado do cluster do local B após a introdução do desastre.
Por outro lado, o IOPS do local Um cluster de storage pegou os workloads adicionais do local B após o failover automatizado. A carga de trabalho adicional pode ser facilmente vista no lado direito dos gráficos de IOPS e throughput na captura de tela a seguir, que mostra o painel de desempenho do NAbox Grafana para o local De Um cluster de armazenamento.
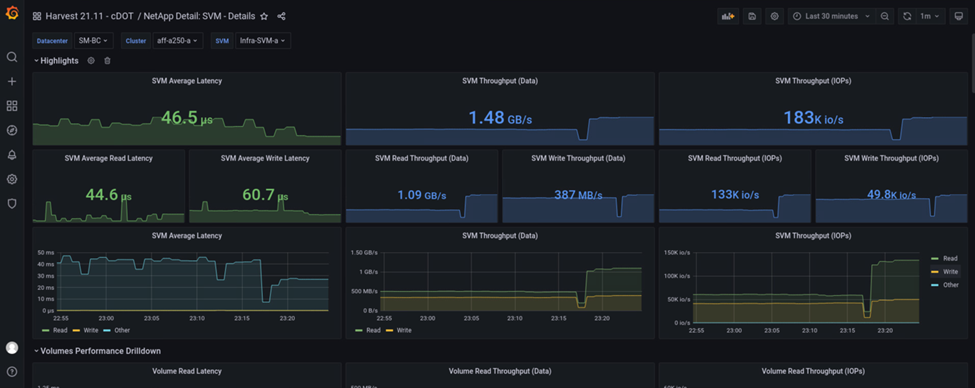
O cenário de teste de desastre de storage acima confirmou que o workload do Microsoft SQL Server pode sobreviver a uma interrupção completa do cluster de storage no local B, onde o banco de dados reside. A aplicação usou de forma transparente os serviços de dados fornecidos pelo local Um cluster de storage após a deteção do desastre e o failover.
Na camada de computação, quando as VMs em execução em um determinado local sofrem uma falha de host, as VMs são projetadas para serem reiniciadas automaticamente pelo recurso VMware HA. Para uma interrupção completa da computação no local, as regras de afinidade de VM/host permitem que as VMs sejam reiniciadas no local sobrevivente. No entanto, para que uma aplicação essencial aos negócios forneça serviços ininterruptos, é necessário um clustering baseado em aplicações, como o cluster de failover Microsoft ou a arquitetura de aplicações baseada em contêiner do Kubernetes, para evitar o tempo de inatividade da aplicação. Consulte o documento relevante para a implementação do clustering baseado em aplicações, que está além do âmbito deste relatório técnico.