

Solução de movimentação de dados
 Sugerir alterações
Sugerir alterações
Em um cluster de big data, os dados são armazenados em HDFS ou HCFS, como MapR-FS, Windows Azure Storage Blob, S3 ou o sistema de arquivos do Google. Realizamos testes com HDFS, MapR-FS e S3 como fonte para copiar dados para exportação NetApp ONTAP NFS com a ajuda do NIPAM usando o hadoop distcp comando da fonte.
O diagrama a seguir ilustra a movimentação típica de dados de um cluster Spark em execução com armazenamento HDFS para um volume NetApp ONTAP NFS para que a NVIDIA possa processar operações de IA.
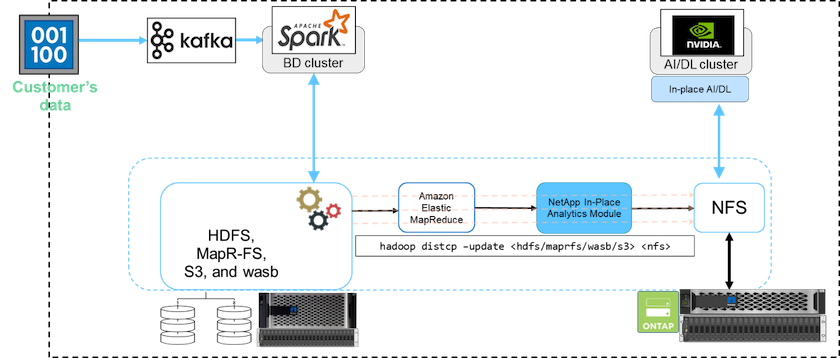
O hadoop distcp O comando usa o programa MapReduce para copiar os dados. O NIPAM trabalha com o MapReduce para atuar como um driver para o cluster Hadoop ao copiar dados. O NIPAM pode distribuir uma carga entre várias interfaces de rede para uma única exportação. Esse processo maximiza a taxa de transferência da rede distribuindo os dados entre várias interfaces de rede quando você copia os dados do HDFS ou HCFS para o NFS.

|
O NIPAM não é compatível nem certificado com o MapR. |