TR-4912: Diretrizes de práticas recomendadas para armazenamento em camadas do Confluent Kafka com NetApp
 Sugerir alterações
Sugerir alterações
Karthikeyan Nagalingam, Joseph Kandatilparambil, NetApp Rankesh Kumar, Confluente
O Apache Kafka é uma plataforma de streaming de eventos distribuída pela comunidade, capaz de lidar com trilhões de eventos por dia. Inicialmente concebido como uma fila de mensagens, o Kafka é baseado em uma abstração de um log de confirmação distribuído. Desde que foi criado e disponibilizado de código aberto pelo LinkedIn em 2011, o Kafka evoluiu de uma fila de mensagens para uma plataforma completa de transmissão de eventos. A Confluent fornece a distribuição do Apache Kafka com a Confluent Platform. A plataforma Confluent complementa o Kafka com recursos comunitários e comerciais adicionais projetados para melhorar a experiência de streaming de operadores e desenvolvedores em produção em grande escala.
Este documento descreve as diretrizes de práticas recomendadas para usar o Confluent Tiered Storage em uma oferta de armazenamento de objetos da NetApp, fornecendo o seguinte conteúdo:
-
Verificação confluente com armazenamento de objetos NetApp – NetApp StorageGRID
-
Testes de desempenho de armazenamento em camadas
-
Diretrizes de práticas recomendadas para Confluent em sistemas de armazenamento NetApp
Por que usar o armazenamento em camadas da Confluent?
O Confluent se tornou a plataforma de streaming em tempo real padrão para muitas aplicações, especialmente para big data, análise e cargas de trabalho de streaming. O armazenamento em camadas permite que os usuários separem a computação do armazenamento na plataforma Confluent. Ele torna o armazenamento de dados mais econômico, permite que você armazene quantidades virtualmente infinitas de dados e aumente (ou diminua) as cargas de trabalho sob demanda, além de facilitar tarefas administrativas como rebalanceamento de dados e locatários. Os sistemas de armazenamento compatíveis com S3 podem aproveitar todos esses recursos para democratizar dados com todos os eventos em um só lugar, eliminando a necessidade de engenharia de dados complexa. Para obter mais informações sobre por que você deve usar armazenamento em camadas para Kafka, verifique"este artigo da Confluent" .
O NetApp instaclustr também oferece suporte ao Kafka com armazenamento em camadas a partir da versão 3.8.1. Confira mais detalhes aqui. "Instaclust usando armazenamento em camadas Kafka"
Por que usar o NetApp StorageGRID para armazenamento em camadas?
StorageGRID é uma plataforma de armazenamento de objetos líder do setor da NetApp. O StorageGRID é uma solução de armazenamento baseada em objetos e definida por software que oferece suporte a APIs de objetos padrão do setor, incluindo a API do Amazon Simple Storage Service (S3). O StorageGRID armazena e gerencia dados não estruturados em escala para fornecer armazenamento de objetos seguro e durável. O conteúdo é colocado no local certo, na hora certa e no nível de armazenamento certo, otimizando fluxos de trabalho e reduzindo custos para mídia avançada distribuída globalmente.
O maior diferencial do StorageGRID é seu mecanismo de política de gerenciamento do ciclo de vida das informações (ILM), que permite o gerenciamento do ciclo de vida dos dados orientado por políticas. O mecanismo de política pode usar metadados para gerenciar como os dados são armazenados ao longo de sua vida útil para otimizar inicialmente o desempenho e otimizar automaticamente o custo e a durabilidade à medida que os dados envelhecem.
Habilitando o armazenamento em camadas do Confluent
A ideia básica do armazenamento em camadas é separar as tarefas de armazenamento de dados do processamento de dados. Com essa separação, fica muito mais fácil para a camada de armazenamento de dados e a camada de processamento de dados escalarem de forma independente.
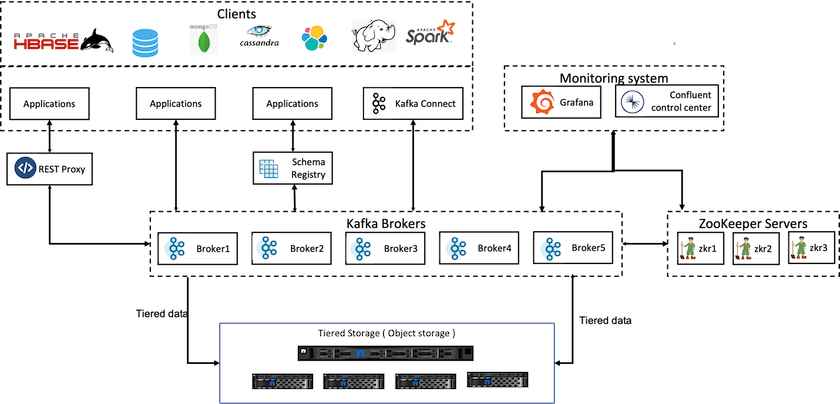
Uma solução de armazenamento em camadas para o Confluent deve atender a dois fatores. Primeiro, ele deve contornar ou evitar propriedades comuns de consistência e disponibilidade de armazenamento de objetos, como inconsistências em operações LIST e indisponibilidade ocasional de objetos. Em segundo lugar, ele deve lidar corretamente com a interação entre o armazenamento em camadas e o modelo de replicação e tolerância a falhas do Kafka, incluindo a possibilidade de líderes zumbis continuarem a estratificar intervalos de deslocamento. O armazenamento de objetos da NetApp fornece disponibilidade consistente de objetos e o modelo de alta disponibilidade torna o armazenamento desgastado disponível para intervalos de deslocamento de camadas. O armazenamento de objetos da NetApp fornece disponibilidade consistente de objetos e um modelo de alta disponibilidade para disponibilizar o armazenamento desgastado para intervalos de deslocamento de camadas.
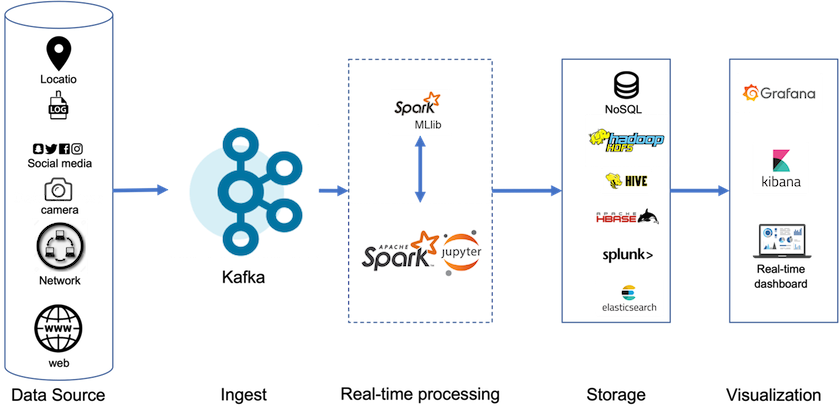
Com o armazenamento em camadas, você pode usar plataformas de alto desempenho para leituras e gravações de baixa latência perto do final dos seus dados de streaming e também pode usar armazenamentos de objetos mais baratos e escaláveis, como o NetApp StorageGRID , para leituras históricas de alto rendimento. Também temos uma solução técnica para Spark com controlador de armazenamento netapp e os detalhes estão aqui. A figura a seguir mostra como o Kafka se encaixa em um pipeline de análise em tempo real.
A figura a seguir mostra como o NetApp StorageGRID se encaixa na camada de armazenamento de objetos do Confluent Kafka.