

Arquitetura Splunk
 Sugerir alterações
Sugerir alterações
Esta seção descreve a arquitetura do Splunk, incluindo definições principais, implantações distribuídas do Splunk, Splunk SmartStore, fluxo de dados, requisitos de hardware e software, requisitos de sites únicos e múltiplos e assim por diante.
Definições principais
As próximas duas tabelas listam os componentes Splunk e NetApp usados na implantação distribuída do Splunk.
Esta tabela lista os componentes de hardware do Splunk para a configuração distribuída do Splunk Enterprise.
| Componente Splunk | Tarefa |
|---|---|
Indexador |
Repositório para dados do Splunk Enterprise |
Despachante universal |
Responsável por ingerir dados e encaminhá-los aos indexadores |
Cabeçalho de pesquisa |
O front-end do usuário usado para pesquisar dados em indexadores |
Mestre do cluster |
Gerencia a instalação de indexadores e cabeçalhos de pesquisa do Splunk |
Console de monitoramento |
Ferramenta de monitoramento centralizada usada em toda a implantação |
Mestre de licença |
O mestre de licenças lida com o licenciamento do Splunk Enterprise |
Servidor de implantação |
Atualiza configurações e distribui aplicativos para o componente de processamento |
Componente de armazenamento |
Tarefa |
NetApp AFF |
Armazenamento all-flash usado para gerenciar dados de nível ativo. Também conhecido como armazenamento local. |
NetApp StorageGRID |
Armazenamento de objetos S3 usado para gerenciar dados da camada quente. Usado pelo SmartStore para mover dados entre as camadas quente e morna. Também conhecido como armazenamento remoto. |
Esta tabela lista os componentes na arquitetura de armazenamento do Splunk.
| Componente Splunk | Tarefa | Componente responsável |
|---|---|---|
Loja Inteligente |
Fornece aos indexadores a capacidade de hierarquizar dados do armazenamento local para o armazenamento de objetos. |
Splunk |
Quente |
O ponto de aterrissagem onde os encaminhadores universais colocam os dados recém-gravados. O armazenamento é gravável e os dados são pesquisáveis. Essa camada de dados normalmente é composta de SSDs ou HDDs rápidos. |
ONTAP |
Gerenciador de Cache |
Gerencia o cache local de dados indexados, busca dados importantes do armazenamento remoto quando ocorre uma pesquisa e remove os dados usados com menos frequência do cache. |
Loja Inteligente |
Esquentar |
Os dados são transferidos logicamente para o bucket e renomeados primeiro para a camada quente a partir da camada quente. Os dados dentro desta camada são protegidos e, assim como na camada ativa, podem ser compostos de SSDs ou HDDs de maior capacidade. Backups incrementais e completos são suportados usando soluções comuns de proteção de dados. |
StorageGRID |
Implantações distribuídas do Splunk
Para dar suporte a ambientes maiores nos quais os dados se originam em muitas máquinas, você precisa processar grandes volumes de dados. Se muitos usuários precisarem pesquisar os dados, você poderá dimensionar a implantação distribuindo instâncias do Splunk Enterprise em várias máquinas. Isso é conhecido como implantação distribuída.
Em uma implantação distribuída típica, cada instância do Splunk Enterprise executa uma tarefa especializada e reside em uma das três camadas de processamento correspondentes às principais funções de processamento.
A tabela a seguir lista os níveis de processamento do Splunk Enterprise.
| Nível | Componente | Descrição |
|---|---|---|
Entrada de dados |
Despachante |
Um encaminhador consome dados e depois os encaminha para um grupo de indexadores. |
Indexação |
Indexador |
Um indexador indexa dados de entrada que normalmente recebe de um grupo de encaminhadores. O indexador transforma os dados em eventos e armazena os eventos em um índice. O indexador também pesquisa os dados indexados em resposta às solicitações de pesquisa de um cabeçalho de pesquisa. |
Gerenciamento de pesquisa |
Cabeçalho de pesquisa |
Um cabeçalho de pesquisa serve como um recurso central para pesquisa. Os cabeçalhos de pesquisa em um cluster são intercambiáveis e têm acesso às mesmas pesquisas, painéis, objetos de conhecimento e assim por diante, de qualquer membro do cluster de cabeçalhos de pesquisa. |
A tabela a seguir lista os componentes importantes usados em um ambiente distribuído do Splunk Enterprise.
| Componente | Descrição | Responsabilidade |
|---|---|---|
Mestre do cluster de índice |
Coordena atividades e atualizações de um cluster de indexadores |
Gestão de índices |
Cluster de índice |
Grupo de indexadores Splunk Enterprise configurados para replicar dados entre si |
Indexação |
Implantador de cabeça de pesquisa |
Lida com a implantação e atualizações no mestre do cluster |
Gerenciamento de cabeçalho de pesquisa |
Cluster de cabeçalho de pesquisa |
Grupo de cabeças de pesquisa que serve como um recurso central para pesquisa |
Gerenciamento de pesquisa |
Balanceadores de carga |
Usado por componentes agrupados para lidar com a demanda crescente de cabeçalhos de pesquisa, indexadores e destino S3 para distribuir a carga entre os componentes agrupados. |
Gerenciamento de carga para componentes em cluster |
Veja os seguintes benefícios das implantações distribuídas do Splunk Enterprise:
-
Acesse fontes de dados diversas ou dispersas
-
Fornece funcionalidade para lidar com as necessidades de dados de empresas de qualquer tamanho e complexidade
-
Obtenha alta disponibilidade e garanta a recuperação de desastres com replicação de dados e implantação em vários locais
Loja Inteligente Splunk
O SmartStore é um recurso de indexador que permite que armazenamentos de objetos remotos, como o Amazon S3, armazenem dados indexados. À medida que o volume de dados de uma implantação aumenta, a demanda por armazenamento geralmente supera a demanda por recursos de computação. O SmartStore permite que você gerencie o armazenamento do indexador e os recursos de computação de forma econômica, dimensionando esses recursos separadamente.
O SmartStore introduz uma camada de armazenamento remoto e um gerenciador de cache. Esses recursos permitem que os dados residam localmente em indexadores ou na camada de armazenamento remoto. O gerenciador de cache gerencia a movimentação de dados entre o indexador e a camada de armazenamento remoto, que é configurada no indexador.
Com o SmartStore, você pode reduzir o espaço de armazenamento do indexador ao mínimo e escolher recursos de computação otimizados para E/S. A maioria dos dados reside no armazenamento remoto. O indexador mantém um cache local que contém uma quantidade mínima de dados: buckets ativos, cópias de buckets ativos que participam de pesquisas ativas ou recentes e metadados de buckets.
Fluxo de dados do Splunk SmartStore
Quando dados provenientes de várias fontes chegam aos indexadores, eles são indexados e salvos localmente em um hot bucket. O indexador também replica os dados do hot bucket para indexadores de destino. Até agora, o fluxo de dados é idêntico ao fluxo de dados para índices não SmartStore.
Quando o balde quente rola para morno, o fluxo de dados diverge. O indexador de origem copia o bucket quente para o armazenamento de objetos remoto (camada de armazenamento remoto), deixando a cópia existente em seu cache, porque as pesquisas tendem a ser executadas em dados indexados recentemente. No entanto, os indexadores de destino excluem suas cópias porque o armazenamento remoto fornece alta disponibilidade sem manter várias cópias locais. A cópia mestre do bucket agora reside no armazenamento remoto.
A imagem a seguir mostra o fluxo de dados do Splunk SmartStore.
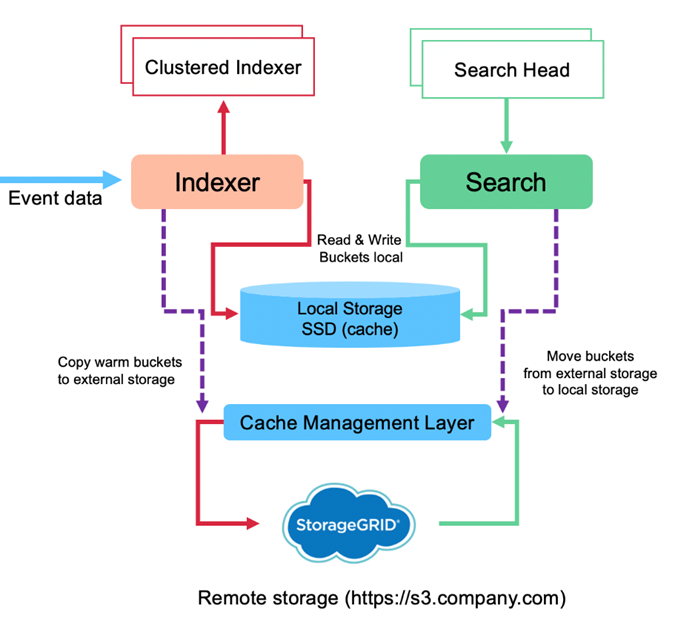
O gerenciador de cache no indexador é central para o fluxo de dados do SmartStore. Ele busca cópias de buckets do armazenamento remoto conforme necessário para lidar com solicitações de pesquisa. Ele também remove cópias mais antigas ou menos pesquisadas de buckets do cache, porque a probabilidade de elas participarem de pesquisas diminui com o tempo.
O trabalho do gerenciador de cache é otimizar o uso do cache disponível e, ao mesmo tempo, garantir que as pesquisas tenham acesso imediato aos buckets necessários.
Requisitos de software
A tabela abaixo lista os componentes de software necessários para implementar a solução. Os componentes de software usados em qualquer implementação da solução podem variar de acordo com os requisitos do cliente.
| Família de produtos | Nome do produto | Versão do produto | Sistema operacional |
|---|---|---|---|
NetApp StorageGRID |
Armazenamento de objetos StorageGRID |
11,6 |
n / D |
CentOS |
CentOS |
8,1 |
CentOS 7.x |
Splunk Enterprise |
Splunk Enterprise com SmartStore |
8.0.3 |
CentOS 7.x |
Requisitos de local único e múltiplo
Em um ambiente Enterprise Splunk (implantações médias e grandes) onde os dados se originam em muitas máquinas e onde muitos usuários precisam pesquisar os dados, você pode dimensionar sua implantação distribuindo instâncias do Splunk Enterprise em sites únicos e múltiplos.
Veja os seguintes benefícios das implantações distribuídas do Splunk Enterprise:
-
Acesse fontes de dados diversas ou dispersas
-
Fornece funcionalidade para lidar com as necessidades de dados de empresas de qualquer tamanho e complexidade
-
Obtenha alta disponibilidade e garanta a recuperação de desastres com replicação de dados e implantação em vários locais
A tabela a seguir lista os componentes usados em um ambiente distribuído do Splunk Enterprise.
| Componente | Descrição | Responsabilidade |
|---|---|---|
Mestre do cluster de índice |
Coordena atividades e atualizações de um cluster de indexadores |
Gestão de índices |
Cluster de índice |
Grupo de indexadores Splunk Enterprise configurados para replicar os dados uns dos outros |
Indexação |
Implantador de cabeça de pesquisa |
Lida com a implantação e atualizações no mestre do cluster |
Gerenciamento de cabeçalho de pesquisa |
Cluster de cabeçalho de pesquisa |
Grupo de cabeças de pesquisa que serve como um recurso central para pesquisa |
Gerenciamento de pesquisa |
Balanceadores de carga |
Usado por componentes agrupados para lidar com a demanda crescente de cabeçalhos de pesquisa, indexadores e destino S3 para distribuir a carga entre os componentes agrupados. |
Gerenciamento de carga para componentes em cluster |
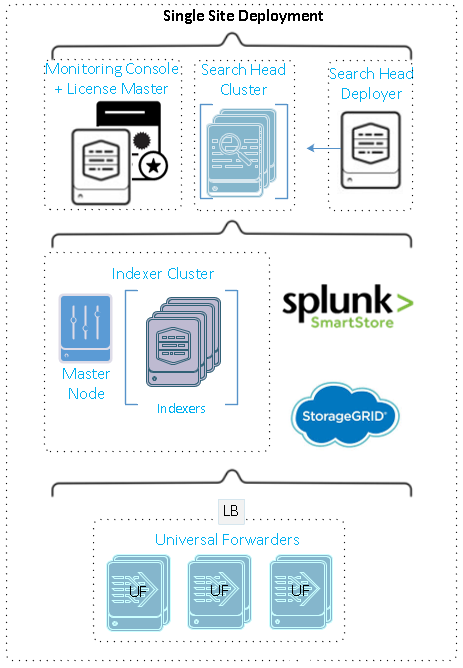
Esta figura descreve um exemplo de uma implantação distribuída em um único local.
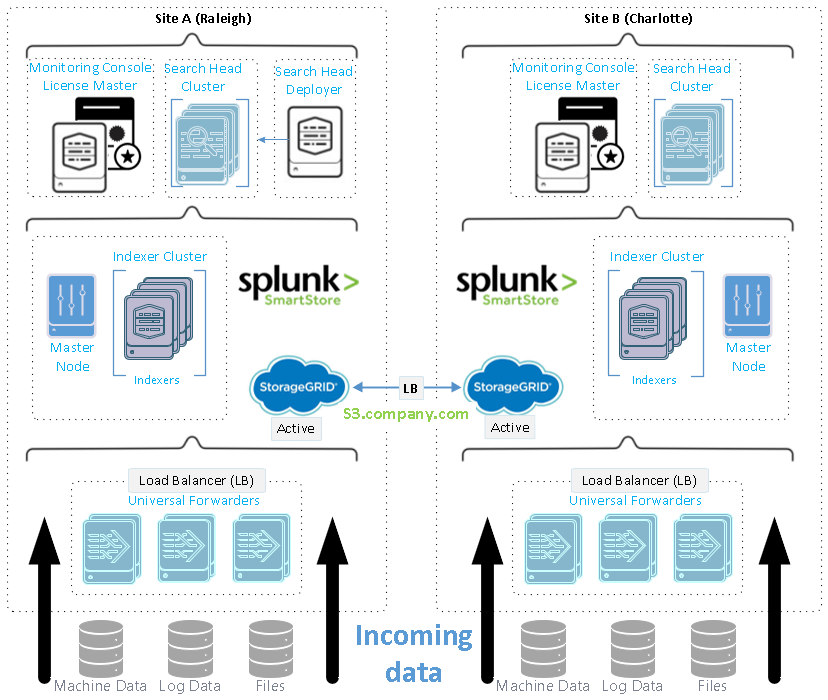
Esta figura descreve um exemplo de uma implantação distribuída em vários locais.
Requisitos de hardware
As tabelas a seguir listam o número mínimo de componentes de hardware necessários para implementar a solução. Os componentes de hardware usados em implementações específicas da solução podem variar de acordo com os requisitos do cliente.

|
Independentemente de você ter implantado o Splunk SmartStore e o StorageGRID em um único site ou em vários sites, todos os sistemas são gerenciados pelo StorageGRID GRID Manager em um único painel de controle. Veja a seção "Gerenciamento simples com o Grid Manager" para mais detalhes. |
Esta tabela lista o hardware usado para um único site.
| Hardware | Quantidade | Disco | Capacidade utilizável | Observação |
|---|---|---|---|---|
StorageGRID SG1000 |
1 |
n / D |
n / D |
Nó de administração e balanceador de carga |
StorageGRID SG6060 |
4 |
x48, 8 TB (HDD NL-SAS) |
1PB |
Armazenamento remoto |
Esta tabela lista o hardware usado para uma configuração multisite (por site).
| Hardware | Quantidade | Disco | Capacidade utilizável | Observação |
|---|---|---|---|---|
StorageGRID SG1000 |
2 |
n / D |
n / D |
Nó de administração e balanceador de carga |
StorageGRID SG6060 |
4 |
x48, 8 TB (HDD NL-SAS) |
1PB |
Armazenamento remoto |
Balanceador de carga NetApp StorageGRID : SG1000
O armazenamento de objetos requer o uso de um balanceador de carga para apresentar o namespace de armazenamento em nuvem. O StorageGRID oferece suporte a balanceadores de carga de terceiros de fornecedores líderes como F5 e Citrix, mas muitos clientes escolhem o balanceador StorageGRID de nível empresarial pela simplicidade, resiliência e alto desempenho. O balanceador de carga StorageGRID está disponível como uma VM, contêiner ou dispositivo desenvolvido especificamente.
O StorageGRID SG1000 facilita o uso de grupos de alta disponibilidade (HA) e balanceamento de carga inteligente para conexões de caminho de dados S3. Nenhum outro sistema de armazenamento de objetos no local fornece um balanceador de carga personalizado.
O aparelho SG1000 oferece os seguintes recursos:
-
Um balanceador de carga e, opcionalmente, funções de nó de administração para um sistema StorageGRID
-
O instalador do dispositivo StorageGRID para simplificar a implantação e a configuração do nó
-
Configuração simplificada de endpoints S3 e SSL
-
Largura de banda dedicada (em vez de compartilhar um balanceador de carga de terceiros com outros aplicativos)
-
Até 4 x 100 Gbps de largura de banda Ethernet agregada
A imagem a seguir mostra o dispositivo SG1000 Gateway Services.

SG6060
O dispositivo StorageGRID SG6060 inclui um controlador de computação (SG6060) e uma prateleira de controlador de armazenamento (E-Series E2860) que contém dois controladores de armazenamento e 60 unidades. Este aparelho oferece os seguintes recursos:
-
Aumente até 400 PB em um único namespace.
-
Até 4x 25 Gbps de largura de banda Ethernet agregada.
-
Inclui o StorageGRID Appliance Installer para simplificar a implantação e a configuração dos nós.
-
Cada dispositivo SG6060 pode ter uma ou duas prateleiras de expansão adicionais para um total de 180 unidades.
-
Dois controladores E-Series E2800 (configuração duplex) para fornecer suporte a failover de controlador de armazenamento.
-
Prateleira com cinco gavetas que comporta sessenta unidades de 3,5 polegadas (duas unidades de estado sólido e 58 unidades NL-SAS).
A imagem a seguir mostra o dispositivo SG6060.

Design Splunk
A tabela a seguir lista a configuração do Splunk para um único site.
| Componente Splunk | Tarefa | Quantidade | Núcleos | Memória | SO |
|---|---|---|---|---|---|
Despachante universal |
Responsável por ingerir dados e encaminhá-los aos indexadores |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gerencia os dados do usuário |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabeçalho de pesquisa |
O front-end do usuário pesquisa dados em indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Implantador de cabeça de pesquisa |
Lida com atualizações para clusters de cabeçalhos de pesquisa |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Mestre do cluster |
Gerencia a instalação e os indexadores do Splunk |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Console de monitoramento e mestre de licenças |
Executa monitoramento centralizado de toda a implantação do Splunk e gerencia licenças do Splunk |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
As tabelas a seguir descrevem a configuração do Splunk para configurações multisite.
Esta tabela lista a configuração do Splunk para uma configuração multisite (site A).
| Componente Splunk | Tarefa | Quantidade | Núcleos | Memória | SO |
|---|---|---|---|---|---|
Despachante universal |
Responsável por ingerir dados e encaminhá-los aos indexadores. |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gerencia os dados do usuário |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabeçalho de pesquisa |
O front-end do usuário pesquisa dados em indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Implantador de cabeça de pesquisa |
Lida com atualizações para clusters de cabeçalhos de pesquisa |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Mestre do cluster |
Gerencia a instalação e os indexadores do Splunk |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Console de monitoramento e mestre de licenças |
Executa o monitoramento centralizado de toda a implantação do Splunk e gerencia as licenças do Splunk. |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Esta tabela lista a configuração do Splunk para uma configuração multisite (site B).
| Componente Splunk | Tarefa | Quantidade | Núcleos | Memória | SO |
|---|---|---|---|---|---|
Despachante universal |
Responsável por ingerir dados e encaminhá-los aos indexadores |
4 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Indexador |
Gerencia os dados do usuário |
10 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Cabeçalho de pesquisa |
O front-end do usuário pesquisa dados em indexadores |
3 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Mestre do cluster |
Gerencia a instalação e os indexadores do Splunk |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |
Console de monitoramento e mestre de licenças |
Executa monitoramento centralizado de toda a implantação do Splunk e gerencia licenças do Splunk |
1 |
16 núcleos |
32 GB de RAM |
CentOS 8.1 |