

Exemplo de caso de uso - Tarefa de treinamento do TensorFlow
 Sugerir alterações
Sugerir alterações
Esta seção descreve as tarefas que precisam ser executadas para executar um trabalho de treinamento do TensorFlow em um ambiente NVIDIA AI Enterprise.
Pré-requisitos
Antes de executar as etapas descritas nesta seção, presumimos que você já criou um modelo de VM convidada seguindo as instruções descritas na"Configurar" página.
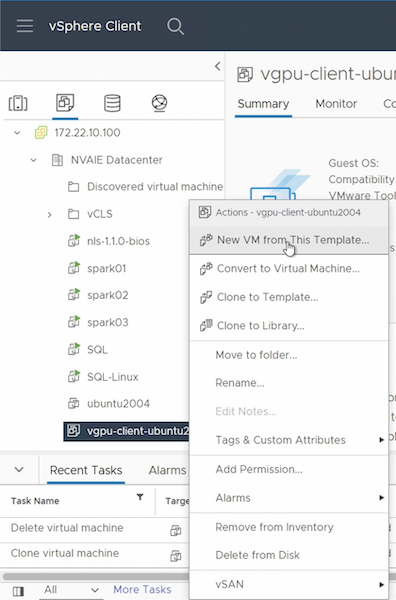
Criar VM convidada a partir do modelo
Primeiro, você deve criar uma nova VM convidada a partir do modelo criado na seção anterior. Para criar uma nova VM convidada a partir do seu modelo, faça login no VMware vSphere, clique com o botão direito do mouse no nome do modelo, escolha "Nova VM deste modelo…" e siga o assistente.
Criar e montar volume de dados
Em seguida, você deve criar um novo volume de dados para armazenar seu conjunto de dados de treinamento. Você pode criar rapidamente um novo volume de dados usando o NetApp DataOps Toolkit. O comando de exemplo a seguir mostra a criação de um volume chamado 'imagenet' com capacidade de 2 TB.
$ netapp_dataops_cli.py create vol -n imagenet -s 2TB
Antes de preencher seu volume de dados com dados, você deve montá-lo na VM convidada. Você pode montar rapidamente um volume de dados usando o NetApp DataOps Toolkit. O comando de exemplo a seguir mostra a montagem do volume que foi criado na etapa anterior.
$ sudo -E netapp_dataops_cli.py mount vol -n imagenet -m ~/imagenet
Preencher volume de dados
Depois que o novo volume for provisionado e montado, o conjunto de dados de treinamento poderá ser recuperado do local de origem e colocado no novo volume. Isso normalmente envolverá extrair dados de um data lake S3 ou Hadoop e, às vezes, envolverá a ajuda de um engenheiro de dados.
Executar tarefa de treinamento do TensorFlow
Agora, você está pronto para executar seu trabalho de treinamento do TensorFlow. Para executar seu trabalho de treinamento do TensorFlow, execute as seguintes tarefas.
-
Puxe a imagem do contêiner NVIDIA NGC Enterprise TensorFlow.
$ sudo docker pull nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Inicie uma instância do contêiner NVIDIA NGC Enterprise TensorFlow. Use a opção '-v' para anexar seu volume de dados ao contêiner.
$ sudo docker run --gpus all -v ~/imagenet:/imagenet -it --rm nvcr.io/nvaie/tensorflow-2-1:22.05-tf1-nvaie-2.1-py3
-
Execute seu programa de treinamento do TensorFlow dentro do contêiner. O comando de exemplo a seguir mostra a execução de um programa de treinamento ResNet-50 de exemplo que está incluído na imagem do contêiner.
$ python ./nvidia-examples/cnn/resnet.py --layers 50 -b 64 -i 200 -u batch --precision fp16 --data_dir /imagenet/data