

MLOps de código aberto com NetApp
 Sugerir alterações
Sugerir alterações
Mike Oglesby, NetApp Sufian Ahmad, NetApp Rick Huang, NetApp Mohan Acharya, NetApp
Empresas e organizações de todos os tamanhos e de diversos setores estão recorrendo à inteligência artificial (IA) para resolver problemas do mundo real, fornecer produtos e serviços inovadores e obter vantagem em um mercado cada vez mais competitivo. Muitas organizações estão recorrendo a ferramentas MLOps de código aberto para acompanhar o ritmo acelerado de inovação no setor. Essas ferramentas de código aberto oferecem recursos avançados e de ponta, mas geralmente não levam em conta a disponibilidade e a segurança dos dados. Infelizmente, isso significa que cientistas de dados altamente qualificados são forçados a gastar uma quantidade significativa de tempo esperando para obter acesso aos dados ou esperar que operações rudimentares relacionadas a dados sejam concluídas. Ao combinar ferramentas populares de MLOps de código aberto com uma infraestrutura de dados inteligente da NetApp, as organizações podem acelerar seus pipelines de dados, o que, por sua vez, acelera suas iniciativas de IA. Eles podem extrair valor de seus dados e, ao mesmo tempo, garantir que eles permaneçam protegidos e seguros. Esta solução demonstra o emparelhamento de recursos de gerenciamento de dados da NetApp com diversas ferramentas e estruturas populares de código aberto para enfrentar esses desafios.
A lista a seguir destaca alguns dos principais recursos habilitados por esta solução:
-
Os usuários podem provisionar rapidamente novos volumes de dados de alta capacidade e espaços de trabalho de desenvolvimento apoiados pelo armazenamento NetApp de alto desempenho e escalonável.
-
Os usuários podem clonar quase instantaneamente volumes de dados de alta capacidade e espaços de trabalho de desenvolvimento para permitir experimentação ou iteração rápida.
-
Os usuários podem salvar quase instantaneamente snapshots de volumes de dados de alta capacidade e espaços de trabalho de desenvolvimento para backup e/ou rastreabilidade/linha de base.
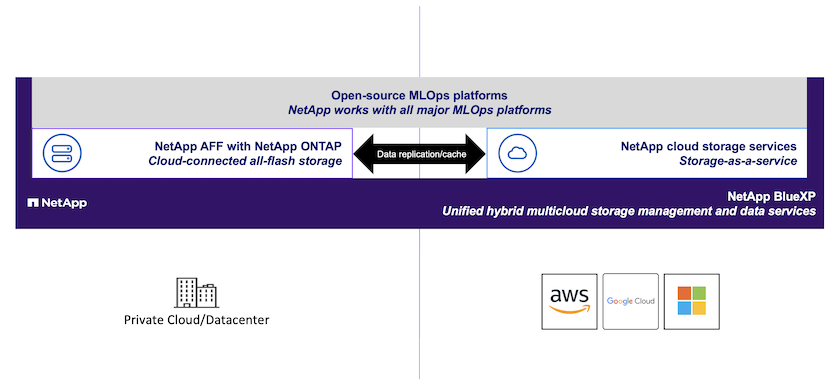
Um fluxo de trabalho MLOps típico incorpora espaços de trabalho de desenvolvimento, geralmente assumindo a forma de"Cadernos Jupyter" ; rastreamento de experimentos; pipelines de treinamento automatizados; pipelines de dados; e inferência/implantação. Esta solução destaca diversas ferramentas e estruturas diferentes que podem ser usadas de forma independente ou em conjunto para abordar os diferentes aspectos do fluxo de trabalho. Também demonstramos o emparelhamento de recursos de gerenciamento de dados da NetApp com cada uma dessas ferramentas. Esta solução tem como objetivo oferecer blocos de construção a partir dos quais uma organização pode construir um fluxo de trabalho MLOps personalizado, específico para seus casos de uso e requisitos.
As seguintes ferramentas/estruturas são abordadas nesta solução:
A lista a seguir descreve padrões comuns para implantar essas ferramentas de forma independente ou em conjunto.
-
Implantar JupyterHub, MLflow e Apache Airflow em conjunto - JupyterHub para"Cadernos Jupyter" , MLflow para rastreamento de experimentos e Apache Airflow para treinamento automatizado e pipelines de dados.
-
Implantar Kubeflow e Apache Airflow em conjunto - Kubeflow para"Cadernos Jupyter" , rastreamento de experimentos, pipelines de treinamento automatizados e inferência; e Apache Airflow para pipelines de dados.
-
Implemente o Kubeflow como uma solução de plataforma MLOps completa para"Cadernos Jupyter" , rastreamento de experimentos, treinamento automatizado e pipelines de dados e inferência.