

Configurar grupos de disponibilidade Always On do SQL Server com Google Cloud NetApp Volumes
 Sugerir alterações
Sugerir alterações
Configure grupos de disponibilidade Always On do SQL Server em instâncias do Google Compute Engine em uma única sub-rede usando o armazenamento em bloco iSCSI do Google Cloud NetApp Volumes. Saiba como configurar instâncias de computação, configurar volumes NetApp, estabelecer clustering de failover e implantar grupos de disponibilidade para alta disponibilidade e recuperação de desastres.
Pré-requisitos
Antes de prosseguir, conclua as etapas de pré-requisito de configuração na documentação do Google Cloud:
Antes de começar
Certifique-se de ter concluído os seguintes requisitos:
-
Projeto do Google Cloud com permissões de administrador para computação, rede, IAM e armazenamento
-
Rede VPC com sub-rede para setup de região
-
Configuração do Active Directory e DNS disponível em uma região
-
Regras de firewall configuradas para permitir as portas necessárias
-
Familiaridade com SQL Server Always On availability groups e failover clustering

|
Novos usuários do Google Cloud podem ser elegíveis para "créditos de teste grátis". |
Objetivos
A configuração do grupo de disponibilidade Always On do SQL Server inclui as seguintes tarefas de alto nível:
-
Configurar instâncias do Compute Engine e volumes de armazenamento NetApp
-
Configurar o SQL Server em ambos os nós
-
Configurar o clustering de failover do Windows Server
-
Configurar o quorum do cluster com file share witness
-
Configurar os grupos de disponibilidade do SQL Server
-
Configurar Distributed Network Name (DNN) para acesso do listener
Considerações sobre custos
Este tutorial utiliza componentes faturáveis do Google Cloud, incluindo "Instâncias do Compute Engine" e "Google Cloud NetApp Volumes" armazenamento.
Use a "Calculadora de preços" para gerar uma estimativa de custo com base nos seus requisitos de computação e armazenamento. A configuração de exemplo utiliza instâncias de computação N4-SKU e armazenamento de nível de serviço Flex da NetApp para a configuração do grupo de disponibilidade Always On do SQL Server.
Configurar contas de domínio
Configure duas contas no Active Directory: uma conta de instalação (sua conta de administrador) e uma conta de serviço para ambas as VMs do SQL Server.
Por exemplo, use os valores na tabela a seguir para as contas:
|
|
Este exemplo usa cvsdemo como nome de domínio. Substitua cvsdemo pelo seu nome de domínio ao longo deste procedimento.
|
| Conta | VM | Nome de domínio completo | Descrição |
|---|---|---|---|
<your account> |
Ambos (sqlnode1 e sqlnode2) |
cvsdemo\DomainAdmin |
Conta de administrador para fazer login em qualquer uma das máquinas virtuais e configurar o clustering e o grupo de disponibilidade |
sqlsvc |
Ambos (sqlnode1 e sqlnode2) |
cvsdemo\sqlsvc |
Conta de serviço para SQL Server e SQL Server Agent em ambas as VMs do SQL Server |
Criar VMs do Compute Engine para SQL Server
Crie duas instâncias de máquina virtual do Google Compute Engine com SQL Server 2022 Enterprise pré-instalado no Windows Server 2025 para hospedar as réplicas do grupo de disponibilidade.
-
No console do Google Cloud, acesse a página "Criar uma instância".
Consulte o "Documentação do Google Cloud" para mais informações.
-
Para Nome, insira
sqlnode1. -
Na seção Machine configuration:
-
Selecione General Purpose
-
Na lista Series, selecione N4
-
Na lista Tipo de máquina, selecione n4-highmem-8 (8 vCPU, 64 GB memória)
-
-
Selecione a região onde você criou sua VPC (por exemplo, region=us-west1, zone=us-west1-a).
-
Na seção Disco de inicialização, clique em Alterar:
-
Na guia Imagens públicas, na lista Sistema operacional, selecione SQL Server on Windows Server.
-
Na lista Versão, selecione SQL Server 2022 Enterprise on Windows Server 2025 Datacenter.
-
Na lista Tipo de disco de inicialização, selecione Hyperdisk Balanced.
-
No campo Tamanho (GB), insira 50 GB.
-
Clique em Select para salvar a configuração do disco de inicialização.
-
-
Na seção Networking, edite a interface de rede para selecionar a VPC e a sub-rede corretas. Se você tiver apenas uma VPC network, ela será selecionada por padrão.
-
Na placa de interface de rede, selecione gVNIC.
-
Para "Nível de serviço de rede", selecione Premium para cargas de trabalho de missão crítica ou Standard para otimizar custos.
-
-
Clique em Create para criar a máquina virtual.
-
Repita estes passos para criar
sqlnode2.
Adicionar servidores ao domínio
Após criar as VMs, associe-as ao domínio do Active Directory e instale os recursos do Windows necessários para clustering de failover e conectividade iSCSI.
-
Conecte-se remotamente à máquina virtual com a conta de administrador local.
-
No Server Manager, selecione Local Server.
-
Selecione o link WORKGROUP.
-
Na seção Nome do computador, selecione Alterar.
-
Selecione a caixa de seleção Domínio e insira seu domínio (por exemplo,
cvsdemo.internal) na caixa de texto. -
Clique em OK.
-
Na caixa de diálogo Segurança do Windows, especifique as credenciais da conta de administrador de domínio padrão (por exemplo,
cvsdemo\DomainAdmin). -
Quando você vir a mensagem "Welcome to the cvsdemo.internal domain", clique em OK.
-
Clique em Fechar e, em seguida, selecione Reiniciar agora na caixa de diálogo.
-
Após a reinicialização do servidor, adicione a
sqlsvcconta ao grupo Administradores.
|
|
Sua instância do SQL será executada usando a conta sqlsvc, que é necessária para clustering e configuração de failover. |
Instalar os recursos necessários do Windows
Instale o clustering de failover e o MPIO em ambas as VMs do SQL Server usando Server Manager ou PowerShell.
-
No Server Manager, selecione Manage > Add Roles and Features.
-
Selecione Role-based or feature-based installation e clique em Next.
-
Selecione o seu servidor e clique em Next.
-
Na página Recursos, selecione clustering de failover e Multipath I/O.
-
Clique em Adicionar funcionalidades quando solicitado a incluir ferramentas de gerenciamento.
-
Conclua o assistente e reinicie se solicitado.
Execute o PowerShell como administrador e execute os seguintes comandos:
# Install Failover Clustering and tools
Install-WindowsFeature Failover-Clustering, RSAT-Clustering-PowerShell, RSAT-Clustering-CmdInterface -IncludeAllSubFeature -IncludeManagementTools
# Install/enable MPIO
Install-WindowsFeature -Name Multipath-IO
Enable-MSDSMAutomaticClaim -BusType "iSCSI"
# Install .NET and other SQL prerequisites (if not already installed)
Install-WindowsFeature NET-Framework-45-Core, NET-Framework-45-Features
Install-WindowsFeature RSAT-AD-PowerShellObtenha nomes de iniciador iSCSI
Obtenha o nome qualificado iSCSI (IQN) para cada máquina virtual do SQL Server a ser incluída no grupo de hosts usando a interface gráfica do iniciador iSCSI ou PowerShell.
-
Pressione Win+R ou use a barra de pesquisa do Windows para abrir
iscsicpl. -
Na caixa de diálogo Propriedades do iniciador iSCSI, vá para a guia Configuração.
-
Copie o valor Initiator Name e inclua-o no grupo de hosts.
Exemplo:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal
Execute o seguinte comando no PowerShell:
Get-InitiatorPort | Select-Object NodeAddressCriar volumes de armazenamento em bloco NetApp
Crie volumes de armazenamento em bloco iSCSI usando o Google Cloud NetApp Volumes para fornecer storage compartilhado de alto desempenho para bancos de dados SQL Server. Esse processo inclui a criação de um grupo de hosts, pool de storage e volumes individuais para dados, logs, temp e backup.
Crie o grupo de hosts
-
Crie um grupo de hosts contendo os iniciadores iSCSI de ambos os nós SQL.
gcloud beta netapp host-groups create HOST_GROUP_NAME \ --location=LOCATION \ --type=ISCSI_INITIATOR \ --hosts=HOSTS \ --os-type=OS_TYPE \ --description=DESCRIPTIONPara mais detalhes, consulte a "Criar um grupo de hosts" documentação.
-
Substitua os seguintes valores:
-
HOST_GROUP_NAME: Nome do grupo de hosts (por exemplo,demosql) -
LOCATION: região (por exemplo,us-west1) -
HOSTS: Lista de IQNs separados por vírgulas de sqlnode1 e sqlnode2Exemplo:
iqn.1991-05.com.microsoft:sqlnode1.cvsdemo.internal,iqn.1991-05.com.microsoft:sqlnode2.cvsdemo.internal -
OS_TYPE: Tipo de sistema operacional (por exemplo,WINDOWS) -
DESCRIPTION: Descrição opcional para o grupo de hosts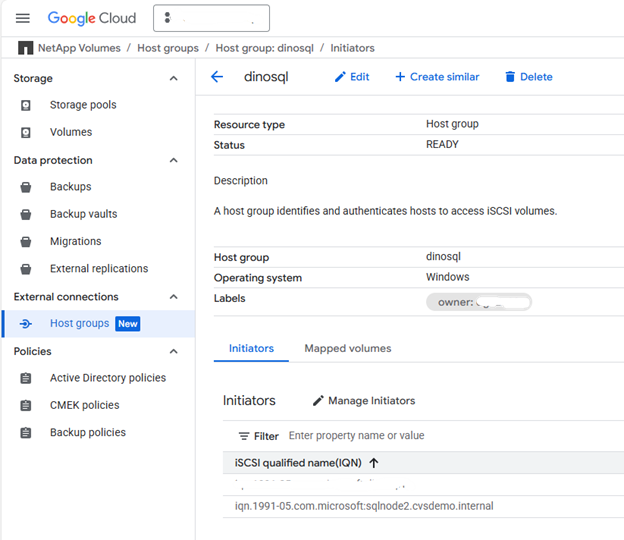
-
Criar pool de storage
-
Crie um pool de storage com capacidade e desempenho adequados.
gcloud netapp storage-pools create POOL_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --service-level=Flex \ --type=Unified \ --capacity=1024 \ --total-throughput=64 \ --total-iops=1024 \ --network=name=VPC_NAME,psa-range=PSA_RANGEPara mais detalhes, consulte a "Criar um pool de armazenamento" documentação.
-
Substitua os seguintes valores:
-
POOL_NAME: nome do pool (por exemplo,sqltest) -
PROJECT_ID: nome do seu projeto do Google Cloud -
LOCATION: mesmo local que suas instâncias de computação (por exemplo,us-west1-b) -
CAPACITY: Capacidade do pool em GiB (por exemplo,1024) -
SERVICE_LEVEL: Nível de serviço (por exemplo,Flex) -
VPC_NAME: nome da sua rede VPC -
PSA_RANGE: faixa de acesso a serviços privados (por exemplo,xx.xxx.xxx.0/20) -
THROUGHPUT: Taxa de transferência opcional em MiBps (por exemplo,64) -
IOPS: IOPS opcionais (por exemplo,1024)
-
Criar volumes
-
Crie volumes para dados, logs, temp e backup. Execute o seguinte comando para cada tipo de volume:
gcloud beta netapp volumes create VOLUME_NAME \ --project=PROJECT_ID \ --location=LOCATION \ --storage-pool=POOL_NAME \ --capacity=CAPACITY \ --protocols=ISCSI \ --block-devices="name=VOLUME_NAME,host-groups=HOST_GROUP_PATH,os-type=WINDOWS" \ --snapshot-directory=falsePara mais detalhes, consulte a "Criar um volume" documentação.
-
Substitua os seguintes valores:
-
VOLUME_NAME: Nome único para cada volume (por exemplo,node1data,node1log,node1temp,node1backup) -
PROJECT_ID: nome do seu projeto do Google Cloud -
LOCATION: Mesmo local que pool de storage (por exemplo,us-west1-b) -
POOL_NAME: nome do pool de storage (por exemplo,sqltest) -
CAPACITY: Capacidade de volume em GiB (por exemplo,200) -
HOST_GROUP_PATH: caminho completo do recurso para o grupo de hosts (por exemplo,projects/PROJECT_ID/locations/us-west1/hostGroups/demosql)
-

|
É possível especificar vários grupos de hosts com um sinal de # separando cada grupo de hosts. |
|
|
Repita esta etapa para cada tipo de volume: data, log, temp e backup. |
Montar volumes iSCSI
Monte os volumes iSCSI não compartilhados em cada instância do SQL Server:
-
No console do Google Cloud, navegue até NetApp volumes > Volumes.
-
Selecione o volume criado para a instância SQL (por exemplo,
node1data). -
Copie os dois endereços IP do destino iSCSI (por exemplo,
10.165.128.216e10.165.128.217). -
No sqlnode1, execute
iscsicplou use PowerShell: -
Clique na aba Discover e, em seguida, em Discover Portal.
-
Adicione cada endereço IP obtido; deixe a porta padrão 3260.
"10.165.128.216","10.165.128.217" | % { New-IscsiTargetPortal -TargetPortalAddress $_ }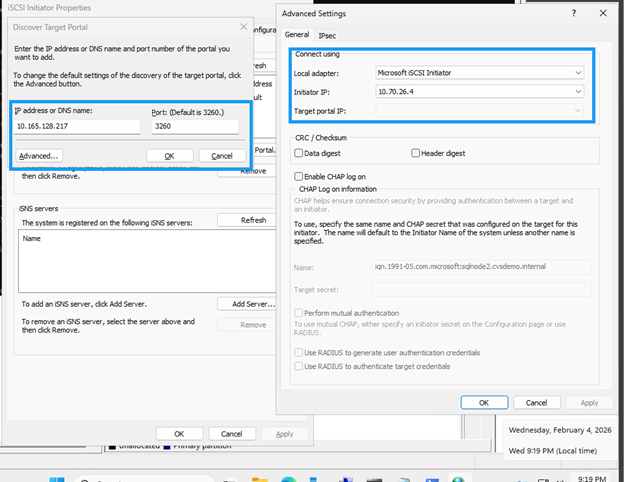
-
Na caixa de diálogo Conectar ao destino, marque Habilitar multipath se estiver usando multipathing.
-
Clique em Avançado e selecione o endereço IP do portal de destino no menu suspenso.
-
Clique em OK para conectar.
-
Configure MPIO para dispositivos iSCSI
-
Abra o MPIO a partir do Painel de Controle ou Server Manager.
-
Clique na aba Discover Multi-Paths.
-
Marque a opção Adicionar suporte para dispositivos iSCSI e clique em Adicionar.
-
Reinicie se solicitado.
-
Verifique a configuração de multipath no Gerenciador de Dispositivos em Unidades de disco.
-
-
Inicializar e formatar volumes
-
Inicie o Gerenciamento do Computador (
compmgmt.msc) e selecione Gerenciamento de Disco. -
Inicialize, particione e formate cada disco com unidade de alocação de 64K:
Format-Volume -DriveLetter <DriveLetter> -FileSystem NTFS -NewFileSystemLabel <Label> -AllocationUnitSize 65536 -Confirm:$false -
Atribua letras às unidades de disco (por exemplo, D: para dados, E: para log, F: para backup, G: para temp).
-
Crie a estrutura de diretórios para SQL Server:
$paths = "D:\MSSQL\DATA","E:\MSSQL\Log","F:\MSSQL\Backup","G:\MSSQL\Temp" $paths | % { New-Item -ItemType Directory -Path $_ -Force }
-
Configurar SQL Server
Configure o SQL Server em ambos os nós para usar a conta de serviço do domínio, atualize os caminhos padrão para usar NetApp volumes e mova os bancos de dados do sistema para os novos locais de storage.
-
Atualize os serviços do SQL Server e do SQL Server Agent para serem executados na conta de serviço do domínio para autenticação do cluster e suporte a failover.
-
Em cada instância SQL, abra
services.msc. -
Atualize Fazer logon como
domain\sqlsvcpara os serviços do SQL Server e SQL Server Agent. -
Abra o SQL Server Management Studio (SSMS) e conecte-se com sua conta de domínio.
Se a conexão falhar, inicie o SSMS como
<local computer>\Administrator. Certifique-se de que a conta Administrator esteja habilitada em Users & Groups com a senha apropriada.
-
-
Crie os logins das contas de domínio com as permissões necessárias.
Substitua CVSDEMOpelo seu nome de domínio nos seguintes comandos SQL.USE [master] GO -- Create login for SQL service account CREATE LOGIN [CVSDEMO\sqlsvc] FROM WINDOWS WITH DEFAULT_DATABASE=[master], DEFAULT_LANGUAGE=[us_english] GO -- Add to sysadmin role ALTER SERVER ROLE [sysadmin] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Create user in master and assign role USE [master] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -- Repeat for model, msdb, and tempdb databases USE [model] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [msdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO USE [tempdb] GO CREATE USER [CVSDEMO\sqlsvc] FOR LOGIN [CVSDEMO\sqlsvc] GO ALTER ROLE [db_owner] ADD MEMBER [CVSDEMO\sqlsvc] GO -
Atualize os caminhos padrão para usar os volumes NetApp em vez da unidade do sistema operacional:
USE [master] GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'BackupDirectory', REG_SZ, N'F:\MSSQL\Backup' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultData', REG_SZ, N'D:\MSSQL\DATA' GO EXEC xp_instance_regwrite N'HKEY_LOCAL_MACHINE', N'Software\Microsoft\MSSQLServer\MSSQLServer', N'DefaultLog', REG_SZ, N'E:\MSSQL\Log' GO -
Mova os bancos de dados do sistema (model, msdb, tempdb e master) da unidade do sistema operacional para os volumes NetApp para melhor desempenho e gerenciamento.
-
Verifique os caminhos atuais:
-- Check current paths SELECT name, physical_name FROM sys.master_files WHERE database_id IN (DB_ID('model'), DB_ID('msdb')); -
Atualizar para novos locais:
-- Move model database ALTER DATABASE model MODIFY FILE (NAME = modeldev, FILENAME = 'D:\MSSQL\Data\model.mdf'); ALTER DATABASE model MODIFY FILE (NAME = modellog, FILENAME = 'E:\MSSQL\Log\modellog.ldf'); -- Move msdb database ALTER DATABASE msdb MODIFY FILE (NAME = MSDBData, FILENAME = 'D:\MSSQL\Data\MSDBData.mdf'); ALTER DATABASE msdb MODIFY FILE (NAME = MSDBLog, FILENAME = 'E:\MSSQL\Log\MSDBLog.ldf'); GO -
Pare o SQL Server, mova manualmente os arquivos do local antigo para os novos caminhos e, em seguida, reinicie o SQL Server.
-
Mover o banco de dados tempdb
USE master; GO -- Check current tempdb files SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID('tempdb'); -- Change paths for tempdb ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'G:\MSSQL\Temp\tempdb.mdf'); ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'G:\MSSQL\Temp\templog.ldf'); GO -
Reinicie o SQL Server para que as alterações entrem em vigor:
Restart-Service -Name "MSSQLSERVER" -Force
-
-
Mova o banco de dados mestre
-
Abra o SQL Server Configuration Manager.
-
Navegue até SQL Server Services, clique com o botão direito em SQL Server (MSSQLSERVER) e selecione Properties.
-
Clique na guia Startup Parameters.
-
Em Parâmetros existentes, localize os parâmetros que começam com
-d,-ee-l. -
Remova os parâmetros antigos e adicione novos:
-dD:\MSSQL\Data\master.mdf -lE:\MSSQL\Log\mastlog.ldf -eE:\MSSQL\Log\ERRORLOG

-
Clique em OK.
-
-
Pare o serviço do SQL Server.
-
Mova manualmente
master.mdfemastlog.ldfda localização antiga para os novos caminhos. -
Se você atualizou o caminho do log de erros, mova o arquivo
ERRORLOGtambém. -
Inicie o serviço SQL Server.
Configurar cluster de failover
Configure o Failover Clustering do Windows Server para fornecer alta disponibilidade para o SQL Server. Para mais detalhes, consulte "Documentação sobre Clustering de Failover do Windows Server".
Configurar regras de firewall
Abra as portas de rede necessárias em ambos os nós SQL para habilitar a comunicação do cluster, a conectividade com o SQL Server e a replicação do grupo de disponibilidade.
-
Abra as portas necessárias em ambos os nós SQL para comunicação do cluster.
Portas necessárias incluem: UDP 3343, TCP 3343, TCP 1433, TCP 5022, TCP 135, TCP 445, TCP 49152-65535 (RPC dinâmico).
-
Execute o seguinte ponto de verificação em ambos os servidores para permitir a comunicação entre o SQL Server e o cluster através do firewall.
Ajuste os números das portas se você tiver configurações personalizadas.
# Open firewall for SQL Server netsh advfirewall firewall add rule name="Allow SQL Server" dir=in action=allow protocol=TCP localport=1433 # Open firewall for SQL Server replication netsh advfirewall firewall add rule name="Allow SQL Server replication" dir=in action=allow protocol=TCP localport=5022Para obter requisitos detalhados de firewall, consulte "Requisitos de serviço e porta de rede do Windows Server".
-
Execute verificações de validação em ambos os nós antes de criar o cluster:
Test-Connection servername Resolve-DnsName servername Get-NetAdapterBinding -ComponentID ms_tcpip6
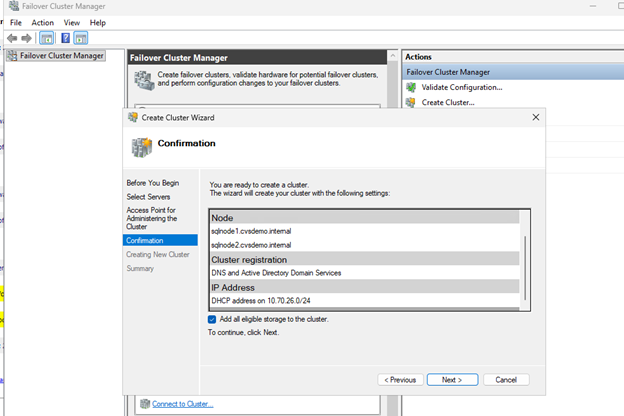
Crie o cluster de failover
Crie um Windows Server Failover Cluster com ambos os nós do SQL Server para habilitar alta disponibilidade e recursos de failover automático.
-
Execute
cluadmin.mscou abra o Gerenciador de Cluster de Failover no Server Manager.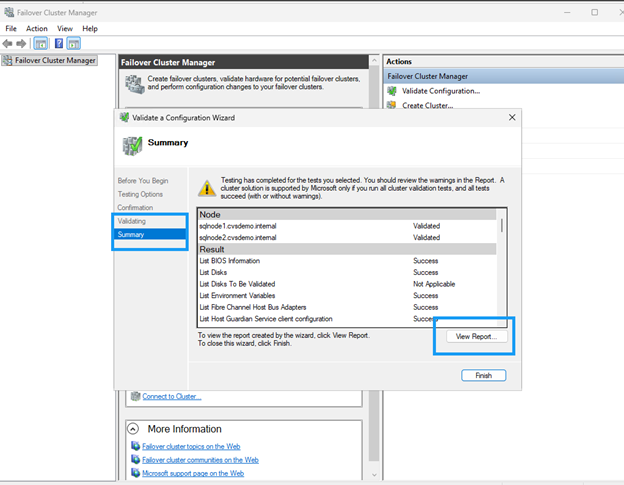
-
Selecione Create Cluster.
-
Adicione ambos os nós SQL (sqlnode1, sqlnode2).
-
Execute testes de validação e certifique-se de que todas as verificações sejam aprovadas. Analise e corrija quaisquer avisos antes de prosseguir.
-
Forneça um nome de cluster (por exemplo,
sqlcluwest1). -
Conclua a criação do cluster.
Configurar o quorum do cluster com testemunha de compartilhamento de arquivos
Configure uma testemunha de compartilhamento de arquivos para manter o quorum em um cluster de dois nós. A testemunha fornece um voto adicional para evitar cenários de split-brain e garantir a disponibilidade do cluster.
Criar compartilhamento de arquivos
Crie um compartilhamento de arquivos em uma VM em uma zona ou região diferente que tenha conectividade de rede e esteja dentro do mesmo domínio do Active Directory.
-
Conecte-se à VM do servidor testemunha de compartilhamento de arquivos.
-
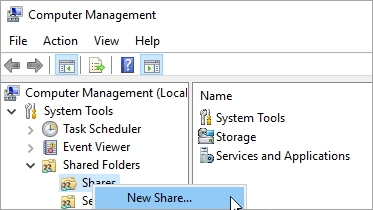
No Server Manager, selecione Tools > Computer Management.
-
Selecione Pastas Compartilhadas, clique com o botão direito em Compartilhamentos e selecione Novo Compartilhamento.
-
Use o Assistente para Criar uma Pasta Compartilhada para criar um compartilhamento
\\servername\share. -
Na página Caminho da Pasta, selecione Procurar.
-
Localize ou crie um caminho para a pasta compartilhada e selecione Next.
-
Na página Nome, Descrição e Configurações, verifique o nome e o caminho do compartilhamento e selecione Next.
-
Na página Permissões de pasta compartilhada, selecione Personalizar permissões e clique em Custom
-
Na caixa de diálogo Personalizar permissões, selecione Adicionar para adicionar a conta do cluster.
Certifique-se de que a conta que está sendo usada para criar o cluster (sqlcluwest1$) tenha controle total.
-
Clique em OK para salvar permissões.
-
Na página Permissões de Pasta Compartilhada, selecione Concluir e selecione Concluir novamente.
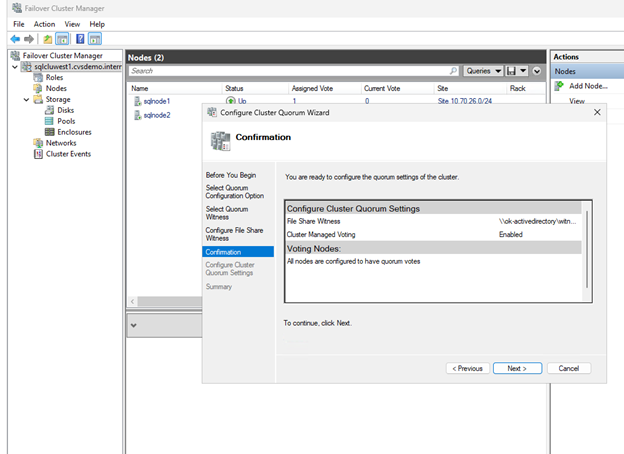
Configurar configurações de quorum
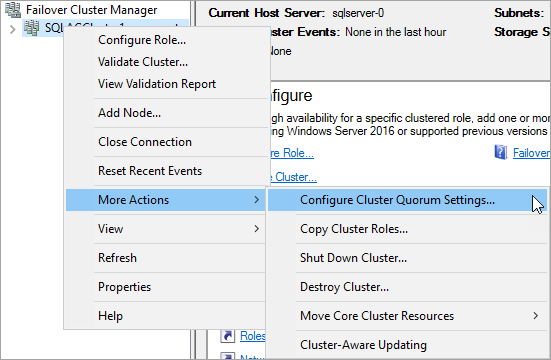
Configurar o cluster para usar o compartilhamento de arquivos como testemunha para votação de quorum.
-
No Failover Cluster Manager, clique com o botão direito do mouse no cluster e selecione More Actions > Configure Cluster Quorum Settings.
-
No Assistente de Configurar Quórum de Cluster, clique em Avançar.
-
Na página Selecionar Configuração de Quórum, escolha Selecionar a testemunha de quórum e clique em Next.
-
Na página Selecionar testemunha de quórum, selecione Configurar um file share witness.
-
Na página Configurar File Share Witness, selecione Configurar a file share witness.
-
Insira o caminho para o compartilhamento que você criou (por exemplo,
\\servername\share) e clique em Avançar. -
Verifique as configurações na página de Confirmação e clique em Next.
-
Clique em Concluir.
Os recursos principais do cluster agora estão configurados com um file share witness.
Ativar grupos de disponibilidade Always On
Ative os grupos de disponibilidade Always On em ambas as VMs do SQL Server:
-
No menu Iniciar, abra o SQL Server Configuration Manager.
-
Na árvore do navegador, selecione SQL Server Services.
-
Clique com o botão direito em SQL Server (MSSQLSERVER) e selecione Propriedades.
-
Selecione a guia Always On High Availability.
-
Marque Ativar grupos de disponibilidade Always On.
-
Clique em Aplicar e, em seguida, reinicie o serviço do SQL Server quando solicitado.
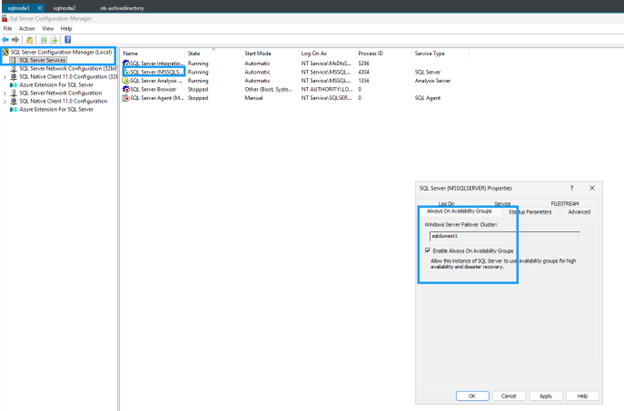
-
Repita para a segunda instância do SQL Server.
Crie um banco de dados na primeira instância do SQL Server
Crie um banco de dados na primeira instância do SQL Server.
-
Conecte-se à primeira máquina virtual do SQL Server com uma conta de domínio que seja membro da função do servidor sysadmin fixa.
-
Abra o SQL Server Management Studio e conecte-se à primeira instância do SQL Server.
-
No Explorador de Objetos, clique com o botão direito do mouse em Bancos de Dados e selecione Novo Banco de Dados.
-
Insira um nome de banco de dados (por exemplo,
MyDB1) e clique em OK. -
Defina o modo de recuperação de banco de dados como Completo:
ALTER DATABASE MyDB1 SET RECOVERY FULL; GO
Criar e configurar grupo de disponibilidade
Crie um grupo de disponibilidade Always On com commit síncrono e failover automático para fornecer alta disponibilidade para seus bancos de dados SQL Server.
-
Faça um backup completo e um backup do log de transações do banco de dados.
-- Full backup BACKUP DATABASE MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH INIT, COMPRESSION; -- Transaction log backup BACKUP LOG MyDB1 TO DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH INIT, COMPRESSION; -
Copie os arquivos de backup para a segunda instância do SQL Server e restaure-os com NORECOVERY.
-- Restore full backup RESTORE DATABASE MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Full.bak' WITH NORECOVERY; -- Restore log backup RESTORE LOG MyDB1 FROM DISK = 'F:\MSSQL\Backup\MyDB1_Log.trn' WITH NORECOVERY; -
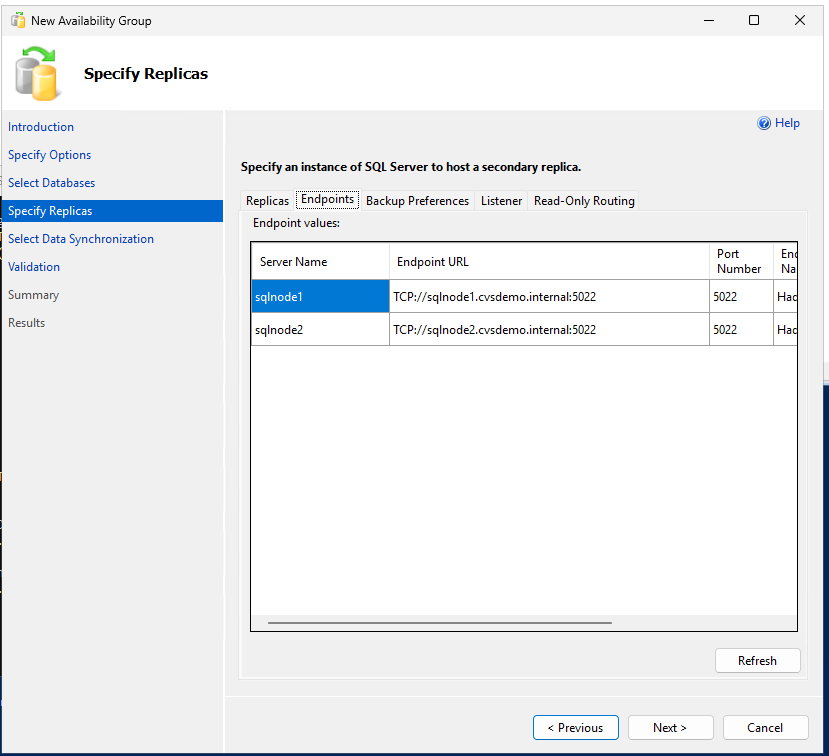
Crie o grupo de disponibilidade com commit síncrono, failover automático e réplicas secundárias legíveis:
-- Run on primary replica CREATE AVAILABILITY GROUP sqlagwest1 WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY) FOR DATABASE MyDB1 REPLICA ON N'SQLNODE1' WITH ( ENDPOINT_URL = N'TCP://sqlnode1.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ), N'SQLNODE2' WITH ( ENDPOINT_URL = N'TCP://sqlnode2.cvsdemo.internal:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = YES) ); GO -
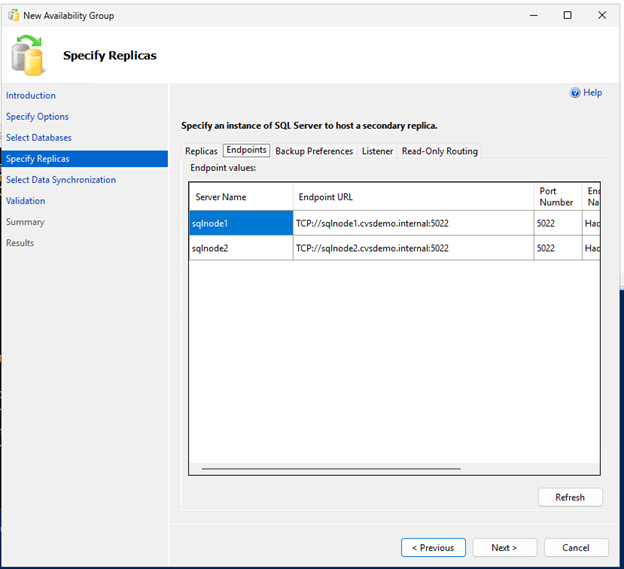
Crie o grupo de disponibilidade usando o Assistente de Grupo de Disponibilidade.
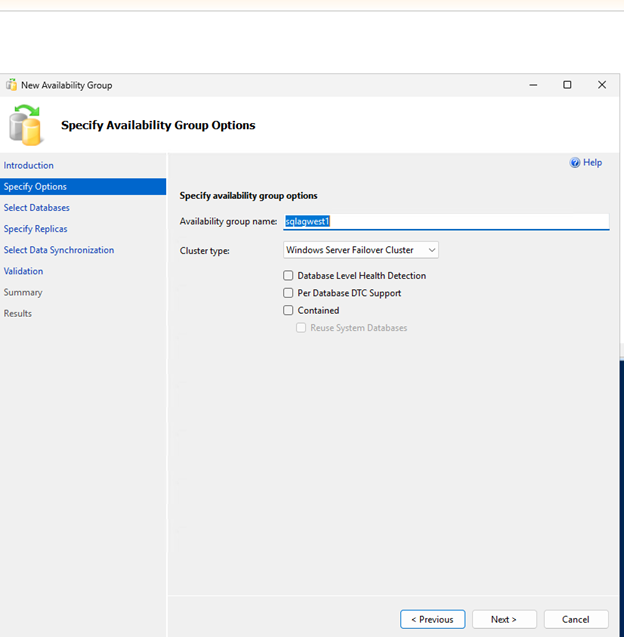


Certifique-se de que a porta 5022 do firewall esteja liberada em ambos os nós SQL. 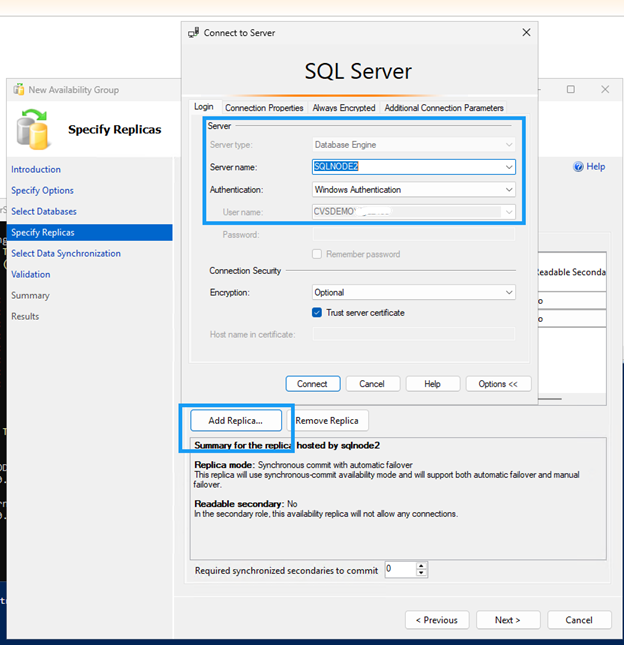
Criar recurso de listener DNN
Crie um ouvinte de Distributed Network Name (DNN) para rotear o tráfego para o recurso clusterizado apropriado sem a necessidade de um balanceador de carga.
Utilize PowerShell para criar o recurso DNN:
$Ag = "sqlagwest1"
$Dns = "AOAGDNN"
$Port = "1433"
# Add DNN resource
Add-ClusterResource -Name $Dns -ResourceType "Distributed Network Name" -Group $Ag
# Set DNN properties
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name DnsName -Value $Dns
Get-ClusterResource -Name $Dns | Set-ClusterParameter -Name Port -Value $Port
# Start DNN resource
Start-ClusterResource -Name $Dns
# Add dependency
$AagResource = Get-ClusterResource | Where-Object {$_.ResourceType -eq "SQL Server Availability Group" -and $_.OwnerGroup -eq $Ag}
Set-ClusterResourceDependency -Resource $AagResource -Dependency "[$Dns]"Configurar possíveis proprietários
Por padrão, o cluster associa o nome DNS do DNN a todos os nós. Exclua os nós que não participam do grupo de disponibilidade:
-
No Failover Cluster Manager, localize o recurso DNN.
-
Clique com o botão direito do mouse no recurso DNN e selecione Propriedades.
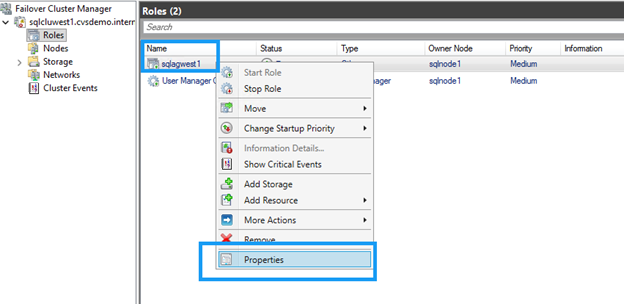
-
Desmarque a caixa de seleção de quaisquer nós que não participam do grupo de disponibilidade.
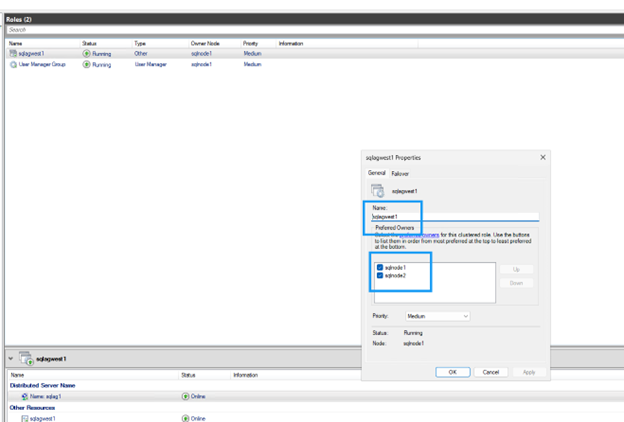
-
Clique em OK para salvar configurações.
Atualize strings de conexão do aplicativo
Atualize as strings de conexão para usar o nome do listener DNN e inclua o MultiSubnetFailover=True parâmetro:
Server=AOAGDNN,1433;Database=MyDB1;MultiSubnetFailover=True;
|
|
Se o seu cliente não suportar o parâmetro MultiSubnetFailover, ele não será compatível com DNN. |
Testar failover
Verifique a configuração do grupo de disponibilidade e teste o failover para garantir que o failover automático funcione corretamente entre os nós.
-
Execute o seguinte comando em qualquer réplica para verificar a configuração do grupo de disponibilidade.
Ambas as réplicas devem mostrar
SYNCHRONOUS_COMMITpara o modo de disponibilidade eAUTOMATICpara o modo de failover, o que garante zero perda de dados durante o failover automático.SELECT ag.name AS AG_Name, ars.primary_replica FROM sys.dm_hadr_availability_group_states AS ars JOIN sys.availability_groups AS ag ON ag.group_id = ars.group_id; -- Check replica configuration SELECT replica_server_name, availability_mode_desc, failover_mode_desc FROM sys.availability_replicas WHERE group_id = (SELECT group_id FROM sys.availability_groups WHERE name = N'sqlagwest1');
-
Execute o seguinte comando no nó secundário para iniciar o failover:
ALTER AVAILABILITY GROUP sqlagwest1 FAILOVER; GO -
Verifique se o destino da conectividade foi alterado para o novo primário:
-- SELECT @@SERVERNAME AS NowPrimary;No SSMS, expanda o nó do grupo de disponibilidade, clique com o botão direito em Always On High Availability e selecione Show Dashboard.
O painel de controle deve exibir ambos os nós com status saudável e confirmar o failover.
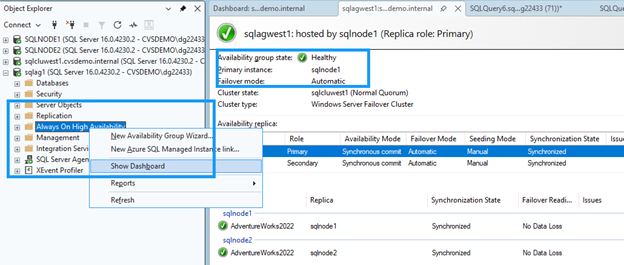
Limpar recursos
Após concluir o tutorial, exclua os recursos que você criou para evitar cobranças adicionais:
-
Excluir instâncias do Compute Engine (sqlnode1, sqlnode2)
-
Excluir Google Cloud NetApp Volumes (volumes, pools de armazenamento, grupos de hosts)
-
Exclua os recursos de VPC e de rede se eles tiverem sido criados especificamente para este tutorial
-
Exclua o servidor file share witness, se aplicável
Consulte "Documentação do Google Cloud NetApp Volumes" e "Documentação do Google Compute Engine" para obter instruções detalhadas sobre como excluir recursos.
Onde encontrar informações adicionais
Para obter mais informações sobre o SQL Server no Google Cloud com NetApp storage, consulte a seguinte documentação: