

TR-4923: SQL Server no AWS EC2 usando Amazon FSx ONTAP
 Sugerir alterações
Sugerir alterações
Esta solução abrange a implantação do SQL Server no AWS EC2 usando o Amazon FSx ONTAP.
Introdução
Muitas empresas que gostariam de migrar aplicativos locais para a nuvem descobrem que o esforço é prejudicado pelas diferenças nos recursos oferecidos pelos sistemas de armazenamento locais e serviços de armazenamento em nuvem. Essa lacuna tornou a migração de aplicativos corporativos, como o Microsoft SQL Server, muito mais problemática. Em particular, lacunas nos serviços necessários para executar um aplicativo empresarial, como snapshots robustos, recursos de eficiência de armazenamento, alta disponibilidade, confiabilidade e desempenho consistente, forçaram os clientes a fazer concessões de design ou abrir mão da migração de aplicativos. Com o FSx ONTAP, os clientes não precisam mais fazer concessões. O FSx ONTAP é um serviço nativo (próprio) da AWS vendido, suportado, cobrado e totalmente gerenciado pela AWS. Ele usa o poder do NetApp ONTAP para fornecer os mesmos recursos de armazenamento de nível empresarial e gerenciamento de dados que a NetApp fornece no local há três décadas na AWS como um serviço gerenciado.
Com o SQL Server em instâncias EC2, os administradores de banco de dados podem acessar e personalizar seu ambiente de banco de dados e o sistema operacional subjacente. Uma instância do SQL Server no EC2 em combinação com "AWS FSx ONTAP" para armazenar os arquivos de banco de dados, permite alto desempenho, gerenciamento de dados e um caminho de migração simples e fácil usando replicação em nível de bloco. Portanto, você pode executar seu banco de dados complexo no AWS VPC com uma abordagem fácil de elevação e transferência, menos cliques e sem conversões de esquema.
Benefícios de usar o Amazon FSx ONTAP com SQL Server
O Amazon FSx ONTAP é o armazenamento de arquivos ideal para implantações do SQL Server na AWS. Os benefícios incluem o seguinte:
-
Alto desempenho e rendimento consistentes com baixa latência
-
Cache inteligente com cache NVMe para melhorar o desempenho
-
Dimensionamento flexível para que você possa aumentar ou diminuir a capacidade, a taxa de transferência e os IOPs em tempo real
-
Replicação eficiente de blocos locais para AWS
-
O uso do iSCSI, um protocolo bem conhecido para o ambiente de banco de dados
-
Recursos de eficiência de armazenamento, como provisionamento fino e clones de pegada zero
-
Redução do tempo de backup de horas para minutos, reduzindo assim o RTO
-
Backup e recuperação granulares de bancos de dados SQL com a interface intuitiva do NetApp SnapCenter
-
A capacidade de executar várias migrações de teste antes da migração real
-
Menor tempo de inatividade durante a migração e superação dos desafios de migração com cópia em nível de arquivo ou de E/S
-
Reduzir o MTTR ao encontrar a causa raiz após uma versão importante ou atualização de patch
A implantação de bancos de dados SQL Server no FSx ONTAP com o protocolo iSCSI, como é comumente usado no local, fornece um ambiente de armazenamento de banco de dados ideal com desempenho superior, eficiência de armazenamento e recursos de gerenciamento de dados. Usando múltiplas sessões iSCSI, assumindo um tamanho de conjunto de trabalho de 5%, a instalação de um Flash Cache fornece mais de 100 mil IOPs com o serviço FSx ONTAP . Esta configuração fornece controle total sobre o desempenho dos aplicativos mais exigentes. O SQL Server em execução em instâncias EC2 menores conectadas ao FSx ONTAP pode ter o mesmo desempenho que o SQL Server em execução em uma instância EC2 muito maior, porque apenas os limites de largura de banda da rede são aplicados ao FSx ONTAP. Reduzir o tamanho das instâncias também reduz o custo de computação, o que proporciona uma implantação otimizada em termos de TCO. A combinação de SQL usando iSCSI, SMB3.0 com compartilhamentos de disponibilidade contínua e multicanal no FSx ONTAP oferece grandes vantagens para cargas de trabalho SQL.
Antes de começar
A combinação do Amazon FSx ONTAP e do SQL Server na instância EC2 permite a criação de designs de armazenamento de banco de dados de nível empresarial que podem atender aos requisitos de aplicativos mais exigentes da atualidade. Para otimizar ambas as tecnologias, é essencial entender os padrões e características de E/S do SQL Server. Um layout de armazenamento bem projetado para um banco de dados SQL Server dá suporte ao desempenho do SQL Server e ao gerenciamento da infraestrutura do SQL Server. Um bom layout de armazenamento também permite que a implantação inicial seja bem-sucedida e que o ambiente cresça suavemente ao longo do tempo, à medida que seu negócio cresce.
Pré-requisitos
Antes de concluir as etapas deste documento, você deve ter os seguintes pré-requisitos:
-
Uma conta AWS
-
Funções IAM apropriadas para provisionar EC2 e FSx ONTAP
-
Um domínio do Windows Active Directory no EC2
-
Todos os nós do SQL Server devem ser capazes de se comunicar entre si
-
Certifique-se de que a resolução de DNS funcione e que os nomes de host possam ser resolvidos. Caso contrário, use a entrada do arquivo host.
-
Conhecimento geral de instalação do SQL Server
Além disso, consulte as Práticas recomendadas da NetApp para ambientes SQL Server para garantir a melhor configuração de armazenamento.
Configurações de práticas recomendadas para ambientes SQL Server no EC2
Com o FSx ONTAP, a obtenção de armazenamento é a tarefa mais fácil e pode ser realizada atualizando o sistema de arquivos. Esse processo simples permite a otimização dinâmica de custos e desempenho conforme necessário, ajuda a equilibrar a carga de trabalho do SQL e também é um ótimo facilitador para provisionamento fino. O provisionamento fino do FSx ONTAP foi projetado para apresentar mais armazenamento lógico para instâncias do EC2 que executam o SQL Server do que o que é provisionado no sistema de arquivos. Em vez de alocar espaço antecipadamente, o espaço de armazenamento é alocado dinamicamente para cada volume ou LUN à medida que os dados são gravados. Na maioria das configurações, o espaço livre também é liberado quando os dados no volume ou LUN são excluídos (e não estão sendo mantidos por nenhuma cópia do Snapshot). A tabela a seguir fornece definições de configuração para alocação dinâmica de armazenamento.
Contexto |
Configuração |
Garantia de volume |
Nenhum (definido por padrão) |
Reserva LUN |
Habilitado |
reserva_fracionária |
0% (definido por padrão) |
reserva instantânea |
0% |
Excluir automaticamente |
volume / mais antigo primeiro |
Dimensionamento automático |
Sobre |
tente_primeiro |
Crescimento automático |
Política de níveis de volume |
Apenas instantâneo |
Política de instantâneo |
Nenhum |
Com essa configuração, o tamanho total dos volumes pode ser maior que o armazenamento real disponível no sistema de arquivos. Se os LUNs ou cópias de instantâneo exigirem mais espaço do que o disponível no volume, os volumes crescerão automaticamente, ocupando mais espaço do sistema de arquivos que os contém. O crescimento automático permite que o FSx ONTAP aumente automaticamente o tamanho do volume até um tamanho máximo predeterminado por você. Deve haver espaço disponível no sistema de arquivos que o contém para suportar o crescimento automático do volume. Portanto, com o crescimento automático habilitado, você deve monitorar o espaço livre no sistema de arquivos e atualizar o sistema de arquivos quando necessário.
Junto com isso, defina o "alocação de espaço" opção no LUN habilitada para que o FSx ONTAP notifique o host EC2 quando o volume ficar sem espaço e o LUN no volume não puder aceitar gravações. Além disso, esta opção permite que o FSx ONTAP recupere espaço automaticamente quando o SQL Server no host EC2 exclui dados. A opção de alocação de espaço é definida como desabilitada por padrão.

|
Se um LUN com espaço reservado for criado em um volume não garantido, o LUN se comportará da mesma forma que um LUN sem espaço reservado. Isso ocorre porque um volume não garantido não tem espaço para alocar ao LUN; o volume em si só pode alocar espaço conforme foi gravado devido à falta de garantia. |
Com essa configuração, os administradores do FSx ONTAP geralmente podem dimensionar o volume para que eles precisem gerenciar e monitorar o espaço usado no LUN no lado do host e no sistema de arquivos.
|
|
A NetApp recomenda usar um sistema de arquivos separado para cargas de trabalho do servidor SQL. Se o sistema de arquivos for usado para vários aplicativos, monitore o uso de espaço do sistema de arquivos e dos volumes dentro do sistema de arquivos para garantir que os volumes não estejam competindo pelo espaço disponível. |
|
|
Cópias de instantâneo usadas para criar volumes FlexClone não são excluídas pela opção de exclusão automática. |
|
|
O excesso de comprometimento de armazenamento deve ser cuidadosamente considerado e gerenciado para um aplicativo de missão crítica, como o SQL Server, para o qual nem mesmo uma interrupção mínima pode ser tolerada. Nesse caso, é melhor monitorar as tendências de consumo de armazenamento para determinar quanto, se houver, excesso de comprometimento é aceitável. |
Melhores Práticas
-
Para um desempenho de armazenamento ideal, provisione a capacidade do sistema de arquivos para 1,35x o tamanho do uso total do banco de dados.
-
É necessário um monitoramento apropriado acompanhado de um plano de ação eficaz ao usar o provisionamento fino para evitar tempo de inatividade do aplicativo.
-
Certifique-se de definir alertas do Cloudwatch e de outras ferramentas de monitoramento para que as pessoas sejam contatadas com tempo suficiente para reagir quando o armazenamento estiver cheio.
Configurar o armazenamento para SQL Server e implantar o Snapcenter para operações de backup, restauração e clonagem
Para executar operações do servidor SQL com o SnapCenter, você deve primeiro criar volumes e LUNs para o servidor SQL.
Criar volumes e LUNs para o SQL Server
Para criar volumes e LUNs para o SQL Server, conclua as seguintes etapas:
-
Abra o console do Amazon FSx em https://console.aws.amazon.com/fsx/
-
Crie um Amazon FSx para o sistema de arquivos NetApp ONTAP usando a opção Criação padrão em Método de criação. Isso permite que você defina as credenciais FSxadmin e vsadmin.
-
Especifique a senha para fsxadmin.
-
Especifique a senha para SVMs.
-
Crie volumes seguindo as etapas listadas em "Criando um volume no FSx ONTAP" .
Melhores práticas
-
Desabilite agendamentos de cópias de instantâneos de armazenamento e políticas de retenção. Em vez disso, use o NetApp SnapCenter para coordenar cópias de instantâneo dos dados do SQL Server e volumes de log.
-
Configure bancos de dados em LUNs individuais em volumes separados para aproveitar a funcionalidade de restauração rápida e granular.
-
Coloque os arquivos de dados do usuário (.mdf) em volumes separados porque eles são cargas de trabalho aleatórias de leitura/gravação. É comum criar backups de log de transações com mais frequência do que backups de banco de dados. Por esse motivo, coloque os arquivos de log de transações (.ldf) em um volume separado dos arquivos de dados para que agendamentos de backup independentes possam ser criados para cada um. Essa separação também isola a E/S de gravação sequencial dos arquivos de log da E/S de leitura/gravação aleatória dos arquivos de dados e melhora significativamente o desempenho do SQL Server.
-
Tempdb é um banco de dados de sistema usado pelo Microsoft SQL Server como um espaço de trabalho temporário, especialmente para operações DBCC CHECKDB intensivas de E/S. Portanto, coloque esse banco de dados em um volume dedicado. Em ambientes grandes nos quais a contagem de volumes é um desafio, você pode consolidar o tempdb em menos volumes e armazená-lo no mesmo volume que outros bancos de dados do sistema após um planejamento cuidadoso. A proteção de dados do tempdb não é uma prioridade alta porque esse banco de dados é recriado toda vez que o Microsoft SQL Server é reiniciado.
-
-
Use o seguinte comando SSH para criar volumes:
vol create -vserver svm001 -volume vol_awssqlprod01_data -aggregate aggr1 -size 800GB -state online -tiering-policy snapshot-only -percent-snapshot-space 0 -autosize-mode grow -snapshot-policy none -security-style ntfs volume modify -vserver svm001 -volume vol_awssqlprod01_data -fractional-reserve 0 volume modify -vserver svm001 -volume vol_awssqlprod01_data -space-mgmt-try-first vol_grow volume snapshot autodelete modify -vserver svm001 -volume vol_awssqlprod01_data -delete-order oldest_first
-
Inicie o serviço iSCSI com o PowerShell usando privilégios elevados em servidores Windows.
Start-service -Name msiscsi Set-Service -Name msiscsi -StartupType Automatic
-
Instale o Multipath-IO com o PowerShell usando privilégios elevados em servidores Windows.
Install-WindowsFeature -name Multipath-IO -Restart
-
Encontre o nome do iniciador do Windows com o PowerShell usando privilégios elevados em servidores Windows.
Get-InitiatorPort | select NodeAddress

-
Conecte-se às máquinas virtuais de armazenamento (SVM) usando o putty e crie um iGroup.
igroup create -igroup igrp_ws2019sql1 -protocol iscsi -ostype windows -initiator iqn.1991-05.com.microsoft:ws2019-sql1.contoso.net
-
Use o seguinte comando SSH para criar LUNs:
lun create -path /vol/vol_awssqlprod01_data/lun_awssqlprod01_data -size 700GB -ostype windows_2008 -space-allocation enabled lun create -path /vol/vol_awssqlprod01_log/lun_awssqlprod01_log -size 100GB -ostype windows_2008 -space-allocation enabled
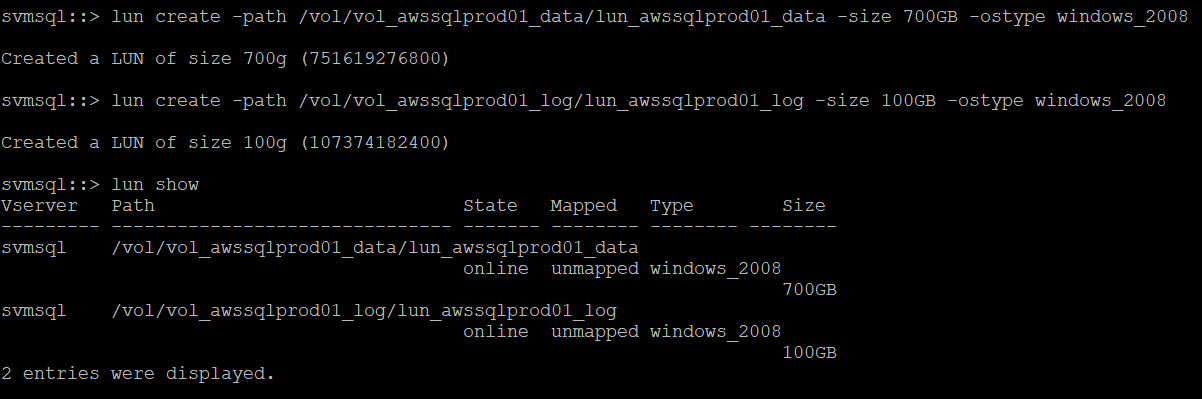
-
Para obter o alinhamento de E/S com o esquema de particionamento do sistema operacional, use windows_2008 como o tipo de LUN recomendado. Referir "aqui" para obter informações adicionais.
-
Use o seguinte comando SSH para mapear o igroup para os LUNs que você acabou de criar.
lun show lun map -path /vol/vol_awssqlprod01_data/lun_awssqlprod01_data -igroup igrp_awssqlprod01lun map -path /vol/vol_awssqlprod01_log/lun_awssqlprod01_log -igroup igrp_awssqlprod01
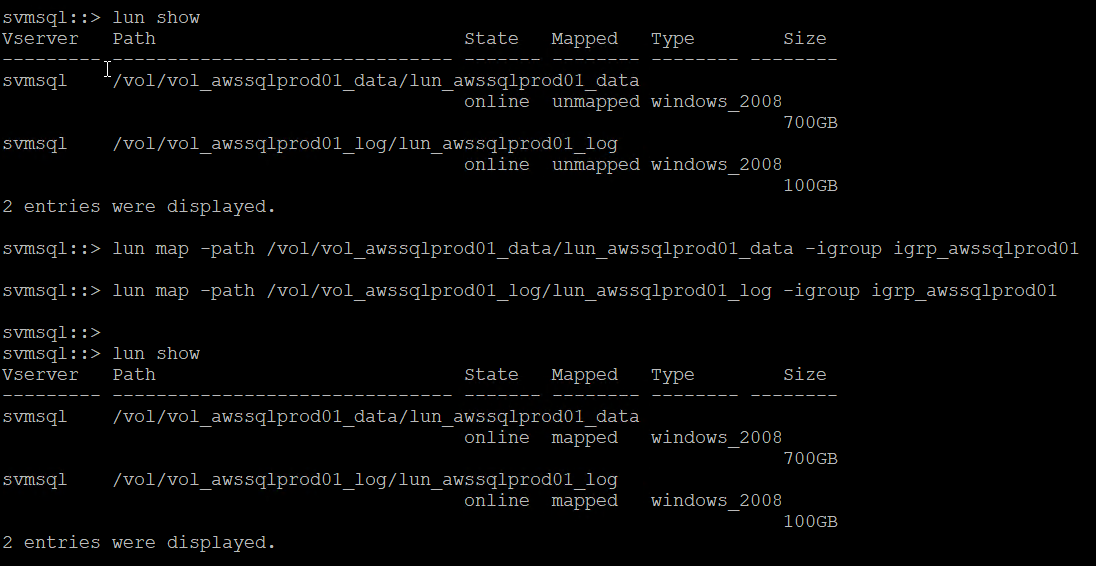
-
Para um disco compartilhado que usa o Cluster de Failover do Windows, execute um comando SSH para mapear o mesmo LUN para o igroup que pertence a todos os servidores que participam do Cluster de Failover do Windows.
-
Conecte o Windows Server a uma SVM com um destino iSCSI. Encontre o endereço IP de destino no Portal da AWS.
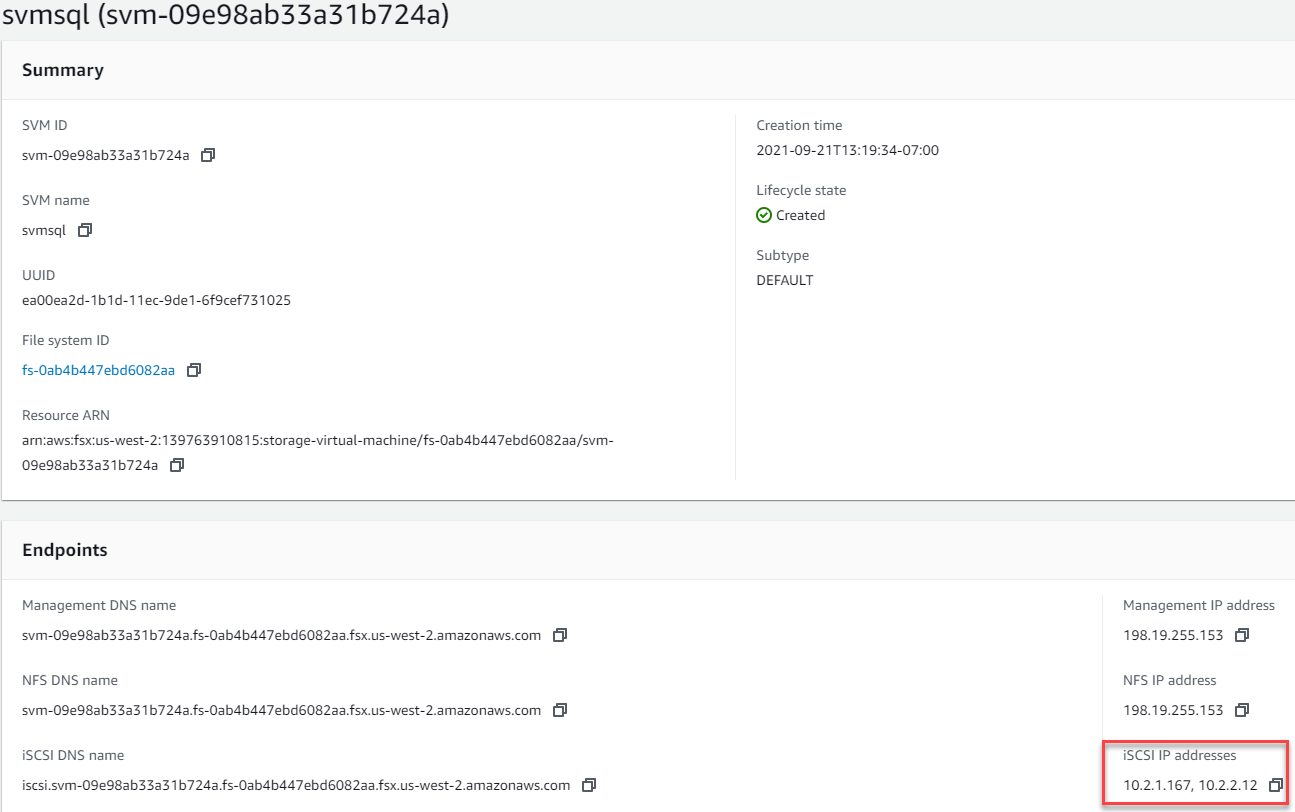
-
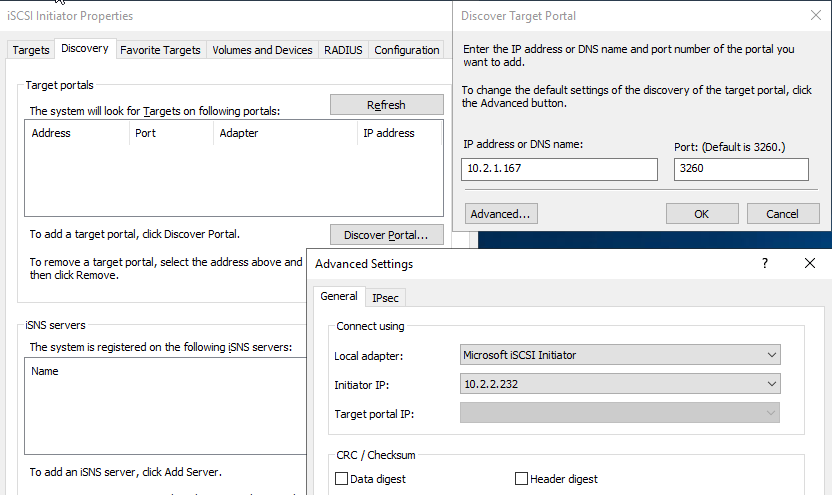
No Gerenciador do Servidor e no menu Ferramentas, selecione o Iniciador iSCSI. Selecione a aba Descoberta e depois selecione Portal de descoberta. Forneça o endereço IP iSCSI da etapa anterior e selecione Avançado. No Adaptador local, selecione Iniciador iSCSI da Microsoft. Em IP do iniciador, selecione o IP do servidor. Em seguida, selecione OK para fechar todas as janelas.
-
Repita a etapa 12 para o segundo IP iSCSI do SVM.
-
Selecione a aba Destinos, selecione Conectar e selecione Ativar multicaminho.
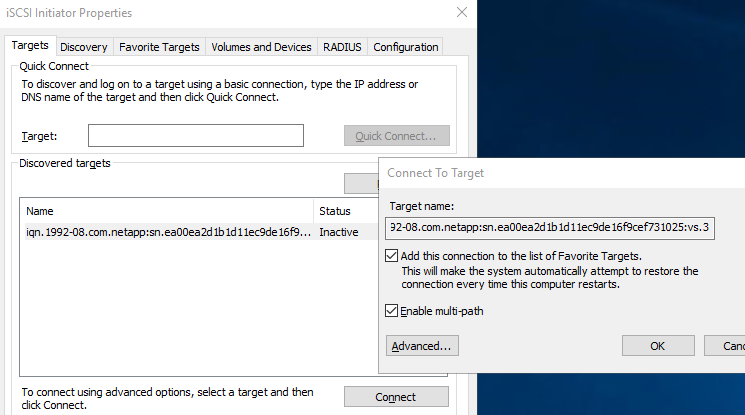
-
Para melhor desempenho, adicione mais sessões; a NetApp recomenda criar cinco sessões iSCSI. Selecione Propriedades> Adicionar sessão> Avançado e repita a etapa 12.
$TargetPortals = ('10.2.1.167', '10.2.2.12') foreach ($TargetPortal in $TargetPortals) {New-IscsiTargetPortal -TargetPortalAddress $TargetPortal}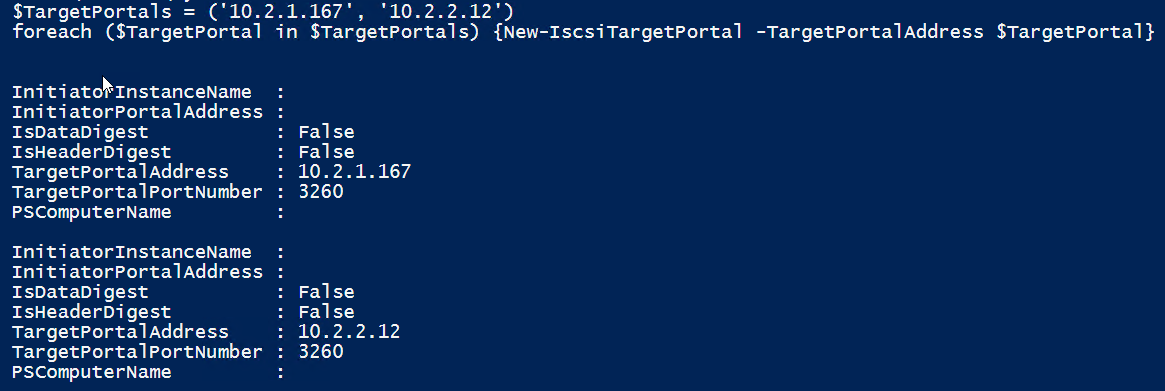
Melhores práticas
-
Configure cinco sessões iSCSI por interface de destino para obter desempenho ideal.
-
Configure uma política round-robin para obter o melhor desempenho geral do iSCSI.
-
Certifique-se de que o tamanho da unidade de alocação esteja definido como 64K para partições ao formatar os LUNs
-
Execute o seguinte comando do PowerShell para garantir que a sessão iSCSI seja persistida.
$targets = Get-IscsiTarget foreach ($target in $targets) { Connect-IscsiTarget -IsMultipathEnabled $true -NodeAddress $target.NodeAddress -IsPersistent $true }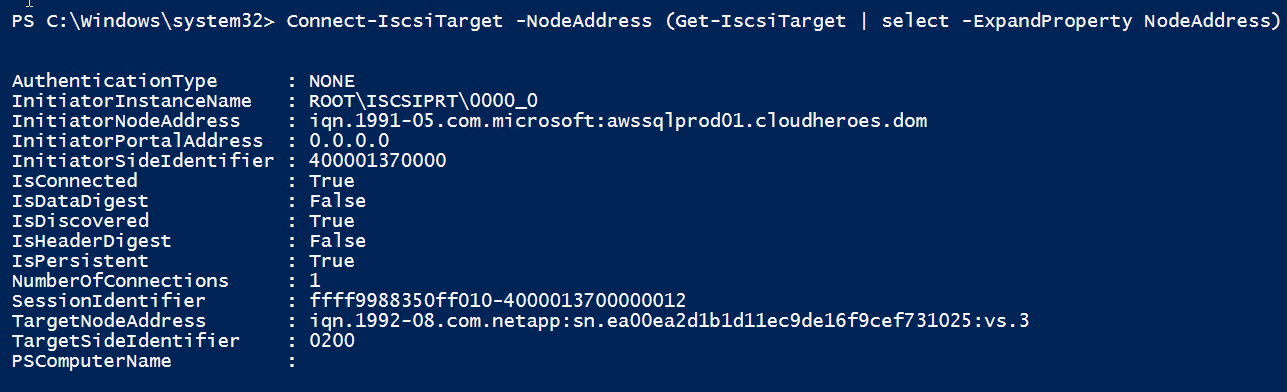
-
Inicialize os discos com o seguinte comando do PowerShell.
$disks = Get-Disk | where PartitionStyle -eq raw foreach ($disk in $disks) {Initialize-Disk $disk.Number}
-
Execute os comandos Criar partição e Formatar disco com o PowerShell.
New-Partition -DiskNumber 1 -DriveLetter F -UseMaximumSize Format-Volume -DriveLetter F -FileSystem NTFS -AllocationUnitSize 65536 New-Partition -DiskNumber 2 -DriveLetter G -UseMaximumSize Format-Volume -DriveLetter G -FileSystem NTFS -AllocationUnitSize 65536
-
Você pode automatizar a criação de volumes e LUNs usando o script do PowerShell do Apêndice B. Os LUNs também podem ser criados usando o SnapCenter.
Depois que os volumes e LUNs estiverem definidos, você precisará configurar o SnapCenter para poder executar as operações do banco de dados.
Visão geral do SnapCenter
O NetApp SnapCenter é um software de proteção de dados de última geração para aplicativos empresariais de nível 1. O SnapCenter, com sua interface de gerenciamento de painel único, automatiza e simplifica os processos manuais, complexos e demorados associados ao backup, recuperação e clonagem de vários bancos de dados e outras cargas de trabalho de aplicativos. O SnapCenter aproveita as tecnologias da NetApp , incluindo NetApp Snapshots, NetApp SnapMirror, SnapRestore e NetApp FlexClone. Essa integração permite que as organizações de TI escalem sua infraestrutura de armazenamento, cumpram compromissos de SLA cada vez mais rigorosos e melhorem a produtividade dos administradores em toda a empresa.
Requisitos do SnapCenter Server
A tabela a seguir lista os requisitos mínimos para instalar o SnapCenter Server e o plug-in no Microsoft Windows Server.
| Componentes | Exigência |
|---|---|
Contagem mínima de CPU |
Quatro núcleos/vCPUs |
Memória |
Mínimo: 8 GB Recomendado: 32 GB |
Espaço de armazenamento |
Espaço mínimo para instalação: 10 GB Espaço mínimo para repositório: 10 GB |
Sistema operacional suportado |
|
Pacotes de software |
|
Para obter informações detalhadas, consulte"requisitos de espaço e dimensionamento" .
Para compatibilidade de versões, consulte o "Ferramenta de Matriz de Interoperabilidade da NetApp" .
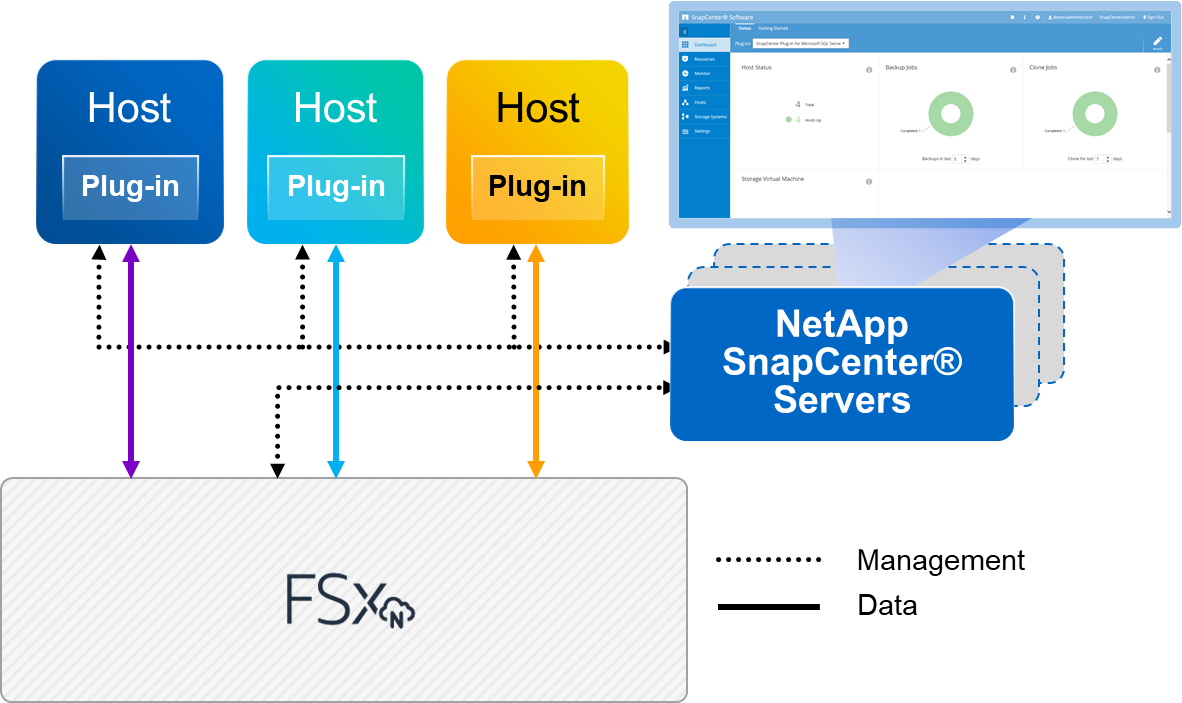
Layout de armazenamento de banco de dados
A figura a seguir descreve algumas considerações para criar o layout de armazenamento do banco de dados do Microsoft SQL Server ao fazer backup com o SnapCenter.
Melhores práticas
-
Coloque bancos de dados com consultas intensivas de E/S ou com tamanho de banco de dados grande (digamos 500 GB ou mais) em um volume separado para recuperação mais rápida. Este volume também deve ser apoiado por trabalhos separados.
-
Consolide bancos de dados de pequeno a médio porte que sejam menos críticos ou tenham menos requisitos de E/S em um único volume. Fazer backup de um grande número de bancos de dados que residem no mesmo volume resulta em menos cópias de Snapshot que precisam ser mantidas. Também é uma prática recomendada consolidar instâncias do Microsoft SQL Server para usar os mesmos volumes para controlar o número de cópias de instantâneo de backup feitas.
-
Crie LUNs separados para armazenar arquivos relacionados a texto completo e arquivos relacionados a streaming de arquivos.
-
Atribua LUNs separados por host para armazenar backups de log do Microsoft SQL Server.
-
Os bancos de dados do sistema que armazenam metadados do servidor de banco de dados, configuração e detalhes do trabalho não são atualizados com frequência. Coloque os bancos de dados do sistema/tempdb em unidades ou LUNs separados. Não coloque bancos de dados do sistema no mesmo volume que os bancos de dados do usuário. Os bancos de dados do usuário têm uma política de backup diferente, e a frequência de backup do banco de dados do usuário não é a mesma para os bancos de dados do sistema.
-
Para a configuração do Grupo de Disponibilidade do Microsoft SQL Server, coloque os dados e arquivos de log das réplicas em uma estrutura de pastas idêntica em todos os nós.
Além do benefício de desempenho da segregação do layout do banco de dados do usuário em volumes diferentes, o banco de dados também afeta significativamente o tempo necessário para fazer backup e restauração. Ter volumes separados para dados e arquivos de log melhora significativamente o tempo de restauração em comparação a um volume que hospeda vários arquivos de dados do usuário. Da mesma forma, bancos de dados de usuários com aplicativos com alto uso intensivo de E/S estão propensos a um aumento no tempo de backup. Uma explicação mais detalhada sobre práticas de backup e restauração é fornecida mais adiante neste documento.
|
|
A partir do SQL Server 2012 (11.x), os bancos de dados do sistema (Master, Model, MSDB e TempDB) e os bancos de dados de usuário do Mecanismo de Banco de Dados podem ser instalados com um servidor de arquivos SMB como uma opção de armazenamento. Isso se aplica tanto a instalações autônomas do SQL Server quanto a instalações de cluster de failover do SQL Server. Isso permite que você use o FSx ONTAP com todos os seus recursos de desempenho e gerenciamento de dados, incluindo capacidade de volume, escalabilidade de desempenho e recursos de proteção de dados, dos quais o SQL Server pode aproveitar. Os compartilhamentos usados pelos servidores de aplicativos devem ser configurados com a propriedade continuamente disponível definida e o volume deve ser criado com o estilo de segurança NTFS. O NetApp Snapcenter não pode ser usado com bancos de dados colocados em compartilhamentos SMB do FSx ONTAP. |
|
|
Para bancos de dados do SQL Server que não usam o SnapCenter para executar backups, a Microsoft recomenda colocar os dados e arquivos de log em unidades separadas. Para aplicativos que atualizam e solicitam dados simultaneamente, o arquivo de log exige muita gravação, e o arquivo de dados (dependendo do seu aplicativo) exige muita leitura/gravação. Para recuperação de dados, o arquivo de log não é necessário. Portanto, as solicitações de dados podem ser atendidas a partir do arquivo de dados colocado em sua própria unidade. |
|
|
Ao criar um novo banco de dados, a Microsoft recomenda especificar unidades separadas para os dados e logs. Para mover arquivos após a criação do banco de dados, o banco de dados deve ser colocado offline. Para obter mais recomendações da Microsoft, consulte Colocar dados e arquivos de log em unidades separadas. |
Instalação e configuração do SnapCenter
Siga o "Instalar o SnapCenter Server" e "Instalando o plug-in SnapCenter para Microsoft SQL Server" para instalar e configurar o SnapCenter.
Após instalar o SnapCenter, conclua as etapas a seguir para configurá-lo.
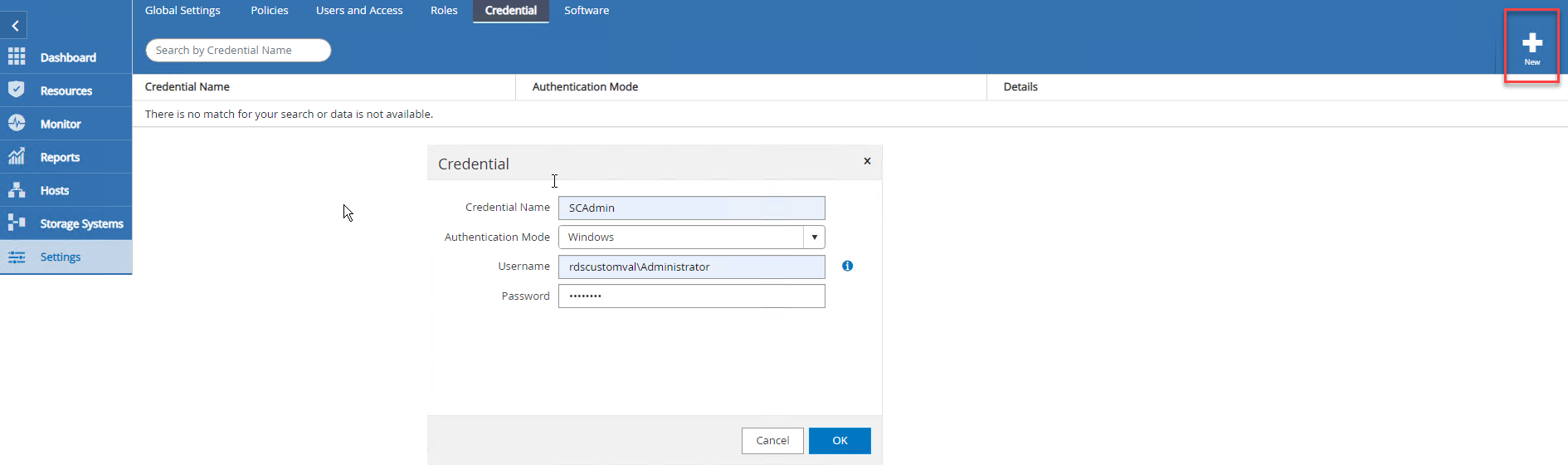
-
Para configurar credenciais, selecione Configurações > Novo e insira as informações de credencial.
-
Adicione o sistema de armazenamento selecionando Sistemas de armazenamento > Novo e forneça as informações de armazenamento apropriadas do FSx ONTAP .
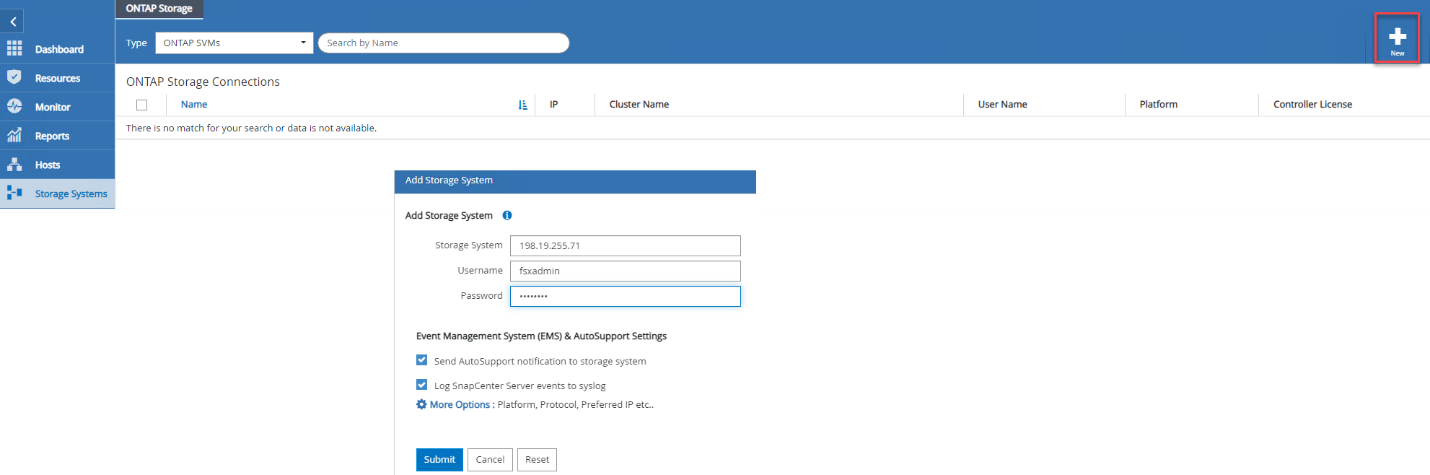
-
Adicione hosts selecionando Hosts > Adicionar e, em seguida, forneça as informações do host. O SnapCenter instala automaticamente o plug-in do Windows e do SQL Server. Esse processo pode levar algum tempo.
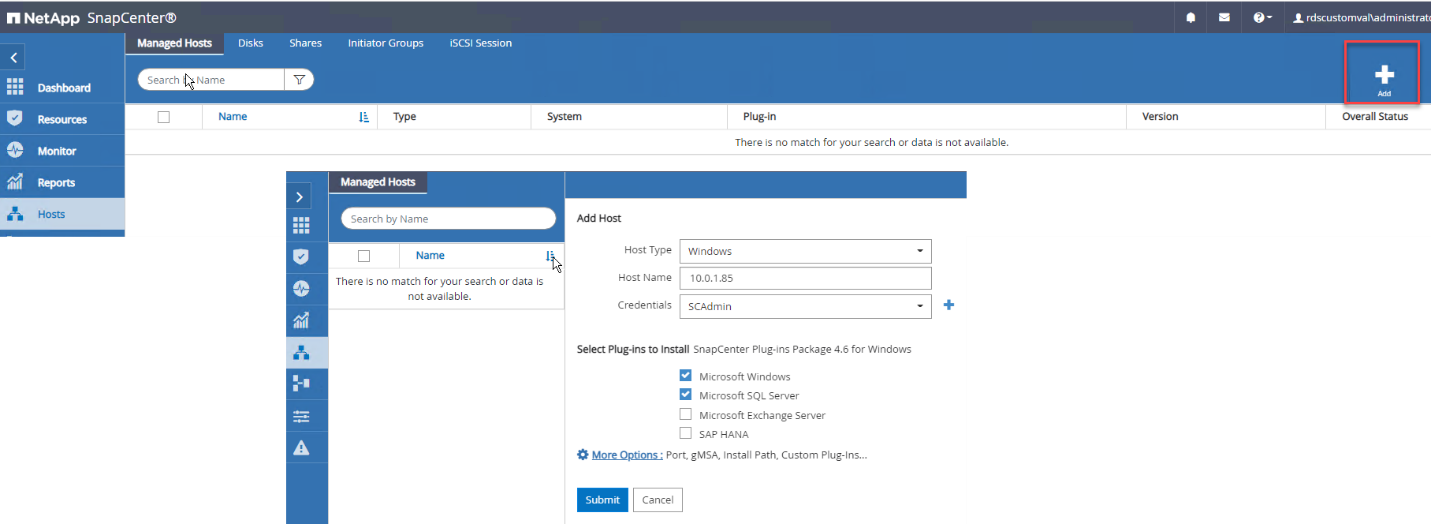
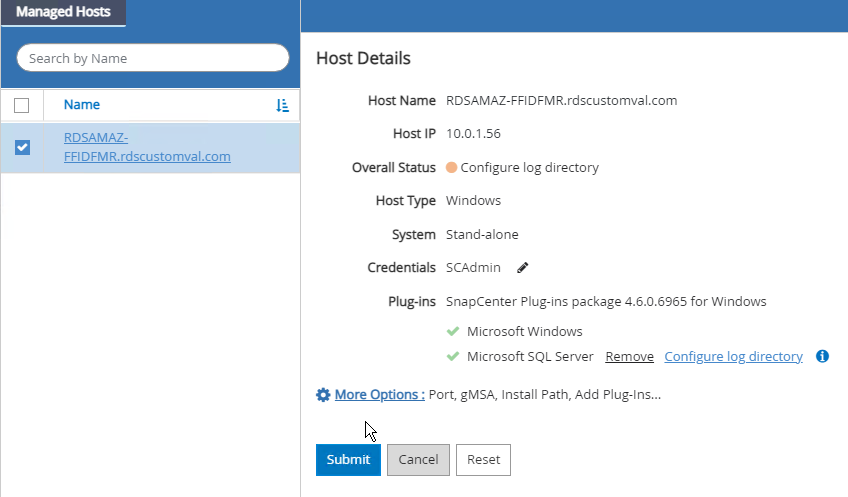
Depois que todos os plug-ins estiverem instalados, você deve configurar o diretório de log. Este é o local onde reside o backup do log de transações. Você pode configurar o diretório de log selecionando o host e depois selecionando configurar o diretório de log.
|
|
O SnapCenter usa um diretório de log do host para armazenar dados de backup do log de transações. Isso ocorre no nível do host e da instância. Cada host do SQL Server usado pelo SnapCenter deve ter um diretório de log do host configurado para executar backups de log. O SnapCenter tem um repositório de banco de dados, portanto, metadados relacionados a operações de backup, restauração ou clonagem são armazenados em um repositório de banco de dados central. |
O tamanho do diretório de log do host é calculado da seguinte maneira:
Tamanho do diretório de log do host = tamanho do banco de dados do sistema + (tamanho máximo do LDF do BD × taxa de alteração diária do log % × (retenção de cópia do instantâneo) ÷ (1 – espaço de sobrecarga do LUN %)
A fórmula de dimensionamento do diretório de log do host pressupõe o seguinte:
-
Um backup do banco de dados do sistema que não inclui o banco de dados tempdb
-
Um espaço de sobrecarga de LUN de 10%Coloque o diretório de log do host em um volume ou LUN dedicado. A quantidade de dados no diretório de log do host depende do tamanho dos backups e do número de dias em que os backups são retidos.
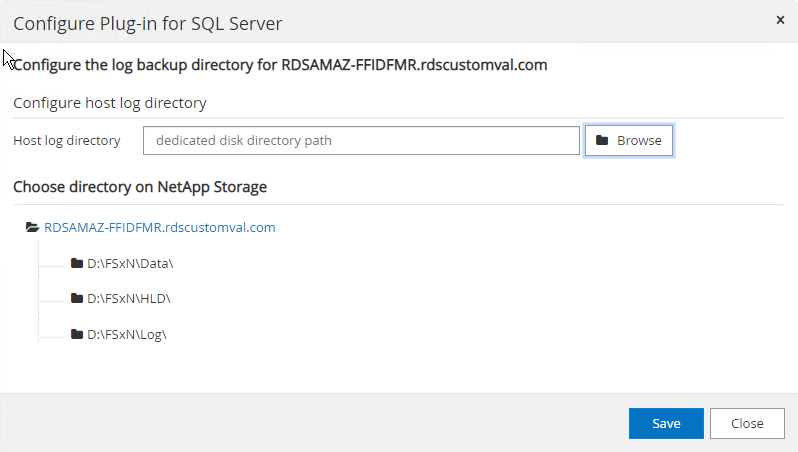
Se os LUNs já tiverem sido provisionados, você poderá selecionar o ponto de montagem para representar o diretório de log do host.
Agora você está pronto para executar operações de backup, restauração e clonagem do SQL Server.
Backup de banco de dados com SnapCenter
Depois de colocar o banco de dados e os arquivos de log nos LUNs do FSx ONTAP , o SnapCenter pode ser usado para fazer backup dos bancos de dados. Os seguintes processos são usados para criar um backup completo.
Melhores Práticas
-
Em termos do SnapCenter , o RPO pode ser identificado como a frequência de backup, por exemplo, a frequência com que você deseja agendar o backup para reduzir a perda de dados para até alguns minutos. O SnapCenter permite que você agende backups com uma frequência de até cinco minutos. No entanto, pode haver algumas instâncias em que um backup pode não ser concluído em cinco minutos durante horários de pico de transação ou quando a taxa de alteração de dados for maior no tempo determinado. Uma prática recomendada é agendar backups frequentes do log de transações em vez de backups completos.
-
Existem inúmeras abordagens para lidar com o RPO e o RTO. Uma alternativa a essa abordagem de backup é ter políticas de backup separadas para dados e logs com intervalos diferentes. Por exemplo, no SnapCenter, agende backups de log em intervalos de 15 minutos e backups de dados em intervalos de 6 horas.
-
Use um grupo de recursos para uma configuração de backup para otimização de instantâneo e o número de trabalhos a serem gerenciados.
-
Selecione Recursos e, em seguida, selecione Microsoft SQL Server *no menu suspenso no canto superior esquerdo. Selecione *Atualizar recursos.
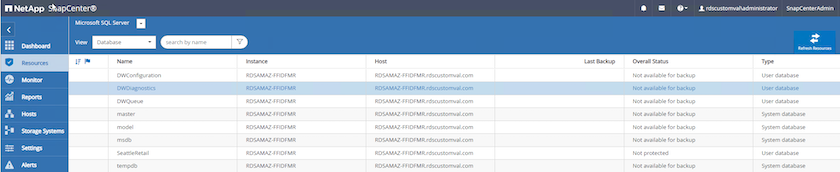
-
Selecione o banco de dados a ser copiado, depois selecione Avançar e (*) para adicionar a política, caso uma ainda não tenha sido criada. Siga a *Nova política de backup do SQL Server para criar uma nova política.
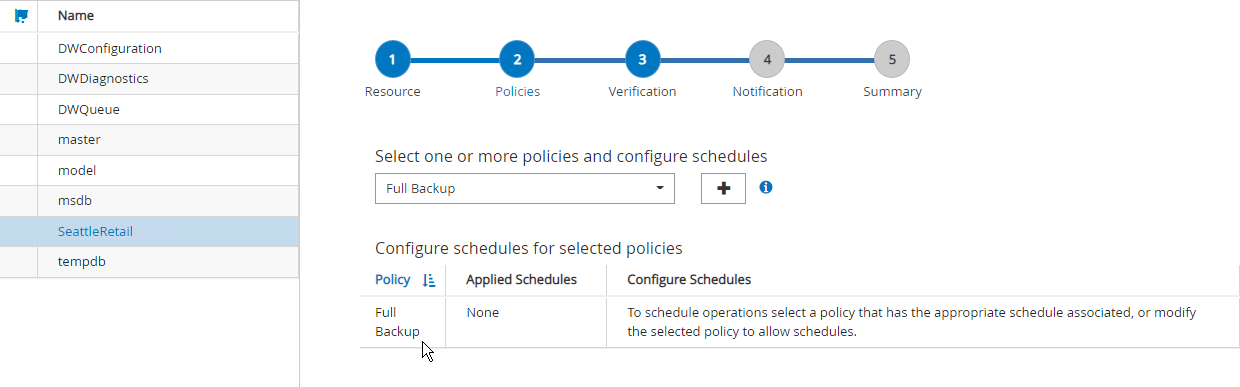
-
Selecione o servidor de verificação, se necessário. Este é o servidor no qual o SnapCenter executa o DBCC CHECKDB após um backup completo ter sido criado. Clique em Avançar para receber a notificação e depois selecione Resumo para revisar. Após a revisão, clique em Concluir.
-
Clique em Fazer backup agora para testar o backup. Nas janelas pop-up, selecione Backup.
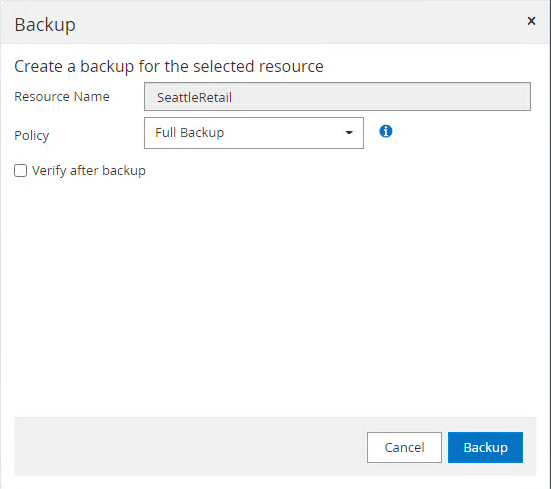
-
Selecione Monitor para verificar se o backup foi concluído.

-
Melhores Práticas
-
Faça backup do log de transações do SnapCenter para que, durante o processo de restauração, o SnapCenter possa ler todos os arquivos de backup e restaurar em sequência automaticamente.
-
Se produtos de terceiros forem usados para backup, selecione Copiar backup no SnapCenter para evitar problemas de sequência de log e teste a funcionalidade de restauração antes de colocar em produção.
Restaurar banco de dados com SnapCenter
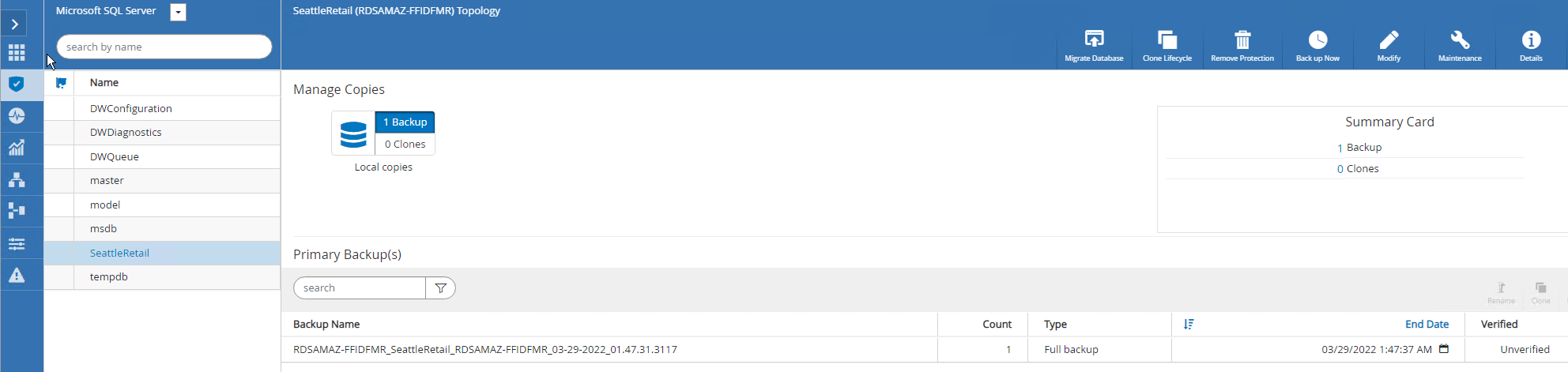
Um dos principais benefícios de usar o FSx ONTAP com o SQL Server no EC2 é sua capacidade de executar restaurações rápidas e granulares em cada nível do banco de dados.
Conclua as etapas a seguir para restaurar um banco de dados individual para um ponto específico no tempo ou atualizado com o SnapCenter.
-
Selecione Recursos e depois selecione o banco de dados que você gostaria de restaurar.
-
Selecione o nome do backup do qual o banco de dados precisa ser restaurado e então selecione restaurar.
-
Siga as janelas pop-up Restaurar para restaurar o banco de dados.
-
Selecione Monitor para verificar se o processo de restauração foi bem-sucedido.
Considerações para uma instância com um grande número de bancos de dados de pequeno a grande porte
O SnapCenter pode fazer backup de um grande número de bancos de dados consideráveis em uma instância ou grupo de instâncias dentro de um grupo de recursos. O tamanho de um banco de dados não é o principal fator no tempo de backup. A duração de um backup pode variar dependendo do número de LUNs por volume, da carga no Microsoft SQL Server, do número total de bancos de dados por instância e, especificamente, da largura de banda e do uso de E/S. Ao configurar a política para fazer backup de bancos de dados de uma instância ou grupo de recursos, a NetApp recomenda que você restrinja o máximo de bancos de dados submetidos a backup por cópia de Snapshot para 100 por host. Certifique-se de que o número total de cópias do Snapshot não exceda o limite de 1.023 cópias.
A NetApp também recomenda que você limite os trabalhos de backup executados em paralelo agrupando o número de bancos de dados em vez de criar vários trabalhos para cada banco de dados ou instância. Para obter o desempenho ideal da duração do backup, reduza o número de tarefas de backup para um número que possa fazer backup de cerca de 100 bancos de dados ou menos por vez.
Como mencionado anteriormente, o uso de E/S é um fator importante no processo de backup. O processo de backup deve aguardar até que todas as operações de E/S em um banco de dados sejam concluídas. Bancos de dados com operações de E/S altamente intensivas devem ser adiados para outro momento de backup ou devem ser isolados de outras tarefas de backup para evitar afetar outros recursos dentro do mesmo grupo de recursos que devem ser copiados.
Para um ambiente com seis hosts do Microsoft SQL Server hospedando 200 bancos de dados por instância, supondo quatro LUNs por host e um LUN por volume criado, defina a política de backup completo com o máximo de bancos de dados copiados por cópia de Snapshot como 100. Duzentos bancos de dados em cada instância são dispostos como 200 arquivos de dados distribuídos igualmente em dois LUNs, e 200 arquivos de log são distribuídos igualmente em dois LUNs, o que equivale a 100 arquivos por LUN por volume.
Agende três tarefas de backup criando três grupos de recursos, cada um agrupando duas instâncias que incluem um total de 400 bancos de dados.
Executar todas as três tarefas de backup em paralelo faz backup de 1.200 bancos de dados simultaneamente. Dependendo da carga no servidor e do uso de E/S, o horário de início e término em cada instância pode variar. Neste caso, um total de 24 cópias de Snapshot são criadas.
Além do backup completo, a NetApp recomenda que você configure um backup de log de transações para bancos de dados críticos. Certifique-se de que a propriedade do banco de dados esteja definida como modelo de recuperação completa.
Melhores práticas
-
Não inclua o banco de dados tempdb em um backup porque os dados que ele contém são temporários. Coloque tempdb em um LUN ou em um compartilhamento SMB que esteja em um volume do sistema de armazenamento no qual cópias de instantâneo não serão criadas.
-
Uma instância do Microsoft SQL Server com um aplicativo com alto uso de E/S deve ser isolada em uma tarefa de backup diferente para reduzir o tempo geral de backup de outros recursos.
-
Limite o conjunto de bancos de dados a serem copiados simultaneamente a aproximadamente 100 e escalone o conjunto restante de backups de banco de dados para evitar um processo simultâneo.
-
Use o nome da instância do Microsoft SQL Server no grupo de recursos em vez de vários bancos de dados porque sempre que novos bancos de dados são criados na instância do Microsoft SQL Server, o SnapCenter considera automaticamente um novo banco de dados para backup.
-
Se você alterar a configuração do banco de dados, como alterar o modelo de recuperação do banco de dados para o modelo de recuperação completo, execute um backup imediatamente para permitir operações de restauração atualizadas.
-
O SnapCenter não pode restaurar backups de log de transações criados fora do SnapCenter.
-
Ao clonar volumes FlexVol , certifique-se de ter espaço suficiente para os metadados do clone.
-
Ao restaurar bancos de dados, certifique-se de que haja espaço suficiente disponível no volume.
-
Crie uma política separada para gerenciar e fazer backup dos bancos de dados do sistema pelo menos uma vez por semana.
Clonando bancos de dados com SnapCenter
Para restaurar um banco de dados em outro local em um ambiente de desenvolvimento ou teste ou para criar uma cópia para fins de análise de negócios, a prática recomendada da NetApp é aproveitar a metodologia de clonagem para criar uma cópia do banco de dados na mesma instância ou em uma instância alternativa.
A clonagem de bancos de dados de 500 GB em um disco iSCSI hospedado em um ambiente FSx ONTAP normalmente leva menos de cinco minutos. Após a conclusão da clonagem, o usuário pode executar todas as operações de leitura/gravação necessárias no banco de dados clonado. A maior parte do tempo é consumida na varredura de disco (diskpart). O procedimento de clonagem do NetApp normalmente leva menos de 2 minutos, independentemente do tamanho dos bancos de dados.
A clonagem de um banco de dados pode ser realizada com o método duplo: você pode criar um clone a partir do backup mais recente ou pode usar o gerenciamento do ciclo de vida do clone, por meio do qual a cópia mais recente pode ser disponibilizada na instância secundária.
O SnapCenter permite que você monte a cópia clone no disco necessário para manter o formato da estrutura de pastas na instância secundária e continuar a agendar trabalhos de backup.
Clonar bancos de dados para o novo nome do banco de dados na mesma instância
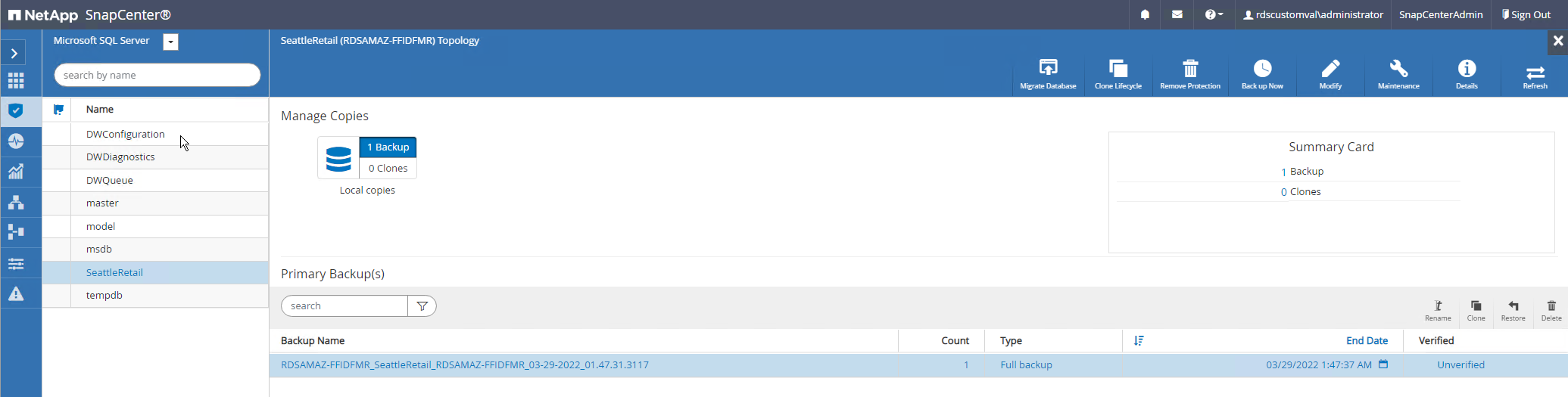
As etapas a seguir podem ser usadas para clonar bancos de dados para o novo nome de banco de dados na mesma instância do servidor SQL em execução no EC2:
-
Selecione Recursos e depois o banco de dados que precisa ser clonado.
-
Selecione o nome do backup que você gostaria de clonar e selecione Clonar.
-
Siga as instruções de clonagem das janelas de backup para concluir o processo de clonagem.
-
Selecione Monitorar para garantir que a clonagem seja concluída.
Clonar bancos de dados na nova instância do SQL Server em execução no EC2
As etapas a seguir são usadas para clonar bancos de dados para a nova instância do servidor SQL em execução no EC2:
-
Crie um novo SQL Server no EC2 na mesma VPC.
-
Habilite o protocolo iSCSI e o MPIO e, em seguida, configure a conexão iSCSI com o FSx ONTAP seguindo as etapas 3 e 4 na seção "Criar volumes e LUNs para o SQL Server".
-
Adicione um novo SQL Server no EC2 no SnapCenter seguindo a etapa 3 na seção "Instalação e configuração do SnapCenter".
-
Selecione Recurso > Exibir instância e, em seguida, selecione Atualizar recurso.
-
Selecione Recursos e, em seguida, o banco de dados que você gostaria de clonar.
-
Selecione o nome do backup que você gostaria de clonar e, em seguida, selecione Clonar.
-
Siga as instruções de Clone do Backup fornecendo a nova instância do SQL Server no EC2 e o nome da instância para concluir o processo de clonagem.
-
Selecione Monitorar para garantir que a clonagem seja concluída.

Para saber mais sobre esse processo, assista ao vídeo a seguir:
Apêndices
Apêndice A: Arquivo YAML para uso no modelo de formação de nuvens
O seguinte arquivo .yaml pode ser usado com o Cloud Formation Template no AWS Console.
Para automatizar a criação do ISCSI LUN e a instalação do NetApp SnapCenter com o PowerShell, clone o repositório de "este link do GitHub" .
Apêndice B: Scripts do Powershell para provisionamento de volumes e LUNs
O script a seguir é usado para provisionar volumes e LUNs e também para configurar o iSCSI com base nas instruções fornecidas acima. Existem dois scripts do PowerShell:
-
_EnableMPIO.ps1
Function Install_MPIO_ssh {
$hostname = $env:COMPUTERNAME
$hostname = $hostname.Replace('-','_')
#Add schedule action for the next step
$path = Get-Location
$path = $path.Path + '\2_CreateDisks.ps1'
$arg = '-NoProfile -WindowStyle Hidden -File ' +$path
$schAction = New-ScheduledTaskAction -Execute "Powershell.exe" -Argument $arg
$schTrigger = New-ScheduledTaskTrigger -AtStartup
$schPrincipal = New-ScheduledTaskPrincipal -UserId "NT AUTHORITY\SYSTEM" -LogonType ServiceAccount -RunLevel Highest
$return = Register-ScheduledTask -Action $schAction -Trigger $schTrigger -TaskName "Create Vols and LUNs" -Description "Scheduled Task to run configuration Script At Startup" -Principal $schPrincipal
#Install -Module Posh-SSH
Write-host 'Enable MPIO and SSH for PowerShell' -ForegroundColor Yellow
$return = Find-PackageProvider -Name 'Nuget' -ForceBootstrap -IncludeDependencies
$return = Find-Module PoSH-SSH | Install-Module -Force
#Install Multipath-IO with PowerShell using elevated privileges in Windows Servers
Write-host 'Enable MPIO' -ForegroundColor Yellow
$return = Install-WindowsFeature -name Multipath-IO -Restart
}
Install_MPIO_ssh
Remove-Item -Path $MyInvocation.MyCommand.Source-
_CreateDisks.ps1
....
#Enable MPIO and Start iSCSI Service
Function PrepISCSI {
$return = Enable-MSDSMAutomaticClaim -BusType iSCSI
#Start iSCSI service with PowerShell using elevated privileges in Windows Servers
$return = Start-service -Name msiscsi
$return = Set-Service -Name msiscsi -StartupType Automatic
}
Function Create_igroup_vols_luns ($fsxN){
$hostname = $env:COMPUTERNAME
$hostname = $hostname.Replace('-','_')
$volsluns = @()
for ($i = 1;$i -lt 10;$i++){
if ($i -eq 9){
$volsluns +=(@{volname=('v_'+$hostname+'_log');volsize=$fsxN.logvolsize;lunname=('l_'+$hostname+'_log');lunsize=$fsxN.loglunsize})
} else {
$volsluns +=(@{volname=('v_'+$hostname+'_data'+[string]$i);volsize=$fsxN.datavolsize;lunname=('l_'+$hostname+'_data'+[string]$i);lunsize=$fsxN.datalunsize})
}
}
$secStringPassword = ConvertTo-SecureString $fsxN.password -AsPlainText -Force
$credObject = New-Object System.Management.Automation.PSCredential ($fsxN.login, $secStringPassword)
$igroup = 'igrp_'+$hostname
#Connect to FSx N filesystem
$session = New-SSHSession -ComputerName $fsxN.svmip -Credential $credObject -AcceptKey:$true
#Create igroup
Write-host 'Creating igroup' -ForegroundColor Yellow
#Find Windows initiator Name with PowerShell using elevated privileges in Windows Servers
$initport = Get-InitiatorPort | select -ExpandProperty NodeAddress
$sshcmd = 'igroup create -igroup ' + $igroup + ' -protocol iscsi -ostype windows -initiator ' + $initport
$ret = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
#Create vols
Write-host 'Creating Volumes' -ForegroundColor Yellow
foreach ($vollun in $volsluns){
$sshcmd = 'vol create ' + $vollun.volname + ' -aggregate aggr1 -size ' + $vollun.volsize #+ ' -vserver ' + $vserver
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
}
#Create LUNs and mapped LUN to igroup
Write-host 'Creating LUNs and map to igroup' -ForegroundColor Yellow
foreach ($vollun in $volsluns){
$sshcmd = "lun create -path /vol/" + $vollun.volname + "/" + $vollun.lunname + " -size " + $vollun.lunsize + " -ostype Windows_2008 " #-vserver " +$vserver
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
#map all luns to igroup
$sshcmd = "lun map -path /vol/" + $vollun.volname + "/" + $vollun.lunname + " -igroup " + $igroup
$return = Invoke-SSHCommand -Command $sshcmd -SSHSession $session
}
}
Function Connect_iSCSI_to_SVM ($TargetPortals){
Write-host 'Online, Initialize and format disks' -ForegroundColor Yellow
#Connect Windows Server to svm with iSCSI target.
foreach ($TargetPortal in $TargetPortals) {
New-IscsiTargetPortal -TargetPortalAddress $TargetPortal
for ($i = 1; $i -lt 5; $i++){
$return = Connect-IscsiTarget -IsMultipathEnabled $true -IsPersistent $true -NodeAddress (Get-iscsiTarget | select -ExpandProperty NodeAddress)
}
}
}
Function Create_Partition_Format_Disks{
#Create Partion and format disk
$disks = Get-Disk | where PartitionStyle -eq raw
foreach ($disk in $disks) {
$return = Initialize-Disk $disk.Number
$partition = New-Partition -DiskNumber $disk.Number -AssignDriveLetter -UseMaximumSize | Format-Volume -FileSystem NTFS -AllocationUnitSize 65536 -Confirm:$false -Force
#$return = Format-Volume -DriveLetter $partition.DriveLetter -FileSystem NTFS -AllocationUnitSize 65536
}
}
Function UnregisterTask {
Unregister-ScheduledTask -TaskName "Create Vols and LUNs" -Confirm:$false
}
Start-Sleep -s 30
$fsxN = @{svmip ='198.19.255.153';login = 'vsadmin';password='net@pp11';datavolsize='10GB';datalunsize='8GB';logvolsize='8GB';loglunsize='6GB'}
$TargetPortals = ('10.2.1.167', '10.2.2.12')
PrepISCSI
Create_igroup_vols_luns $fsxN
Connect_iSCSI_to_SVM $TargetPortals
Create_Partition_Format_Disks
UnregisterTask
Remove-Item -Path $MyInvocation.MyCommand.Source
....
Execute o arquivo EnableMPIO.ps1 o primeiro e o segundo script são executados automaticamente após a reinicialização do servidor. Esses scripts do PowerShell podem ser removidos após serem executados devido ao acesso de credencial ao SVM.
Onde encontrar informações adicionais
-
Amazon FSx ONTAP
-
Introdução ao FSx ONTAP
-
Visão geral da interface do SnapCenter
-
Passeio pelas opções do painel de navegação do SnapCenter
-
Configurar o SnapCenter 4.0 para o plug-in SQL Server
-
Como fazer backup e restaurar bancos de dados usando o SnapCenter com o plug-in do SQL Server
-
Como clonar um banco de dados usando o SnapCenter com o plug-in do SQL Server