

Gerenciamento de banco de dados Oracle EC2 e FSx
 Sugerir alterações
Sugerir alterações
Além do console de gerenciamento AWS EC2 e FSx, o nó de controle Ansible e a ferramenta SnapCenter UI são implantados para gerenciamento de banco de dados neste ambiente Oracle.
Um nó de controle do Ansible pode ser usado para gerenciar a configuração do ambiente Oracle, com atualizações paralelas que mantêm as instâncias primária e de espera sincronizadas para atualizações de kernel ou patch. Failover, ressincronização e failback podem ser automatizados com o NetApp Automation Toolkit para arquivar recuperação rápida de aplicativos e disponibilidade com o Ansible. Algumas tarefas repetíveis de gerenciamento de banco de dados podem ser executadas usando um manual para reduzir erros humanos.
A ferramenta SnapCenter UI pode executar backup de instantâneos de banco de dados, recuperação de ponto no tempo, clonagem de banco de dados e assim por diante com o plug-in SnapCenter para bancos de dados Oracle. Para obter mais informações sobre os recursos do plug-in Oracle, consulte o"Visão geral do plug-in SnapCenter para banco de dados Oracle" .
As seções a seguir fornecem detalhes sobre como as principais funções do gerenciamento de banco de dados Oracle são cumpridas com a interface do usuário do SnapCenter :
-
Backups de instantâneos de banco de dados
-
Restauração de ponto no tempo do banco de dados
-
Criação de clone de banco de dados
A clonagem de banco de dados cria uma réplica de um banco de dados primário em um host EC2 separado para recuperação de dados em caso de erro lógico ou corrupção de dados, e os clones também podem ser usados para testes de aplicativos, depuração, validação de patches e assim por diante.
Tirando uma foto instantânea
Um banco de dados Oracle EC2/FSx é submetido a backup regularmente em intervalos configurados pelo usuário. Um usuário também pode fazer um backup instantâneo único a qualquer momento. Isso se aplica tanto a backups de snapshots de banco de dados completo quanto a backups de snapshots somente de log de arquivamento.
Tirando um instantâneo completo do banco de dados
Um instantâneo completo do banco de dados inclui todos os arquivos Oracle, incluindo arquivos de dados, arquivos de controle e arquivos de log de arquivamento.
-
Faça login na interface do SnapCenter e clique em Recursos no menu do lado esquerdo. No menu suspenso Exibir, altere para a exibição Grupo de recursos.
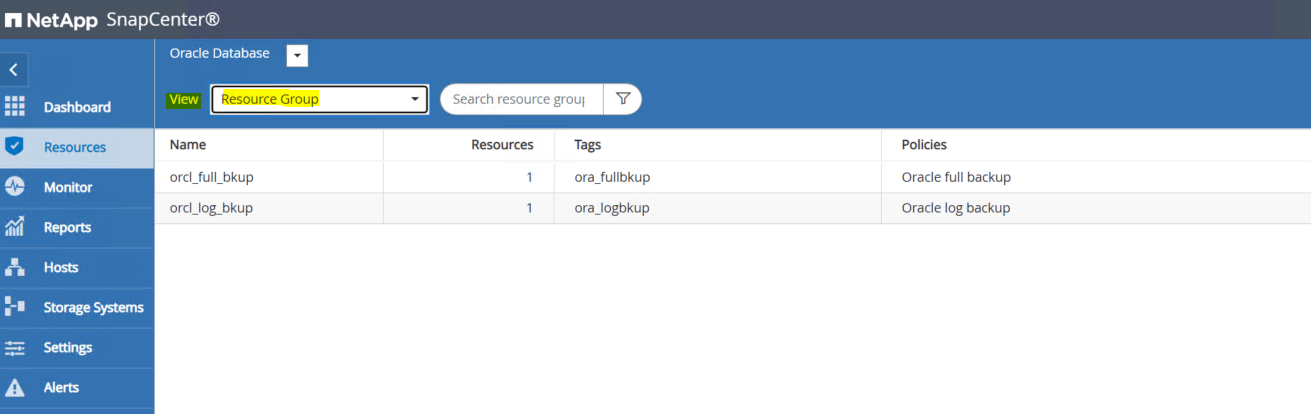
-
Clique no nome completo do recurso de backup e, em seguida, clique no ícone Fazer backup agora para iniciar um backup adicional.
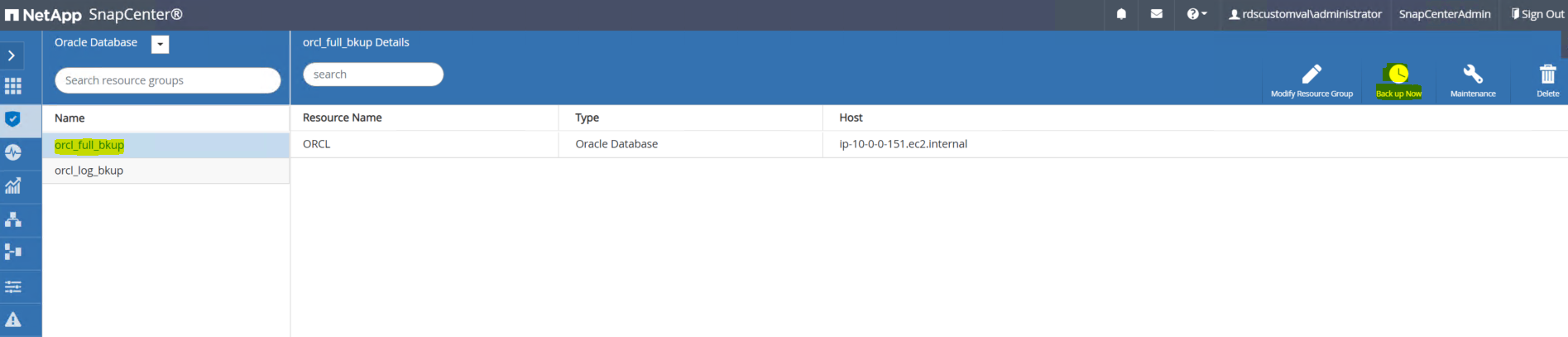
-
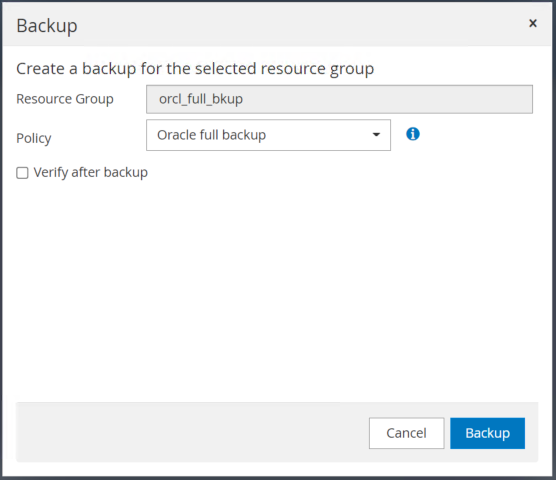
Clique em Backup e confirme o backup para iniciar um backup completo do banco de dados.
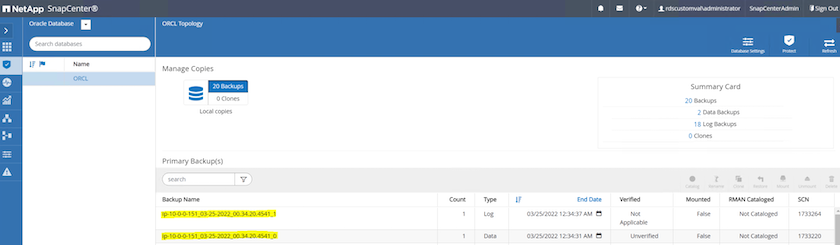
Na exibição Recurso do banco de dados, abra a página Cópias de backup gerenciadas do banco de dados para verificar se o backup único foi concluído com sucesso. Um backup completo do banco de dados cria dois instantâneos: um para o volume de dados e outro para o volume de log.
Tirando um instantâneo do log de arquivo
Um instantâneo do log de arquivo é tirado somente para o volume de log de arquivo do Oracle.
-
Faça login na interface do SnapCenter e clique na guia Recursos na barra de menu do lado esquerdo. No menu suspenso Exibir, altere para a exibição Grupo de recursos.
-
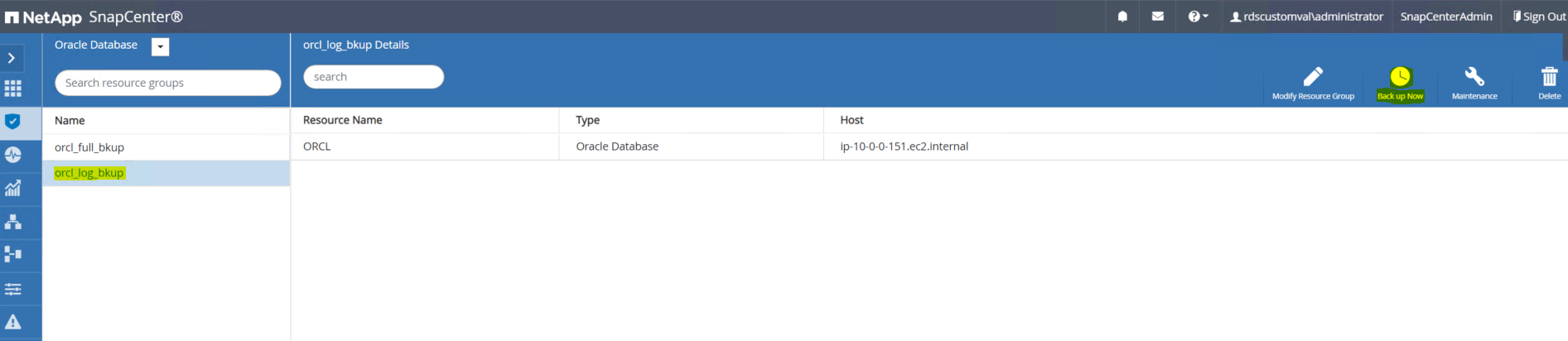
Clique no nome do recurso de backup de log e, em seguida, clique no ícone Fazer backup agora para iniciar um backup adicional para logs de arquivamento.
-
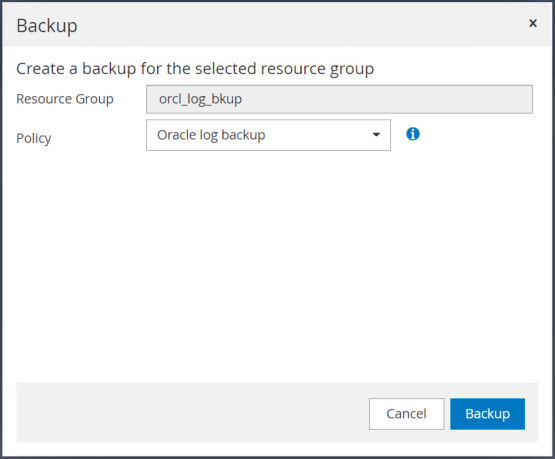
Clique em Backup e confirme o backup para iniciar um backup de log de arquivamento.
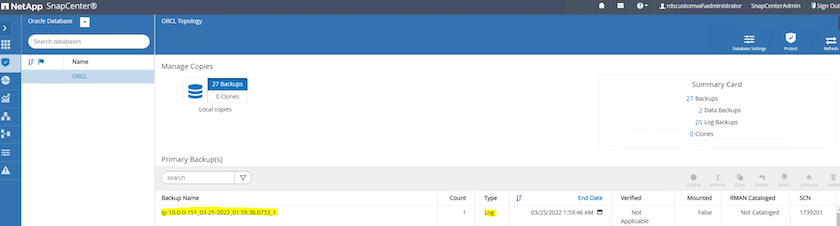
Na exibição Recurso do banco de dados, abra a página Cópias de backup gerenciadas do banco de dados para verificar se o backup de log de arquivamento único foi concluído com sucesso. Um backup de log de arquivamento cria um instantâneo para o volume de log.
Restaurando para um ponto no tempo
A restauração baseada em SnapCenter para um ponto no tempo é executada no mesmo host de instância do EC2. Conclua as seguintes etapas para executar a restauração:
-
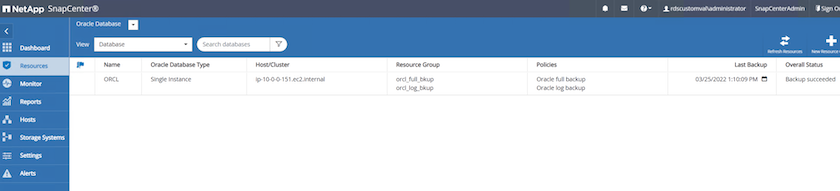
Na guia Recursos do SnapCenter > Exibição do banco de dados, clique no nome do banco de dados para abrir o backup do banco de dados.
-
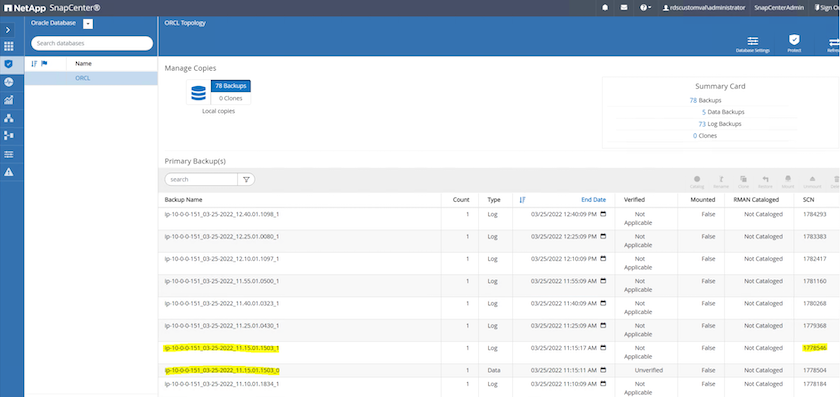
Selecione a cópia de backup do banco de dados e o momento desejado para restauração. Anote também o número SCN correspondente para aquele momento. A restauração de ponto no tempo pode ser executada usando o tempo ou o SCN.
-
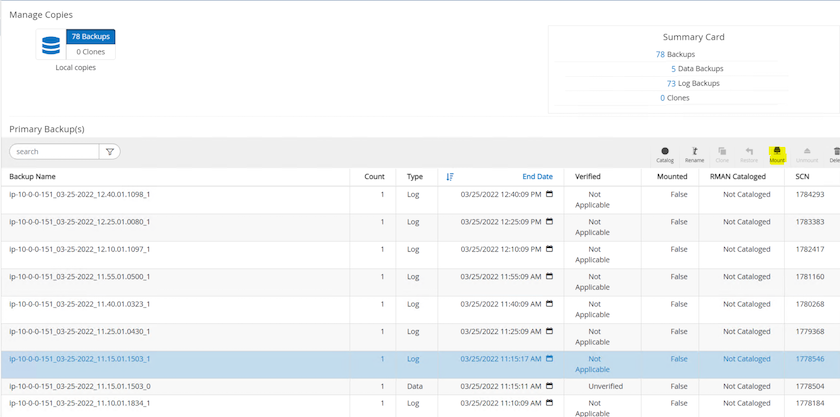
Realce o instantâneo do volume de log e clique no botão Montar para montar o volume.
-
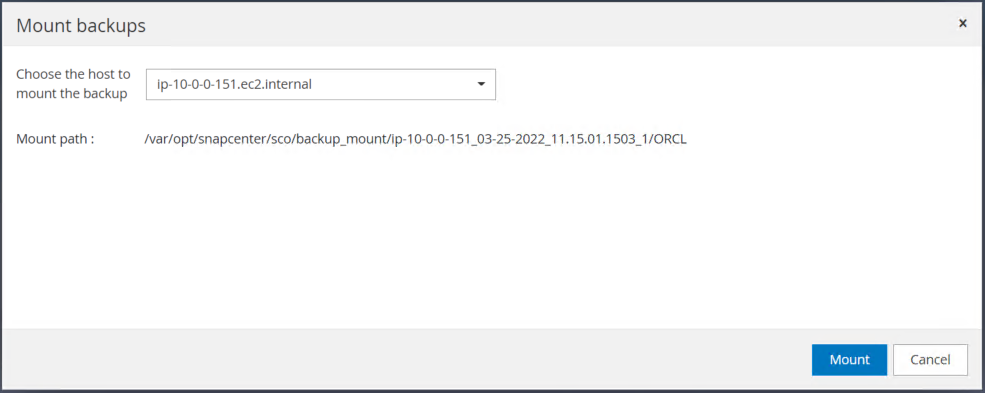
Escolha a instância primária do EC2 para montar o volume de log.
-
Verifique se o trabalho de montagem foi concluído com sucesso. Verifique também no host da instância do EC2 para ver qual volume de log foi montado e também o caminho do ponto de montagem.


-
Copie os logs de arquivo do volume de log montado para o diretório de log de arquivo atual.
[ec2-user@ip-10-0-0-151 ~]$ cp /var/opt/snapcenter/sco/backup_mount/ip-10-0-0-151_03-25-2022_11.15.01.1503_1/ORCL/1/db/ORCL_A/arch/*.arc /ora_nfs_log/db/ORCL_A/arch/
-
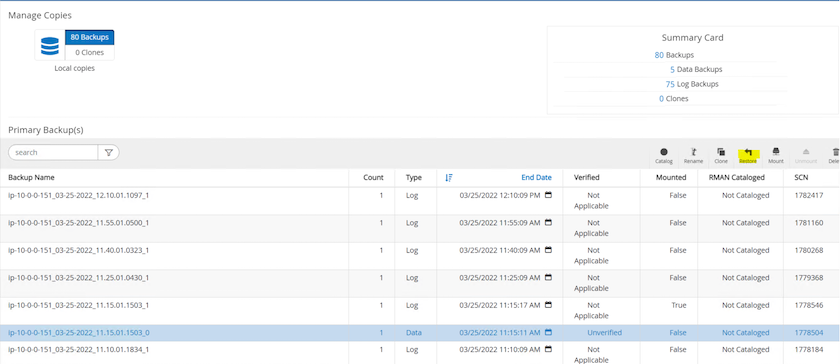
Retorne à guia Recursos do SnapCenter > página de backup do banco de dados, realce a cópia do instantâneo de dados e clique no botão Restaurar para iniciar o fluxo de trabalho de restauração do banco de dados.
-
Marque "Todos os arquivos de dados" e "Alterar estado do banco de dados, se necessário, para restauração e recuperação" e clique em Avançar.
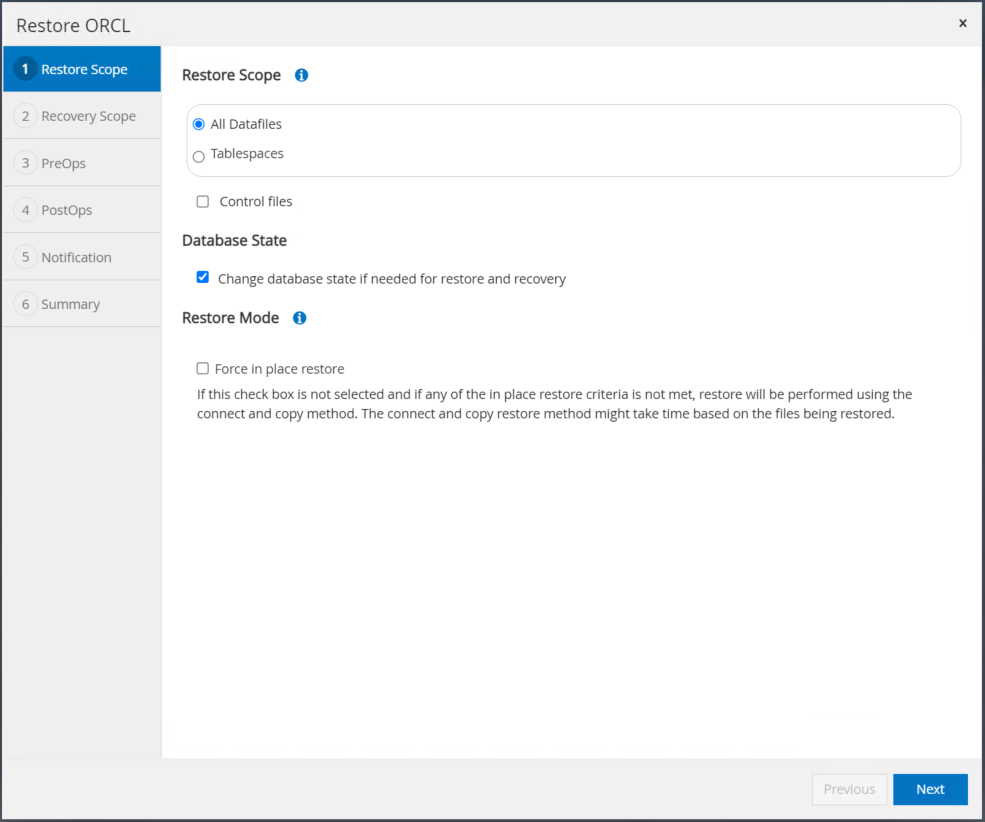
-
Escolha um escopo de recuperação desejado usando SCN ou tempo. Em vez de copiar os logs de arquivo montados para o diretório de log atual, conforme demonstrado na etapa 6, o caminho do log de arquivo montado pode ser listado em "Especificar locais de arquivos de log de arquivo externo" para recuperação.
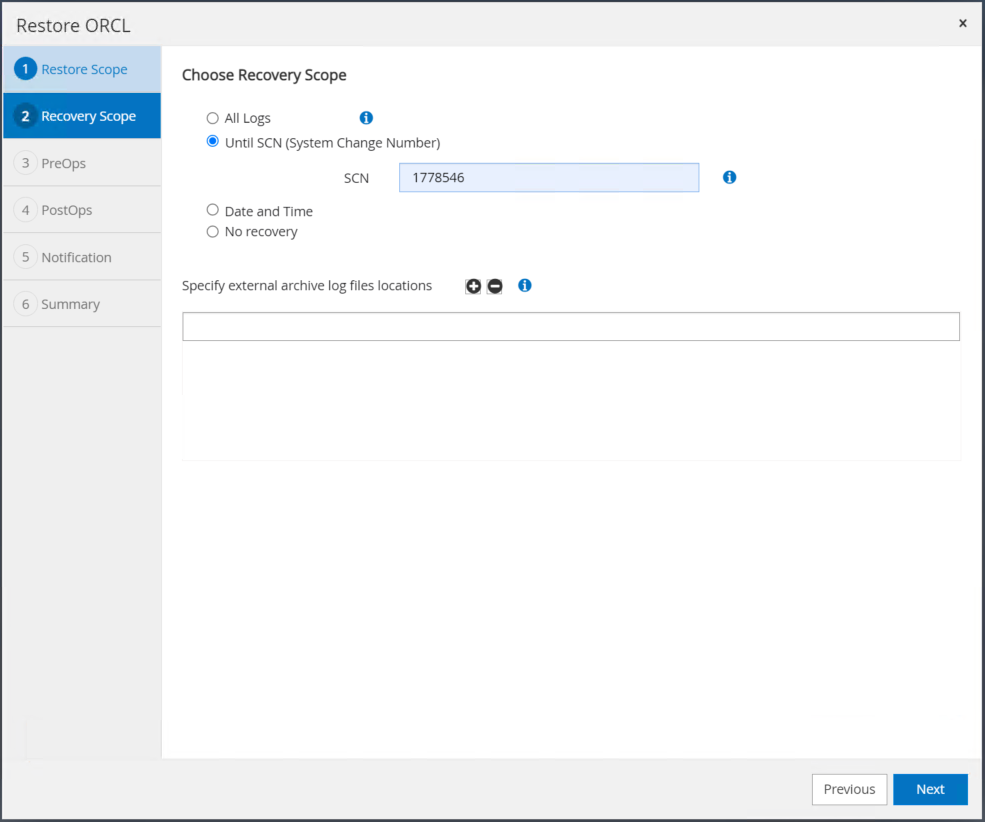
-
Especifique uma prescrição opcional para ser executada, se necessário.
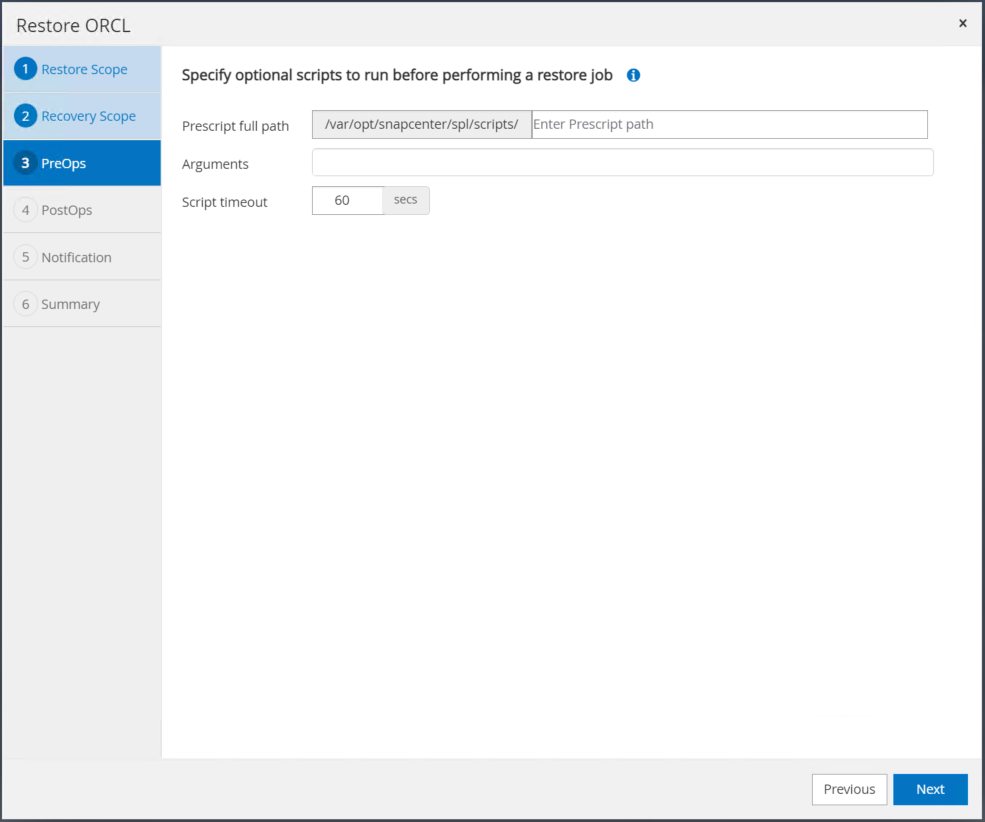
-
Especifique um afterscript opcional para ser executado, se necessário. Verifique o banco de dados aberto após a recuperação.
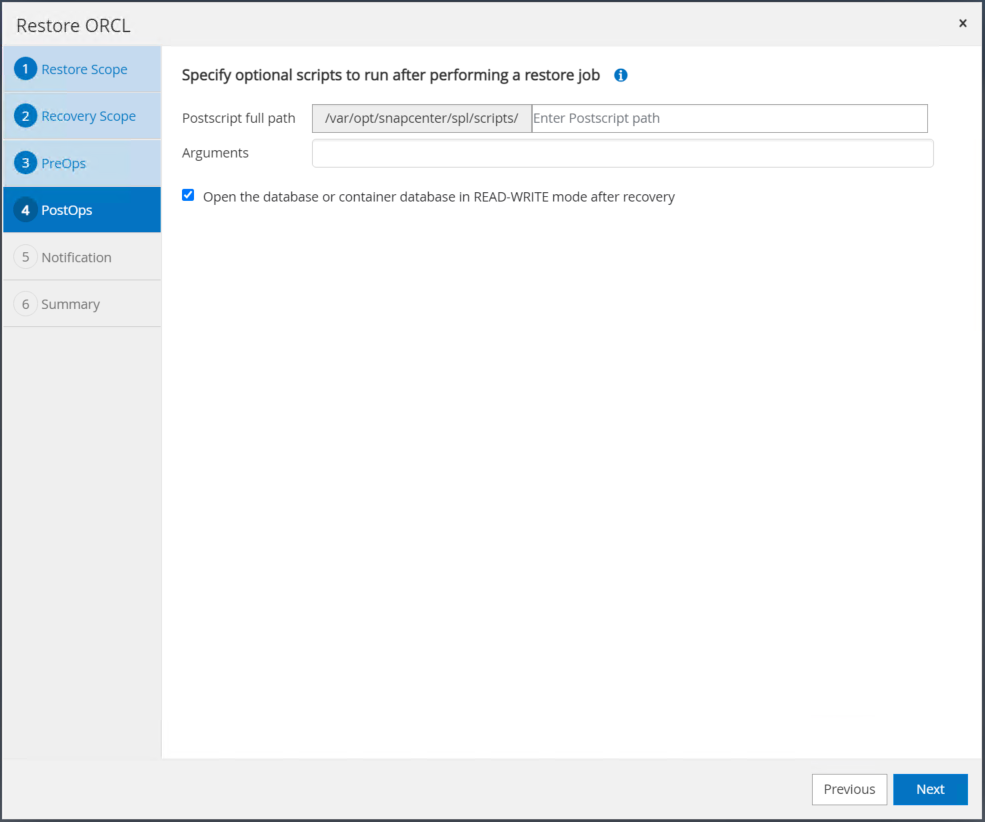
-
Forneça um servidor SMTP e um endereço de e-mail se uma notificação de trabalho for necessária.
-
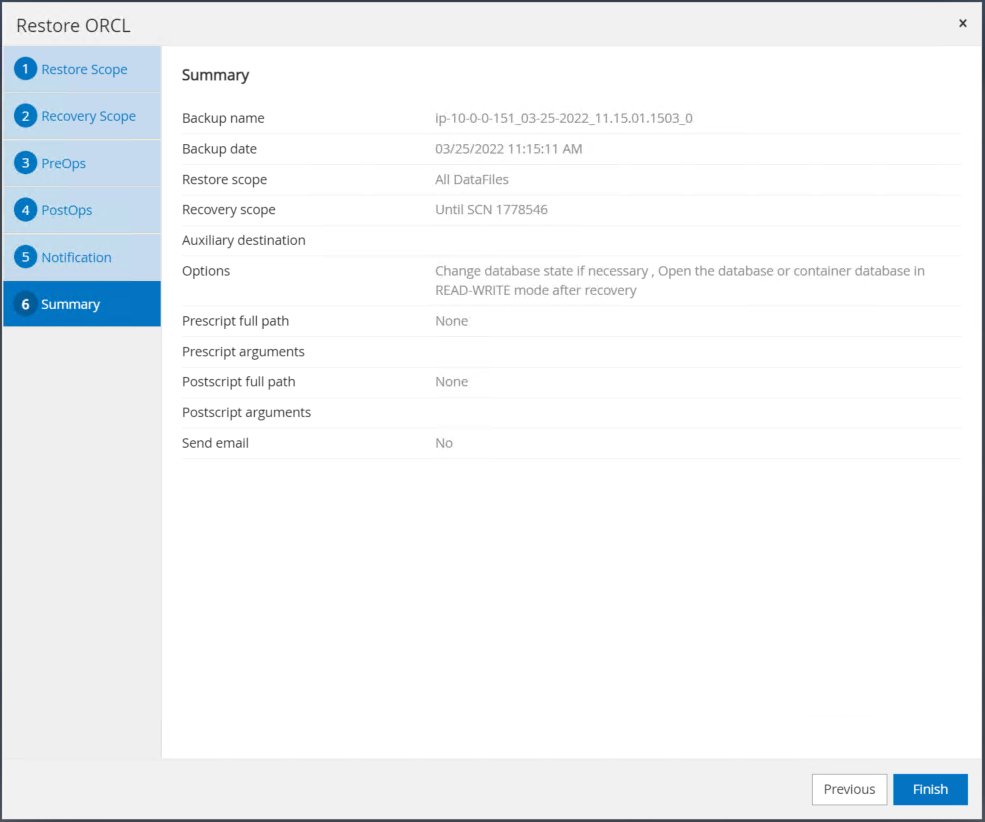
Restaure o resumo do trabalho. Clique em Concluir para iniciar o trabalho de restauração.
-
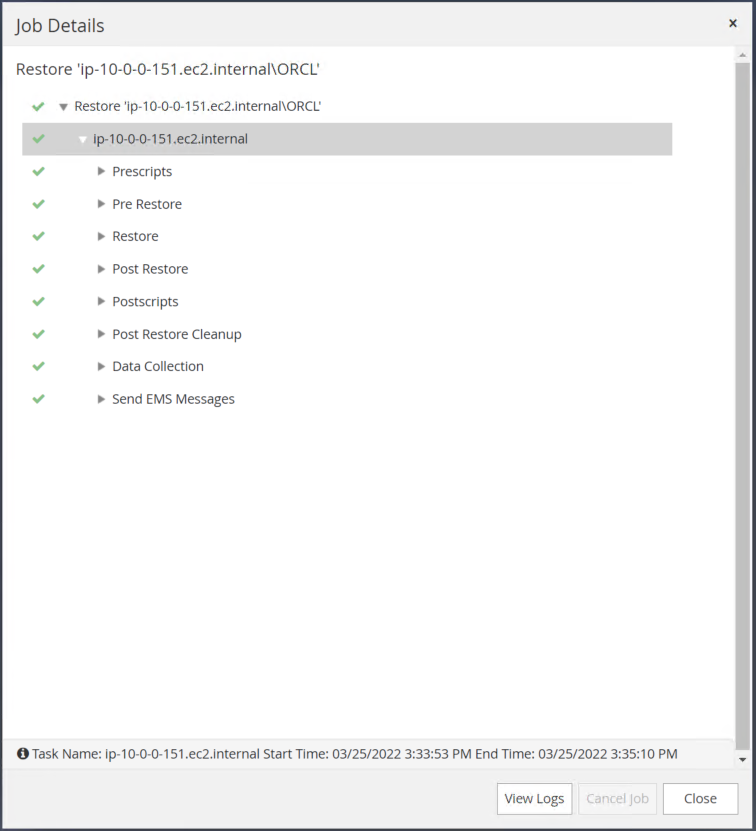
Valide a restauração do SnapCenter.
-
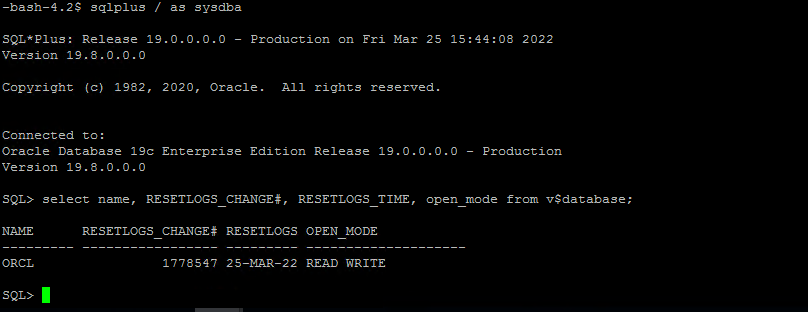
Valide a restauração do host da instância EC2.
-
Para desmontar o volume do log de restauração, inverta as etapas da etapa 4.
Criando um clone de banco de dados
A seção a seguir demonstra como usar o fluxo de trabalho de clone do SnapCenter para criar um clone de banco de dados de um banco de dados primário para uma instância EC2 em espera.
-
Faça um backup instantâneo completo do banco de dados primário do SnapCenter usando o grupo de recursos de backup completo.
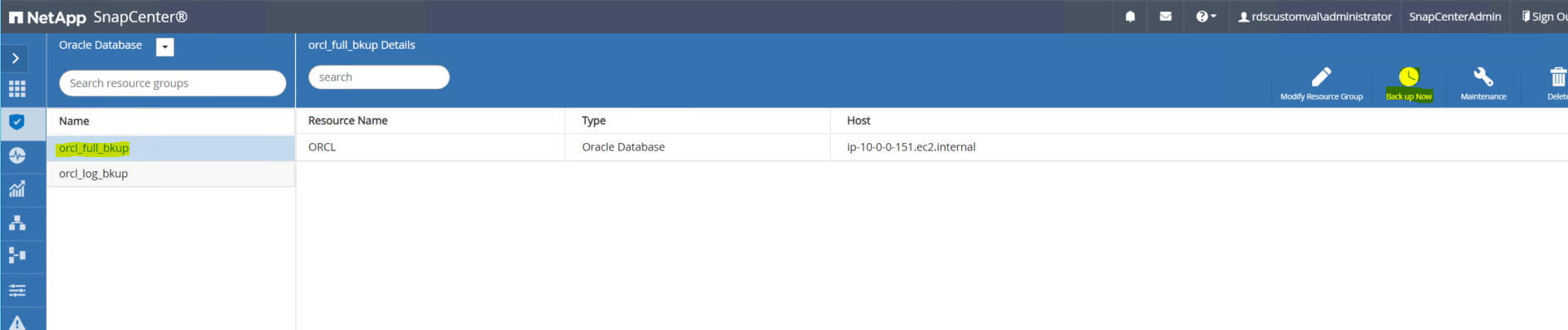
-
Na guia Recurso do SnapCenter > exibição Banco de dados, abra a página Gerenciamento de backup do banco de dados para o banco de dados principal do qual a réplica será criada.
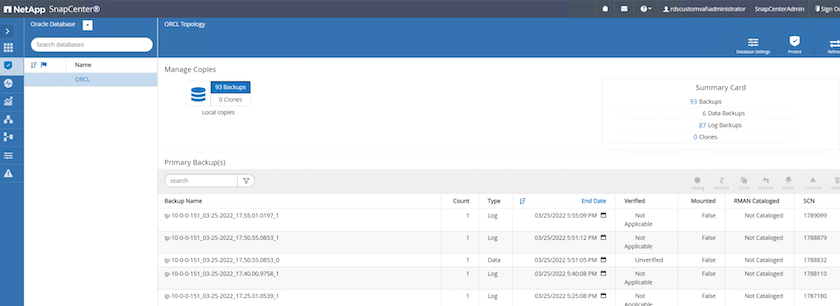
-
Monte o instantâneo do volume de log obtido na etapa 4 no host da instância do EC2 em espera.
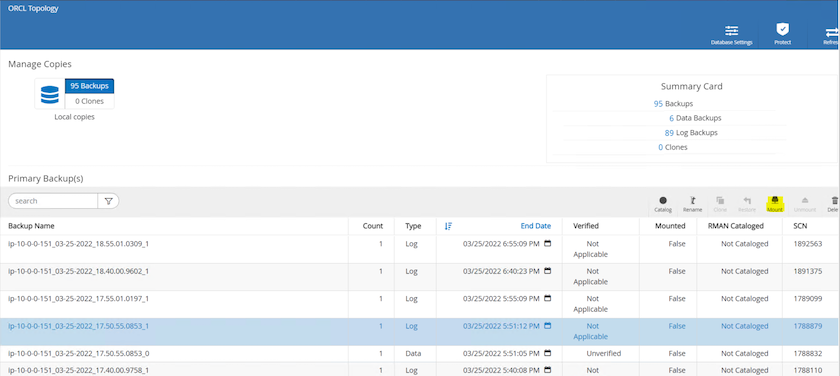
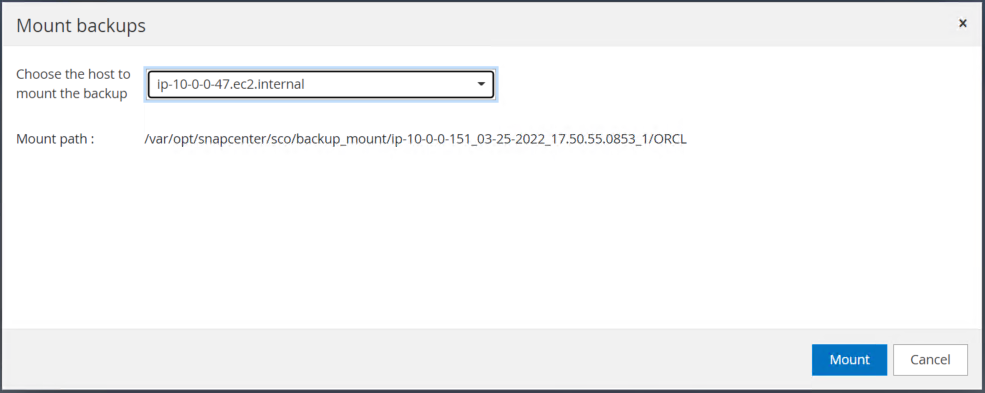
-
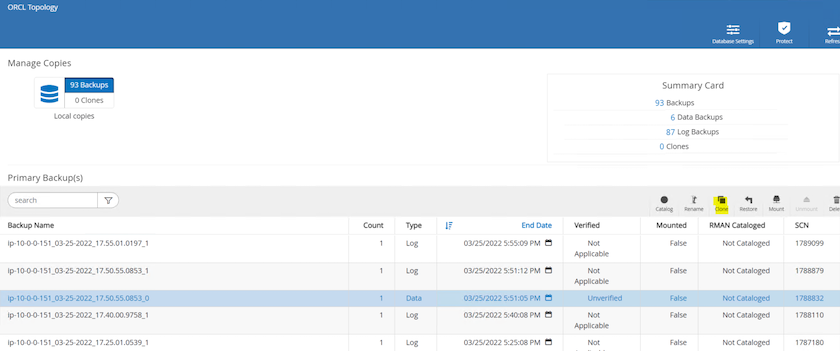
Realce a cópia do instantâneo a ser clonada para a réplica e clique no botão Clonar para iniciar o procedimento de clonagem.
-
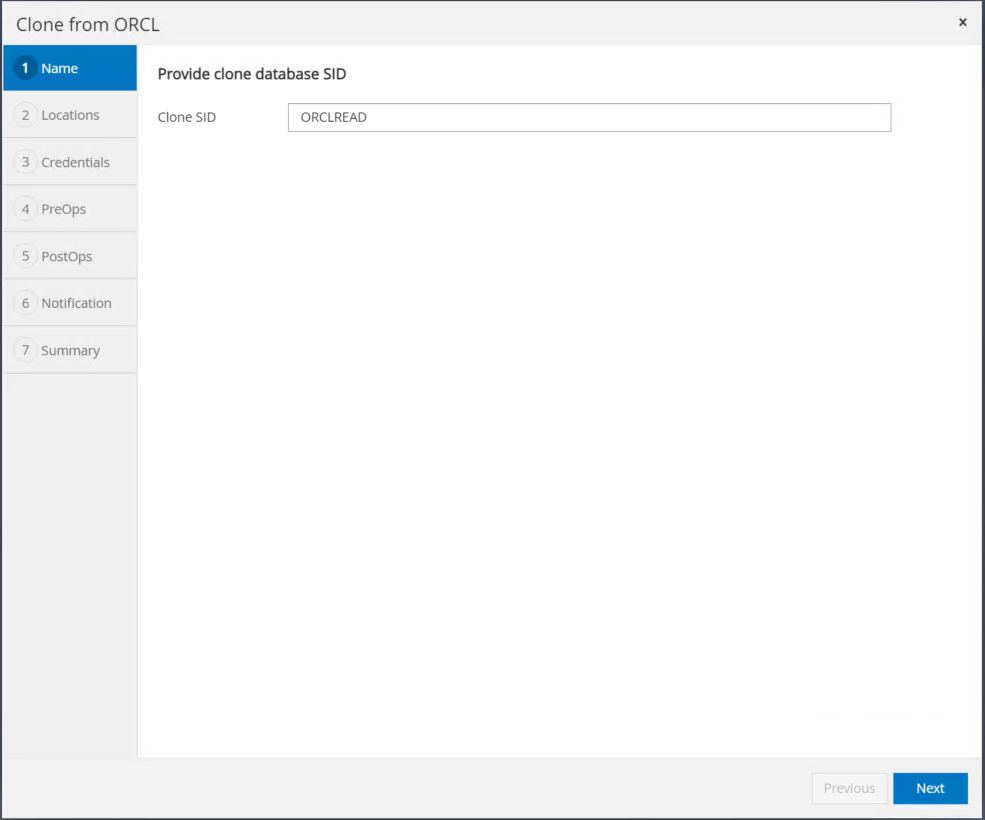
Altere o nome da cópia de réplica para que seja diferente do nome do banco de dados principal. Clique em Avançar.
-
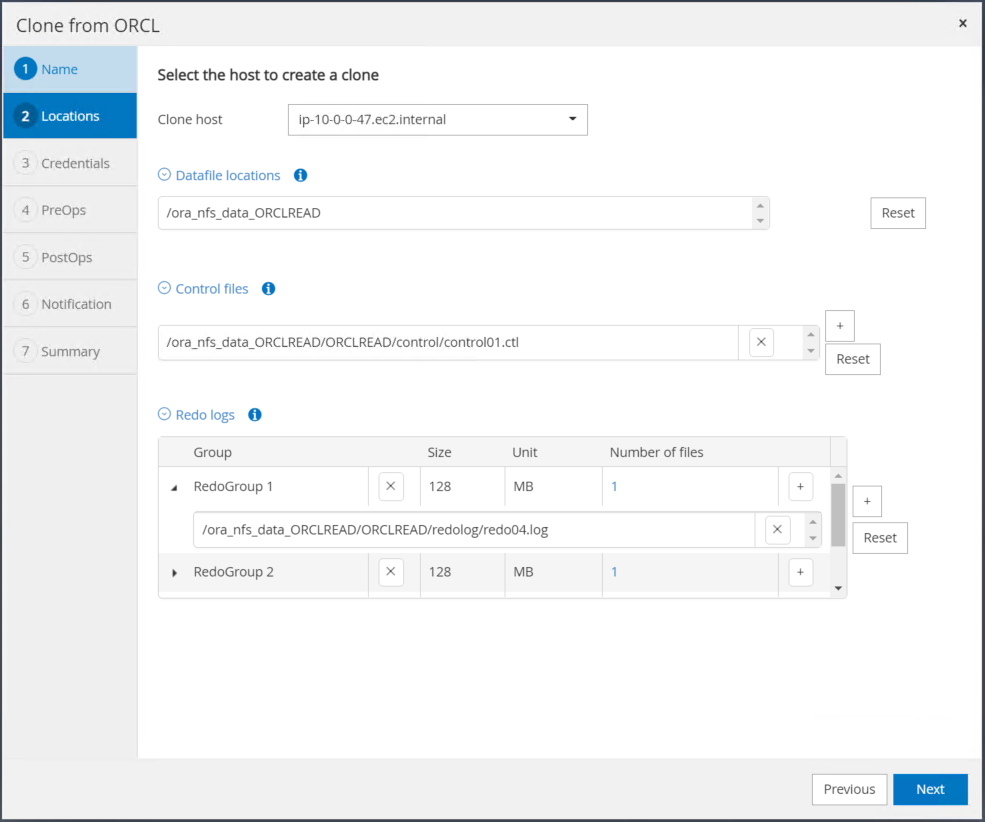
Altere o host clone para o host EC2 em espera, aceite a nomenclatura padrão e clique em Avançar.
-
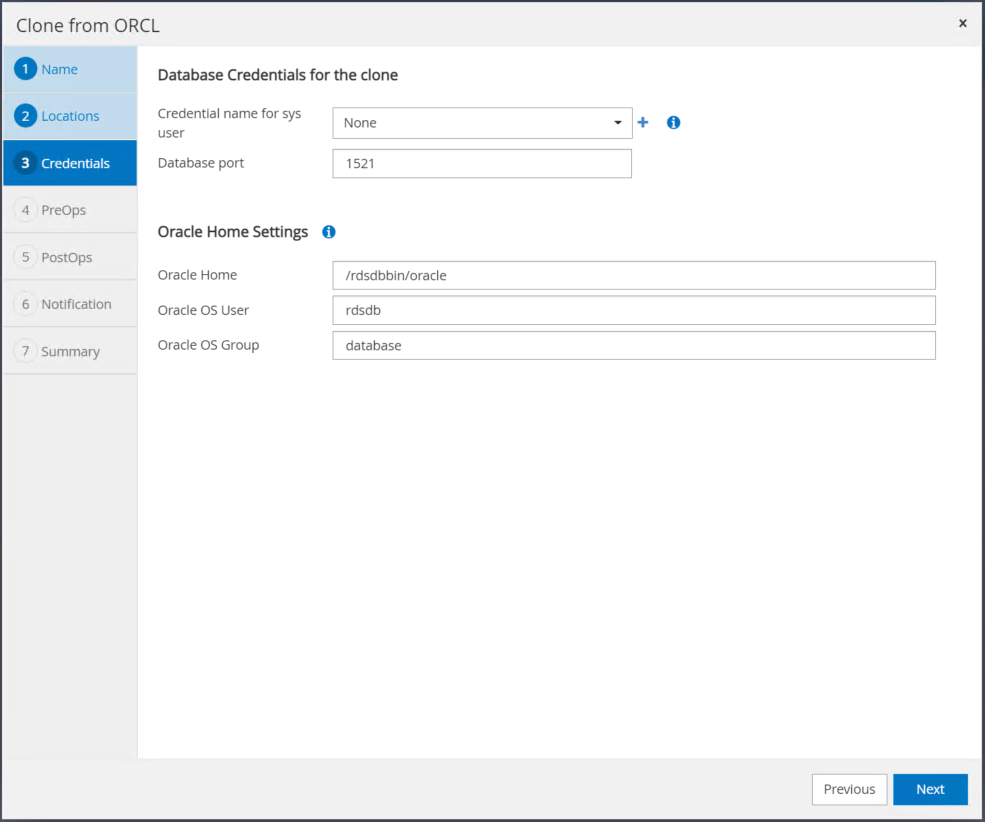
Altere as configurações do Oracle home para corresponder às configuradas para o host do servidor Oracle de destino e clique em Avançar.
-
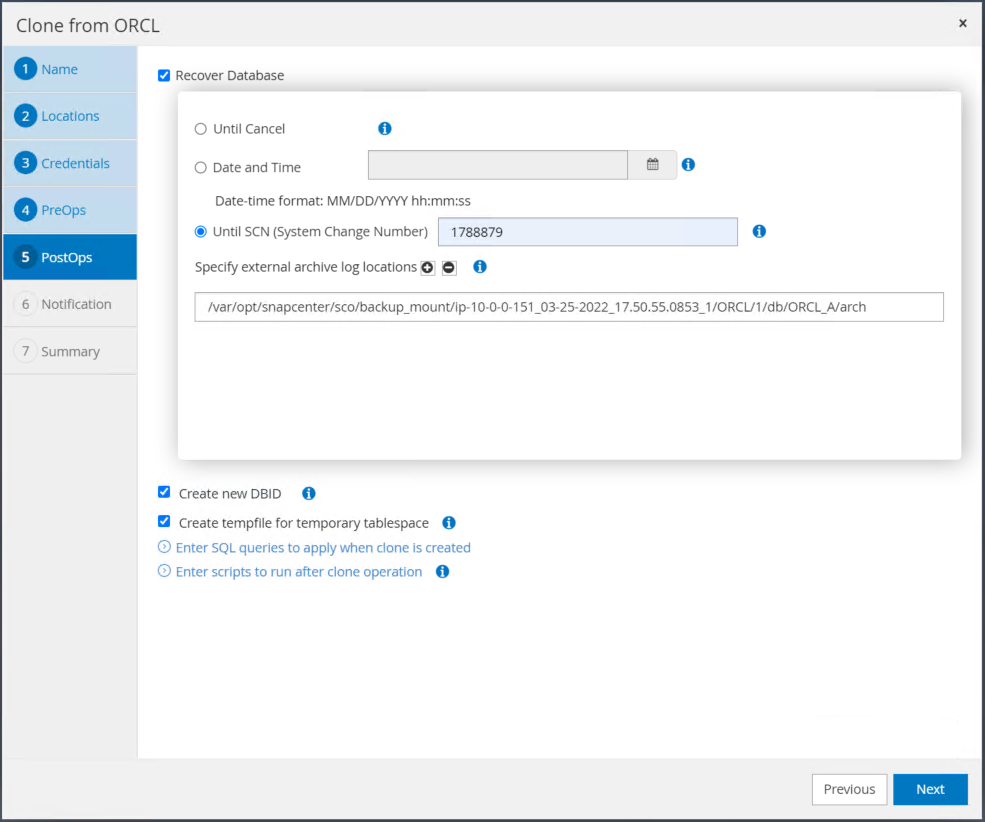
Especifique um ponto de recuperação usando o tempo ou o SCN e o caminho do log de arquivo montado.
-
Envie as configurações de e-mail SMTP, se necessário.
-
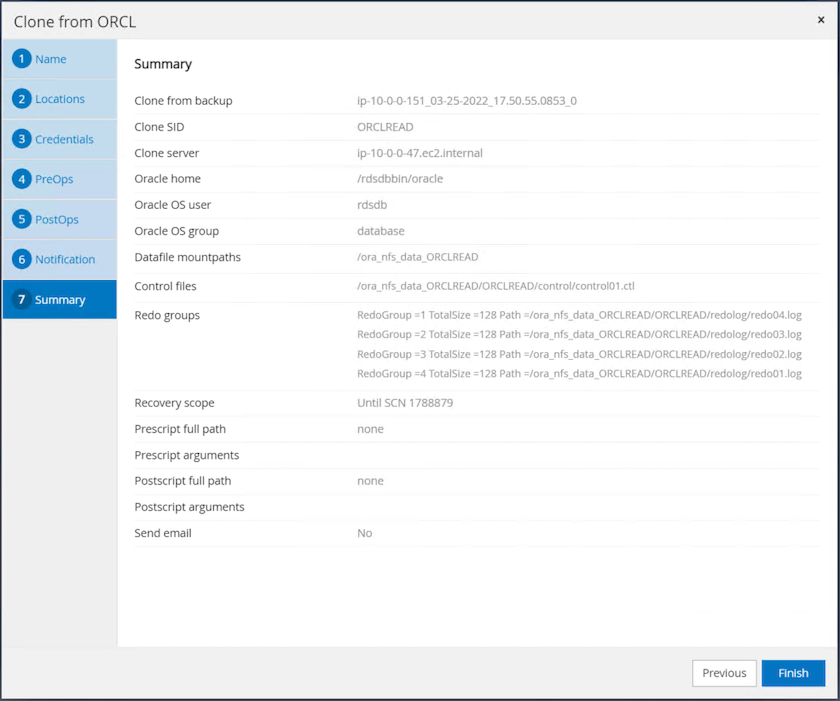
Clone o resumo do trabalho e clique em Concluir para iniciar o trabalho de clonagem.
-
Valide o clone da réplica revisando o log do trabalho de clonagem.
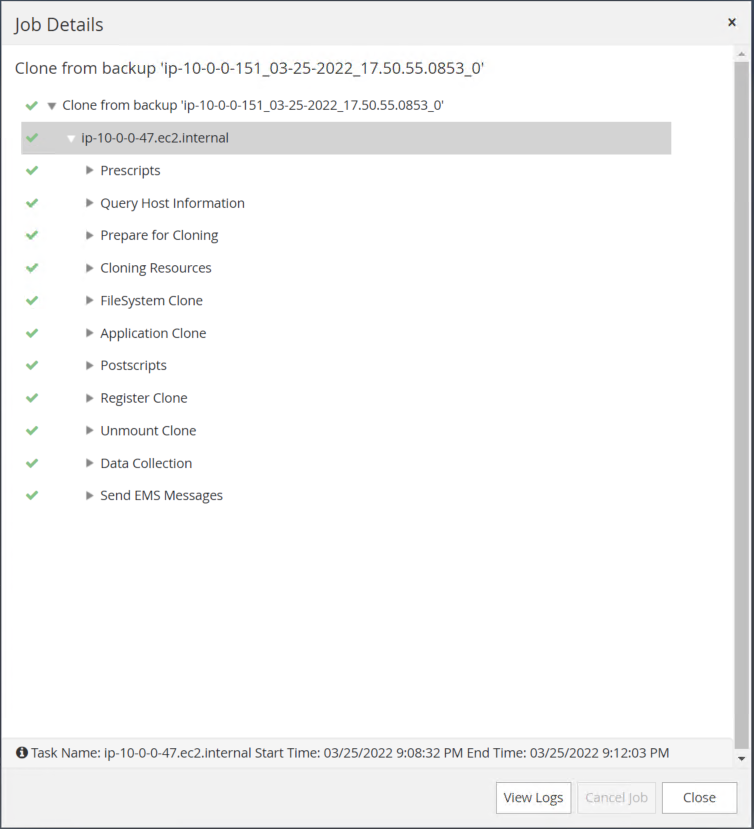
O banco de dados clonado é registrado no SnapCenter imediatamente.
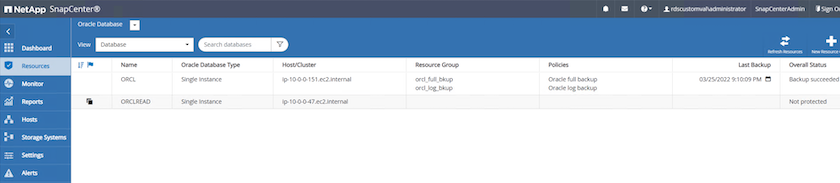
-
Desative o modo de log de arquivamento do Oracle. Efetue login na instância do EC2 como usuário oracle e execute o seguinte comando:
sqlplus / as sysdbashutdown immediate;startup mount;alter database noarchivelog;alter database open;

|
Em vez de cópias de backup primárias do Oracle, um clone também pode ser criado a partir de cópias de backup secundárias replicadas no cluster FSx de destino com os mesmos procedimentos. |
Failover de HA para espera e ressincronização
O cluster Oracle HA em espera fornece alta disponibilidade em caso de falha no site principal, seja na camada de computação ou na camada de armazenamento. Um benefício significativo da solução é que um usuário pode testar e validar a infraestrutura a qualquer momento ou com qualquer frequência. O failover pode ser simulado pelo usuário ou acionado por uma falha real. Os processos de failover são idênticos e podem ser automatizados para recuperação rápida de aplicativos.
Veja a seguinte lista de procedimentos de failover:
-
Para um failover simulado, execute um backup de instantâneo de log para liberar as transações mais recentes para o site de espera, conforme demonstrado na seçãoTirando um instantâneo do log de arquivo . Para um failover acionado por uma falha real, os últimos dados recuperáveis são replicados para o site em espera com o último backup de volume de log agendado bem-sucedido.
-
Divida o SnapMirror entre o cluster FSx primário e o de espera.
-
Monte os volumes de banco de dados em espera replicados no host da instância do EC2 em espera.
-
Revincule o binário Oracle se o binário Oracle replicado for usado para recuperação Oracle.
-
Recupere o banco de dados Oracle em espera para o último log de arquivamento disponível.
-
Abra o banco de dados Oracle em espera para acesso de aplicativos e usuários.
-
Em caso de falha real do site primário, o banco de dados Oracle de espera agora assume a função do novo site primário e os volumes do banco de dados podem ser usados para reconstruir o site primário com falha como um novo site de espera com o método SnapMirror reverso.
-
Para uma falha simulada do site primário para teste ou validação, desligue o banco de dados Oracle em espera após a conclusão dos exercícios de teste. Em seguida, desmonte os volumes do banco de dados em espera do host da instância EC2 em espera e ressincronize a replicação do site principal para o site em espera.
Esses procedimentos podem ser executados com o NetApp Automation Toolkit disponível para download no site público do NetApp GitHub.
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLeia atentamente as instruções README antes de tentar a configuração e o teste de failover.