Procedimentos passo a passo de implantação do Oracle no AWS EC2 e FSx
 Sugerir alterações
Sugerir alterações
Esta seção descreve os procedimentos de implantação do banco de dados personalizado Oracle RDS com armazenamento FSx.
Implantar uma instância EC2 Linux para Oracle via console EC2
Se você é novo na AWS, primeiro precisa configurar um ambiente AWS. A guia de documentação na página inicial do site da AWS fornece links de instruções do EC2 sobre como implantar uma instância do Linux EC2 que pode ser usada para hospedar seu banco de dados Oracle por meio do console do AWS EC2. A seção a seguir é um resumo dessas etapas. Para obter detalhes, consulte a documentação específica do AWS EC2 vinculada.
Configurando seu ambiente AWS EC2
Você deve criar uma conta AWS para provisionar os recursos necessários para executar seu ambiente Oracle no serviço EC2 e FSx. A seguinte documentação da AWS fornece os detalhes necessários:
Tópicos principais:
-
Inscreva-se na AWS.
-
Crie um par de chaves.
-
Crie um grupo de segurança.
Habilitando várias zonas de disponibilidade em atributos de conta da AWS
Para uma configuração de alta disponibilidade do Oracle, conforme demonstrado no diagrama de arquitetura, você deve habilitar pelo menos quatro zonas de disponibilidade em uma região. As múltiplas zonas de disponibilidade também podem ser situadas em diferentes regiões para atender às distâncias necessárias para recuperação de desastres.
Criação e conexão a uma instância EC2 para hospedar banco de dados Oracle
Veja o tutorial"Comece a usar instâncias do Amazon EC2 Linux" para procedimentos de implantação passo a passo e melhores práticas.
Tópicos principais:
-
Visão geral.
-
Pré-requisitos.
-
Etapa 1: inicie uma instância.
-
Etapa 2: conecte-se à sua instância.
-
Etapa 3: limpe sua instância.
As capturas de tela a seguir demonstram a implantação de uma instância Linux do tipo m5 com o console EC2 para executar o Oracle.
-
No painel do EC2, clique no botão amarelo Iniciar instância para iniciar o fluxo de trabalho de implantação da instância do EC2.
-
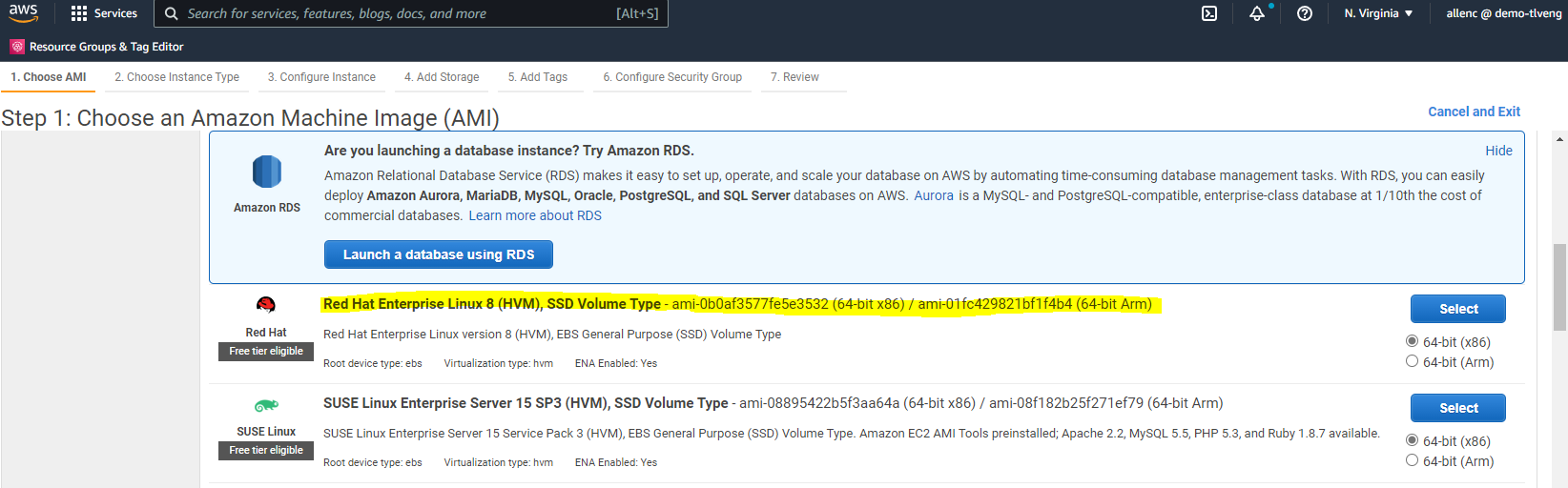
Na Etapa 1, selecione "Red Hat Enterprise Linux 8 (HVM), Tipo de Volume SSD - ami-0b0af3577fe5e3532 (x86 de 64 bits) / ami-01fc429821bf1f4b4 (Arm de 64 bits)."
-
Na Etapa 2, selecione um tipo de instância m5 com a alocação de CPU e memória apropriada com base na carga de trabalho do seu banco de dados Oracle. Clique em "Avançar: Configurar detalhes da instância".
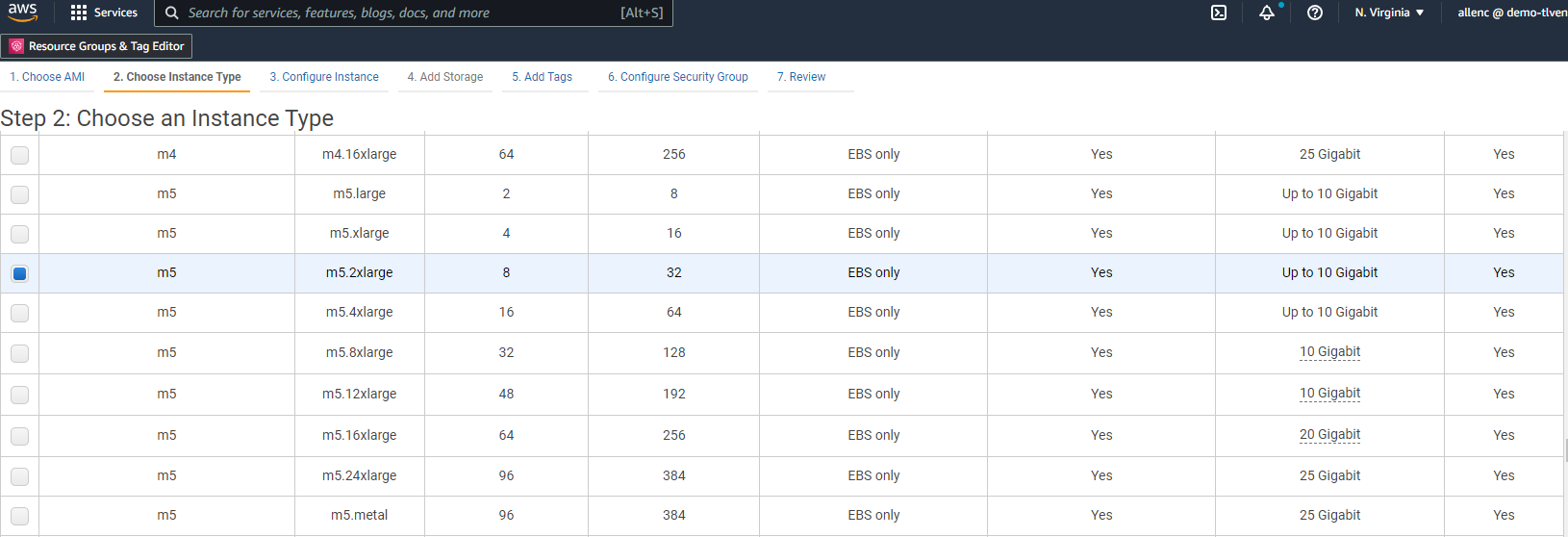
-
Na Etapa 3, escolha a VPC e a sub-rede onde a instância deve ser colocada e habilite a atribuição de IP público. Clique em "Avançar: Adicionar armazenamento".
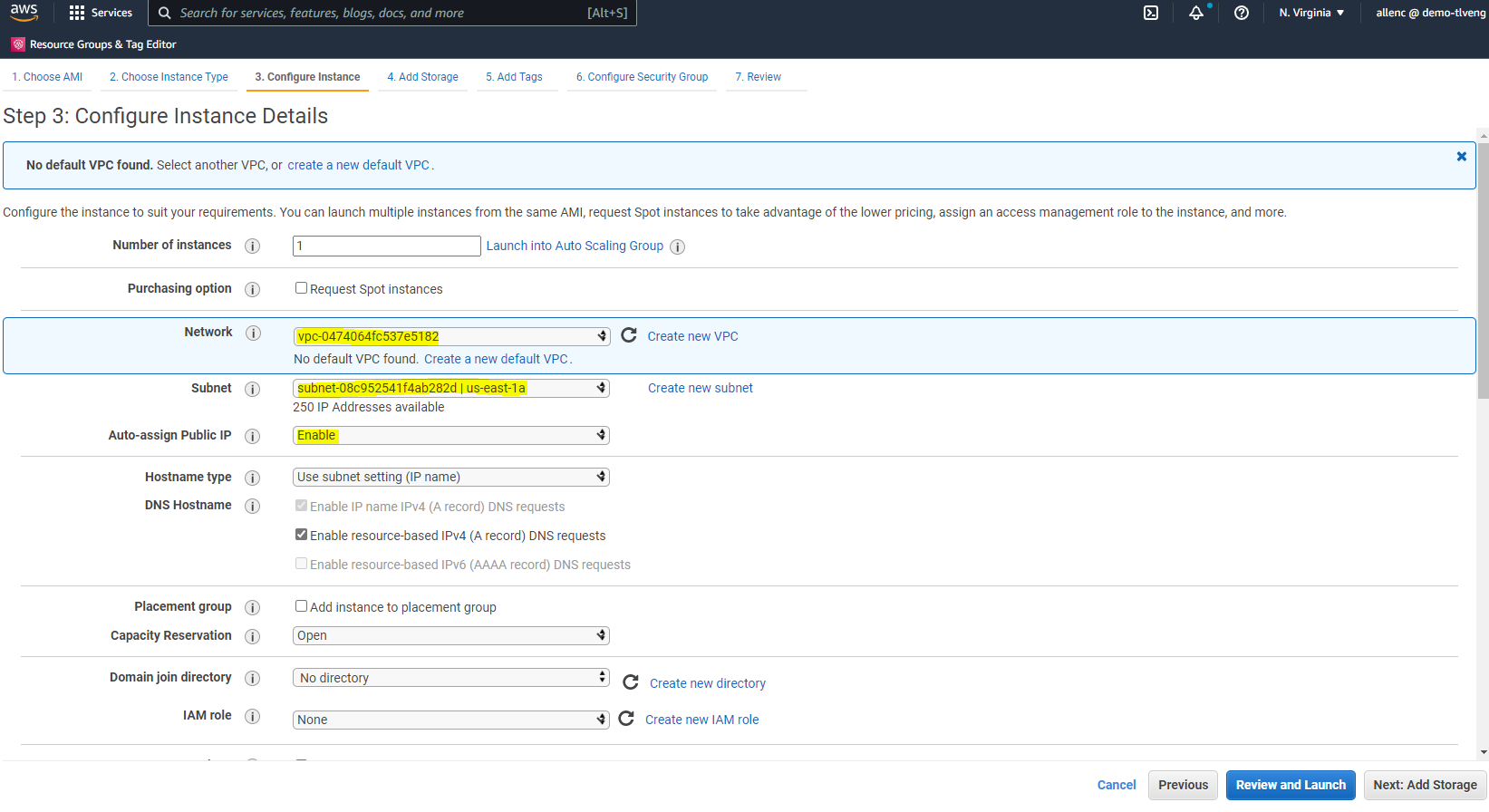
-
Na Etapa 4, aloque espaço suficiente para o disco raiz. Você pode precisar de espaço para adicionar uma troca. Por padrão, a instância do EC2 atribui espaço de swap zero, o que não é ideal para executar o Oracle.
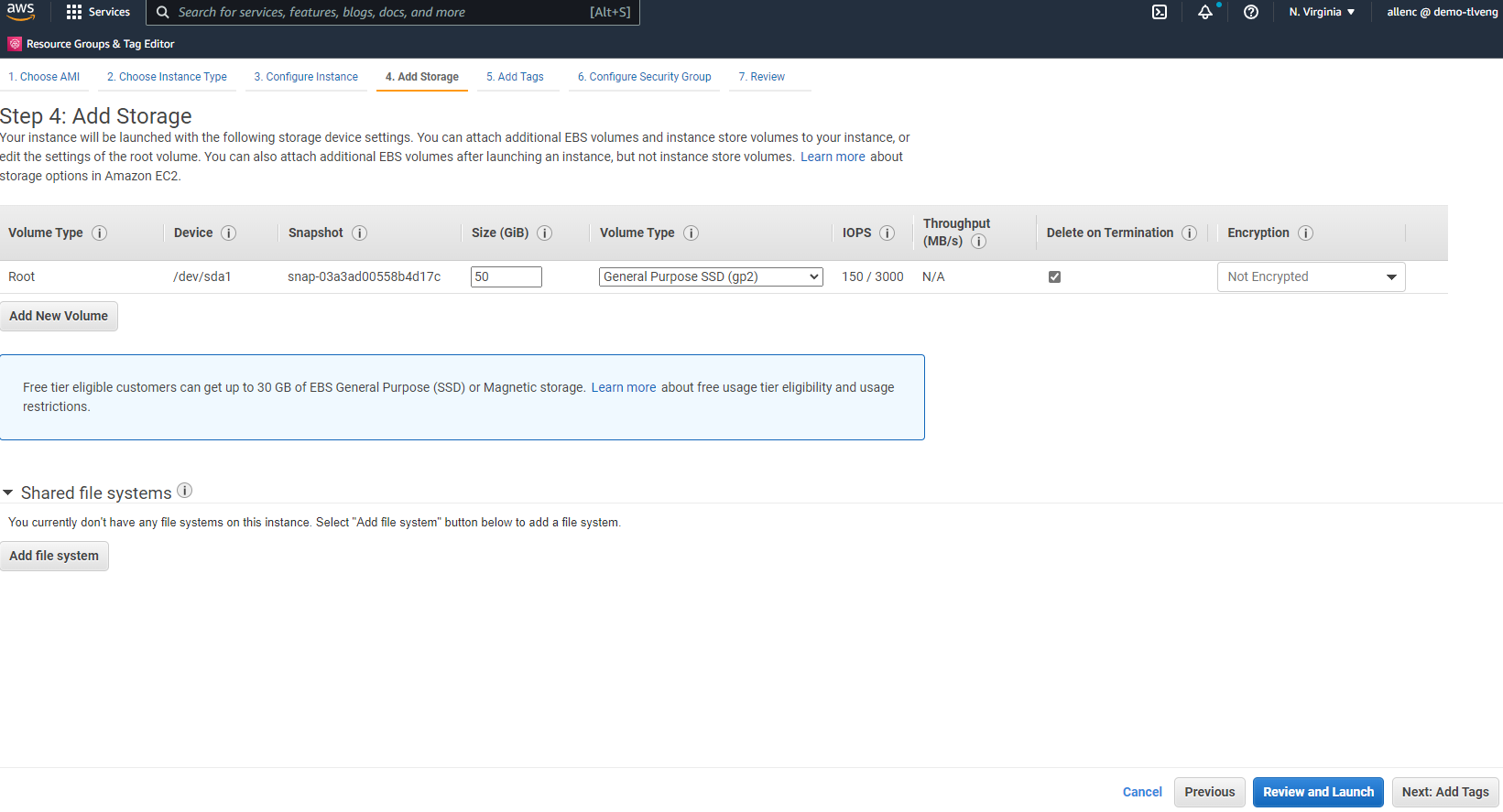
-
Na Etapa 5, adicione uma tag para identificação da instância, se necessário.
-
Na Etapa 6, selecione um grupo de segurança existente ou crie um novo com a política de entrada e saída desejada para a instância.
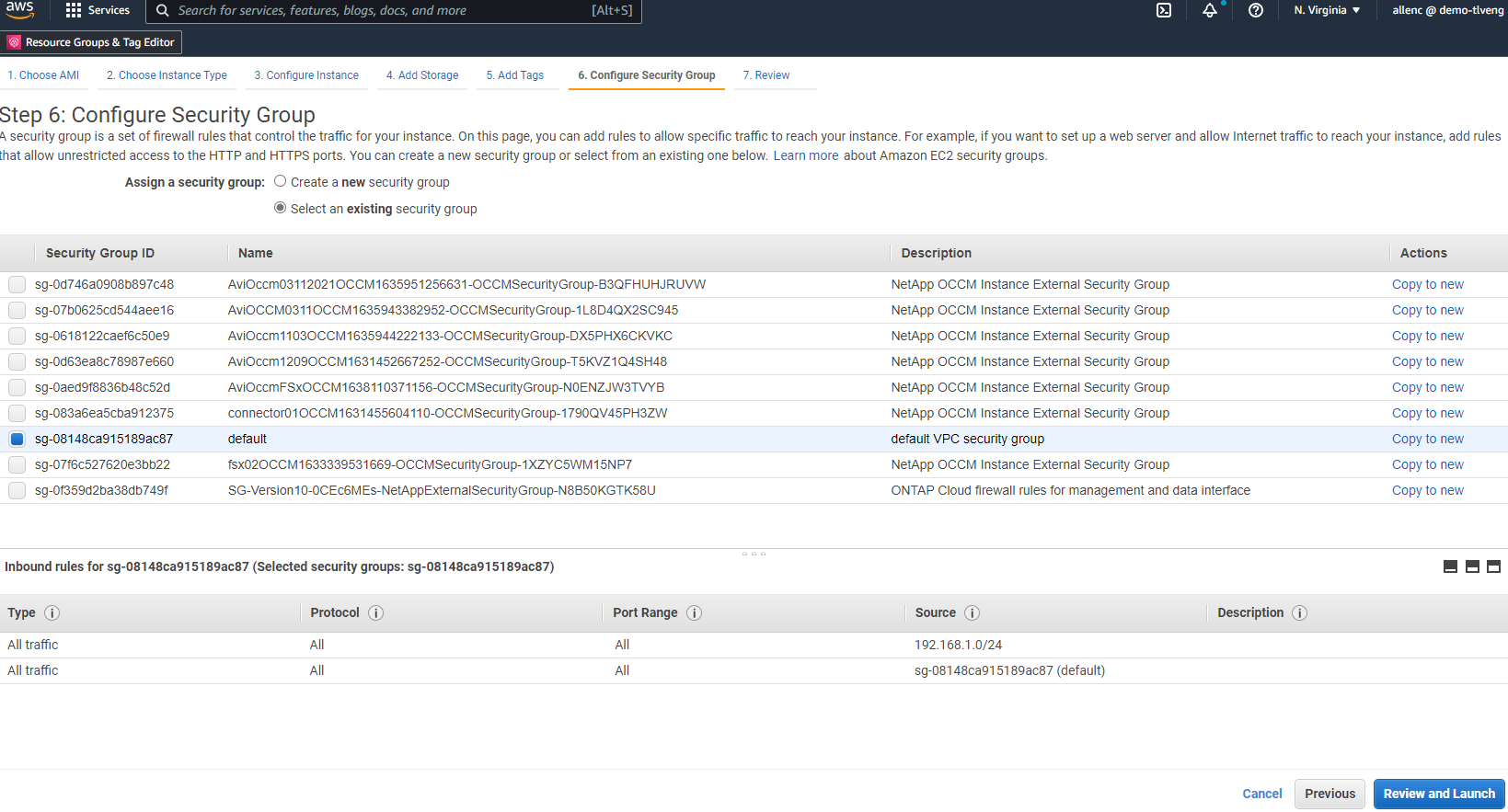
-
Na Etapa 7, revise o resumo da configuração da instância e clique em Iniciar para iniciar a implantação da instância. Você será solicitado a criar um par de chaves ou selecionar um par de chaves para acesso à instância.
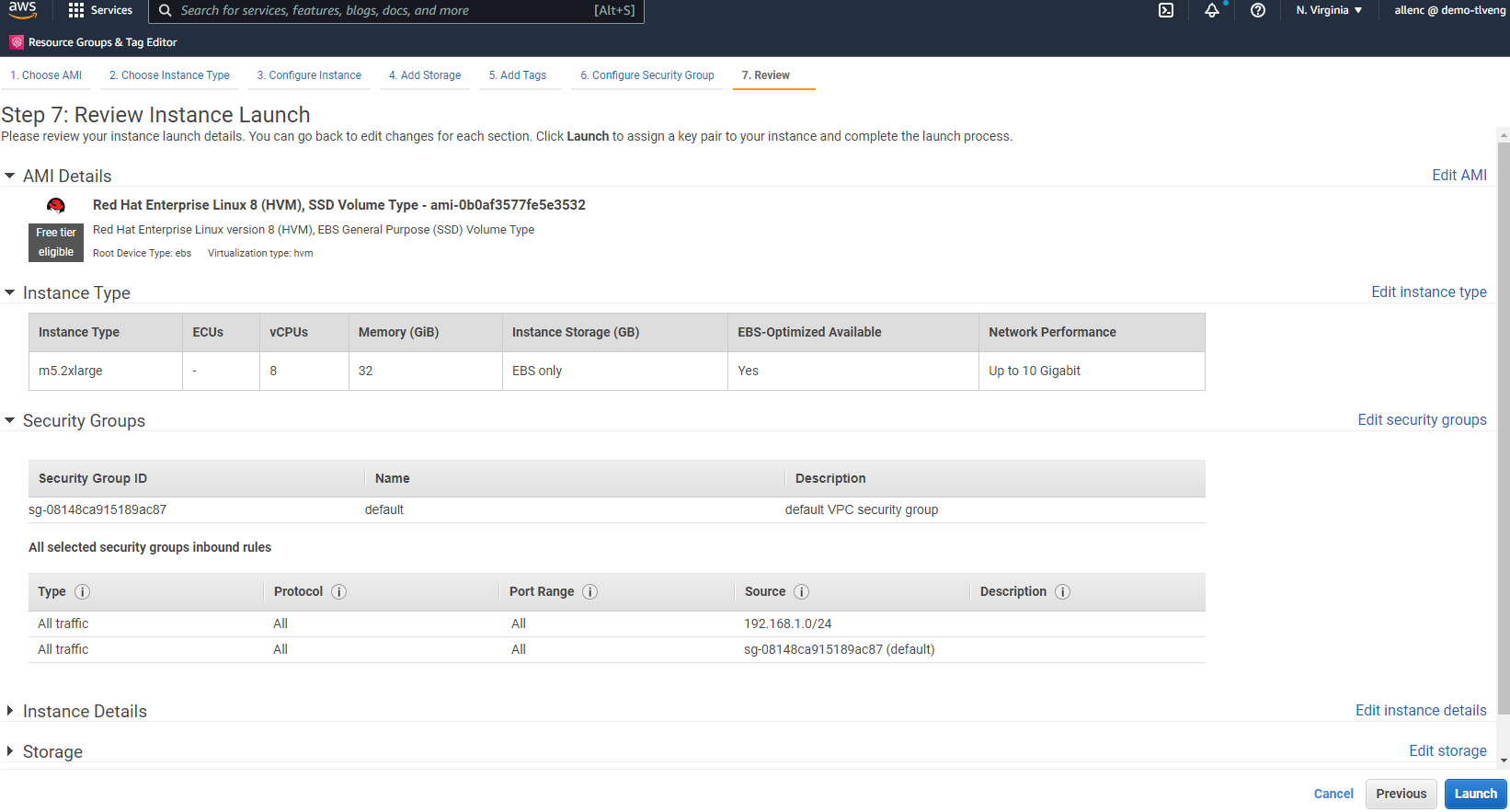
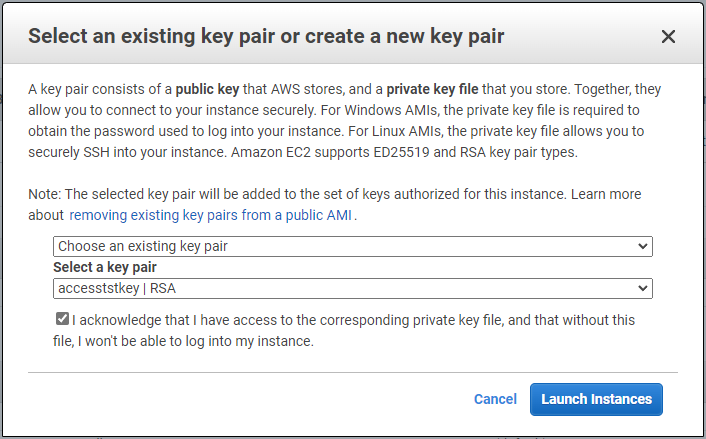
-
Efetue login na instância EC2 usando um par de chaves SSH. Faça alterações no nome da sua chave e no endereço IP da instância conforme apropriado.
ssh -i ora-db1v2.pem ec2-user@54.80.114.77
Você precisa criar duas instâncias do EC2 como servidores Oracle primário e de espera em suas zonas de disponibilidade designadas, conforme demonstrado no diagrama de arquitetura.
Provisionar sistemas de arquivos FSx ONTAP para armazenamento de banco de dados Oracle
A implantação da instância do EC2 aloca um volume raiz do EBS para o sistema operacional. Os sistemas de arquivos FSx ONTAP fornecem volumes de armazenamento de banco de dados Oracle, incluindo volumes binários, de dados e de log do Oracle. Os volumes NFS de armazenamento do FSx podem ser provisionados a partir do console do AWS FSx ou da instalação e automação de configuração do Oracle que aloca os volumes conforme o usuário configura em um arquivo de parâmetros de automação.
Criação de sistemas de arquivos FSx ONTAP
Referiu-se a esta documentação "Gerenciando sistemas de arquivos FSx ONTAP" para criar sistemas de arquivos FSx ONTAP .
Considerações principais:
-
Capacidade de armazenamento SSD. Mínimo 1024 GiB, máximo 192 TiB.
-
IOPS SSD provisionados. Com base nos requisitos de carga de trabalho, um máximo de 80.000 IOPS SSD por sistema de arquivos.
-
Capacidade de processamento.
-
Definir senha do administrador fsxadmin/vsadmin. Necessário para automação de configuração do FSx.
-
Backup e manutenção. Desabilite backups diários automáticos; o backup do armazenamento do banco de dados é executado por meio do agendamento do SnapCenter .
-
Recupere o endereço IP de gerenciamento do SVM, bem como os endereços de acesso específicos do protocolo na página de detalhes do SVM. Necessário para automação de configuração do FSx.
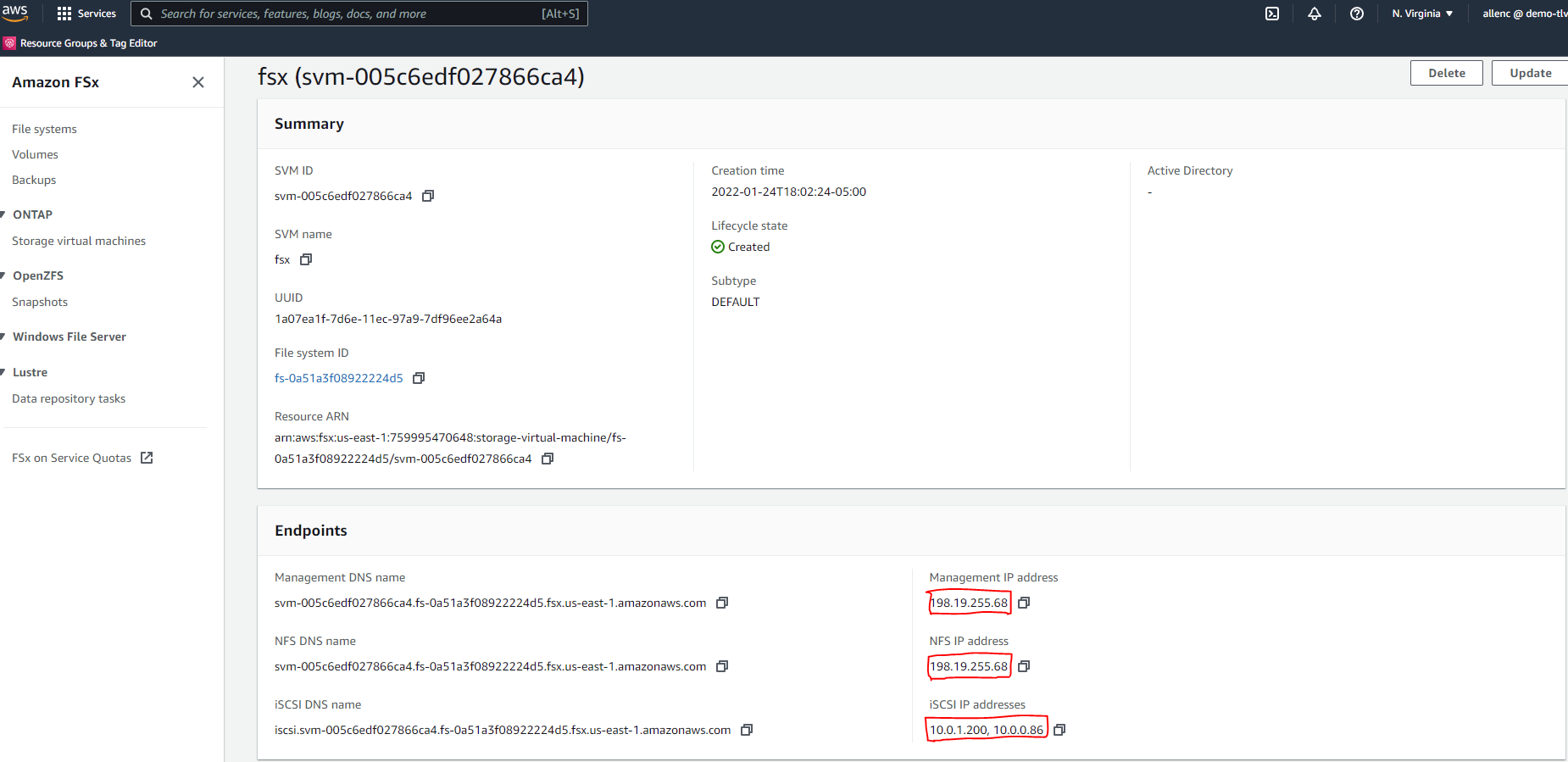
Veja os procedimentos passo a passo a seguir para configurar um cluster HA FSx primário ou em espera.
-
No console do FSx, clique em Criar sistema de arquivos para iniciar o fluxo de trabalho de provisionamento do FSx.
-
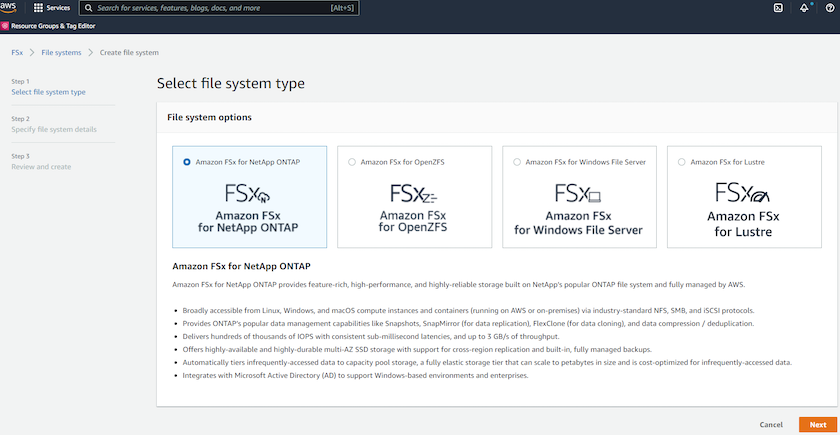
Selecione Amazon FSx ONTAP. Em seguida, clique em Avançar.
-
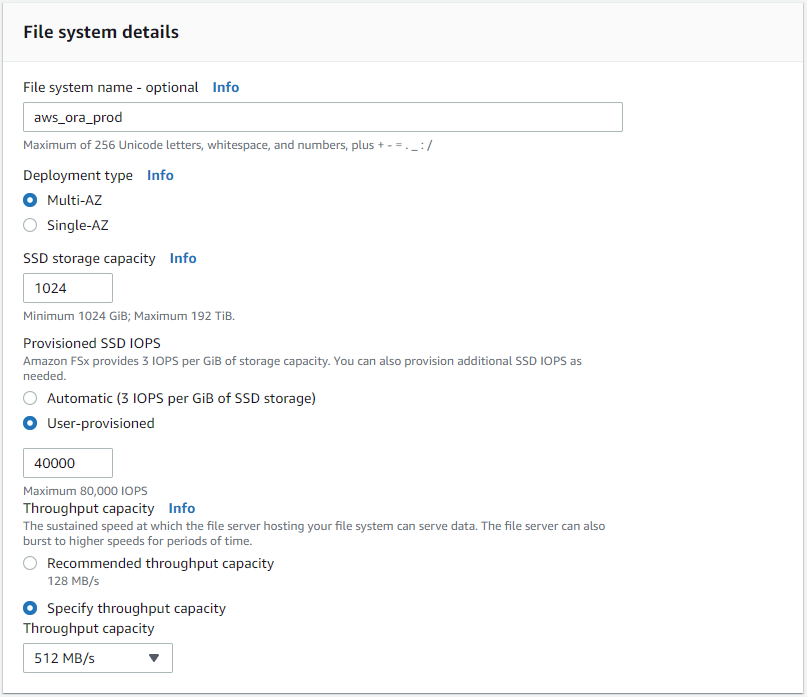
Selecione Criação Padrão e, em Detalhes do Sistema de Arquivos, nomeie seu sistema de arquivos como Multi-AZ HA. Com base na carga de trabalho do seu banco de dados, escolha IOPS automático ou provisionado pelo usuário até 80.000 IOPS SSD. O armazenamento FSx vem com cache NVMe de até 2 TiB no backend, o que pode fornecer IOPS medidos ainda mais altos.
-
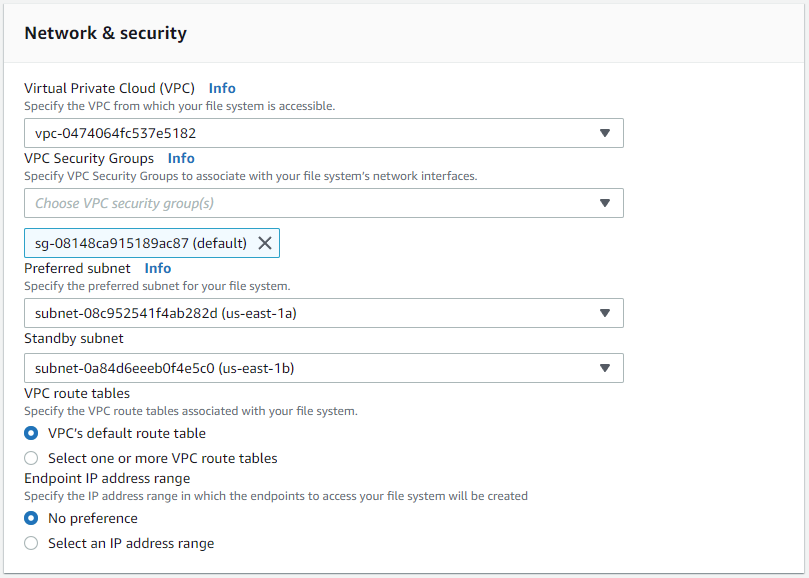
Na seção Rede e segurança, selecione a VPC, o grupo de segurança e as sub-redes. Eles devem ser criados antes da implantação do FSx. Com base na função do cluster FSx (primário ou em espera), coloque os nós de armazenamento FSx nas zonas apropriadas.
-
Na seção Segurança e Criptografia, aceite o padrão e digite a senha fsxadmin.
-
Digite o nome do SVM e a senha vsadmin.
-
Deixe a configuração do volume em branco; você não precisa criar um volume neste momento.
-
Revise a página Resumo e clique em Criar sistema de arquivos para concluir o provisionamento do sistema de arquivos FSx.
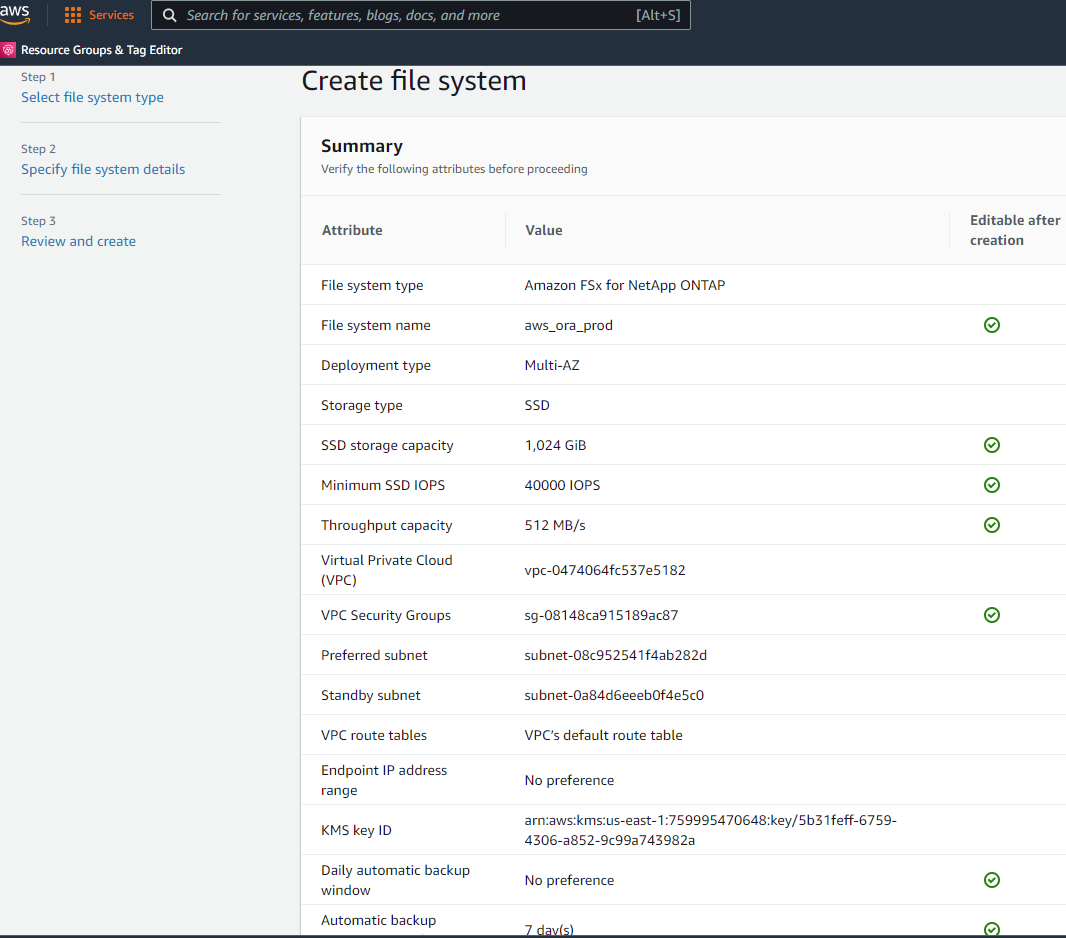
Provisionamento de volumes de banco de dados para banco de dados Oracle
Ver"Gerenciando volumes FSx ONTAP - criando um volume" para mais detalhes.
Considerações principais:
-
Dimensionar adequadamente os volumes do banco de dados.
-
Desabilitando a política de níveis do pool de capacidade para configuração de desempenho.
-
Habilitando o Oracle dNFS para volumes de armazenamento NFS.
-
Configurando multicaminhos para volumes de armazenamento iSCSI.
Criar volume de banco de dados a partir do console FSx
No console do AWS FSx, você pode criar três volumes para armazenamento de arquivos de banco de dados Oracle: um para o binário Oracle, um para os dados Oracle e um para o log Oracle. Certifique-se de que a nomenclatura do volume corresponda ao nome do host Oracle (definido no arquivo hosts no kit de ferramentas de automação) para uma identificação adequada. Neste exemplo, usamos db1 como o nome do host Oracle do EC2 em vez de um nome de host típico baseado em endereço IP para uma instância do EC2.
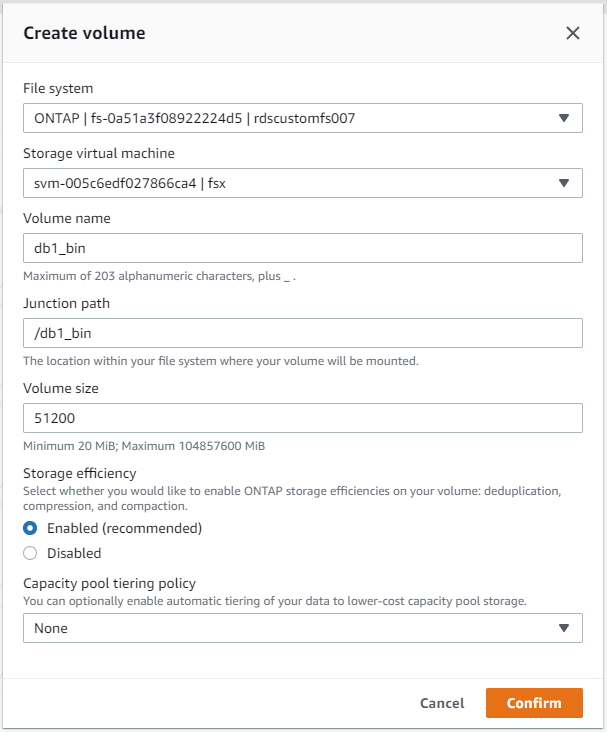
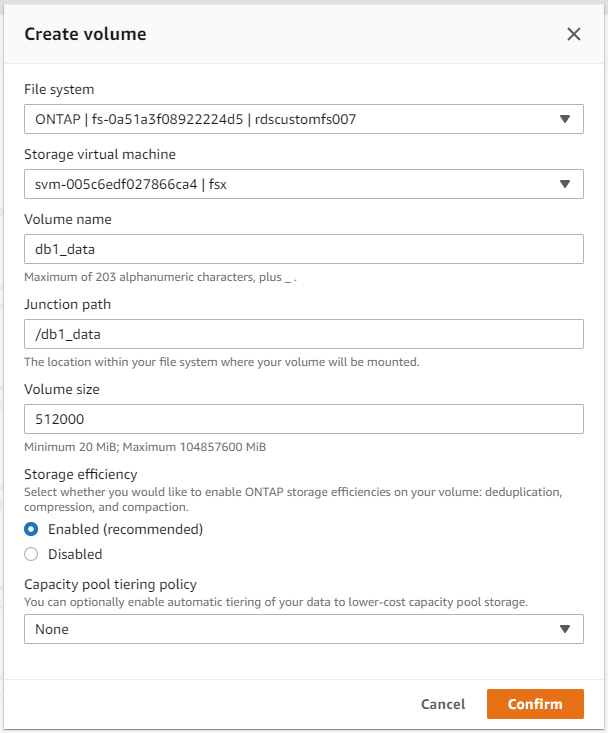
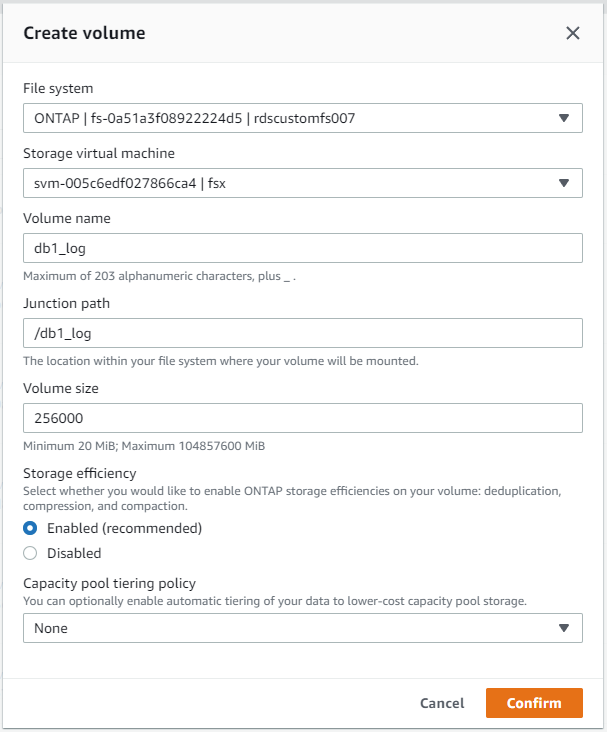

|
A criação de LUNs iSCSI não é suportada atualmente pelo console FSx. Para implantação de LUNs iSCSI para Oracle, os volumes e LUNs podem ser criados usando a automação para ONTAP com o NetApp Automation Toolkit. |
Instalar e configurar o Oracle em uma instância EC2 com volumes de banco de dados FSx
A equipe de automação da NetApp fornece um kit de automação para executar a instalação e a configuração do Oracle em instâncias do EC2 de acordo com as práticas recomendadas. A versão atual do kit de automação oferece suporte ao Oracle 19c no NFS com o patch RU padrão 19.8. O kit de automação pode ser facilmente adaptado para outros patches RU, se necessário.
Preparar um controlador Ansible para executar a automação
Siga as instruções na seção "Criação e conexão a uma instância EC2 para hospedar banco de dados Oracle "para provisionar uma pequena instância do EC2 Linux para executar o controlador Ansible. Em vez de usar RedHat, o Amazon Linux t2.large com 2vCPU e 8G RAM deve ser suficiente.
Recuperar o kit de ferramentas de automação de implantação do NetApp Oracle
Faça login na instância do controlador EC2 Ansible provisionada na etapa 1 como ec2-user e, no diretório inicial do ec2-user, execute o comando git clone comando para clonar uma cópia do código de automação.
git clone https://github.com/NetApp-Automation/na_oracle19c_deploy.gitgit clone https://github.com/NetApp-Automation/na_rds_fsx_oranfs_config.gitExecute a implantação automatizada do Oracle 19c usando o kit de ferramentas de automação
Veja estas instruções detalhadas"Implantação CLI do banco de dados Oracle 19c" para implantar o Oracle 19c com automação CLI. Há uma pequena alteração na sintaxe do comando para execução do playbook porque você está usando um par de chaves SSH em vez de uma senha para autenticação de acesso ao host. A lista a seguir é um resumo de alto nível:
-
Por padrão, uma instância EC2 usa um par de chaves SSH para autenticação de acesso. Dos diretórios raiz de automação do controlador Ansible
/home/ec2-user/na_oracle19c_deploy, e/home/ec2-user/na_rds_fsx_oranfs_config, faça uma cópia da chave SSHaccesststkey.pempara o host Oracle implantado na etapa "Criação e conexão a uma instância EC2 para hospedar banco de dados Oracle ." -
Efetue login no host do banco de dados da instância EC2 como ec2-user e instale a biblioteca python3.
sudo yum install python3 -
Crie um espaço de swap de 16 G a partir da unidade de disco raiz. Por padrão, uma instância EC2 cria zero espaço de swap. Siga esta documentação da AWS:"Como aloco memória para funcionar como espaço de swap em uma instância do Amazon EC2 usando um arquivo de swap?" .
-
Retornar ao controlador Ansible(
cd /home/ec2-user/na_rds_fsx_oranfs_config) e executar o manual de pré-clone com os requisitos apropriados elinux_configetiquetas.ansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t requirements_configansible-playbook -i hosts rds_preclone_config.yml -u ec2-user --private-key accesststkey.pem -e @vars/fsx_vars.yml -t linux_config -
Mudar para o
/home/ec2-user/na_oracle19c_deploy-masterdiretório, leia o arquivo README e preencha o globalvars.ymlarquivo com os parâmetros globais relevantes. -
Preencher o
host_name.ymlarquivo com os parâmetros relevantes nohost_varsdiretório. -
Execute o manual para Linux e pressione Enter quando for solicitada a senha vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t linux_config -e @vars/vars.yml -
Execute o playbook do Oracle e pressione Enter quando solicitado a senha vsadmin.
ansible-playbook -i hosts all_playbook.yml -u ec2-user --private-key accesststkey.pem -t oracle_config -e @vars/vars.yml
Altere o bit de permissão no arquivo de chave SSH para 400, se necessário. Alterar o host Oracle(ansible_host no host_vars arquivo) endereço IP para o endereço público da sua instância EC2.
Configurando o SnapMirror entre o cluster FSx HA primário e o de espera
Para alta disponibilidade e recuperação de desastres, você pode configurar a replicação do SnapMirror entre o cluster de armazenamento FSx primário e em espera. Diferentemente de outros serviços de armazenamento em nuvem, o FSx permite que um usuário controle e gerencie a replicação do armazenamento na frequência e na taxa de transferência de replicação desejadas. Ele também permite que os usuários testem HA/DR sem qualquer efeito na disponibilidade.
As etapas a seguir mostram como configurar a replicação entre um cluster de armazenamento FSx primário e em espera.
-
Configurar peering de cluster primário e de espera. Efetue login no cluster primário como usuário fsxadmin e execute o seguinte comando. Esse processo de criação recíproca executa o comando create no cluster primário e no cluster de espera. Substituir
standby_cluster_namecom o nome apropriado para seu ambiente.cluster peer create -peer-addrs standby_cluster_name,inter_cluster_ip_address -username fsxadmin -initial-allowed-vserver-peers * -
Configure o peering do vServer entre o cluster primário e o cluster em espera. Efetue login no cluster primário como usuário vsadmin e execute o seguinte comando. Substituir
primary_vserver_name,standby_vserver_name,standby_cluster_namecom os nomes apropriados para seu ambiente.vserver peer create -vserver primary_vserver_name -peer-vserver standby_vserver_name -peer-cluster standby_cluster_name -applications snapmirror -
Verifique se os peerings do cluster e do vserver estão configurados corretamente.
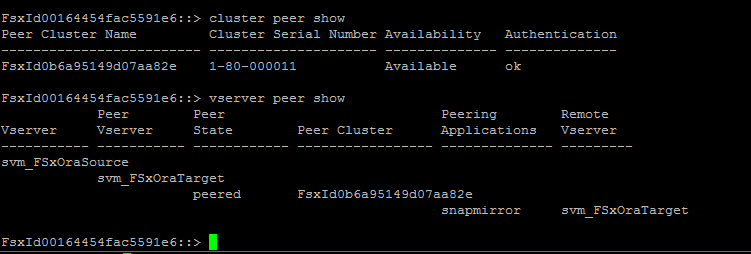
-
Crie volumes NFS de destino no cluster FSx em espera para cada volume de origem no cluster FSx primário. Substitua o nome do volume conforme apropriado para seu ambiente.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -type DPvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -type DPvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -type DP -
Você também pode criar volumes iSCSI e LUNs para o binário Oracle, dados Oracle e o log Oracle se o protocolo iSCSI for empregado para acesso a dados. Deixe aproximadamente 10% de espaço livre nos volumes para instantâneos.
vol create -volume dr_db1_bin -aggregate aggr1 -size 50G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_bin/dr_db1_bin_01 -size 45G -ostype linuxvol create -volume dr_db1_data -aggregate aggr1 -size 500G -state online -policy default -unix-permissions ---rwxr-xr-x -type RWlun create -path /vol/dr_db1_data/dr_db1_data_01 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_02 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_03 -size 100G -ostype linuxlun create -path /vol/dr_db1_data/dr_db1_data_04 -size 100G -ostype linuxvol create -volume dr_db1_log -aggregate aggr1 -size 250G -state online -policy default -unix-permissions ---rwxr-xr-x -type RW
lun create -path /vol/dr_db1_log/dr_db1_log_01 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_02 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_03 -size 45G -ostype linuxlun create -path /vol/dr_db1_log/dr_db1_log_04 -size 45G -ostype linux -
Para LUNs iSCSI, crie um mapeamento para o iniciador do host Oracle para cada LUN, usando o LUN binário como exemplo. Substitua o igroup por um nome apropriado para seu ambiente e incremente o lun-id para cada LUN adicional.
lun mapping create -path /vol/dr_db1_bin/dr_db1_bin_01 -igroup ip-10-0-1-136 -lun-id 0lun mapping create -path /vol/dr_db1_data/dr_db1_data_01 -igroup ip-10-0-1-136 -lun-id 1 -
Crie um relacionamento SnapMirror entre os volumes do banco de dados primário e de espera. Substitua o nome SVM apropriado para seu ambiente.
snapmirror create -source-path svm_FSxOraSource:db1_bin -destination-path svm_FSxOraTarget:dr_db1_bin -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_data -destination-path svm_FSxOraTarget:dr_db1_data -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DPsnapmirror create -source-path svm_FSxOraSource:db1_log -destination-path svm_FSxOraTarget:dr_db1_log -vserver svm_FSxOraTarget -throttle unlimited -identity-preserve false -policy MirrorAllSnapshots -type DP
Esta configuração do SnapMirror pode ser automatizada com um NetApp Automation Toolkit para volumes de banco de dados NFS. O kit de ferramentas está disponível para download no site público do GitHub da NetApp .
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitLeia atentamente as instruções do README antes de tentar a configuração e o teste de failover.
|
|
Replicar o binário Oracle do cluster primário para um cluster de espera pode ter implicações na licença do Oracle. Entre em contato com seu representante de licenças da Oracle para obter esclarecimentos. A alternativa é ter o Oracle instalado e configurado no momento da recuperação e do failover. |
Implantação do SnapCenter
Instalação do SnapCenter
Seguir"Instalando o SnapCenter Server" para instalar o servidor SnapCenter . Esta documentação aborda como instalar um servidor SnapCenter autônomo. Uma versão SaaS do SnapCenter está em análise beta e poderá estar disponível em breve. Verifique com seu representante da NetApp a disponibilidade, se necessário.
Configurar o plugin SnapCenter para o host EC2 Oracle
-
Após a instalação automatizada do SnapCenter , efetue login no SnapCenter como usuário administrativo para o host do Windows no qual o servidor SnapCenter está instalado.

-
No menu do lado esquerdo, clique em Configurações, depois em Credencial e Novo para adicionar credenciais de usuário ec2 para instalação do plugin SnapCenter .
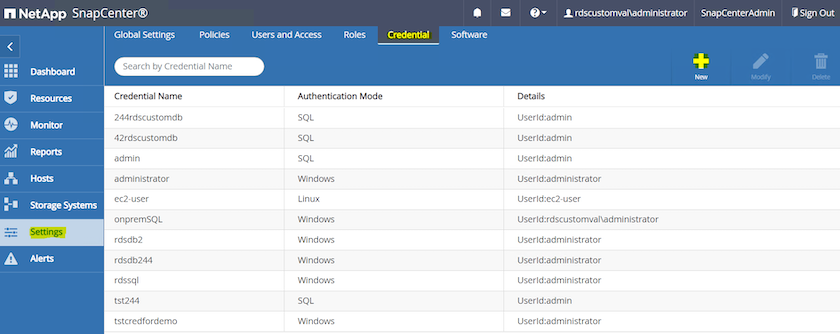
-
Redefina a senha do usuário ec2 e habilite a autenticação SSH por senha editando o
/etc/ssh/sshd_configarquivo no host da instância EC2. -
Verifique se a caixa de seleção "Usar privilégios sudo" está marcada. Você acabou de redefinir a senha do usuário ec2 na etapa anterior.
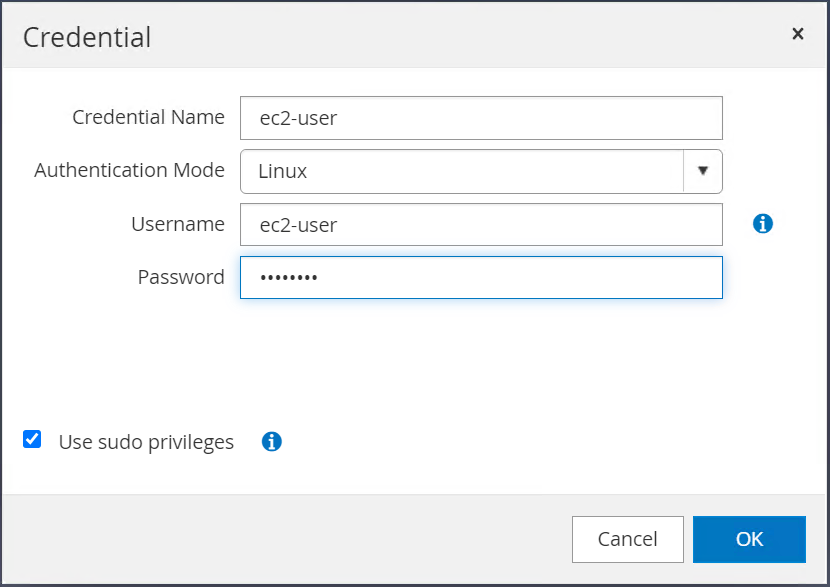
-
Adicione o nome do servidor SnapCenter e o endereço IP ao arquivo de host da instância EC2 para resolução de nomes.
[ec2-user@ip-10-0-0-151 ~]$ sudo vi /etc/hosts [ec2-user@ip-10-0-0-151 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 10.0.1.233 rdscustomvalsc.rdscustomval.com rdscustomvalsc
-
No host do Windows do servidor SnapCenter , adicione o endereço IP do host da instância EC2 ao arquivo do host do Windows
C:\Windows\System32\drivers\etc\hosts.10.0.0.151 ip-10-0-0-151.ec2.internal
-
No menu do lado esquerdo, selecione Hosts > Hosts gerenciados e clique em Adicionar para adicionar o host da instância EC2 ao SnapCenter.
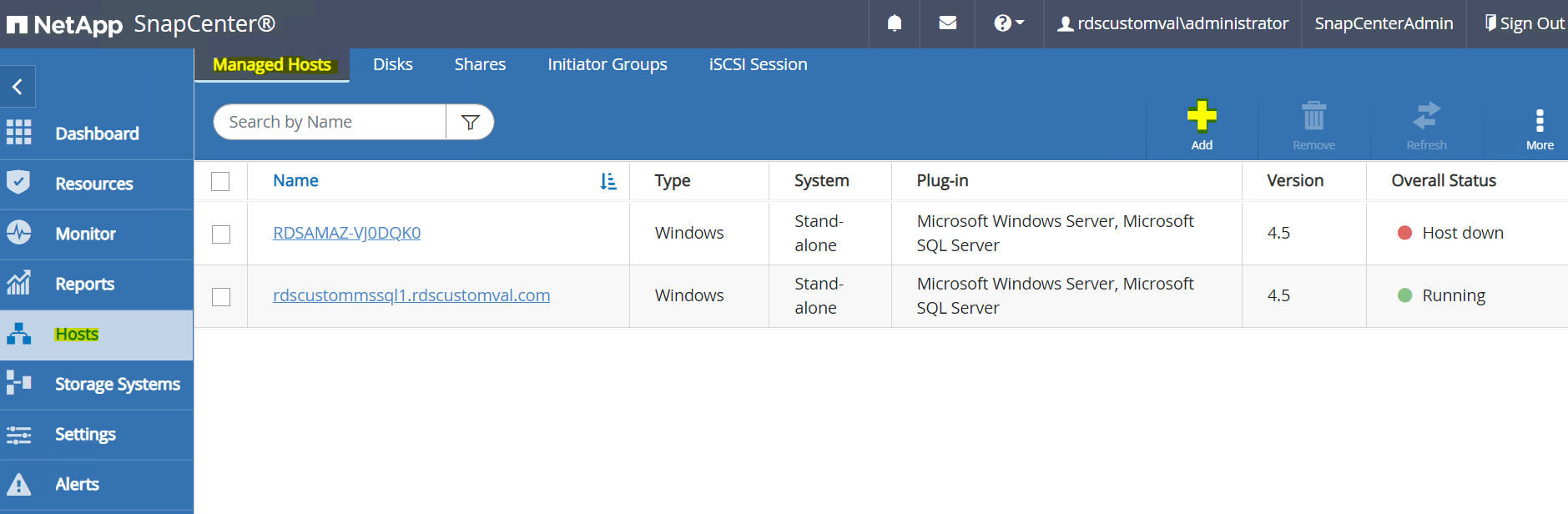
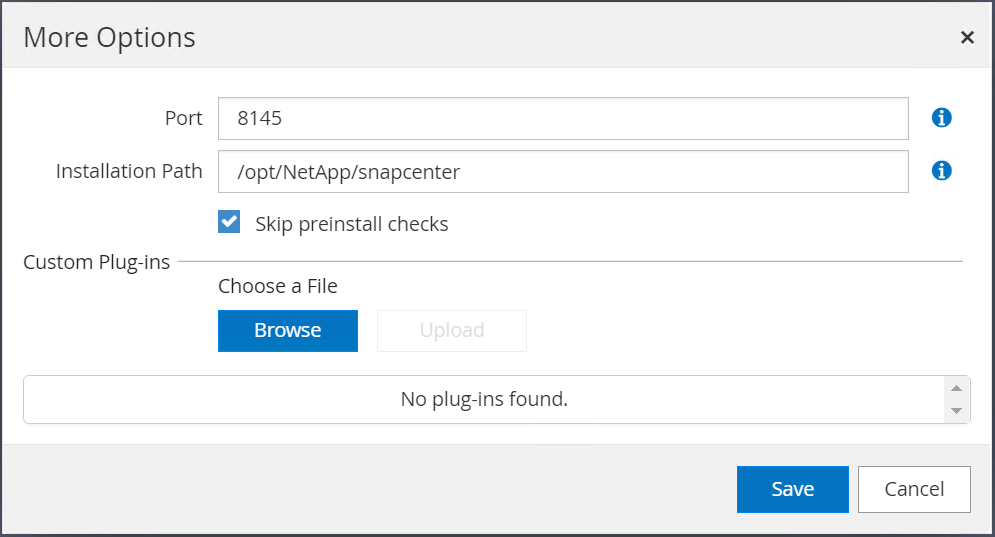
Verifique o Oracle Database e, antes de enviar, clique em Mais opções.
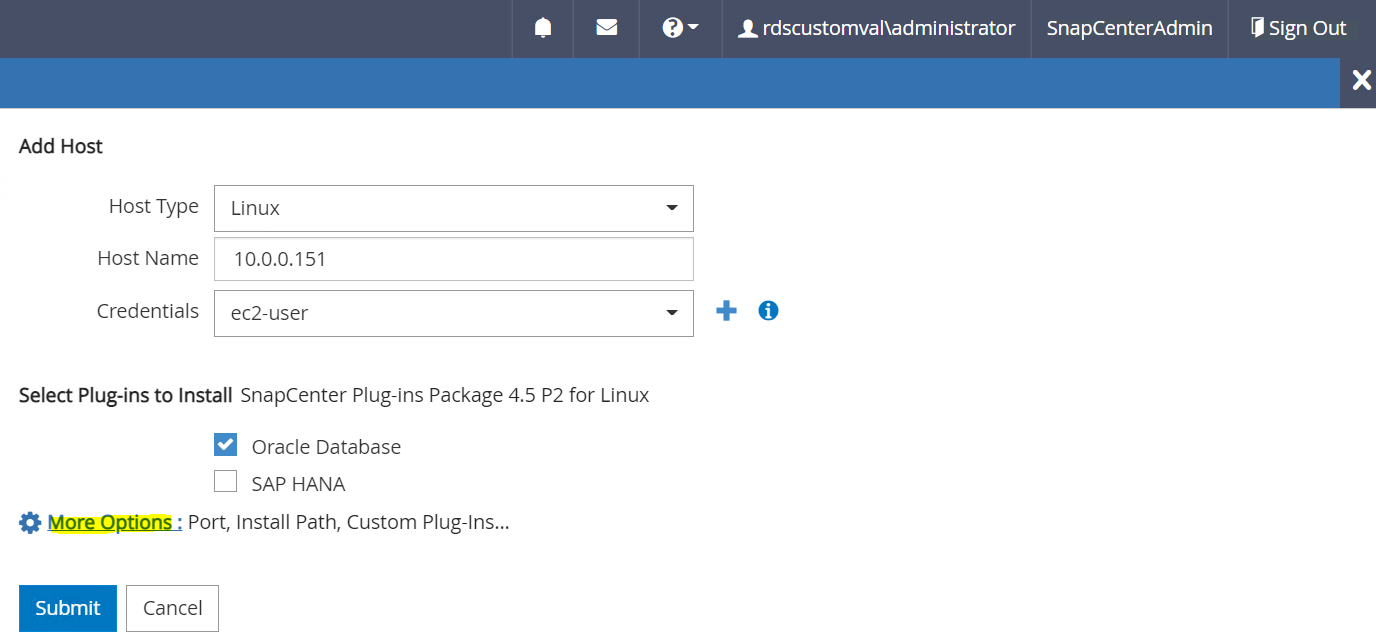
Marque Ignorar verificações de pré-instalação. Confirme a opção Ignorar verificações de pré-instalação e clique em Enviar após salvar.
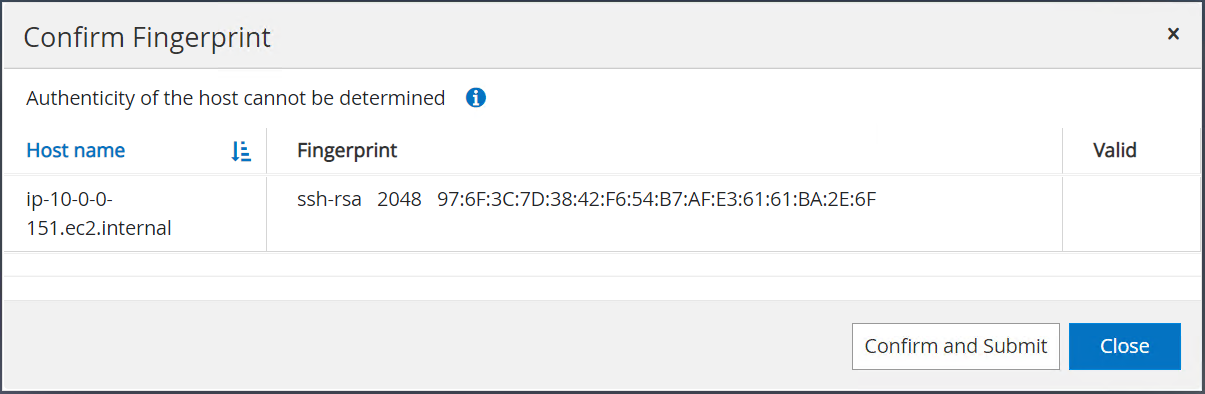
Você será solicitado a confirmar impressão digital e, em seguida, clicar em Confirmar e enviar.
Após a configuração bem-sucedida do plugin, o status geral do host gerenciado será exibido como Em execução.

Configurar política de backup para banco de dados Oracle
Consulte esta seção"Configurar política de backup de banco de dados no SnapCenter" para obter detalhes sobre como configurar a política de backup do banco de dados Oracle.
Geralmente, você precisa criar uma política para o backup completo do banco de dados Oracle e uma política para o backup do snapshot somente do log de arquivamento do Oracle.
|
|
Você pode habilitar a remoção de log de arquivamento do Oracle na política de backup para controlar o espaço de arquivamento de log. Marque "Atualizar SnapMirror após criar uma cópia local do Snapshot" em "Selecionar opção de replicação secundária", pois você precisa replicar para um local de espera para HA ou DR. |
Configurar backup e agendamento do banco de dados Oracle
O backup do banco de dados no SnapCenter é configurável pelo usuário e pode ser configurado individualmente ou em grupo em um grupo de recursos. O intervalo de backup depende dos objetivos do RTO e do RPO. A NetApp recomenda que você execute um backup completo do banco de dados a cada poucas horas e arquive o backup do log com uma frequência maior, como 10 a 15 minutos para recuperação rápida.
Consulte a seção Oracle de"Implementar política de backup para proteger o banco de dados" para obter processos detalhados passo a passo para implementar a política de backup criada na seçãoConfigurar política de backup para banco de dados Oracle e para agendamento de tarefas de backup.
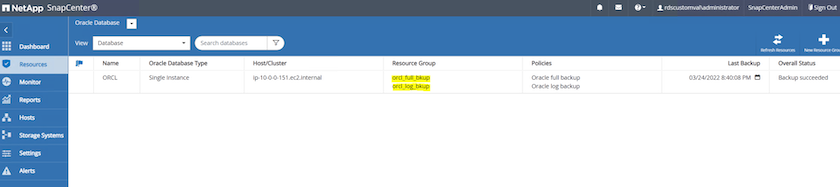
A imagem a seguir fornece um exemplo dos grupos de recursos configurados para fazer backup de um banco de dados Oracle.