

TR-4998: Oracle HA no AWS EC2 com Pacemaker Clustering e FSx ONTAP
 Sugerir alterações
Sugerir alterações
Allen Cao, Niyaz Mohamed, NetApp
Esta solução fornece uma visão geral e detalhes para habilitar a alta disponibilidade (HA) do Oracle no AWS EC2 com clustering do Pacemaker no Redhat Enterprise Linux (RHEL) e no Amazon FSx ONTAP para o armazenamento de banco de dados HA via protocolo NFS.
Propósito
Muitos clientes que se esforçam para autogerenciar e executar o Oracle na nuvem pública precisam superar alguns desafios. Um desses desafios é permitir alta disponibilidade para o banco de dados Oracle. Tradicionalmente, os clientes da Oracle contam com um recurso do banco de dados Oracle chamado "Real Application Cluster" ou RAC para suporte a transações ativas em vários nós do cluster. Um nó com falha não interromperia o processamento do aplicativo. Infelizmente, a implementação do Oracle RAC não está prontamente disponível ou não tem suporte em muitas nuvens públicas populares, como o AWS EC2. Ao aproveitar o clustering Pacemaker (PCS) integrado no RHEL e no Amazon FSx ONTAP, os clientes podem obter uma alternativa viável sem custo de licença do Oracle RAC para clustering ativo-passivo em computação e armazenamento para dar suporte à carga de trabalho de banco de dados Oracle de missão crítica na nuvem AWS.
Esta documentação demonstra os detalhes da configuração do cluster do Pacemaker no RHEL, da implantação do banco de dados Oracle no EC2 e do Amazon FSx ONTAP com protocolo NFS, da configuração de recursos Oracle no Pacemaker para HA e da conclusão da demonstração com validação nos cenários de HA mais frequentemente encontrados. A solução também fornece informações sobre backup rápido, restauração e clonagem de banco de dados Oracle com a ferramenta NetApp SnapCenter UI.
Esta solução aborda os seguintes casos de uso:
-
Configuração e configuração de cluster do Pacemaker HA no RHEL.
-
Implantação de HA de banco de dados Oracle no AWS EC2 e Amazon FSx ONTAP.
Público
Esta solução é destinada às seguintes pessoas:
-
Um DBA que gostaria de implantar o Oracle no AWS EC2 e no Amazon FSx ONTAP.
-
Um arquiteto de soluções de banco de dados que gostaria de testar cargas de trabalho Oracle no AWS EC2 e no Amazon FSx ONTAP.
-
Um administrador de armazenamento que gostaria de implantar e gerenciar um banco de dados Oracle no AWS EC2 e no Amazon FSx ONTAP.
-
Um proprietário de aplicativo que gostaria de configurar um banco de dados Oracle no AWS EC2 e no Amazon FSx ONTAP.
Ambiente de teste e validação de soluções
Os testes e a validação desta solução foram realizados em um ambiente de laboratório que pode não corresponder ao ambiente de implantação final. Veja a seçãoFatores-chave para consideração de implantação para maiores informações.
Arquitetura
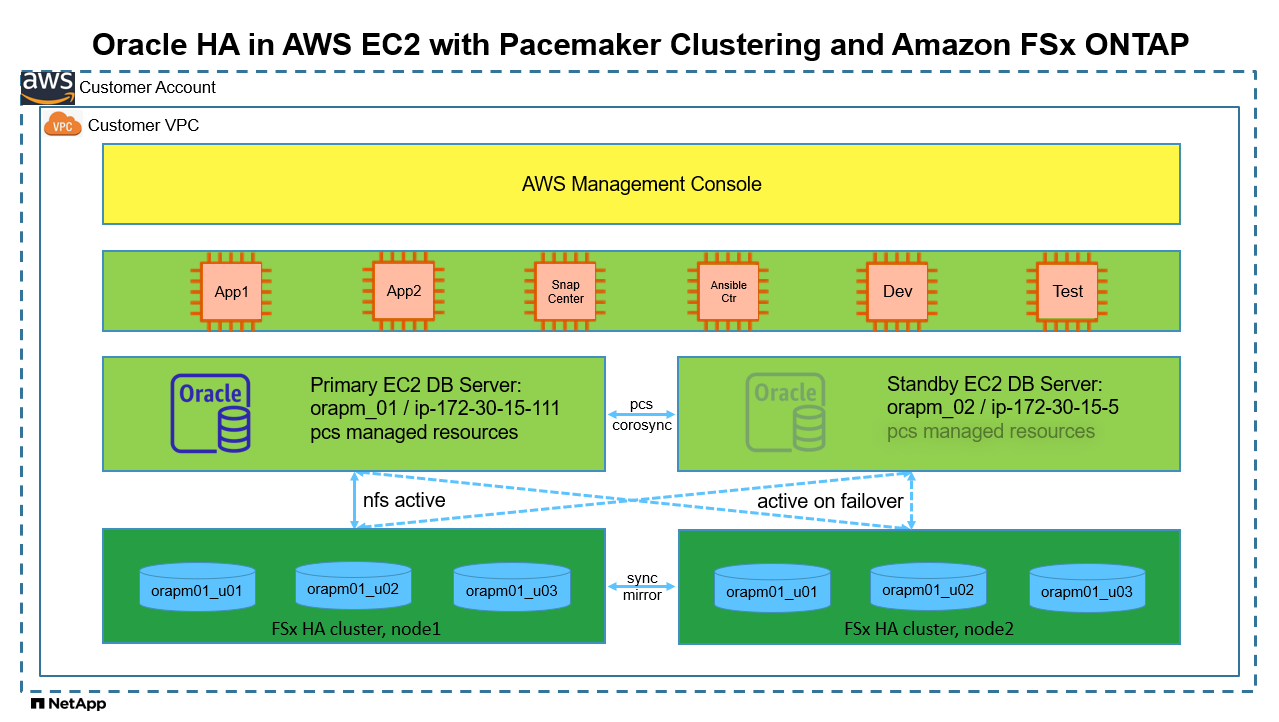
Componentes de hardware e software
Hardware |
||
Armazenamento Amazon FSx ONTAP |
Versão atual oferecida pela AWS |
Single-AZ em us-east-1, capacidade de 1024 GiB, taxa de transferência de 128 MB/s |
Instâncias EC2 para servidor de banco de dados |
t2.xlarge/4vCPU/16G |
Duas instâncias EC2 T2 xlarge EC2, uma como servidor de banco de dados primário e a outra como servidor de banco de dados de espera |
VM para controlador Ansible |
4 vCPUs, 16 GiB de RAM |
Uma VM Linux para executar provisionamento automatizado AWS EC2/FSx e implantação Oracle no NFS |
Software |
||
RedHat Linux |
RHEL Linux 8.6 (LVM) - x64 Gen2 |
Assinatura RedHat implantada para teste |
Banco de Dados Oracle |
Versão 19.18 |
Patch RU aplicado p34765931_190000_Linux-x86-64.zip |
Oracle OPatch |
Versão 12.2.0.1.36 |
Último patch p6880880_190000_Linux-x86-64.zip |
Marcapasso |
Versão 0.10.18 |
Complemento de alta disponibilidade para RHEL 8.0 da RedHat |
NFS |
Versão 3.0 |
Oracle dNFS habilitado |
Ansible |
núcleo 2.16.2 |
Python 3.6.8 |
Configuração ativa/passiva do banco de dados Oracle no ambiente de laboratório AWS EC2/FSx
Servidor |
Banco de dados |
Armazenamento de banco de dados |
nó primário: orapm01/ip-172.30.15.111 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) |
/u01, /u02, /u03 Montagens NFS em volumes Amazon FSx ONTAP |
nó de espera: orapm02/ip-172.30.15.5 |
NTAP(NTAP_PDB1,NTAP_PDB2,NTAP_PDB3) quando failover |
/u01, /u02, /u03 NFS monta quando failover |
Fatores-chave para consideração de implantação
-
* Amazon FSx ONTAP HA.* O Amazon FSx ONTAP é provisionado em um par HA de controladores de armazenamento em uma ou várias zonas de disponibilidade por padrão. Ele fornece redundância de armazenamento de forma ativa/passiva para cargas de trabalho de banco de dados de missão crítica. O failover de armazenamento é transparente para o usuário final. A intervenção do usuário não é necessária em caso de failover de armazenamento.
-
Grupo de recursos do PCS e ordenação de recursos. Um grupo de recursos permite que vários recursos com dependência sejam executados no mesmo nó do cluster. A ordem dos recursos impõe a ordem de inicialização dos recursos e a ordem de desligamento ao contrário.
-
Nó preferido. O cluster Pacemaker é implantado propositalmente em clustering ativo/passivo (não é um requisito do Pacemaker) e está sincronizado com o clustering FSx ONTAP . A instância ativa do EC2 é configurada como um nó preferencial para recursos Oracle quando disponível com uma restrição de localização.
-
Atraso de cerca no nó de espera. Em um cluster PCS de dois nós, o quorum é definido artificialmente como 1. No caso de um problema de comunicação entre os nós do cluster, qualquer um dos nós pode tentar isolar o outro, o que pode causar corrupção de dados. Configurar um atraso no nó em espera atenua o problema e permite que o nó primário continue fornecendo serviços enquanto o nó em espera está cercado.
-
Consideração de implantação de múltiplas infraestruturas. A solução é implantada e validada em uma única zona de disponibilidade. Para implantação multi-az, recursos de rede AWS adicionais são necessários para mover o IP flutuante do PCS entre as zonas de disponibilidade.
-
Layout de armazenamento do banco de dados Oracle. Nesta demonstração de solução, provisionamos três volumes de banco de dados para o banco de dados de teste NTAP para hospedar binários, dados e log do Oracle. Os volumes são montados no servidor Oracle DB como /u01 - binário, /u02 - dados e /u03 - log via NFS. Arquivos de controle duplo são configurados nos pontos de montagem /u02 e /u03 para redundância.
-
configuração dNFS. Ao usar o dNFS (disponível desde o Oracle 11g), um banco de dados Oracle em execução em uma VM de banco de dados pode gerar significativamente mais E/S do que o cliente NFS nativo. A implantação automatizada do Oracle configura o dNFS no NFSv3 por padrão.
-
Backup de banco de dados. A NetApp fornece um pacote de SnapCenter software para backup, restauração e clonagem de banco de dados com uma interface de usuário amigável. A NetApp recomenda implementar uma ferramenta de gerenciamento para obter backups rápidos (menos de um minuto) de snapshots, restaurações rápidas (minutos) de bancos de dados e clonagens de bancos de dados.
Implantação da solução
As seções a seguir fornecem procedimentos passo a passo para implantação e configuração do Oracle Database HA no AWS EC2 com clustering do Pacemaker e Amazon FSx ONTAP para proteção de armazenamento de banco de dados.
Pré-requisitos para implantação
Details
A implantação requer os seguintes pré-requisitos.
-
Uma conta da AWS foi configurada e os segmentos de VPC e rede necessários foram criados dentro da sua conta da AWS.
-
Provisione uma VM Linux como o nó do controlador Ansible com a versão mais recente do Ansible e do Git instalada. Consulte o link a seguir para obter detalhes:"Introdução à automação de soluções da NetApp " na seção -
Setup the Ansible Control Node for CLI deployments on RHEL / CentOSou
Setup the Ansible Control Node for CLI deployments on Ubuntu / Debian.Habilite a autenticação de chave pública/privada SSH entre o controlador Ansible e as VMs do banco de dados da instância EC2.
Provisionar instâncias do EC2 e cluster de armazenamento Amazon FSx ONTAP
Details
Embora a instância do EC2 e o Amazon FSx ONTAP possam ser provisionados manualmente no console da AWS, é recomendável usar o kit de ferramentas de automação baseado no NetApp Terraform para automatizar o provisionamento de instâncias do EC2 e do cluster de armazenamento do FSx ONTAP . A seguir estão os procedimentos detalhados.
-
No AWS CloudShell ou na VM do controlador Ansible, clone uma cópia do kit de ferramentas de automação para EC2 e FSx ONTAP.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_aws_fsx_ec2_deploy.git
Se o kit de ferramentas não for executado no AWS CloudShell, a autenticação da AWS CLI será necessária com sua conta da AWS usando o par de chaves secretas/acesso à conta de usuário da AWS. -
Revise o arquivo READme.md incluído no kit de ferramentas. Revise main.tf e os arquivos de parâmetros associados conforme necessário para os recursos da AWS necessários.
An example of main.tf: resource "aws_instance" "orapm01" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag1 } } resource "aws_instance" "orapm02" { ami = var.ami instance_type = var.instance_type subnet_id = var.subnet_id key_name = var.ssh_key_name root_block_device { volume_type = "gp3" volume_size = var.root_volume_size } tags = { Name = var.ec2_tag2 } } resource "aws_fsx_ontap_file_system" "fsx_01" { storage_capacity = var.fs_capacity subnet_ids = var.subnet_ids preferred_subnet_id = var.preferred_subnet_id throughput_capacity = var.fs_throughput fsx_admin_password = var.fsxadmin_password deployment_type = var.deployment_type disk_iops_configuration { iops = var.iops mode = var.iops_mode } tags = { Name = var.fsx_tag } } resource "aws_fsx_ontap_storage_virtual_machine" "svm_01" { file_system_id = aws_fsx_ontap_file_system.fsx_01.id name = var.svm_name svm_admin_password = var.vsadmin_password } -
Valide e execute o plano do Terraform. Uma execução bem-sucedida criaria duas instâncias do EC2 e um cluster de armazenamento FSx ONTAP na conta AWS de destino. A saída de automação exibe o endereço IP da instância EC2 e os pontos de extremidade do cluster FSx ONTAP .
terraform plan -out=main.planterraform apply main.plan
Isso conclui as instâncias do EC2 e o provisionamento do FSx ONTAP para Oracle.
Configuração do cluster do marcapasso
Details
O High Availability Add-On para RHEL é um sistema em cluster que fornece confiabilidade, escalabilidade e disponibilidade para serviços de produção críticos, como serviços de banco de dados Oracle. Nesta demonstração de caso de uso, um cluster Pacemaker de dois nós é configurado para oferecer suporte à alta disponibilidade de um banco de dados Oracle em um cenário de clustering ativo/passivo.
Efetue login nas instâncias do EC2, como usuário ec2, conclua as seguintes tarefas em both Instâncias EC2:
-
Remova o cliente AWS Red Hat Update Infrastructure (RHUI).
sudo -i yum -y remove rh-amazon-rhui-client* -
Registre as VMs da instância do EC2 com o Red Hat.
sudo subscription-manager register --username xxxxxxxx --password 'xxxxxxxx' --auto-attach -
Habilitar rpms de alta disponibilidade do RHEL.
sudo subscription-manager config --rhsm.manage_repos=1sudo subscription-manager repos --enable=rhel-8-for-x86_64-highavailability-rpms -
Instalar marcapasso e cerca anti-retorno.
sudo yum update -ysudo yum install pcs pacemaker fence-agents-aws -
Crie uma senha para o usuário hacluster em todos os nós do cluster. Use a mesma senha para todos os nós.
sudo passwd hacluster -
Inicie o serviço pcs e habilite-o para iniciar na inicialização.
sudo systemctl start pcsd.servicesudo systemctl enable pcsd.service -
Validar serviço pcsd.
sudo systemctl status pcsd[ec2-user@ip-172-30-15-5 ~]$ sudo systemctl status pcsd ● pcsd.service - PCS GUI and remote configuration interface Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2024-09-10 18:50:22 UTC; 33s ago Docs: man:pcsd(8) man:pcs(8) Main PID: 65302 (pcsd) Tasks: 1 (limit: 100849) Memory: 24.0M CGroup: /system.slice/pcsd.service └─65302 /usr/libexec/platform-python -Es /usr/sbin/pcsd Sep 10 18:50:21 ip-172-30-15-5.ec2.internal systemd[1]: Starting PCS GUI and remote configuration interface... Sep 10 18:50:22 ip-172-30-15-5.ec2.internal systemd[1]: Started PCS GUI and remote configuration interface. -
Adicione nós de cluster aos arquivos do host.
sudo vi /etc/hosts[ec2-user@ip-172-30-15-5 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 # cluster nodes 172.30.15.111 ip-172-30-15-111.ec2.internal 172.30.15.5 ip-172-30-15-5.ec2.internal
-
Instale e configure o awscli para conectividade com a conta AWS.
sudo yum install awsclisudo aws configure[ec2-user@ip-172-30-15-111 ]# sudo aws configure AWS Access Key ID [None]: XXXXXXXXXXXXXXXXX AWS Secret Access Key [None]: XXXXXXXXXXXXXXXX Default region name [None]: us-east-1 Default output format [None]: json
-
Instale o pacote resource-agents se ainda não estiver instalado.
sudo yum install resource-agents
Sobre only one do nó do cluster, conclua as seguintes tarefas para criar o cluster de pcs.
-
Autentique o usuário pcs hacluster.
sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs host auth ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal Username: hacluster Password: ip-172-30-15-111.ec2.internal: Authorized ip-172-30-15-5.ec2.internal: Authorized
-
Crie o cluster de pcs.
sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster setup ora_ec2nfsx ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal No addresses specified for host 'ip-172-30-15-5.ec2.internal', using 'ip-172-30-15-5.ec2.internal' No addresses specified for host 'ip-172-30-15-111.ec2.internal', using 'ip-172-30-15-111.ec2.internal' Destroying cluster on hosts: 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal'... ip-172-30-15-5.ec2.internal: Successfully destroyed cluster ip-172-30-15-111.ec2.internal: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful removal of the file 'pcsd settings' ip-172-30-15-5.ec2.internal: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-111.ec2.internal: successful distribution of the file 'pacemaker authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync authkey' ip-172-30-15-5.ec2.internal: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'ip-172-30-15-111.ec2.internal', 'ip-172-30-15-5.ec2.internal' ip-172-30-15-111.ec2.internal: successful distribution of the file 'corosync.conf' ip-172-30-15-5.ec2.internal: successful distribution of the file 'corosync.conf' Cluster has been successfully set up.
-
Habilite o cluster.
sudo pcs cluster enable --all[ec2-user@ip-172-30-15-111 ~]$ sudo pcs cluster enable --all ip-172-30-15-5.ec2.internal: Cluster Enabled ip-172-30-15-111.ec2.internal: Cluster Enabled
-
Inicie e valide o cluster.
sudo pcs cluster start --allsudo pcs status[ec2-user@ip-172-30-15-111 ~]$ sudo pcs status Cluster name: ora_ec2nfsx WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 15:43:23 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 15:43:06 2024 by hacluster via hacluster on ip-172-30-15-111.ec2.internal * 2 nodes configured * 0 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Isso conclui a configuração do cluster do Pacemaker e a configuração inicial.
Configuração de vedação do cluster do marcapasso
Details
A configuração de vedação do marcapasso é obrigatória para um cluster de produção. Ele garante que um nó com defeito no seu cluster AWS EC2 seja isolado automaticamente, evitando assim que o nó consuma os recursos do cluster, comprometa a funcionalidade do cluster ou corrompa dados compartilhados. Esta seção demonstra a configuração do fencing de cluster usando o agente de fencing fence_aws.
-
Como usuário root, insira a seguinte consulta de metadados da AWS para obter o ID da instância para cada nó de instância do EC2.
echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id)[root@ip-172-30-15-111 ec2-user]# echo $(curl -s http://169.254.169.254/latest/meta-data/instance-id) i-0d8e7a0028371636f or just get instance-id from AWS EC2 console
-
Digite o seguinte comando para configurar o dispositivo de cerca. Use o comando pcmk_host_map para mapear o nome do host RHEL para o ID da instância. Use a Chave de acesso da AWS e a Chave de acesso secreta da AWS da conta de usuário da AWS que você usou anteriormente para autenticação na AWS.
sudo pcs stonith \ create clusterfence fence_aws access_key=XXXXXXXXXXXXXXXXX secret_key=XXXXXXXXXXXXXXXXXX \ region=us-east-1 pcmk_host_map="ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e" \ power_timeout=240 pcmk_reboot_timeout=480 pcmk_reboot_retries=4 -
Valide a configuração da cerca.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Wed Sep 11 21:17:18 2024 on ip-172-30-15-111.ec2.internal * Last change: Wed Sep 11 21:16:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 1 resource instance configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
-
Defina stonith-action como desativado em vez de reinicializar no nível do cluster.
pcs property set stonith-action=off[root@ip-172-30-15-111 ec2-user]# pcs property config Cluster Properties: cluster-infrastructure: corosync cluster-name: ora_ec2nfsx dc-version: 2.1.7-5.1.el8_10-0f7f88312 have-watchdog: false last-lrm-refresh: 1726257586 stonith-action: off
Com stonith-action definido como desativado, o nó do cluster cercado será desligado inicialmente. Após o período definido em stonith power_timeout (240 segundos), o nó cercado será reinicializado e se juntará novamente ao cluster. -
Defina o atraso da cerca para 10 segundos para o nó em espera.
pcs stonith update clusterfence pcmk_delay_base="ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s"[root@ip-172-30-15-111 ec2-user]# pcs stonith config Resource: clusterfence (class=stonith type=fence_aws) Attributes: clusterfence-instance_attributes access_key=XXXXXXXXXXXXXXXX pcmk_delay_base=ip-172-30-15-111.ec2.internal:0;ip-172-30-15-5.ec2.internal:10s pcmk_host_map=ip-172-30-15-111.ec2.internal:i-0d8e7a0028371636f;ip-172-30-15-5.ec2.internal:i-0bc54b315afb20a2e pcmk_reboot_retries=4 pcmk_reboot_timeout=480 power_timeout=240 region=us-east-1 secret_key=XXXXXXXXXXXXXXXX Operations: monitor: clusterfence-monitor-interval-60s interval=60s
|
|
Executar pcs stonith refresh comando para atualizar o agente de cerca Stonith parado ou limpar ações de recursos Stonith com falha.
|
Implantar banco de dados Oracle no cluster PCS
Details
Recomendamos aproveitar o manual do Ansible fornecido pela NetApp para executar tarefas de instalação e configuração de banco de dados com parâmetros predefinidos no cluster PCS. Para esta implantação automatizada do Oracle, três arquivos de parâmetros definidos pelo usuário precisam de entrada do usuário antes da execução do playbook.
-
hosts - definem alvos nos quais o manual de automação está sendo executado.
-
vars/vars.yml - o arquivo de variável global que define variáveis que se aplicam a todos os destinos.
-
host_vars/host_name.yml - o arquivo de variáveis locais que define variáveis que se aplicam somente a um destino nomeado. No nosso caso de uso, esses são os servidores Oracle DB.
Além desses arquivos de variáveis definidos pelo usuário, há vários arquivos de variáveis padrão que contêm parâmetros padrão que não exigem alterações, a menos que seja necessário. A seguir são mostrados os detalhes da implantação automatizada do Oracle no AWS EC2 e FSx ONTAP em uma configuração de cluster PCS.
-
No diretório inicial do usuário administrador do controlador Ansible, clone uma cópia do kit de ferramentas de automação de implantação do NetApp Oracle para NFS.
git clone https://bitbucket.ngage.netapp.com/scm/ns-bb/na_oracle_deploy_nfs.git
O controlador Ansible pode estar localizado na mesma VPC que a instância EC2 do banco de dados ou no local, desde que haja conectividade de rede entre eles. -
Preencha os parâmetros definidos pelo usuário nos arquivos de parâmetros dos hosts. A seguir estão exemplos de configuração típica de arquivo host.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat hosts #Oracle hosts [oracle] orapm01 ansible_host=172.30.15.111 ansible_ssh_private_key_file=ec2-user.pem orapm02 ansible_host=172.30.15.5 ansible_ssh_private_key_file=ec2-user.pem
-
Preencha os parâmetros definidos pelo usuário nos arquivos de parâmetros vars/vars.yml. A seguir estão alguns exemplos de configuração típica do arquivo vars.yml.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat vars/vars.yml ###################################################################### ###### Oracle 19c deployment user configuration variables ###### ###### Consolidate all variables from ONTAP, linux and oracle ###### ###################################################################### ########################################### ### ONTAP env specific config variables ### ########################################### # Prerequisite to create three volumes in NetApp ONTAP storage from System Manager or cloud dashboard with following naming convention: # db_hostname_u01 - Oracle binary # db_hostname_u02 - Oracle data # db_hostname_u03 - Oracle redo # It is important to strictly follow the name convention or the automation will fail. ########################################### ### Linux env specific config variables ### ########################################### redhat_sub_username: xxxxxxxx redhat_sub_password: "xxxxxxxx" #################################################### ### DB env specific install and config variables ### #################################################### # Database domain name db_domain: ec2.internal # Set initial password for all required Oracle passwords. Change them after installation. initial_pwd_all: "xxxxxxxx"
-
Preencha os parâmetros definidos pelo usuário nos arquivos de parâmetros host_vars/host_name.yml. A seguir estão exemplos de configuração típica do arquivo host_vars/host_name.yml.
[admin@ansiblectl na_oracle_deploy_nfs]$ cat host_vars/orapm01.yml # User configurable Oracle host specific parameters # Database SID. By default, a container DB is created with 3 PDBs within the CDB oracle_sid: NTAP # CDB is created with SGA at 75% of memory_limit, MB. Consider how many databases to be hosted on the node and # how much ram to be allocated to each DB. The grand total of SGA should not exceed 75% available RAM on node. memory_limit: 8192 # Local NFS lif ip address to access database volumes nfs_lif: 172.30.15.95
O endereço nfs_lif pode ser recuperado da saída dos pontos finais do cluster FSx ONTAP da implantação automatizada do EC2 e do FSx ONTAP na seção anterior. -
Crie volumes de banco de dados no console do AWS FSx. Certifique-se de usar o nome do host do nó primário do PCS (orapm01) como prefixo para os volumes, conforme demonstrado abaixo.
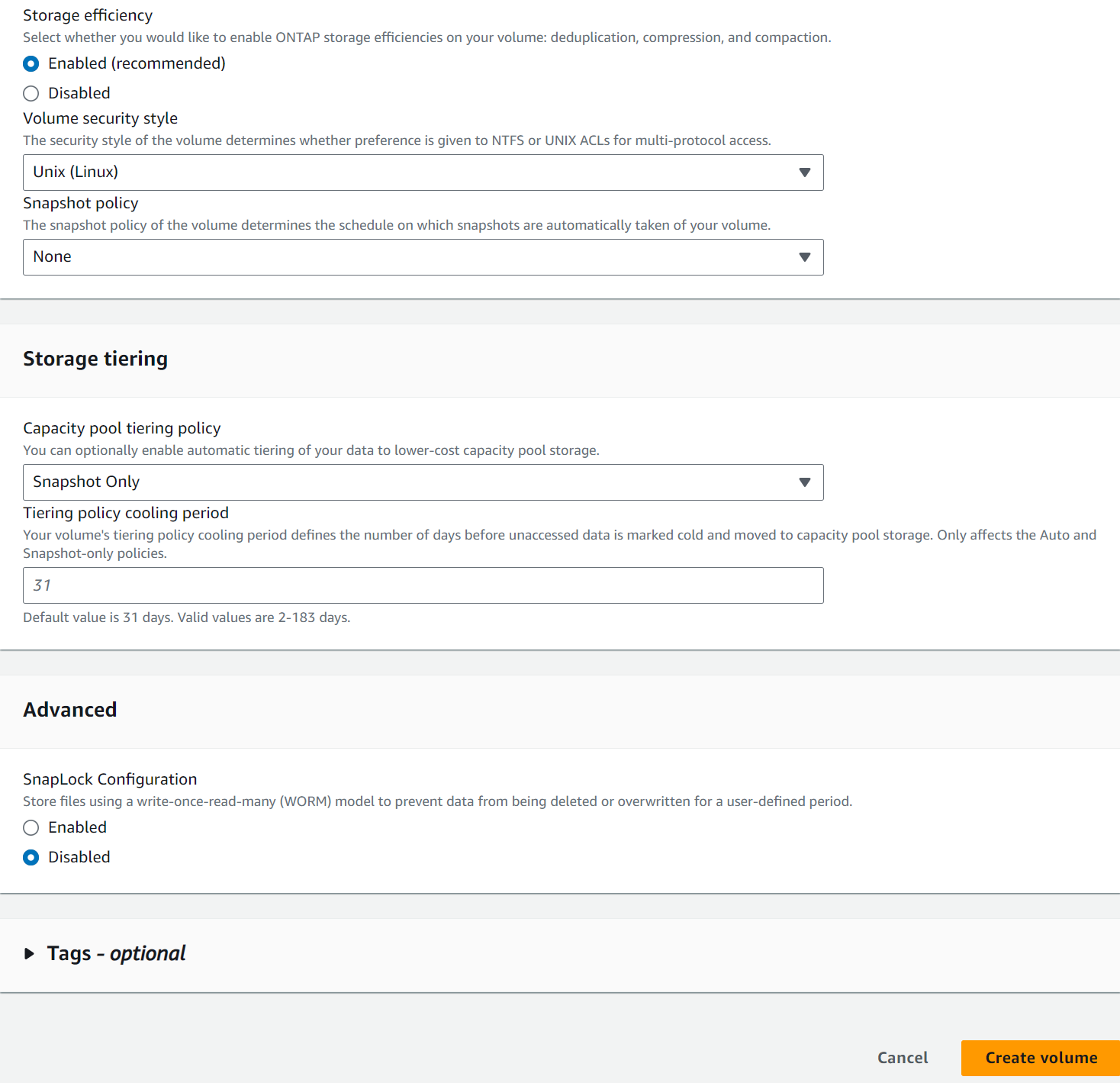
-
Etapa seguinte: arquivos de instalação do Oracle 19c na instância EC2 do nó primário do PCS ip-172-30-15-111.ec2.internal /tmp/archive diretório com permissão 777.
installer_archives: - "LINUX.X64_193000_db_home.zip" - "p34765931_190000_Linux-x86-64.zip" - "p6880880_190000_Linux-x86-64.zip"
-
Execute o manual de configuração do Linux para
all nodes.ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 2-linux_config.yml -u ec2-user -e @vars/vars.yml PLAY [Linux Setup and Storage Config for Oracle] **************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] ok: [orapm02] TASK [linux : Configure RedHat 7 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** skipping: [orapm01] skipping: [orapm02] TASK [linux : Configure RedHat 8 for Oracle DB installation] **************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/linux/tasks/rhel8_config.yml for orapm01, orapm02 TASK [linux : Register subscriptions for RedHat Server] ********************************************************************************************************************************************************************************************************************************************************************* ok: [orapm01] ok: [orapm02] . . .
-
Executar manual para configuração do Oracle
only on primary node(comente o nó standby no arquivo hosts).ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut"[admin@ansiblectl na_oracle_deploy_nfs]$ ansible-playbook -i hosts 4-oracle_config.yml -u ec2-user -e @vars/vars.yml --skip-tags "enable_db_start_shut" PLAY [Oracle installation and configuration] ******************************************************************************************************************************************************************************************************************************************************************************** TASK [Gathering Facts] ****************************************************************************************************************************************************************************************************************************************************************************************************** ok: [orapm01] TASK [oracle : Oracle software only install] ******************************************************************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_install.yml for orapm01 TASK [oracle : Create mount points for NFS file systems / Mount NFS file systems on Oracle hosts] *************************************************************************************************************************************************************************************************************************** included: /home/admin/na_oracle_deploy_nfs/roles/oracle/tasks/oracle_mount_points.yml for orapm01 TASK [oracle : Create mount points for NFS file systems] ******************************************************************************************************************************************************************************************************************************************************************** changed: [orapm01] => (item=/u01) changed: [orapm01] => (item=/u02) changed: [orapm01] => (item=/u03) . . .
-
Após a implantação do banco de dados, comente as montagens /u01, /u02, /u03 em /etc/fstab no nó primário, pois os pontos de montagem serão gerenciados somente pelo PCS.
sudo vi /etc/fstab[root@ip-172-30-15-111 ec2-user]# cat /etc/fstab UUID=eaa1f38e-de0f-4ed5-a5b5-2fa9db43bb38 / xfs defaults 0 0 /mnt/swapfile swap swap defaults 0 0 #172.30.15.95:/orapm01_u01 /u01 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u02 /u02 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0 #172.30.15.95:/orapm01_u03 /u03 nfs rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 0 0
-
Copie /etc/oratab /etc/oraInst.loc, /home/oracle/.bash_profile para o nó em espera. Certifique-se de manter a propriedade e as permissões adequadas dos arquivos.
-
Desligue o banco de dados, o listener e desmonte /u01, /u02, /u03 no nó primário.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Wed Sep 18 16:51:02 UTC 2024 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Wed Sep 18 16:51:16 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> shutdown immediate; SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl stop listener.ntap [oracle@ip-172-30-15-111 ~]$ exit logout [root@ip-172-30-15-111 ec2-user]# umount /u01 [root@ip-172-30-15-111 ec2-user]# umount /u02 [root@ip-172-30-15-111 ec2-user]# umount /u03
-
Crie pontos de montagem no nó de espera ip-172-30-15-5.
mkdir /u01 mkdir /u02 mkdir /u03 -
Monte os volumes do banco de dados FSx ONTAP no nó de espera ip-172-30-15-5.
mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536[root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03
-
Alterado para usuário oracle, revincular binário.
[root@ip-172-30-15-5 ec2-user]# su - oracle Last login: Thu Sep 12 18:09:03 UTC 2024 on pts/0 [oracle@ip-172-30-15-5 ~]$ env | grep ORA ORACLE_SID=NTAP ORACLE_HOME=/u01/app/oracle/product/19.0.0/NTAP [oracle@ip-172-30-15-5 ~]$ cd $ORACLE_HOME/bin [oracle@ip-172-30-15-5 bin]$ ./relink writing relink log to: /u01/app/oracle/product/19.0.0/NTAP/install/relinkActions2024-09-12_06-21-40PM.log
-
Copie a biblioteca dnfs de volta para a pasta odm. Relink pode perder o arquivo de biblioteca dfns.
[oracle@ip-172-30-15-5 odm]$ cd /u01/app/oracle/product/19.0.0/NTAP/rdbms/lib/odm [oracle@ip-172-30-15-5 odm]$ cp ../../../lib/libnfsodm19.so .
-
Inicie o banco de dados para validar no nó de espera ip-172-30-15-5.
[oracle@ip-172-30-15-5 odm]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:30:04 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> show pdbs CON_ID CON_NAME OPEN MODE RESTRICTED ---------- ------------------------------ ---------- ---------- 2 PDB$SEED READ ONLY NO 3 NTAP_PDB1 READ WRITE NO 4 NTAP_PDB2 READ WRITE NO 5 NTAP_PDB3 READ WRITE NO -
Desligue o banco de dados e faça failback do banco de dados para o nó primário ip-172-30-15-111.
SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut down. SQL> exit [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-5 ec2-user]# umount /u01 [root@ip-172-30-15-5 ec2-user]# umount /u02 [root@ip-172-30-15-5 ec2-user]# umount /u03 [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u01 /u01 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u02 /u02 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# mount -t nfs 172.30.15.95:/orapm01_u03 /u03 -o rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536 mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. [root@ip-172-30-15-111 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.8G 48M 7.7G 1% /dev/shm tmpfs 7.8G 33M 7.7G 1% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/xvda2 50G 29G 22G 58% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 844G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 844G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 844G 100% /u03 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 12 18:13:34 UTC 2024 on pts/1 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu Sep 12 18:38:46 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to an idle instance. SQL> startup; ORACLE instance started. Total System Global Area 6442449688 bytes Fixed Size 9177880 bytes Variable Size 1090519040 bytes Database Buffers 5335154688 bytes Redo Buffers 7598080 bytes Database mounted. Database opened. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 [oracle@ip-172-30-15-111 ~]$ lsnrctl start listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 12-SEP-2024 18:39:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Starting /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr: please wait... TNSLSNR for Linux: Version 19.0.0.0.0 - Production System parameter file is /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Log messages written to /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) Listening on: (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 12-SEP-2024 18:39:17 Uptime 0 days 0 hr. 0 min. 0 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=ip-172-30-15-111.ec2.internal)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) The listener supports no services The command completed successfully
Configurar recursos Oracle para gerenciamento de PCS
Details
O objetivo de configurar o clustering do Pacemaker é configurar uma solução de alta disponibilidade ativa/passiva para executar o Oracle no ambiente AWS EC2 e FSx ONTAP com intervenção mínima do usuário em caso de falha. A seguir é demonstrada a configuração de recursos do Oracle para gerenciamento de PCS.
-
Como usuário root na instância primária do EC2 ip-172-30-15-111, crie um endereço IP privado secundário com um endereço IP privado não utilizado no bloco CIDR da VPC como IP flutuante. No processo, crie um grupo de recursos Oracle ao qual o endereço IP privado secundário pertencerá.
pcs resource create privip ocf:heartbeat:awsvip secondary_private_ip=172.30.15.33 --group oracle[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:25:35 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:25:23 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Se o privilégio for criado no nó do cluster em espera, mova-o para o nó primário, conforme mostrado abaixo. -
Mover um recurso entre nós do cluster.
pcs resource move privip ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs resource move privip ip-172-30-15-111.ec2.internal Warning: A move constraint has been created and the resource 'privip' may or may not move depending on other configuration [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:26:38 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:26:27 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 2 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal (Monitoring) Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Crie um IP virtual (vip) para o Oracle. O IP virtual flutuará entre o nó primário e o nó de espera, conforme necessário.
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle[root@ip-172-30-15-111 ec2-user]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.30.15.33 cidr_netmask=25 nic=eth0 op monitor interval=10s --group oracle [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx WARNINGS: Following resources have been moved and their move constraints are still in place: 'privip' Run 'pcs constraint location' or 'pcs resource clear <resource id>' to view or remove the constraints, respectively Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 16:27:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 16:27:24 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 3 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Como usuário Oracle, atualize os arquivos listener.ora e tnsnames.ora para apontar para o endereço vip. Reinicie o ouvinte. Retorne o banco de dados se necessário para que o BD se registre com o listener.
vi $ORACLE_HOME/network/admin/listener.oravi $ORACLE_HOME/network/admin/tnsnames.ora[oracle@ip-172-30-15-111 admin]$ cat listener.ora # listener.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora # Generated by Oracle configuration tools. LISTENER.NTAP = (DESCRIPTION_LIST = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521)) ) ) [oracle@ip-172-30-15-111 admin]$ cat tnsnames.ora # tnsnames.ora Network Configuration File: /u01/app/oracle/product/19.0.0/NTAP/network/admin/tnsnames.ora # Generated by Oracle configuration tools. NTAP = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = NTAP.ec2.internal) ) ) LISTENER_NTAP = (ADDRESS = (PROTOCOL = TCP)(HOST = 172.30.15.33)(PORT = 1521)) [oracle@ip-172-30-15-111 admin]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 18:28:17 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 13-SEP-2024 18:15:51 Uptime 0 days 0 hr. 12 min. 25 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully **Oracle listener now listens on vip for database connection** -
Adicione os pontos de montagem /u01, /u02, /u03 ao grupo de recursos Oracle.
pcs resource create u01 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u01' directory='/u01' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u02 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u02' directory='/u02' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oraclepcs resource create u03 ocf:heartbeat:Filesystem device='172.30.15.95:/orapm01_u03' directory='/u03' fstype='nfs' options='rw,bg,hard,vers=3,proto=tcp,timeo=600,rsize=65536,wsize=65536' --group oracle -
Crie um ID de usuário do monitor PCS no Oracle DB.
[root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Fri Sep 13 18:12:24 UTC 2024 on pts/0 [oracle@ip-172-30-15-111 ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 19:08:41 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> CREATE USER c##ocfmon IDENTIFIED BY "XXXXXXXX"; User created. SQL> grant connect to c##ocfmon; Grant succeeded. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0
-
Adicionar banco de dados ao grupo de recursos Oracle.
pcs resource create ntap ocf:heartbeat:oracle sid='NTAP' home='/u01/app/oracle/product/19.0.0/NTAP' user='oracle' monuser='C##OCFMON' monpassword='XXXXXXXX' monprofile='DEFAULT' --group oracle -
Adicione o ouvinte do banco de dados ao grupo de recursos do Oracle.
pcs resource create listener ocf:heartbeat:oralsnr sid='NTAP' listener='listener.ntap' --group=oracle -
Atualizar todas as restrições de localização de recursos no grupo de recursos do Oracle para o nó primário como nó preferencial.
pcs constraint location privip prefers ip-172-30-15-111.ec2.internal pcs constraint location vip prefers ip-172-30-15-111.ec2.internal pcs constraint location u01 prefers ip-172-30-15-111.ec2.internal pcs constraint location u02 prefers ip-172-30-15-111.ec2.internal pcs constraint location u03 prefers ip-172-30-15-111.ec2.internal pcs constraint location ntap prefers ip-172-30-15-111.ec2.internal pcs constraint location listener prefers ip-172-30-15-111.ec2.internal[root@ip-172-30-15-111 ec2-user]# pcs constraint config Location Constraints: Resource: listener Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: ntap Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: privip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u01 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u02 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: u03 Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Resource: vip Enabled on: Node: ip-172-30-15-111.ec2.internal (score:INFINITY) Ordering Constraints: Colocation Constraints: Ticket Constraints: -
Validar a configuração dos recursos do Oracle.
pcs status[root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 19:25:32 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 19:23:40 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Validação de HA pós-implantação
Details
Após a implantação, é essencial executar alguns testes e validações para garantir que o cluster de failover do banco de dados Oracle do PCS esteja configurado corretamente e funcione conforme o esperado. A validação do teste inclui failover gerenciado e simulação de falha inesperada de recursos e recuperação pelo mecanismo de proteção do cluster.
-
Valide o isolamento do nó acionando manualmente o isolamento do nó em espera e observe se o nó em espera foi colocado offline e reinicializado após um tempo limite.
pcs stonith fence <standbynodename>[root@ip-172-30-15-111 ec2-user]# pcs stonith fence ip-172-30-15-5.ec2.internal Node: ip-172-30-15-5.ec2.internal fenced [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 21:58:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 21:55:12 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-111.ec2.internal ] * OFFLINE: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-111.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Started ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Started ip-172-30-15-111.ec2.internal Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled -
Simule uma falha no listener do banco de dados eliminando o processo do listener e observe que o PCS monitorou a falha do listener e o reiniciou em alguns segundos.
[root@ip-172-30-15-111 ec2-user]# ps -ef | grep lsnr oracle 154895 1 0 18:15 ? 00:00:00 /u01/app/oracle/product/19.0.0/NTAP/bin/tnslsnr listener.ntap -inherit root 217779 120186 0 19:36 pts/0 00:00:00 grep --color=auto lsnr [root@ip-172-30-15-111 ec2-user]# kill -9 154895 [root@ip-172-30-15-111 ec2-user]# su - oracle Last login: Thu Sep 19 14:58:54 UTC 2024 [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 13-SEP-2024 19:36:51 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=IPC)(KEY=EXTPROC1521))) TNS-12541: TNS:no listener TNS-12560: TNS:protocol adapter error TNS-00511: No listener Linux Error: 111: Connection refused [oracle@ip-172-30-15-111 ~]$ lsnrctl status listener.ntap LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 19-SEP-2024 15:00:10 Copyright (c) 1991, 2022, Oracle. All rights reserved. Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=172.30.15.33)(PORT=1521))) STATUS of the LISTENER ------------------------ Alias listener.ntap Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 16-SEP-2024 14:00:14 Uptime 3 days 0 hr. 59 min. 56 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/oracle/product/19.0.0/NTAP/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/ip-172-30-15-111/listener.ntap/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=172.30.15.33)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=tcps)(HOST=ip-172-30-15-111.ec2.internal)(PORT=5500))(Security=(my_wallet_directory=/u01/app/oracle/product/19.0.0/NTAP/admin/NTAP/xdb_wallet))(Presentation=HTTP)(Session=RAW)) Services Summary... Service "21f0b5cc1fa290e2e0636f0f1eacfd43.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b74445329119e0636f0f1eacec03.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "21f0b83929709164e0636f0f1eacacc3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAP.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "NTAPXDB.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb1.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb2.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... Service "ntap_pdb3.ec2.internal" has 1 instance(s). Instance "NTAP", status READY, has 1 handler(s) for this service... The command completed successfully
-
Simule uma falha no banco de dados eliminando o processo pmon e observe que o PCS monitorou a falha do banco de dados e o reiniciou em poucos segundos.
**Make a remote connection to ntap database** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:42:42 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Thu Sep 12 2024 13:37:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL> **Kill ntap pmon process to simulate a failure** [root@ip-172-30-15-111 ec2-user]# ps -ef | grep pmon oracle 159247 1 0 18:27 ? 00:00:00 ora_pmon_NTAP root 230595 120186 0 19:44 pts/0 00:00:00 grep --color=auto pmon [root@ip-172-30-15-111 ec2-user]# kill -9 159247 **Observe the DB failure** SQL> / select instance_name, host_name from v$instance * ERROR at line 1: ORA-03113: end-of-file on communication channel Process ID: 227424 Session ID: 396 Serial number: 4913 SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 **Reconnect to DB after reboot** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 15:47:24 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:42:47 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
-
Valide um failover de banco de dados gerenciado do primário para o modo de espera colocando o nó primário no modo de espera para fazer o failover de recursos Oracle para o nó de espera.
pcs node standby <nodename>**Stopping Oracle resources on primary node in reverse order** [root@ip-172-30-15-111 ec2-user]# pcs node standby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:16 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby (with active resources) * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Stopping ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on standby node in sequencial order** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:01:34 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:01:08 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Node ip-172-30-15-111.ec2.internal: standby * Online: [ ip-172-30-15-5.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-5.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-5.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-5.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **NFS mount points mounted on standby node** [root@ip-172-30-15-5 ec2-user]# df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 7.7G 0 7.7G 0% /dev tmpfs 7.7G 33M 7.7G 1% /dev/shm tmpfs 7.7G 17M 7.7G 1% /run tmpfs 7.7G 0 7.7G 0% /sys/fs/cgroup /dev/xvda2 50G 21G 30G 41% / tmpfs 1.6G 0 1.6G 0% /run/user/1000 172.30.15.95:/orapm01_u01 48T 47T 840G 99% /u01 172.30.15.95:/orapm01_u02 285T 285T 840G 100% /u02 172.30.15.95:/orapm01_u03 190T 190T 840G 100% /u03 tmpfs 1.6G 0 1.6G 0% /run/user/54321 **Database opened on standby node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:34:08 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 15:47:28 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select name, open_mode from v$database; NAME OPEN_MODE --------- -------------------- NTAP READ WRITE SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-5.ec2.internal SQL> -
Valide um failback de banco de dados gerenciado do modo de espera para o primário pelo nó primário não-de-espera e observe que os recursos do Oracle fazem failback automaticamente devido à configuração do nó preferencial.
pcs node unstandby <nodename>**Stopping Oracle resources on standby node for failback to primary** [root@ip-172-30-15-111 ec2-user]# pcs node unstandby ip-172-30-15-111.ec2.internal [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:30 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Stopping ip-172-30-15-5.ec2.internal * vip (ocf::heartbeat:IPaddr2): Stopped * u01 (ocf::heartbeat:Filesystem): Stopped * u02 (ocf::heartbeat:Filesystem): Stopped * u03 (ocf::heartbeat:Filesystem): Stopped * ntap (ocf::heartbeat:oracle): Stopped * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Starting Oracle resources on primary node for failback** [root@ip-172-30-15-111 ec2-user]# pcs status Cluster name: ora_ec2nfsx Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: ip-172-30-15-111.ec2.internal (version 2.1.7-5.1.el8_10-0f7f88312) - partition with quorum * Last updated: Fri Sep 13 20:41:45 2024 on ip-172-30-15-111.ec2.internal * Last change: Fri Sep 13 20:41:18 2024 by root via root on ip-172-30-15-111.ec2.internal * 2 nodes configured * 8 resource instances configured Node List: * Online: [ ip-172-30-15-5.ec2.internal ip-172-30-15-111.ec2.internal ] Full List of Resources: * clusterfence (stonith:fence_aws): Started ip-172-30-15-5.ec2.internal * Resource Group: oracle: * privip (ocf::heartbeat:awsvip): Started ip-172-30-15-111.ec2.internal * vip (ocf::heartbeat:IPaddr2): Started ip-172-30-15-111.ec2.internal * u01 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u02 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * u03 (ocf::heartbeat:Filesystem): Started ip-172-30-15-111.ec2.internal * ntap (ocf::heartbeat:oracle): Starting ip-172-30-15-111.ec2.internal * listener (ocf::heartbeat:oralsnr): Stopped Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled **Database now accepts connection on primary node** [oracle@ora_01 ~]$ sqlplus system@//172.30.15.33:1521/NTAP.ec2.internal SQL*Plus: Release 19.0.0.0.0 - Production on Fri Sep 13 16:46:07 2024 Version 19.18.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Sep 13 2024 16:34:12 -04:00 Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.18.0.0.0 SQL> select instance_name, host_name from v$instance; INSTANCE_NAME ---------------- HOST_NAME ---------------------------------------------------------------- NTAP ip-172-30-15-111.ec2.internal SQL>
Isso conclui a validação do Oracle HA e a demonstração da solução no AWS EC2 com clustering do Pacemaker e Amazon FSx ONTAP como backend de armazenamento de banco de dados.
Backup, restauração e clonagem do Oracle com SnapCenter
Details
A NetApp recomenda a ferramenta SnapCenter UI para gerenciar o banco de dados Oracle implantado no AWS EC2 e no Amazon FSx ONTAP. Consulte TR-4979"Oracle simplificado e autogerenciado no VMware Cloud na AWS com FSx ONTAP montado no convidado" seção Oracle backup, restore, and clone with SnapCenter para obter detalhes sobre como configurar o SnapCenter e executar os fluxos de trabalho de backup, restauração e clonagem do banco de dados.
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, revise os seguintes documentos e/ou sites: