

TR-4956: Implantação automatizada de alta disponibilidade do PostgreSQL e recuperação de desastres no AWS FSx/EC2
 Sugerir alterações
Sugerir alterações
Allen Cao, Niyaz Mohamed, NetApp
Esta solução fornece uma visão geral e detalhes para implantação de banco de dados PostgreSQL e configuração de HA/DR, failover e ressincronização com base na tecnologia NetApp SnapMirror incorporada à oferta de armazenamento FSx ONTAP e ao kit de ferramentas de automação NetApp Ansible na AWS.
Propósito
O PostgreSQL é um banco de dados de código aberto amplamente utilizado e classificado como o número quatro entre os dez mecanismos de banco de dados mais populares pela"Motores DB" . Por um lado, o PostgreSQL deriva sua popularidade de seu modelo de código aberto e sem licença, ao mesmo tempo em que possui recursos sofisticados. Por outro lado, por ser de código aberto, há escassez de orientações detalhadas sobre implantação de banco de dados de nível de produção na área de alta disponibilidade e recuperação de desastres (HA/DR), especialmente na nuvem pública. Em geral, pode ser difícil configurar um sistema HA/DR PostgreSQL típico com espera ativa e passiva, replicação de streaming e assim por diante. Testar o ambiente HA/DR promovendo o site de espera e depois alternando de volta para o principal pode causar interrupções na produção. Há problemas de desempenho bem documentados no primário quando cargas de trabalho de leitura são implantadas em espera ativa de streaming.
Nesta documentação, demonstramos como você pode dispensar uma solução de HA/DR de streaming PostgreSQL em nível de aplicativo e criar uma solução de HA/DR PostgreSQL com base no armazenamento AWS FSx ONTAP e em instâncias de computação EC2 usando replicação em nível de armazenamento. A solução cria um sistema mais simples e comparável e oferece resultados equivalentes quando comparado à replicação de streaming tradicional no nível do aplicativo PostgreSQL para HA/DR.
Esta solução é baseada na tecnologia de replicação em nível de armazenamento NetApp SnapMirror , comprovada e madura, disponível no armazenamento em nuvem FSX ONTAP nativo da AWS para PostgreSQL HA/DR. É simples de implementar com um kit de ferramentas de automação fornecido pela equipe da NetApp Solutions. Ele fornece funcionalidade semelhante ao mesmo tempo em que elimina a complexidade e o desempenho do site principal com a solução HA/DR baseada em streaming no nível do aplicativo. A solução pode ser facilmente implantada e testada sem afetar o site principal ativo.
Esta solução aborda os seguintes casos de uso:
-
Implantação de HA/DR de nível de produção para PostgreSQL na nuvem pública da AWS
-
Testando e validando uma carga de trabalho PostgreSQL na nuvem pública AWS
-
Testando e validando uma estratégia de HA/DR do PostgreSQL baseada na tecnologia de replicação NetApp SnapMirror
Público
Esta solução é destinada às seguintes pessoas:
-
O DBA interessado em implantar o PostgreSQL com HA/DR na nuvem pública da AWS.
-
O arquiteto de soluções de banco de dados interessado em testar cargas de trabalho do PostgreSQL na nuvem pública da AWS.
-
O administrador de armazenamento interessado em implantar e gerenciar instâncias do PostgreSQL implantadas no armazenamento AWS FSx.
-
O proprietário do aplicativo interessado em configurar um ambiente PostgreSQL no AWS FSx/EC2.
Ambiente de teste e validação de soluções
O teste e a validação desta solução foram realizados em um ambiente AWS FSx e EC2 que pode não corresponder ao ambiente de implantação final. Para mais informações, consulte a seção Fatores-chave para consideração de implantação .
Arquitetura
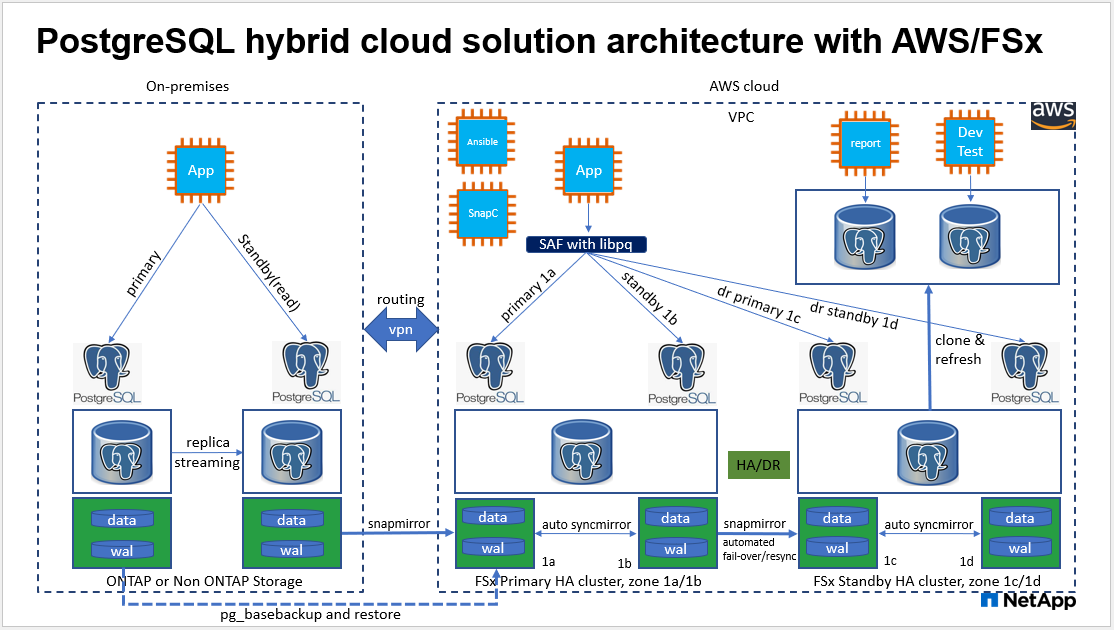
Componentes de hardware e software
Hardware |
||
Armazenamento FSx ONTAP |
Versão atual |
Dois pares FSx HA na mesma VPC e zona de disponibilidade como clusters HA primário e em espera |
Instância EC2 para computação |
t2.xlarge/4vCPU/16G |
Duas instâncias de computação EC2 T2 xlarge como primária e de espera |
Controlador Ansible |
Centos VM/4vCPU/8G no local |
Uma VM para hospedar o controlador de automação Ansible no local ou na nuvem |
Software |
||
RedHat Linux |
RHEL-8.6.0_HVM-20220503-x86_64-2-Hora2-GP2 |
Assinatura RedHat implantada para teste |
Centos Linux |
CentOS Linux versão 8.2.2004 (Core) |
Hospedagem do controlador Ansible implantado em laboratório local |
PostgreSQL |
Versão 14.5 |
A automação extrai a versão mais recente disponível do PostgreSQL do repositório postgresql.ora yum |
Ansible |
Versão 2.10.3 |
Pré-requisitos para coleções e bibliotecas necessárias instaladas com o manual de requisitos |
Fatores-chave para consideração de implantação
-
Backup, restauração e recuperação de banco de dados PostgreSQL. Um banco de dados PostgreSQL suporta vários métodos de backup, como um backup lógico usando pg_dump, um backup físico on-line com pg_basebackup ou um comando de backup de sistema operacional de nível inferior e snapshots consistentes no nível de armazenamento. Esta solução usa snapshots de grupo de consistência do NetApp para backup, restauração e recuperação de dados de banco de dados PostgreSQL e volumes WAL no site em espera. Os instantâneos de volume do grupo de consistência do NetApp sequenciam E/S conforme são gravados no armazenamento e protegem a integridade dos arquivos de dados do banco de dados.
-
Instâncias de computação do EC2. Nesses testes e validações, usamos o tipo de instância t2.xlarge do AWS EC2 para a instância de computação do banco de dados PostgreSQL. A NetApp recomenda usar uma instância EC2 do tipo M5 como instância de computação para PostgreSQL na implantação porque ela é otimizada para cargas de trabalho de banco de dados. A instância de computação em espera sempre deve ser implantada na mesma zona que o sistema de arquivos passivo (em espera) implantado para o cluster FSx HA.
-
Implantação de clusters de HA de armazenamento FSx em uma ou várias zonas. Nesses testes e validações, implantamos um cluster FSx HA em uma única zona de disponibilidade da AWS. Para implantação de produção, a NetApp recomenda implantar um par FSx HA em duas zonas de disponibilidade diferentes. Um par de HA de espera para recuperação de desastres para continuidade de negócios pode ser configurado em uma região diferente se uma distância específica for necessária entre o primário e o de espera. Um cluster FSx HA é sempre provisionado em um par HA que é espelhado de forma sincronizada em um par de sistemas de arquivos ativos-passivos para fornecer redundância em nível de armazenamento.
-
Posicionamento de dados e logs do PostgreSQL. Implantações típicas do PostgreSQL compartilham o mesmo diretório raiz ou volumes para dados e arquivos de log. Em nossos testes e validações, separamos os dados e logs do PostgreSQL em dois volumes separados para melhor desempenho. Um link simbólico é usado no diretório de dados para apontar para o diretório de log ou volume que hospeda os logs do PostgreSQL WAL e os logs do WAL arquivados.
-
Temporizador de atraso na inicialização do serviço PostgreSQL. Esta solução usa volumes montados NFS para armazenar o arquivo de banco de dados PostgreSQL e os arquivos de log do WAL. Durante a reinicialização do host do banco de dados, o serviço PostgreSQL pode tentar iniciar enquanto o volume não está montado. Isso resulta em falha na inicialização do serviço de banco de dados. É necessário um atraso de 10 a 15 segundos no temporizador para que o banco de dados PostgreSQL inicie corretamente.
-
RPO/RTO para continuidade de negócios. A replicação de dados do FSx do primário para o standby para DR é baseada em ASYNC, o que significa que o RPO depende da frequência de backups do Snapshot e da replicação do SnapMirror . Uma frequência maior de cópia do Snapshot e replicação do SnapMirror reduz o RPO. Portanto, há um equilíbrio entre a potencial perda de dados em caso de desastre e o custo incremental de armazenamento. Determinamos que a cópia do Snapshot e a replicação do SnapMirror podem ser implementadas em intervalos de apenas 5 minutos para RPO, e o PostgreSQL geralmente pode ser recuperado no site de espera do DR em menos de um minuto para o RTO.
-
Backup de banco de dados. Depois que um banco de dados PostgreSQL é implementado ou migrado para o armazenamento AWS FSx de um data center local, os dados são espelhados e sincronizados automaticamente no par FSx HA para proteção. Os dados são ainda mais protegidos com um site de reserva replicado em caso de desastre. Para retenção de backup ou proteção de dados de longo prazo, a NetApp recomenda usar o utilitário pg_basebackup integrado do PostgreSQL para executar um backup completo do banco de dados que pode ser transferido para o armazenamento de blobs do S3.
Implantação de solução
A implantação desta solução pode ser concluída automaticamente usando o kit de ferramentas de automação baseado em NetApp Ansible, seguindo as instruções detalhadas descritas abaixo.
-
Leia as instruções no kit de ferramentas de automação READme.md"na_postgresql_aws_deploy_hadr" .
-
Assista ao vídeo passo a passo a seguir.
-
Configurar os arquivos de parâmetros necessários(
hosts,host_vars/host_name.yml,fsx_vars.yml) inserindo parâmetros específicos do usuário no modelo nas seções relevantes. Em seguida, use o botão copiar para copiar os arquivos para o host do controlador Ansible.
Pré-requisitos para implantação automatizada
A implantação requer os seguintes pré-requisitos.
-
Uma conta da AWS foi configurada e os segmentos de VPC e rede necessários foram criados dentro da sua conta da AWS.
-
No console do AWS EC2, você deve implantar duas instâncias do EC2 Linux, uma como o servidor de banco de dados PostgreSQL principal no site primário e uma no site de DR em espera. Para redundância de computação nos sites de DR primário e de espera, implante duas instâncias adicionais do EC2 Linux como servidores de banco de dados PostgreSQL de espera. Veja o diagrama de arquitetura na seção anterior para obter mais detalhes sobre a configuração do ambiente. Revise também o"Guia do usuário para instâncias Linux" para maiores informações.
-
No console do AWS EC2, implante dois clusters de HA de armazenamento FSx ONTAP para hospedar os volumes do banco de dados PostgreSQL. Se você não estiver familiarizado com a implantação do armazenamento FSx, consulte a documentação"Criação de sistemas de arquivos FSx ONTAP" para obter instruções passo a passo.
-
Crie uma VM Centos Linux para hospedar o controlador Ansible. O controlador Ansible pode estar localizado no local ou na nuvem da AWS. Se estiver localizado no local, você deverá ter conectividade SSH com as instâncias VPC, EC2 Linux e clusters de armazenamento FSx.
-
Configure o controlador Ansible conforme descrito na seção "Configurar o nó de controle Ansible para implantações CLI no RHEL/CentOS" do recurso"Introdução à automação de soluções da NetApp" .
-
Clone uma cópia do kit de ferramentas de automação do site público do NetApp GitHub.
git clone https://github.com/NetApp-Automation/na_postgresql_aws_deploy_hadr.git-
No diretório raiz do kit de ferramentas, execute os playbooks de pré-requisitos para instalar as coleções e bibliotecas necessárias para o controlador Ansible.
ansible-playbook -i hosts requirements.ymlansible-galaxy collection install -r collections/requirements.yml --force --force-with-deps-
Recuperar os parâmetros de instância EC2 FSx necessários para o arquivo de variáveis do host do BD
host_vars/*e o arquivo de variáveis globaisfsx_vars.ymlconfiguração.
Configurar o arquivo hosts
Insira o IP de gerenciamento do cluster FSx ONTAP primário e os nomes dos hosts das instâncias EC2 no arquivo de hosts.
# Primary FSx cluster management IP address [fsx_ontap] 172.30.15.33
# Primary PostgreSQL DB server at primary site where database is initialized at deployment time [postgresql] psql_01p ansible_ssh_private_key_file=psql_01p.pem
# Primary PostgreSQL DB server at standby site where postgresql service is installed but disabled at deployment # Standby DB server at primary site, to setup this server comment out other servers in [dr_postgresql] # Standby DB server at standby site, to setup this server comment out other servers in [dr_postgresql] [dr_postgresql] -- psql_01s ansible_ssh_private_key_file=psql_01s.pem #psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
Configure o arquivo host_name.yml na pasta host_vars
# Add your AWS EC2 instance IP address for the respective PostgreSQL server host
ansible_host: "10.61.180.15"
# "{{groups.postgresql[0]}}" represents first PostgreSQL DB server as defined in PostgreSQL hosts group [postgresql]. For concurrent multiple PostgreSQL DB servers deployment, [0] will be incremented for each additional DB server. For example, "{{groups.posgresql[1]}}" represents DB server 2, "{{groups.posgresql[2]}}" represents DB server 3 ... As a good practice and the default, two volumes are allocated to a PostgreSQL DB server with corresponding /pgdata, /pglogs mount points, which store PostgreSQL data, and PostgreSQL log files respectively. The number and naming of DB volumes allocated to a DB server must match with what is defined in global fsx_vars.yml file by src_db_vols, src_archivelog_vols parameters, which dictates how many volumes are to be created for each DB server. aggr_name is aggr1 by default. Do not change. lif address is the NFS IP address for the SVM where PostgreSQL server is expected to mount its database volumes. Primary site servers from primary SVM and standby servers from standby SVM.
host_datastores_nfs:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
# Add swap space to EC2 instance, that is equal to size of RAM up to 16G max. Determine the number of blocks by dividing swap size in MB by 128.
swap_blocks: "128"
# Postgresql user configurable parameters
psql_port: "5432"
buffer_cache: "8192MB"
archive_mode: "on"
max_wal_size: "5GB"
client_address: "172.30.15.0/24"Configure o arquivo global fsx_vars.yml na pasta vars
########################################################################
###### PostgreSQL HADR global user configuration variables ######
###### Consolidate all variables from FSx, Linux, and postgresql ######
########################################################################
###########################################
### Ontap env specific config variables ###
###########################################
####################################################################################################
# Variables for SnapMirror Peering
####################################################################################################
#Passphrase for cluster peering authentication
passphrase: "xxxxxxx"
#Please enter destination or standby FSx cluster name
dst_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter destination or standby FSx cluster management IP
dst_cluster_ip: "172.30.15.90"
#Please enter destination or standby FSx cluster inter-cluster IP
dst_inter_ip: "172.30.15.13"
#Please enter destination or standby SVM name to create mirror relationship
dst_vserver: "dr"
#Please enter destination or standby SVM management IP
dst_vserver_mgmt_lif: "172.30.15.88"
#Please enter destination or standby SVM NFS lif
dst_nfs_lif: "172.30.15.88"
#Please enter source or primary FSx cluster name
src_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter source or primary FSx cluster management IP
src_cluster_ip: "172.30.15.20"
#Please enter source or primary FSx cluster inter-cluster IP
src_inter_ip: "172.30.15.5"
#Please enter source or primary SVM name to create mirror relationship
src_vserver: "prod"
#Please enter source or primary SVM management IP
src_vserver_mgmt_lif: "172.30.15.115"
#####################################################################################################
# Variable for PostgreSQL Volumes, lif - source or primary FSx NFS lif address
#####################################################################################################
src_db_vols:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
src_archivelog_vols:
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
#Names of the Nodes in the ONTAP Cluster
nfs_export_policy: "default"
#####################################################################################################
### Linux env specific config variables ###
#####################################################################################################
#NFS Mount points for PostgreSQL DB volumes
mount_points:
- "/pgdata"
- "/pglogs"
#RedHat subscription username and password
redhat_sub_username: "xxxxx"
redhat_sub_password: "xxxxx"
####################################################
### DB env specific install and config variables ###
####################################################
#The latest version of PostgreSQL RPM is pulled/installed and config file is deployed from a preconfigured template
#Recovery type and point: default as all logs and promote and leave all PITR parameters blankImplantação do PostgreSQL e configuração de HA/DR
As tarefas a seguir implantam o serviço do servidor de banco de dados PostgreSQL e inicializam o banco de dados no site principal no host do servidor de banco de dados EC2 principal. Um host de servidor de banco de dados EC2 primário em espera é então configurado no site em espera. Por fim, a replicação do volume do BD é configurada do cluster FSx do site principal para o cluster FSx do site de espera para recuperação de desastres.
-
Crie volumes de banco de dados no cluster FSx primário e configure o postgresql no host da instância EC2 primária.
ansible-playbook -i hosts postgresql_deploy.yml -u ec2-user --private-key psql_01p.pem -e @vars/fsx_vars.yml -
Configure o host da instância do DR EC2 em espera.
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml -
Configure o peering de cluster FSx ONTAP e a replicação de volume de banco de dados.
ansible-playbook -i hosts fsx_replication_setup.yml -e @vars/fsx_vars.yml -
Consolide as etapas anteriores em uma única implantação do PostgreSQL e configuração de HA/DR.
ansible-playbook -i hosts postgresql_hadr_setup.yml -u ec2-user -e @vars/fsx_vars.yml -
Para configurar um host de banco de dados PostgreSQL em espera nos sites principal ou em espera, comente todos os outros servidores na seção [dr_postgresql] do arquivo de hosts e execute o manual postgresql_standby_setup.yml com o respectivo host de destino (como psql_01ps ou instância de computação EC2 em espera no site principal). Certifique-se de que um arquivo de parâmetros do host, como
psql_01ps.ymlestá configurado sob ohost_varsdiretório.[dr_postgresql] -- #psql_01s ansible_ssh_private_key_file=psql_01s.pem psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01ps.pem -e @vars/fsx_vars.ymlBackup e replicação de snapshots de banco de dados PostgreSQL para site standby
O backup e a replicação de snapshots do banco de dados PostgreSQL para o site standby podem ser controlados e executados no controlador Ansible com um intervalo definido pelo usuário. Validamos que o intervalo pode ser de apenas 5 minutos. Portanto, no caso de falha no site principal, há 5 minutos de potencial perda de dados se a falha ocorrer logo antes do próximo backup de instantâneo agendado.
*/15 * * * * /home/admin/na_postgresql_aws_deploy_hadr/data_log_snap.shFailover para o site em espera para DR
Para testar o sistema HA/DR do PostgreSQL como um exercício de DR, execute o failover e a recuperação do banco de dados PostgreSQL na instância primária do EC2 DB em espera no site em espera, executando o seguinte manual. Em um cenário de DR real, execute o mesmo para um failover real para o site de DR.
ansible-playbook -i hosts postgresql_failover.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlRessincronizar volumes de banco de dados replicados após teste de failover
Execute a ressincronização após o teste de failover para restabelecer a replicação do SnapMirror do volume do banco de dados.
ansible-playbook -i hosts postgresql_standby_resync.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlFailover do servidor de banco de dados EC2 primário para o servidor de banco de dados EC2 em espera devido a falha na instância de computação do EC2
A NetApp recomenda executar failover manual ou usar um cluster de sistema operacional bem estabelecido que pode exigir uma licença.
Onde encontrar informações adicionais
Para saber mais sobre as informações descritas neste documento, revise os seguintes documentos e/ou sites:
-
Amazon FSx ONTAP
-
Amazon EC2
-
Automação de soluções NetApp