

Análise e notificação de eventos de performance
 Sugerir alterações
Sugerir alterações
Os eventos de desempenho notificam você sobre problemas de desempenho de e/S em um workload de volume causado pela contenção em um componente do cluster. O Unified Manager analisa o evento para identificar todos os workloads envolvidos, o componente em contenção e se o evento ainda é um problema que talvez você precise resolver.
O Unified Manager monitora a latência de e/S (tempo de resposta) e IOPS (operações) de volumes em um cluster. Quando outras cargas de trabalho usam excessivamente um componente de cluster, por exemplo, o componente está na contenção e não pode ter desempenho em um nível ideal para atender às demandas de workload. O desempenho de outros workloads que estão usando o mesmo componente pode ser afetado, causando o aumento de suas latências. Se a latência ultrapassar o limite de desempenho, o Unified Manager acionará um evento de desempenho e enviará um alerta por e-mail para notificá-lo.
Análise de eventos
O Unified Manager realiza as seguintes análises, usando as estatísticas de desempenho dos 15 dias anteriores, para identificar os workloads da vítima, os workloads bully e o componente do cluster envolvido em um evento:
-
Identifica cargas de trabalho da vítima cuja latência ultrapassou o limite de desempenho, que é o limite superior do intervalo esperado:
-
Para volumes em agregados de HDD ou Flash Pool (híbridos), os eventos são acionados somente quando a latência é maior que 5 milissegundos (ms) e o IOPS é mais de 10 operações por segundo (operações/seg).
-
Para volumes em agregados all-SSD ou agregados FabricPool (compostos), os eventos são acionados apenas quando a latência é superior a 1 ms e o IOPS é superior a 100 operações/segundo
-
-
Identifica o componente do cluster na contenção.

Se a latência das cargas de trabalho da vítima na interconexão de cluster for superior a 1 ms, o Unified Manager tratará isso como significativo e acionará um evento para a interconexão de cluster.
-
Identifica as cargas de trabalho bully que estão sobreusando o componente do cluster e fazendo com que ele esteja na contenção.
-
Classifica as cargas de trabalho envolvidas, com base em seu desvio na utilização ou atividade de um componente de cluster, para determinar quais bullies têm a maior alteração no uso do componente de cluster e quais vítimas são as mais impactadas.
Um evento pode ocorrer por apenas um breve momento e depois se corrigir depois que o componente que está usando não está mais em disputa. Um evento contínuo é aquele que ocorre novamente para o mesmo componente do cluster dentro de um intervalo de cinco minutos e permanece no estado ativo. Para eventos contínuos, o Unified Manager aciona um alerta após detetar o mesmo evento durante dois intervalos de análise consecutivos. Os eventos que permanecem não resolvidos, que têm um estado de novo, podem exibir mensagens de descrição diferentes como cargas de trabalho envolvidas na alteração do evento.
Quando um evento é resolvido, ele permanece disponível no Unified Manager como parte do Registro de problemas de desempenho anteriores de um volume. Cada evento tem um ID exclusivo que identifica o tipo de evento e os volumes, o cluster e os componentes do cluster envolvidos.
|
|
Um único volume pode ser envolvido em mais de um evento ao mesmo tempo. |
Estado do evento
Os eventos podem estar em um dos seguintes estados:
-
Ativo
Indica que o evento de desempenho está ativo no momento (novo ou confirmado). O problema que causa o evento não foi corrigido ou não foi resolvido. O contador de performance do objeto de storage permanece acima do limite de performance.
-
Obsoleto
Indica que o evento já não está ativo. O problema que causa o evento foi corrigido ou foi resolvido. O contador de desempenho do objeto de storage não está mais acima do limite de desempenho.
Notificação de evento
Os alertas de eventos são exibidos na página Dashboards/Overview, Dashboards/Performance, Performance/volume Details e são enviados para endereços de e-mail especificados. Você pode visualizar informações detalhadas de análise sobre um evento e obter sugestões para resolvê-lo na página de detalhes do evento.
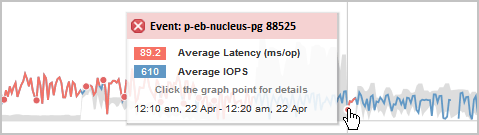
Neste exemplo, um evento é indicado por um ponto vermelho (![]() ) no gráfico de latência na página Detalhes de desempenho/volume. Passar o cursor do Mouse sobre o ponto vermelho exibe um popup com mais detalhes sobre o evento e opções para analisá-lo.
) no gráfico de latência na página Detalhes de desempenho/volume. Passar o cursor do Mouse sobre o ponto vermelho exibe um popup com mais detalhes sobre o evento e opções para analisá-lo.
Interação de eventos
Na página Detalhes de desempenho/volume, você pode interagir com eventos das seguintes maneiras:
-
Mover o ponteiro sobre um ponto vermelho exibe uma mensagem que mostra o ID do evento, juntamente com a latência, o número de operações por segundo e a data e hora em que o evento foi detetado.
Se houver vários eventos para o mesmo período de tempo, a mensagem mostrará o número de eventos, juntamente com a latência média e as operações por segundo para o volume.
-
Clicar em um único evento exibe uma caixa de diálogo que mostra informações mais detalhadas sobre o evento, incluindo os componentes do cluster envolvidos, semelhante à seção Resumo na página Detalhes do evento.
O componente em contenção é circulado e realçado a vermelho. Você pode clicar no ID do evento ou em Exibir análise completa para visualizar a análise completa na página de detalhes do evento. Se houver vários eventos para o mesmo período de tempo, a caixa de diálogo mostra detalhes sobre os três eventos mais recentes. Você pode clicar em um ID de evento para exibir a análise de evento na página de detalhes do evento. Se houver mais de três eventos para o mesmo período de tempo, clicar no ponto vermelho não exibirá a caixa de diálogo.