

Práticas recomendadas operacionais
 Sugerir alterações
Sugerir alterações
As seções a seguir descrevem as práticas recomendadas operacionais para o storage VMware SRM e ONTAP.
Armazenamentos de dados e protocolos
-
Se possível, sempre use ferramentas do ONTAP para provisionar armazenamentos de dados e volumes. Isso garante que volumes, caminhos de junção, LUNs, grupos, políticas de exportação e outras configurações sejam configurados de maneira compatível.
-
O SRM dá suporte a iSCSI, Fibre Channel e NFS versão 3 com ONTAP 9 ao usar replicação baseada em array por meio do SRA. O SRM não dá suporte à replicação baseada em array para NFS versão 4,1 com datastores tradicionais ou vVols.
-
Para confirmar a conectividade, verifique sempre se é possível montar e desmontar um novo datastore de teste no local de DR do cluster do ONTAP de destino. Teste cada protocolo que você pretende usar para a conetividade do datastore. Uma prática recomendada é usar as ferramentas do ONTAP para criar seu datastore de teste, já que ele está fazendo toda a automação do datastore, conforme indicado pelo SRM.
-
Os protocolos SAN devem ser homogêneos para cada local. Você pode misturar NFS e SAN, mas os protocolos SAN não devem ser misturados em um local. Por exemplo, você pode usar FCP no local A e iSCSI no local B. você não deve usar FCP e iSCSI no local A.
-
Guias anteriores aconselharam a criação de LIF para localidade de dados. Ou seja, monte sempre um datastore usando um LIF localizado no nó que possui fisicamente o volume. Embora essa ainda seja a melhor prática, não é mais um requisito nas versões modernas do ONTAP 9. Sempre que possível, e se forem dadas credenciais com escopo de cluster, as ferramentas do ONTAP ainda escolherão o balanceamento de carga entre LIFs locais para os dados, mas não será um requisito de alta disponibilidade ou desempenho.
-
O ONTAP 9 pode ser configurado para remover automaticamente snapshots para preservar o tempo de atividade em caso de uma condição fora do espaço quando o dimensionamento automático não é capaz de fornecer capacidade de emergência suficiente. A configuração padrão para esse recurso não exclui automaticamente os snapshots criados pelo SnapMirror. Se os snapshots do SnapMirror forem excluídos, o NetApp SRA não poderá reverter e ressincronizar a replicação para o volume afetado. Para evitar que o ONTAP elimine instantâneos do SnapMirror, configure a capacidade de instantâneos para "tentar".
snap autodelete modify -volume -commitment try
-
O dimensionamento automático de volume deve ser definido como
growpara volumes que contêm armazenamentos de dados SAN egrow_shrinkpara armazenamentos de dados NFS. Saiba mais sobre este tópico em "Configure volumes para aumentar e diminuir automaticamente o tamanho". -
O SRM tem melhor desempenho quando o número de datastores e, portanto, os grupos de proteção são minimizados em seus planos de recuperação. Portanto, você deve considerar a otimização para a densidade da VM em ambientes protegidos pelo SRM, onde o rto é de importância fundamental.
-
Use o DRS (Distributed Resource Scheduler) para ajudar a equilibrar a carga nos clusters ESXi protegidos e de recuperação. Lembre-se de que, se você planeja fazer o failback, ao executar uma reproteção, os clusters anteriormente protegidos se tornarão os novos clusters de recuperação. O DRS ajudará a equilibrar a colocação em ambas as direções.
-
Sempre que possível, evite usar a personalização de IP com o SRM, pois isso pode aumentar seu rto.
Sobre os pares de array
Um gerenciador de array é criado para cada par de array. Com as ferramentas SRM e ONTAP, cada emparelhamento de array é feito com o escopo de uma SVM, mesmo que você esteja usando credenciais de cluster. Isso permite segmentar fluxos de trabalho de DR entre locatários com base em quais SVMs eles foram atribuídos a gerenciar. Você pode criar vários gerenciadores de array para um determinado cluster, e eles podem ser assimétricos. Você pode fazer fan-out ou fan-out entre diferentes clusters do ONTAP 9. Por exemplo, você pode fazer a replicação do SVM-A e do SVM-B no Cluster-1 para SVM-C no Cluster-2, SVM-D no Cluster-3 ou vice-versa.
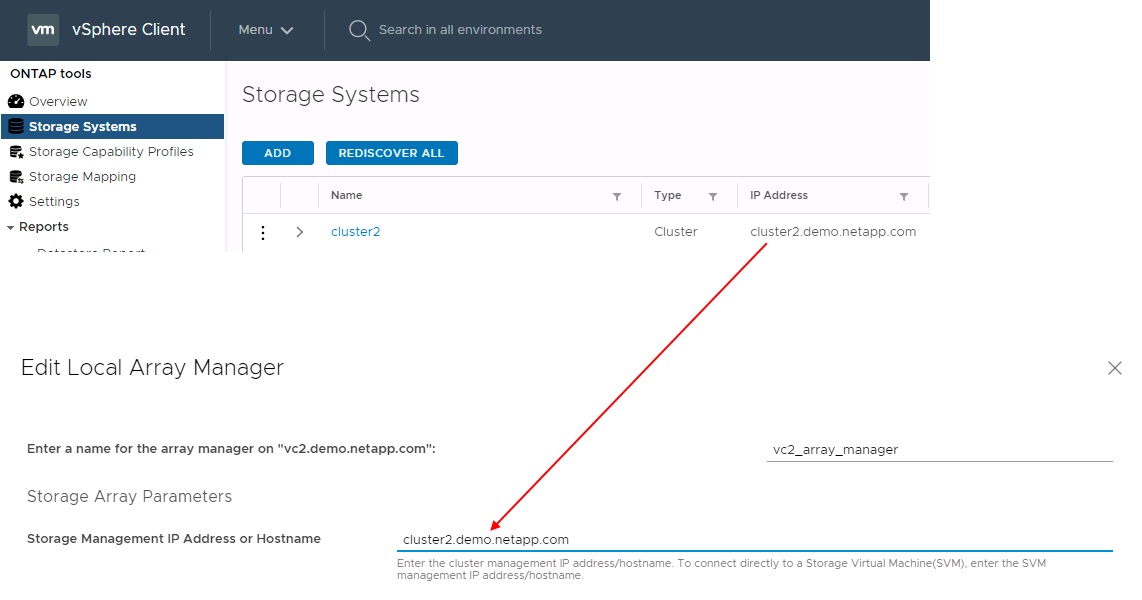
Ao configurar pares de matrizes no SRM, deve sempre adicioná-los no SRM da mesma forma que os adicionou às Ferramentas do ONTAP, ou seja, devem utilizar o mesmo nome de utilizador, palavra-passe e LIF de gestão. Esse requisito garante que o SRA se comunique adequadamente com o array. A captura de tela a seguir ilustra como um cluster pode aparecer nas Ferramentas do ONTAP e como ele pode ser adicionado a um gerenciador de array.
Sobre os grupos de replicação
Os grupos de replicação contêm coleções lógicas de máquinas virtuais que são recuperadas juntas. Como a replicação do ONTAP SnapMirror ocorre no nível do volume, todas as VMs em um volume estão no mesmo grupo de replicação.
Há vários fatores a serem considerados nos grupos de replicação e como você distribui VMs pelos volumes do FlexVol. Agrupar VMs semelhantes no mesmo volume pode aumentar a eficiência de storage com sistemas ONTAP mais antigos que não possuem deduplicação em nível de agregado, mas o agrupamento aumenta o tamanho do volume e reduz a simultaneidade de e/S do volume. O melhor equilíbrio entre performance e eficiência de storage pode ser obtido em sistemas ONTAP modernos, distribuindo máquinas virtuais por volumes FlexVol no mesmo agregado, aproveitando a deduplicação em nível de agregado e obtendo maior paralelização de e/S em vários volumes. Você pode recuperar VMs nos volumes juntos porque um grupo de proteção (discutido abaixo) pode conter vários grupos de replicação. A desvantagem desse layout é que os blocos podem ser transmitidos por cabo várias vezes, porque o SnapMirror não leva em conta a deduplicação agregada.
Uma consideração final para grupos de replicação é que cada um é, por sua natureza, um grupo de consistência lógica (não deve ser confundido com grupos de consistência SRM). Isso ocorre porque todas as VMs no volume são transferidas juntas usando o mesmo snapshot. Portanto, se você tiver VMs que precisam ser consistentes umas com as outras, considere armazená-las no mesmo FlexVol.
Sobre grupos de proteção
Os grupos de proteção definem VMs e datastores em grupos que são recuperados juntos do site protegido. O local protegido é onde as VMs configuradas em um grupo de proteção existem durante operações normais de estado estacionário. É importante notar que, embora o SRM possa exibir vários gerenciadores de matriz para um grupo de proteção, um grupo de proteção não pode abranger vários gerenciadores de matriz. Por esse motivo, você não deve estender arquivos de VM entre armazenamentos de dados em diferentes SVMs.
Sobre planos de recuperação
Os planos de recuperação definem quais grupos de proteção são recuperados no mesmo processo. Vários grupos de proteção podem ser configurados no mesmo plano de recuperação. Além disso, para permitir mais opções para a execução de planos de recuperação, um único grupo de proteção pode ser incluído em vários planos de recuperação.
Os planos de recuperação permitem que os administradores do SRM definam fluxos de trabalho de recuperação atribuindo VMs a um grupo de prioridades de 1 (mais alto) a 5 (mais baixo), sendo 3 (médio) o padrão. Dentro de um grupo de prioridade, as VMs podem ser configuradas para dependências.
Por exemplo, sua empresa pode ter um aplicativo essencial para negócios de nível 1 que depende de um servidor Microsoft SQL para seu banco de dados. Então, você decide colocar suas VMs no grupo de prioridades 1. No grupo de prioridade 1, você começa a Planejar o pedido para abrir serviços. Você provavelmente quer que o controlador de domínio do Microsoft Windows seja inicializado antes do servidor Microsoft SQL, que precisaria estar online antes do servidor de aplicativos, e assim por diante. Você adicionaria todas essas VMs ao grupo de prioridade e, em seguida, definiria as dependências porque as dependências se aplicam somente a um determinado grupo de prioridade.
A NetApp recomenda fortemente que você trabalhe com suas equipes de aplicações para entender a ordem das operações necessárias em um cenário de failover e para construir seus planos de recuperação adequadamente.
Failover de teste
Como prática recomendada, sempre execute um failover de teste sempre que for feita uma alteração na configuração do storage de VM protegido. Isso garante que, no caso de um desastre, você possa confiar que o Site Recovery Manager pode restaurar serviços dentro do destino de rto esperado.
O NetApp também recomenda confirmar ocasionalmente a funcionalidade do aplicativo in-Guest, especialmente depois de reconfigurar o armazenamento de VM.
Quando uma operação de recuperação de teste é executada, uma rede privada de bolhas de teste é criada no host ESXi para as VMs. No entanto, essa rede não é conetada automaticamente a nenhum adaptador de rede físico e, portanto, não fornece conetividade entre os hosts ESXi. Para permitir a comunicação entre VMs que estão sendo executadas em diferentes hosts ESXi durante o teste de DR, uma rede privada física é criada entre os hosts ESXi no local de DR. Para verificar se a rede de teste é privada, a rede de bolhas de teste pode ser separada fisicamente ou usando VLANs ou marcação de VLAN. Essa rede deve ser segregada da rede de produção porque, à medida que as VMs são recuperadas, elas não podem ser colocadas na rede de produção com endereços IP que podem entrar em conflito com os sistemas de produção reais. Quando um plano de recuperação é criado no SRM, a rede de teste criada pode ser selecionada como a rede privada para conetar as VMs durante o teste.
Depois que o teste tiver sido validado e não for mais necessário, execute uma operação de limpeza. A limpeza em execução retorna as VMs protegidas ao seu estado inicial e redefine o plano de recuperação para o estado Pronto.
Considerações sobre failover
Há várias outras considerações quando se trata de falhar em um local, além da ordem de operações mencionada neste guia.
Um problema que você pode ter que lidar com as diferenças de rede entre sites. Alguns ambientes podem ser capazes de usar os mesmos endereços IP de rede no local principal e no local de DR. Essa capacidade é referida como uma LAN virtual (VLAN) estendida ou configuração de rede estendida. Outros ambientes podem ter um requisito para usar endereços IP de rede diferentes (por exemplo, em VLANs diferentes) no local principal em relação ao local de DR.
A VMware oferece várias maneiras de resolver esse problema. Por um lado, tecnologias de virtualização de rede como o VMware NSX-T Data Center abstraem toda a pilha de rede das camadas 2 a 7 do ambiente operacional, permitindo soluções mais portáteis. Saiba mais "Opções NSX-T com SRM"sobre o .
O SRM também lhe dá a capacidade de alterar a configuração de rede de uma VM à medida que ela é recuperada. Essa reconfiguração inclui configurações como endereços IP, endereços de gateway e configurações de servidor DNS. Diferentes configurações de rede, que são aplicadas a VMs individuais à medida que são recuperadas, podem ser especificadas nas configurações da propriedade de uma VM no plano de recuperação.
Para configurar o SRM para aplicar diferentes configurações de rede a várias VMs sem ter que editar as propriedades de cada uma no plano de recuperação, a VMware fornece uma ferramenta chamada DR-ip-Customizer. Saiba como usar este utilitário, "Documentação da VMware"consulte .
Reproteger
Após uma recuperação, o local de recuperação se torna o novo local de produção. Como a operação de recuperação quebrou a replicação do SnapMirror, o novo local de produção não fica protegido de nenhum desastre futuro. Uma prática recomendada é proteger o novo local de produção para outro local imediatamente após uma recuperação. Se o local de produção original estiver operacional, o administrador da VMware poderá usar o local de produção original como um novo local de recuperação para proteger o novo local de produção, invertendo efetivamente o sentido de proteção. A reproteção está disponível apenas em falhas não catastróficas. Portanto, os vCenter Servers originais, os servidores ESXi, os servidores SRM e os bancos de dados correspondentes devem ser eventualmente recuperáveis. Se eles não estiverem disponíveis, um novo grupo de proteção e um novo plano de recuperação devem ser criados.
Failback
Uma operação de failback é fundamentalmente um failover em uma direção diferente do anterior. Como prática recomendada, você verifica se o site original está de volta aos níveis aceitáveis de funcionalidade antes de tentar failback ou, em outras palavras, failover para o site original. Se o local original ainda estiver comprometido, você deve atrasar o failback até que a falha seja suficientemente remediada.
Outra prática recomendada de failback é sempre executar um failover de teste após concluir a reproteção e antes de fazer seu failback final. Isso verifica se os sistemas no local original podem concluir a operação.
Reproteger o site original
Após o failback, você deve confirmar com todas as partes interessadas que seus serviços foram devolvidos ao normal antes de executar o reprotect novamente,
A execução do reprotect After failback coloca essencialmente o ambiente de volta ao estado em que estava no início, com a replicação do SnapMirror sendo executada novamente do local de produção para o local de recuperação.