

Atualização manual de ONTAP sem interrupções de uma configuração de MetroCluster de quatro ou oito nós usando a CLI
 Sugerir alterações
Sugerir alterações
Uma atualização manual de uma configuração do MetroCluster de quatro ou oito nós envolve a preparação para a atualização, a atualização dos pares de DR em cada um dos um ou dois grupos de DR simultaneamente e a execução de tarefas pós-atualização.
-
Esta tarefa aplica-se às seguintes configurações:
-
Configurações IP ou FC MetroCluster de quatro nós executando o ONTAP 9.2 ou anterior
-
Configurações de FC MetroCluster de oito nós, independentemente da versão do ONTAP
-
-
Se você tiver uma configuração de MetroCluster de dois nós, não use este procedimento.
-
As seguintes tarefas referem-se às versões antigas e novas do ONTAP.
-
Ao atualizar, a versão antiga é uma versão anterior do ONTAP, com um número de versão menor do que a nova versão do ONTAP.
-
Ao fazer o downgrade, a versão antiga é uma versão posterior do ONTAP, com um número de versão maior do que a nova versão do ONTAP.
-
-
Esta tarefa utiliza o seguinte fluxo de trabalho de alto nível:
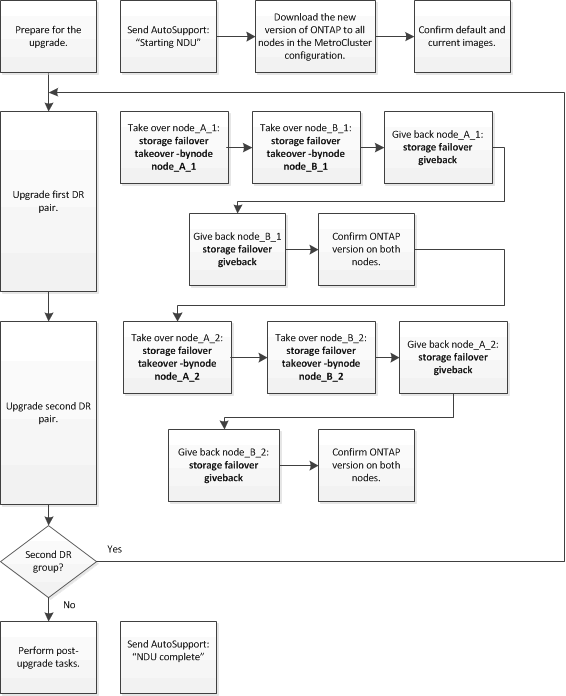
Diferenças ao atualizar o software ONTAP em uma configuração de MetroCluster de oito ou quatro nós
O processo de atualização do software MetroCluster difere, dependendo se há oito ou quatro nós na configuração do MetroCluster.
Uma configuração do MetroCluster consiste em um ou dois grupos de DR. Cada grupo de DR consiste em dois pares de HA, um par de HA em cada cluster do MetroCluster. Um MetroCluster de oito nós inclui dois grupos de DR:
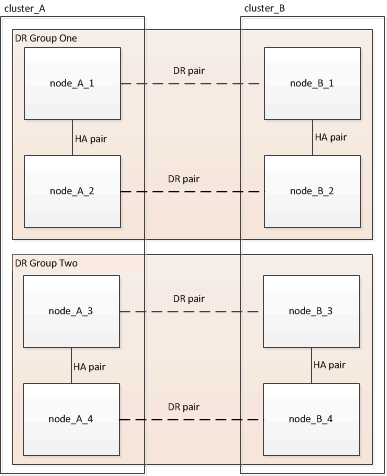
Você atualiza um grupo de DR de cada vez.
-
Atualizar o grupo de RD 1:
-
Atualize node_A_1 e node_B_1.
-
Atualize node_A_2 e node_B_2.
-
-
Atualizar o grupo de RD 1:
-
Atualize node_A_1 e node_B_1.
-
Atualize node_A_2 e node_B_2.
-
-
Atualizar Grupo DR dois:
-
Atualize node_A_3 e node_B_3.
-
Atualize node_A_4 e node_B_4.
-
Preparando-se para atualizar um grupo de DR do MetroCluster
Antes de atualizar o software ONTAP nos nós, você deve identificar as relações de DR entre os nós, enviar uma mensagem do AutoSupport informando que você está iniciando uma atualização e confirmar a versão do ONTAP em execução em cada nó.
Você deve ter "transferido" e "instalado" as imagens de software.
Essa tarefa deve ser repetida em cada grupo de DR. Se a configuração do MetroCluster consistir em oito nós, haverá dois grupos de DR. Assim, essa tarefa deve ser repetida em cada grupo de DR.
Os exemplos fornecidos nesta tarefa usam os nomes mostrados na ilustração a seguir para identificar os clusters e nós:
-
Identifique os pares de DR na configuração:
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
Defina o nível de privilégio de admin para Advanced, inserindo y quando solicitado a continuar:
set -privilege advanced(`*>`É apresentado o aviso avançado ).
-
Confirme a versão do ONTAP no cluster_A:
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confirme a versão no cluster_B:
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Acione uma notificação AutoSupport:
autosupport invoke -node * -type all -message "Starting_NDU"Esta notificação do AutoSupport inclui um registo do estado do sistema antes da atualização. Ele salva informações úteis de solução de problemas se houver um problema com o processo de atualização.
Se o cluster não estiver configurado para enviar mensagens AutoSupport, uma cópia da notificação será salva localmente.
-
Para cada nó no primeiro conjunto, defina a imagem do software ONTAP de destino como a imagem padrão:
system image modify {-node nodename -iscurrent false} -isdefault trueEste comando usa uma consulta estendida para alterar a imagem do software de destino, que é instalada como imagem alternativa, para ser a imagem padrão para o nó.
-
Verifique se a imagem do software ONTAP de destino está definida como a imagem padrão no cluster_A:
system image showNo exemplo a seguir, image2 é a nova versão do ONTAP e é definida como a imagem padrão em cada um dos nós no primeiro conjunto:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
Verifique se a imagem do software ONTAP de destino está definida como a imagem padrão no cluster_B:
system image showO exemplo a seguir mostra que a versão de destino é definida como a imagem padrão em cada um dos nós no primeiro conjunto:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
Determine se os nós a serem atualizados estão atendendo a clientes duas vezes para cada nó:
system node run -node target-node -command uptimeO comando uptime exibe o número total de operações que o nó executou para clientes NFS, CIFS, FC e iSCSI desde que o nó foi inicializado pela última vez. Para cada protocolo, você precisa executar o comando duas vezes para determinar se as contagens de operação estão aumentando. Se eles estão aumentando, o nó está atendendo clientes para esse protocolo no momento. Se eles não estiverem aumentando, o nó não estará atendendo clientes para esse protocolo.

Você deve fazer uma nota de cada protocolo que tem operações de cliente crescentes para que, após o nó ser atualizado, você possa verificar se o tráfego de cliente foi retomado. Este exemplo mostra um nó com operações NFS, CIFS, FC e iSCSI. No entanto, o nó está atualmente atendendo apenas clientes NFS e iSCSI.
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
Atualizando o primeiro par de DR em um grupo de DR do MetroCluster
Você precisa executar um takeover e giveback dos nós na ordem correta para fazer da nova versão do ONTAP a versão atual do nó.
Todos os nós devem estar executando a versão antiga do ONTAP.
Nesta tarefa, node_A_1 e node_B_1 são atualizados.
Se você atualizou o software ONTAP no primeiro grupo DR e está atualizando o segundo grupo DR em uma configuração de MetroCluster de oito nós, nesta tarefa você estaria atualizando node_A_3 e node_B_3.
-
Migre todos os LIFs de dados para fora do nó:
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
Se o software MetroCluster Tiebreaker estiver ativado, desative-o.
-
Para cada nó no par de HA, desative a opção giveback automática:
storage failover modify -node target-node -auto-giveback falseEsse comando deve ser repetido para cada nó no par de HA.
-
Verifique se a giveback automática está desativada:
storage failover show -fields auto-givebackEste exemplo mostra que o giveback automático foi desativado em ambos os nós:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
Certifique-se de que a e/S não exceda os aproximadamente 50% para cada controladora e que a utilização de CPU não exceda os aproximadamente 50% por controladora.
-
Inicie um takeover do nó de destino no cluster_A:
Não especifique o parâmetro -option immediate, porque um controle normal é necessário para os nós que estão sendo levados para inicializar na nova imagem de software.
-
Assuma o parceiro DR no cluster_A (node_a_1):
storage failover takeover -ofnode node_A_1O nó inicializa até o estado "aguardando pela giveback".
Se o AutoSupport estiver ativado, uma mensagem AutoSupport será enviada indicando que os nós estão fora do quórum do cluster. Você pode ignorar esta notificação e prosseguir com a atualização. -
Verifique se a aquisição foi bem-sucedida:
storage failover showO exemplo a seguir mostra que a aquisição foi bem-sucedida. Node_A_1 está no estado "aguardando giveback" e node_A_2 está no estado "na aquisição".
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
Assuma o parceiro DR no cluster_B (node_B_1):
Não especifique o parâmetro -option immediate, porque um controle normal é necessário para os nós que estão sendo levados para inicializar na nova imagem de software.
-
Assumir node_B_1:
storage failover takeover -ofnode node_B_1O nó inicializa até o estado "aguardando pela giveback".
Se o AutoSupport estiver ativado, uma mensagem AutoSupport será enviada indicando que os nós estão fora do quórum do cluster. Você pode ignorar esta notificação e prosseguir com a atualização. -
Verifique se a aquisição foi bem-sucedida:
storage failover showO exemplo a seguir mostra que a aquisição foi bem-sucedida. Node_B_1 está no estado "aguardando giveback" e node_B_2 está no estado "em aquisição".
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
Aguarde pelo menos oito minutos para garantir as seguintes condições:
-
O multipathing do cliente (se implantado) está estabilizado.
-
Os clientes são recuperados da pausa na I/o que ocorre durante a aquisição.
O tempo de recuperação é específico do cliente e pode demorar mais de oito minutos, dependendo das caraterísticas dos aplicativos cliente.
-
-
Retornar os agregados aos nós de destino:
Depois de atualizar as configurações IP do MetroCluster para o ONTAP 9.5 ou posterior, os agregados ficarão em estado degradado por um curto período antes da ressincronização e retorno a um estado espelhado.
-
Devolver os agregados ao parceiro de DR no cluster_A:
storage failover giveback -ofnode node_A_1 -
Devolver os agregados ao parceiro de DR no cluster_B:
storage failover giveback -ofnode node_B_1A operação giveback primeiro retorna o agregado raiz para o nó e, depois que o nó terminar de inicializar, retorna os agregados não-raiz.
-
-
Verifique se todos os agregados foram retornados emitindo o seguinte comando em ambos os clusters:
storage failover show-givebackSe o campo Status do Giveback indicar que não há agregados para devolver, todos os agregados foram retornados. Se o giveback for vetado, o comando exibirá o progresso da giveback e qual subsistema vetou a giveback.
-
Se algum agregado não tiver sido devolvido, faça o seguinte:
-
Revise a solução alternativa de veto para determinar se você deseja abordar a condição "para" ou substituir o veto.
-
Se necessário, aborde a condição "para" descrita na mensagem de erro, garantindo que todas as operações identificadas sejam terminadas graciosamente.
-
Reinsira o comando Storage failover giveback.
Se você decidiu substituir a condição "para", defina o parâmetro -override-vetos como true.
-
-
Aguarde pelo menos oito minutos para garantir as seguintes condições:
-
O multipathing do cliente (se implantado) está estabilizado.
-
Os clientes são recuperados da pausa em I/o que ocorre durante a giveback.
O tempo de recuperação é específico do cliente e pode demorar mais de oito minutos, dependendo das caraterísticas dos aplicativos cliente.
-
-
Defina o nível de privilégio de admin para Advanced, inserindo y quando solicitado a continuar:
set -privilege advanced(`*>`É apresentado o aviso avançado ).
-
Confirme a versão no cluster_A:
system image showO exemplo a seguir mostra que a system image2 (imagem ONTAP de destino) é a versão padrão e atual no node_A_1:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confirme a versão no cluster_B:
system image showO exemplo a seguir mostra que a imagem do sistema image2 (imagem ONTAP de destino) é a versão padrão e atual no node_B_1:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
Atualizando o segundo par de DR em um grupo de DR do MetroCluster
Você precisa executar um takeover e giveback do nó na ordem correta para fazer da nova versão do ONTAP a versão atual do nó.
Você deve ter atualizado o primeiro par de DR (node_A_1 e node_B_1).
Nesta tarefa, node_A_2 e node_B_2 são atualizados.
Se você atualizou o software ONTAP no primeiro grupo de DR e está atualizando o segundo grupo de DR em uma configuração de MetroCluster de oito nós, nesta tarefa você está atualizando node_A_4 e node_B_4.
-
Migre todos os LIFs de dados para fora do nó:
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
Inicie um takeover do nó de destino no cluster_A:
Não especifique o parâmetro -option immediate, porque um controle normal é necessário para os nós que estão sendo levados para inicializar na nova imagem de software.
-
Assuma o controle do parceiro DR no cluster_A:
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
A allow-version-mismatchopção não é necessária para atualizações do ONTAP 9.0 para o ONTAP 9.1 ou para quaisquer atualizações de patch.O nó inicializa até o estado "aguardando pela giveback".
Se o AutoSupport estiver ativado, uma mensagem AutoSupport será enviada indicando que os nós estão fora do quórum do cluster. Você pode ignorar esta notificação e prosseguir com a atualização.
-
Verifique se a aquisição foi bem-sucedida:
storage failover showO exemplo a seguir mostra que a aquisição foi bem-sucedida. Node_A_2 está no estado "aguardando giveback" e node_A_1 está no estado "na aquisição".
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Inicie um takeover do nó de destino no cluster_B:
Não especifique o parâmetro -option immediate, porque um controle normal é necessário para os nós que estão sendo levados para inicializar na nova imagem de software.
-
Assuma o parceiro DR no cluster_B (node_B_2):
Se você está atualizando de… Digite este comando… ONTAP 9.2 ou ONTAP 9.1
storage failover takeover -ofnode node_B_2ONTAP 9 .0 ou Data ONTAP 8.3.x
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
A allow-version-mismatchopção não é necessária para atualizações do ONTAP 9.0 para o ONTAP 9.1 ou para quaisquer atualizações de patch.O nó inicializa até o estado "aguardando pela giveback".
Se o AutoSupport estiver habilitado, uma mensagem AutoSupport será enviada indicando que os nós estão fora do quórum do cluster. Você pode ignorar esta notificação com segurança e prosseguir com a atualização. -
Verifique se a aquisição foi bem-sucedida:
storage failover showO exemplo a seguir mostra que a aquisição foi bem-sucedida. Node_B_2 está no estado "aguardando giveback" e node_B_1 está no estado "em aquisição".
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
Aguarde pelo menos oito minutos para garantir as seguintes condições:
-
O multipathing do cliente (se implantado) está estabilizado.
-
Os clientes são recuperados da pausa na I/o que ocorre durante a aquisição.
O tempo de recuperação é específico do cliente e pode demorar mais de oito minutos, dependendo das caraterísticas dos aplicativos cliente.
-
-
Retornar os agregados aos nós de destino:
Depois de atualizar as configurações IP do MetroCluster para o ONTAP 9.5, os agregados estarão em um estado degradado por um curto período antes da ressincronização e retorno a um estado espelhado.
-
Devolver os agregados ao parceiro de DR no cluster_A:
storage failover giveback -ofnode node_A_2 -
Devolver os agregados ao parceiro de DR no cluster_B:
storage failover giveback -ofnode node_B_2A operação giveback primeiro retorna o agregado raiz para o nó e, depois que o nó terminar de inicializar, retorna os agregados não-raiz.
-
-
Verifique se todos os agregados foram retornados emitindo o seguinte comando em ambos os clusters:
storage failover show-givebackSe o campo Status do Giveback indicar que não há agregados para devolver, todos os agregados foram retornados. Se o giveback for vetado, o comando exibirá o progresso da giveback e qual subsistema vetou a giveback.
-
Se algum agregado não tiver sido devolvido, faça o seguinte:
-
Revise a solução alternativa de veto para determinar se você deseja abordar a condição "para" ou substituir o veto.
-
Se necessário, aborde a condição "para" descrita na mensagem de erro, garantindo que todas as operações identificadas sejam terminadas graciosamente.
-
Reinsira o comando Storage failover giveback.
Se você decidiu substituir a condição "para", defina o parâmetro -override-vetos como true.
-
-
Aguarde pelo menos oito minutos para garantir as seguintes condições:
-
O multipathing do cliente (se implantado) está estabilizado.
-
Os clientes são recuperados da pausa em I/o que ocorre durante a giveback.
O tempo de recuperação é específico do cliente e pode demorar mais de oito minutos, dependendo das caraterísticas dos aplicativos cliente.
-
-
Defina o nível de privilégio de admin para Advanced, inserindo y quando solicitado a continuar:
set -privilege advanced(`*>`É apresentado o aviso avançado ).
-
Confirme a versão no cluster_A:
system image showO exemplo a seguir mostra que a imagem do sistema image2 (imagem ONTAP de destino) é a versão padrão e atual no node_A_2:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
Confirme a versão no cluster_B:
system image showO exemplo a seguir mostra que a system image2 (imagem ONTAP de destino) é a versão padrão e atual no node_B_2:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
Para cada nó no par de HA, habilite a giveback automática:
storage failover modify -node target-node -auto-giveback trueEsse comando deve ser repetido para cada nó no par de HA.
-
Verifique se o giveback automático está ativado:
storage failover show -fields auto-givebackEste exemplo mostra que o giveback automático foi ativado em ambos os nós:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.