

Performance
 Suggest changes
Suggest changes
NetApp AFX was built with performance and scale in mind – specifically geared towards workloads that require high read and write throughput and can provide simple, linear scale.
Per-node performance
Each NetApp AFX storage node provides a specific amount of throughput for reads and writes. As nodes are added to the cluster, they linearly increase that performance, as covered in the "Linear scaling of node performance" section in this document.
Currently, the node types are AFX 1K and provide throughput for reads and writes at roughly the amounts below. As newer hardware is available to NetApp AFX, these limits may change. NOTE: Maximum performance was reached using multiple clients reading and writing multiple files as shown in the "Benchmark results" section below.
Per-node performance estimates
| Node type | Read performance max | Write performance max |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
For the most up-to-date performance estimates, check with your NetApp sales team. |
Per-shelf performance
Each shelf contains high performance shelf modules with 16 x 100GB Ethernet ports that leverage RoCEv2 communication for high bandwidth storage interaction with the compute nodes in the cluster. Like any physical resource, these shelves have maximums that can be achieved – particularly since NetApp AFX can present multiple nodes pointing to the same set of disks. The following table shows the estimated maximum read and write performance for a single shelf for TLC and QLC drives. For more information on TLC and QLC differences, see TLC vs. QLC.
Per-shelf performance estimates
| Shelf module type | Read performance max | Write performance max |
|---|---|---|
NSM 140 |
140GB/s (TLC and QLC) |
70GB/s TLC 35GB/s QLC |
|
|
For the most up-to-date performance estimates, check with your NetApp sales team. |
Performance density
Decoupling storage nodes from shelves in the disaggregated ONTAP architecture allows for more nodes to push traffic to fewer shelves, which helps reduce the overall datacenter footprint needed to get maximum performance with only the capacity you need.
This concept of "performance density" enables storage administrators to get the most out of the hardware they have while never having to overprovision their storage environment.
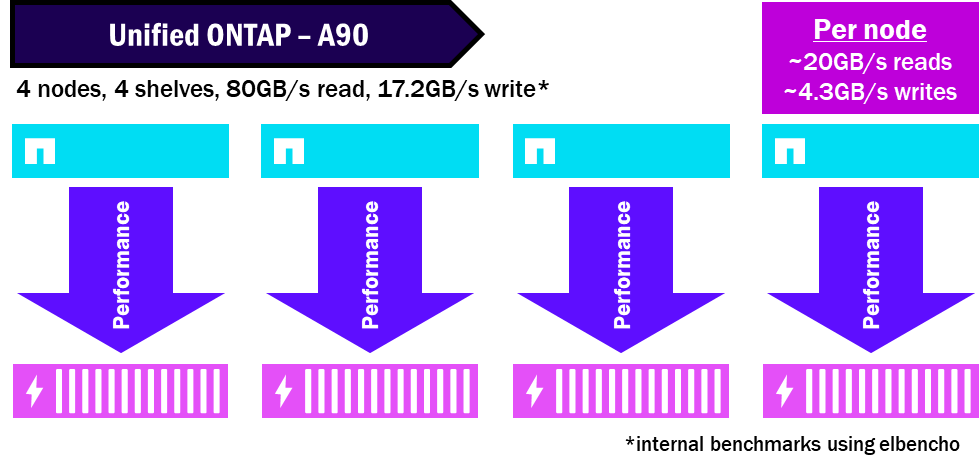
For instance, in a unified ONTAP cluster, since each node has its own set of disks, the performance is directed only to the disks owned by the node, and since only one node can access one set of disks, it can't necessarily saturate the available disks and achieve its maximum performance.
Unified ONTAP – How performance is divided up
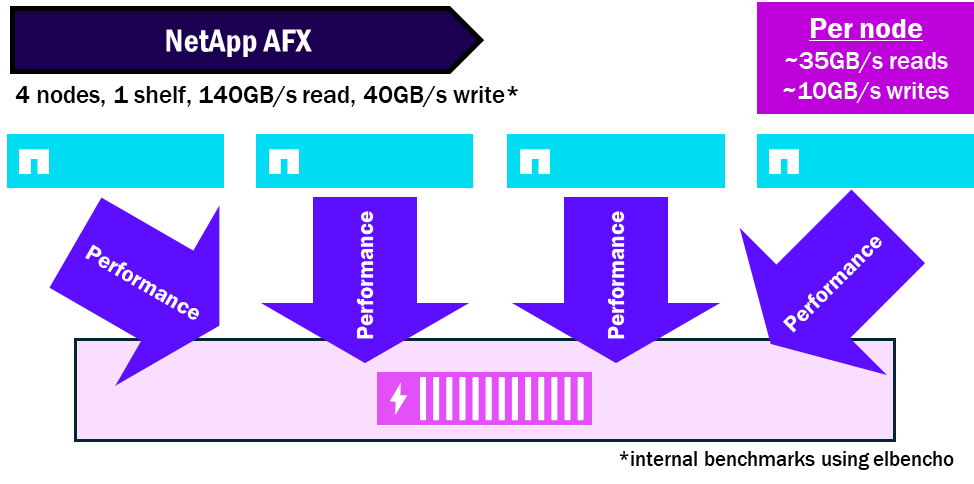
NetApp AFX pools all the disks into a single Storage Availability Zone, so all nodes can leverage all the disks. And because the disks and nodes are decoupled, you won't need as many shelves to get the same performance. This condenses down the performance and maximizes the shelf's maximum performance potential.
NetApp AFX – Performance density
Node to shelf ratios
Unified ONTAP nodes require at least one set of disks per node and can have multiple shelves attached to a single node. As a result, there can be performance bottlenecks at the single node that may not be able to saturate its own disks.
NetApp AFX presents all disk shelves to all nodes. Each shelf contains modules with 16 x 100GB RoCE-capable interfaces to increase the total amount of performance allowed per shelf. Because of this, you can saturate a single shelf with multiple nodes that will be reading and writing to the same set of disks.
As of ONTAP 9.19.1, the node:shelf saturation ratio is around 4:1.
Benchmark results
The following section covers benchmark results using a NetApp AFX cluster with the following configuration parameters.
-
4 nodes, 4 data interfaces
-
2 shelves (7.6TB drives)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, session trunking)
-
FlexGroup volume
-
ElBencho benchmark
-
Writes: elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
Reads: elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 Cisco C240 M8 servers, 2 port * 200GbE CX-7 cards, 80 threads
-
NFS mount options: rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
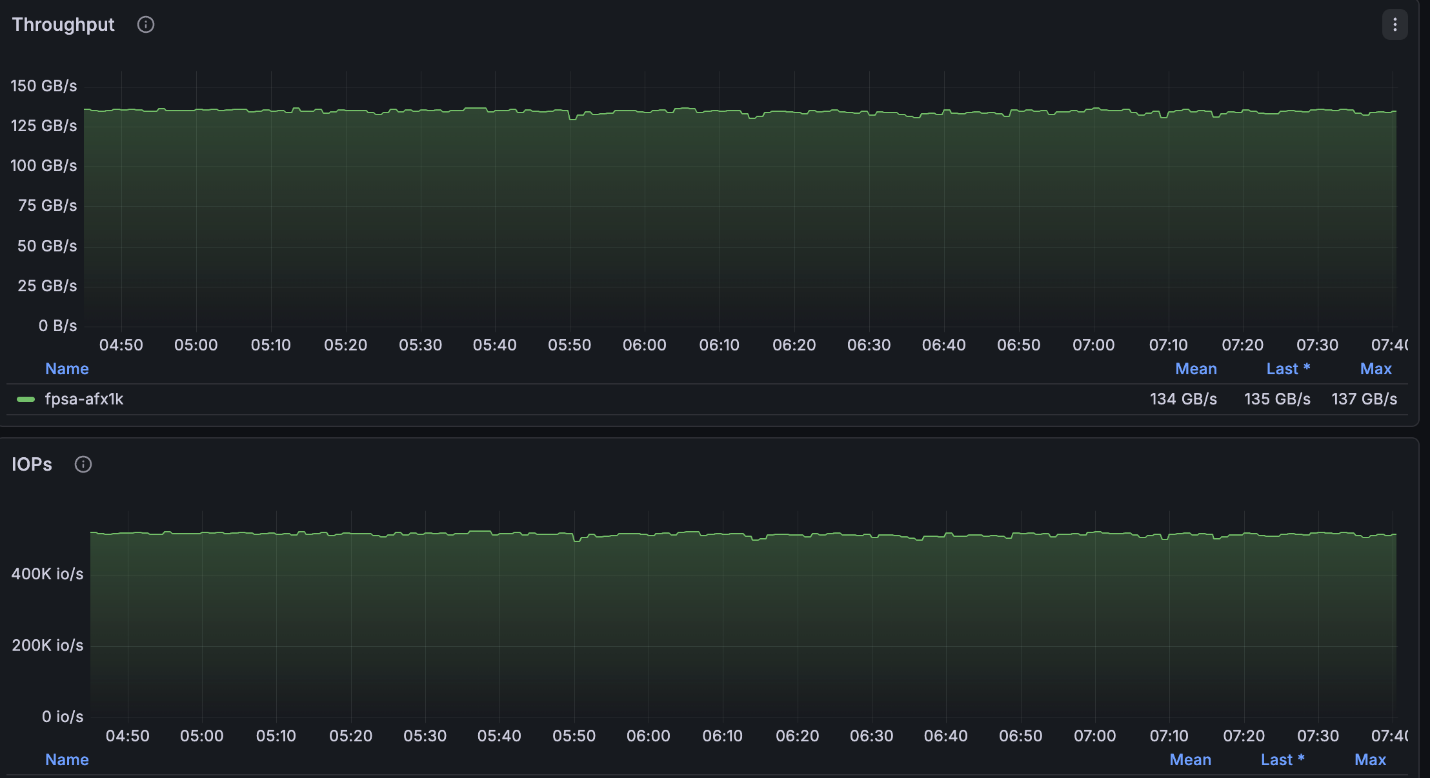
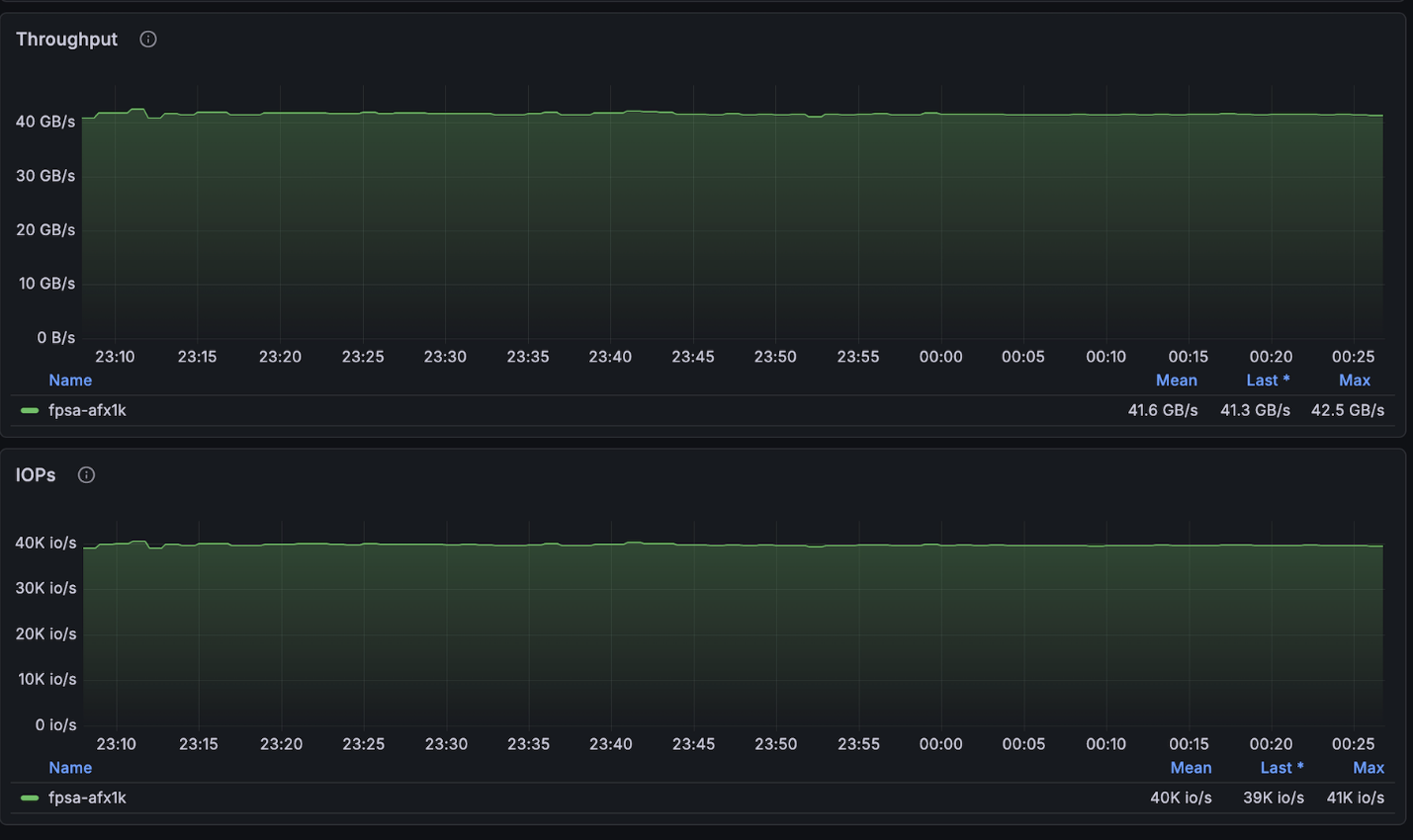
The configuration above achieved very near the maximum reads available to the 4-node cluster (~134GB/s) and was right at the maximum writes allowed per node (40GB/s).
NetApp AFX – ElBencho read performance, 4 nodes
NetApp AFX – ElBencho write performance, 4 nodes
Aggressive read-ahead
In media streaming workloads, a 4K movie is often split into tens of thousands of files, each typically 50 MB to 250 MB in size. Each file represents a frame, and the application reads an entire frame in a single request. To maintain a smooth, uninterrupted stream with no visible buffering, these frame reads must complete without drops.
ONTAP provides a volume-level option (-aggressive-readahead-mode) to optimize these workloads. Starting in ONTAP 9.19.1, a new cross_file_sequential_read mode for aggressive readahead has been introduced on AFX to accelerate workloads with predictable I/O patterns across similar file types (for example, media rendering and streaming).
cross_file_sequential_read predicts the next file to be read based on its name and begins readahead on those files before the client issues the read call. The prediction logic assumes that all files in a directory follow a naming pattern with a monotonically increasing numeric suffix (eg. file1, file2, file3). All files in the directory must follow this pattern, using either decimal or hexadecimal numbering. Filenames can be up to 255 characters long. The logic is extensionagnostic and generates the next set of filenames in the current directory based solely on the current filename. If a filename previously generated using base10 numbering does not exist in the directory, the names are regenerated using hexadecimal numbering. If none of the generated filenames exist, no prefetch is issued for that set. Prefetching resumes when the next client read is issued.
With these options enabled, frametest performance benchmarks were able to read 30,000 4K frames at 30 frames per second with 30 clients (NFSv3 and SMB3) and 34 clients (NFSv4.1), without a single dropped frame.
While cross-file sequential read is primarily designed for media workloads, other readheavy workloads with predictable access patterns and file names - such as AI training and inference - can also benefit.
Considerations and caveats
-
Shared buffer cache – Aggressive read ahead uses the same buffer cache as other volumes on the node. Enabling it may affect read performance for other volumes on that node.
-
Underlying storage performance – If files cannot be read quickly enough (for example, on HDD-based FAS systems), cached data may be evicted before the client read occurs, negating the benefits of read ahead.
-
Access pattern requirements – If the workload's read pattern is not sequential, or if files in a directory are not named in an increasing sequential order, the cross_file_sequential_read aggressive read ahead mode will not provide meaningful benefits.
NFSv4.x performance enhancements
NFS version 3 has been a gold standard for NFS applications for decades – starting all the way back in 1995, when it was first officially released. Its blend of performance and resiliency has made it difficult to consider a move to newer NFS versions for good reason.
However, NFSv3 is not without its limitations. Statelessness of the protocol, while great for performance and for minimizing disruptions on storage failover, is not so great for data consistency and lock management. An NFS server doesn't really keep track of lock states, so if there is a failure, the NFS server may or may not release the locks, and the NFS client may not know whether a file is locked or not.
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]).
While NFSv4.x has been around for over 20 years, there still hasn't been widespread adoption of it for a few reasons.
-
Complexity of identity management: Many environments don't have a name service infrastructure in place to properly take advantage of the name string and Kerberos security requirements in NFSv4.x.
-
Need for newer NFS clients: This concern is less pressing in today's modern NFS environments, as the further we get from the initial release date of NFSv4. Almost all currently used OS's include NFS clients with full NFsv4 support, but there are still legacy systems that may not have the necessary NFSv4.x packages. In fact, some applications still require use of older NFS versions.
-
"If it ain't broke, don't fix it" mentality: Enterprise IT organizations are notoriously conservative in adoption of newer technologies – even ones that have been around for over 20 years. And if the current NFS version is working fine, why change?
-
Performance concerns: Performance of a stateful protocol like NFSv4.x has lagged behind stateless NFSv3 for much of the past 20 years. In the past, the performance impact often outweighed the NFSv4.x benefits.
NFSv4.x improvements in ONTAP 9.18.1 using AFX
Some architectural changes to ONTAP have provided a much needed performance boost to NFS in general, and have made some serious inroads to improving NFSv4.x performance in general.
Below is a high-level summary of some of those changes.
Sequential read enhancement: NFSv4.1 30% better than NFSv3
ONTAP 9.18.1 introduces support for multipath IO with NFSv4.1. Rather than processing reads from the WAFL file system, MPIO shifts read operations into a network domain to be served in a multipath-safe manner. This approach reduces context switches, providing greater overall parallelism in sequential read traffic, as well as reducing the overhead from buffer management by bypassing WAFL.
Random read enhancement for FlexGroup volumes: NFSv4.1 within 7% of NFSv3
FlexGroup volumes are volumes that take many underlying constituent volumes and present them as a single unified namespace. In AFX, FlexGroup volumes have Advanced Capacity Balancing enabled by default, which will write files larger than 10GB across multiple constituent volumes as multipart files. Because of the remote location of these file parts, random reads traditionally have had a modest perf disadvantage with NFSv4.x (around 18% less than NFSv3). ONTAP 9.18.1 introduces support for cached IO for multipart reads with NFSv4.x to help address this. NOTE: This change does not apply to FlexVol volumes.
Sequential writes: +10% improvement from previous releases
An improvement of how we replicate NVLOG data used for HA failover functionality increased overall sequential write performance for NetApp AFX systems.
Metadata operations: Within 15% performance of NFSv3 for EDA benchmarks
NFSv4.1 traditionally serializes all OPEN and CLOSE operations, with a cluster node processing them one at a time before they can be sent from the network to WAFL. ONTAP 9.18.1 introduces Concurrent Open Close (COC), which eliminates network serialization by changing how race conditions are resolved, which removes OPEN/CLOSE bottlenecks seen in prior releases.
All of these changes – along with the architecture changes brought about in AFX – have made it possible to improve the overall NFSv4.1 performance in ONTAP 9.18.1.
Sequential IO results
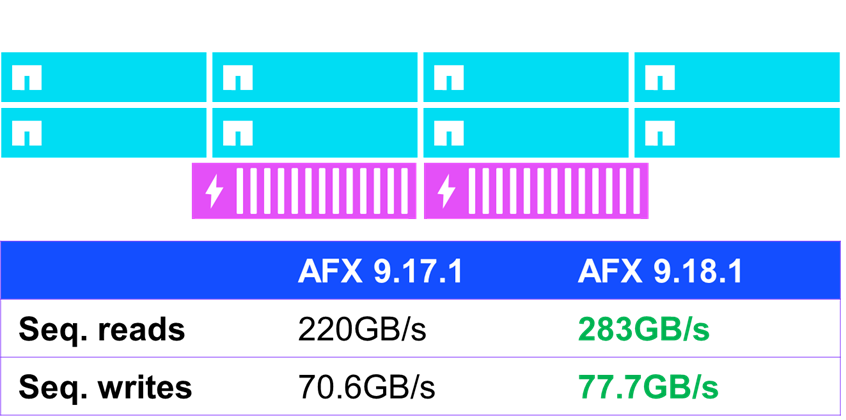
One of the areas where some modest performance improvements were seen was with sequential IO (ie, IO that is predictable and issued consecutively). In standard performance tests using fio, AFX running ONTAP 9.18.1 improved sequential read performance by nearly 30% and sequential write performance by 10%.
NetApp AFX – NFSv4.1 sequential IO performance in ONTAP 9.18.1
Metadata-heavy workload results
Even more impressive are the improvements with one of NFSv4.x's top performance pain points – metadata. These are random IOs, usually in the 4K range, used to manage file owners and attributes, creating and listing files, and so on. Because of the statefulness of NFSv4.x, these types of operations tend to cost more in CPU and latency, which in turn reduces overall possible performance.
With the changes in AFX ONTAP 9.18.1, NFSv4.x performance for these types of workloads has improved substantially and has closed the gap on NFSv3 performance (within 15%).
Our performance engineering teams compared performance of standard AI image, EDA, and software build benchmarks and found massive gains from the previous ONTAP release.
NetApp AFX – NFSv4.1 metadata IO performance in ONTAP 9.18.1
