

客户用例
 建议更改
建议更改
NetApp ActiveIQ 用例
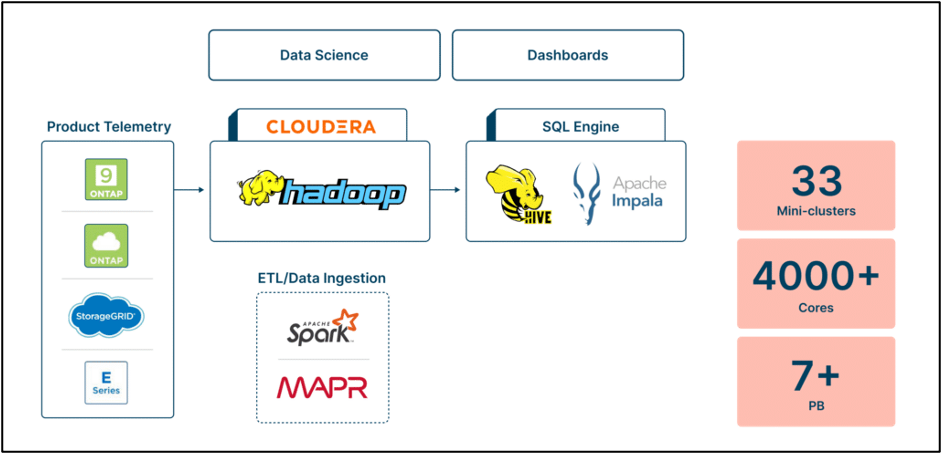
挑战:NetApp 自己的内部Active IQ解决方案最初设计用于支持众多用例,现已发展成为面向内部用户和客户的综合产品。然而,由于数据的快速增长和对高效数据访问的需求,基于 Hadoop/MapR 的底层后端基础设施在成本和性能方面带来了挑战。扩展存储意味着添加不必要的计算资源,从而导致成本增加。
此外,管理 Hadoop 集群非常耗时,并且需要专业知识。数据性能和管理问题进一步使情况复杂化,查询平均需要 45 分钟,并且由于配置错误导致资源匮乏。为了应对这些挑战, NetApp寻求现有传统 Hadoop 环境的替代方案,并确定基于 Dremio 构建的新型现代解决方案可以降低成本、分离存储和计算、提高性能、简化数据管理、提供细粒度控制并提供灾难恢复功能。
解决方案: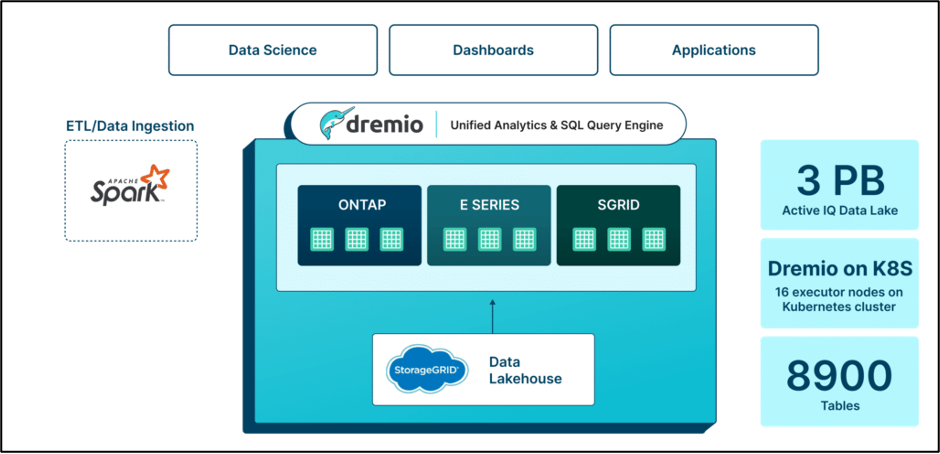 Dremio 使NetApp能够分阶段实现其基于 Hadoop 的数据基础架构的现代化,为统一分析提供路线图。与其他需要对数据处理进行重大更改的供应商不同,Dremio 与现有管道无缝集成,从而节省了迁移期间的时间和费用。通过过渡到完全容器化的环境, NetApp降低了管理开销、提高了安全性并增强了弹性。 Dremio 采用 Apache Iceberg 和 Arrow 等开放生态系统,确保了面向未来性、透明度和可扩展性。
Dremio 使NetApp能够分阶段实现其基于 Hadoop 的数据基础架构的现代化,为统一分析提供路线图。与其他需要对数据处理进行重大更改的供应商不同,Dremio 与现有管道无缝集成,从而节省了迁移期间的时间和费用。通过过渡到完全容器化的环境, NetApp降低了管理开销、提高了安全性并增强了弹性。 Dremio 采用 Apache Iceberg 和 Arrow 等开放生态系统,确保了面向未来性、透明度和可扩展性。
作为 Hadoop/Hive 基础设施的替代品,Dremio 通过语义层提供了二级用例的功能。虽然现有的基于 Spark 的 ETL 和数据提取机制仍然存在,但 Dremio 提供了统一的访问层,以便更轻松地发现和探索数据,而无需重复。这种方法显著减少了数据复制因素,并分离了存储和计算。
好处:借助 Dremio, NetApp通过最大限度地减少数据环境中的计算消耗和磁盘空间要求,实现了显著的成本削减。新的Active IQ数据湖由 8,900 个表组成,包含 3PB 的数据,而之前的基础架构包含超过 7PB 的数据。迁移到 Dremio 还涉及从 33 个微集群和 4,000 个核心过渡到 Kubernetes 集群上的 16 个执行器节点。即使计算资源大幅减少, NetApp 的性能仍得到显著提升。通过 Dremio 直接访问数据,查询运行时间从 45 分钟减少到 2 分钟,从而使预测性维护和优化的洞察时间提高了 95%。迁移还使计算成本降低了 60% 以上,查询速度提高了 20 倍以上,并且总拥有成本 (TCO) 节省了 30% 以上。
汽车零部件销售客户用例。
挑战:在这家全球汽车零部件销售公司中,高管和企业财务规划和分析小组无法获得销售报告的综合视图,而被迫阅读单独的业务线销售指标报告并尝试合并它们。这导致客户根据至少一天前的数据做出决策。获得新的分析见解的准备时间通常需要四周以上的时间。排除数据管道故障需要更多时间,在本来就很长的时间表上再增加三天或更长时间。缓慢的报告开发过程以及报告性能迫使分析师群体不断等待数据处理或加载,而不是让他们发现新的业务见解并推动新的业务行为。这些问题环境由不同业务线的众多不同数据库组成,从而导致出现大量数据孤岛。缓慢而分散的环境使数据治理变得复杂,因为分析师有太多方法可以得出自己的事实版本,而不是单一的事实来源。该方法的数据平台和人力成本超过 190 万美元。维护遗留平台和填写数据请求每年需要七名现场技术工程师 (FTE)。随着数据请求的增长,数据智能团队无法扩展旧环境以满足未来的需求
解决方案:在NetApp对象存储中经济高效地存储和管理大型 Iceberg 表。使用 Dremio 的语义层构建数据域,让业务用户轻松创建、搜索和共享数据产品。
客户受益:• 改进并优化现有数据架构,将洞察时间从四周缩短至数小时 • 将故障排除时间从三天缩短至数小时 • 降低数据平台和管理成本超过 380,000 美元 • 每年节省 (2) 个 FTE 数据智能工作量