

NetApp Spark 解决方案概述
 建议更改
建议更改
NetApp有三个存储产品组合: FAS/ AFF、E 系列和Cloud Volumes ONTAP。我们已经通过 Apache Spark 验证了适用于 Hadoop 解决方案的AFF和带有ONTAP存储系统的 E 系列。
NetApp提供支持的数据结构集成了数据管理服务和应用程序(构建块),用于数据访问、控制、保护和安全,如下图所示。
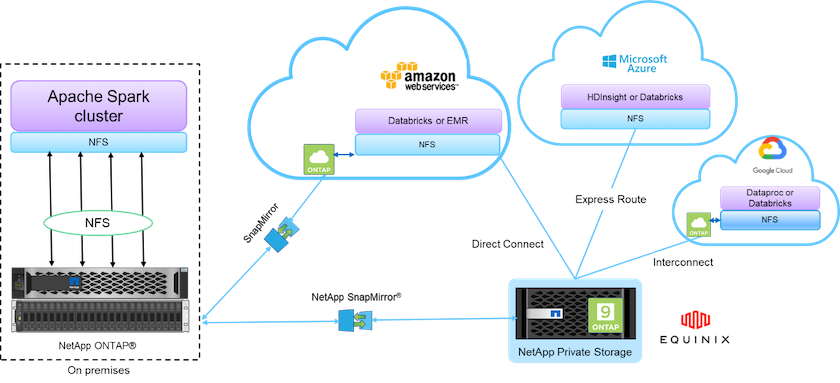
上图中的构建块包括:
-
* NetApp NFS 直接访问。*为最新的 Hadoop 和 Spark 集群提供对NetApp NFS 卷的直接访问,无需额外的软件或驱动程序要求。
-
* NetApp Cloud Volumes ONTAP和Google Cloud NetApp Volumes 。*基于在 Amazon Web Services (AWS) 或 Microsoft Azure 云服务中的Azure NetApp Files (ANF) 中运行的ONTAP的软件定义连接存储。
-
* NetApp SnapMirror技术。*在本地和ONTAP Cloud 或 NPS 实例之间提供数据保护功能。
-
*云服务提供商。*这些提供商包括 AWS、Microsoft Azure、Google Cloud 和 IBM Cloud。
-
*平台即服务 (PaaS)。*基于云的分析服务,例如 AWS 中的 Amazon Elastic MapReduce (EMR) 和 Databricks 以及 Microsoft Azure HDInsight 和 Azure Databricks。
下图描述了采用NetApp存储的 Spark 解决方案。
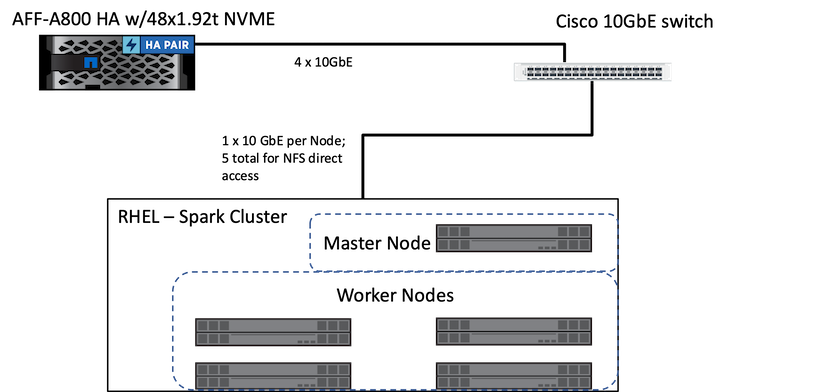
ONTAP Spark 解决方案使用NetApp NFS 直接访问协议进行就地分析以及通过访问现有生产数据来实现 AI、ML 和 DL 工作流。 Hadoop 节点可用的生产数据被导出以执行就地分析和 AI、ML 和 DL 作业。您可以使用NetApp NFS 直接访问或不使用 NetApp NFS 直接访问来访问 Hadoop 节点中要处理的数据。在 Spark 中,使用独立或 yarn`集群管理器,您可以使用配置 NFS 卷 `\file://<target_volume>。我们用不同的数据集验证了三个用例。这些验证的详细信息在“测试结果”部分中介绍。 (外部参照)
下图描述了NetApp Apache Spark/Hadoop 存储定位。
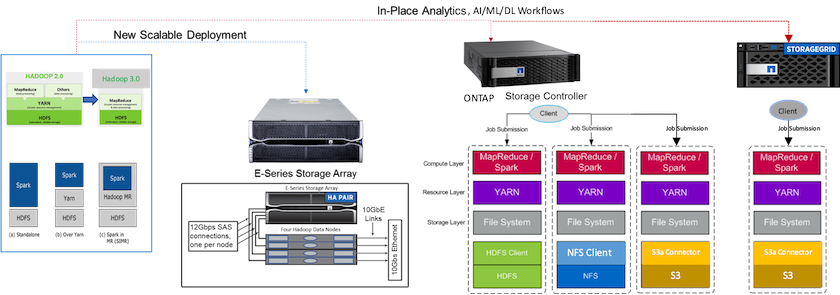
我们确定了 E 系列 Spark 解决方案、 AFF/ FAS ONTAP Spark 解决方案和StorageGRID Spark 解决方案的独特功能,并进行了详细的验证和测试。根据我们的观察, NetApp建议对于绿地安装和新的可扩展部署使用 E 系列解决方案,对于使用现有 NFS 数据的就地分析、AI、ML 和 DL 工作负载使用AFF/ FAS解决方案,对于需要对象存储时的 AI、ML、DL 和现代数据分析使用StorageGRID 。
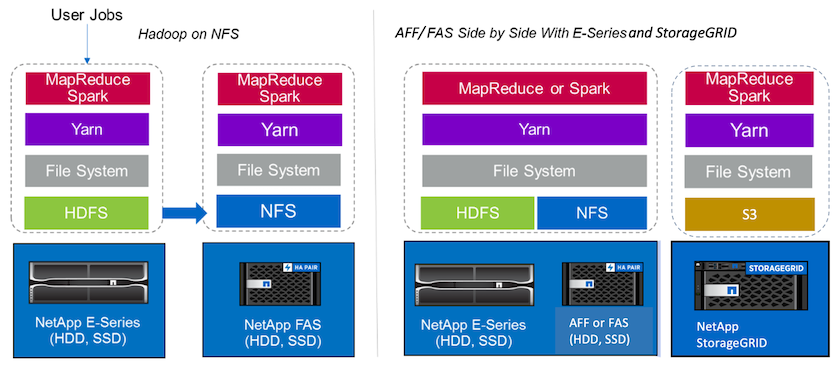
数据湖是原生形式的大型数据集的存储库,可用于分析、AI、ML 和 DL 作业。我们为 E 系列、 AFF/ FAS和StorageGRID SG6060 Spark 解决方案构建了一个数据湖存储库。 E 系列系统提供对 Hadoop Spark 集群的 HDFS 访问,而现有生产数据则通过 NFS 直接访问协议访问 Hadoop 集群。对于驻留在对象存储中的数据集, NetApp StorageGRID提供 S3 和 S3a 安全访问。