

测试程序和详细结果
 建议更改
建议更改
本节描述了详细的测试过程结果。
在ONTAP中使用 ResNet 进行图像识别训练
我们使用一台和两台 SR670 V2 服务器运行 ResNet50 基准测试。本次测试使用MXNet 22.04-py3 NGC容器运行训练。
我们在本次验证中使用了以下测试程序:
-
我们在运行脚本之前清除了主机缓存,以确保数据尚未被缓存:
sync ; sudo /sbin/sysctl vm.drop_caches=3
-
我们在服务器存储(本地 SSD 存储)以及NetApp AFF存储系统上使用 ImageNet 数据集运行基准测试脚本。
-
我们使用以下方法验证了网络和本地存储性能 `dd`命令。
-
对于单节点运行,我们使用以下命令:
python train_imagenet.py --gpus 0,1,2,3,4,5,6,7 --batch-size 408 --kv-store horovod --lr 10.5 --mom 0.9 --lr-step-epochs pow2 --lars-eta 0.001 --label-smoothing 0.1 --wd 5.0e-05 --warmup-epochs 2 --eval-period 4 --eval-offset 2 --optimizer sgdwfastlars --network resnet-v1b-stats-fl --num-layers 50 --num-epochs 37 --accuracy-threshold 0.759 --seed 27081 --dtype float16 --disp-batches 20 --image-shape 4,224,224 --fuse-bn-relu 1 --fuse-bn-add-relu 1 --bn-group 1 --min-random-area 0.05 --max-random-area 1.0 --conv-algo 1 --force-tensor-core 1 --input-layout NHWC --conv-layout NHWC --batchnorm-layout NHWC --pooling-layout NHWC --batchnorm-mom 0.9 --batchnorm-eps 1e-5 --data-train /data/train.rec --data-train-idx /data/train.idx --data-val /data/val.rec --data-val-idx /data/val.idx --dali-dont-use-mmap 0 --dali-hw-decoder-load 0 --dali-prefetch-queue 5 --dali-nvjpeg-memory-padding 256 --input-batch-multiplier 1 --dali- threads 6 --dali-cache-size 0 --dali-roi-decode 1 --dali-preallocate-width 5980 --dali-preallocate-height 6430 --dali-tmp-buffer-hint 355568328 --dali-decoder-buffer-hint 1315942 --dali-crop-buffer-hint 165581 --dali-normalize-buffer-hint 441549 --profile 0 --e2e-cuda-graphs 0 --use-dali
-
对于分布式运行,我们使用了参数服务器的并行化模型。我们每个节点使用两个参数服务器,并将 epoch 数设置为与单节点运行相同。我们这样做是因为由于进程之间的同步不完善,分布式训练通常需要更多的时期。不同的时期数可能会扭曲单节点和分布式情况之间的比较。
数据读取速度:本地存储与网络存储
读取速度是通过 `dd`对 ImageNet 数据集的其中一个文件执行命令。具体来说,我们对本地和网络数据运行以下命令:
sync ; sudo /sbin/sysctl vm.drop_caches=3dd if=/a400-100g/netapp-ra/resnet/data/preprocessed_data/train.rec of=/dev/null bs=512k count=2048Results (average of 5 runs): Local storage: 1.7 GB/s Network storage: 1.5 GB/s.
两个值相似,表明网络存储可以以与本地存储相似的速率传输数据。
共享用例:多个独立、同时的作业
该测试模拟了该解决方案的预期用例:多作业、多用户 AI 训练。每个节点在使用共享网络存储的同时运行自己的训练。结果如下图所示,从图中可以看出,该解决方案案例提供了出色的性能,所有作业的运行速度与单个作业基本相同。总吞吐量与节点数量成线性关系。
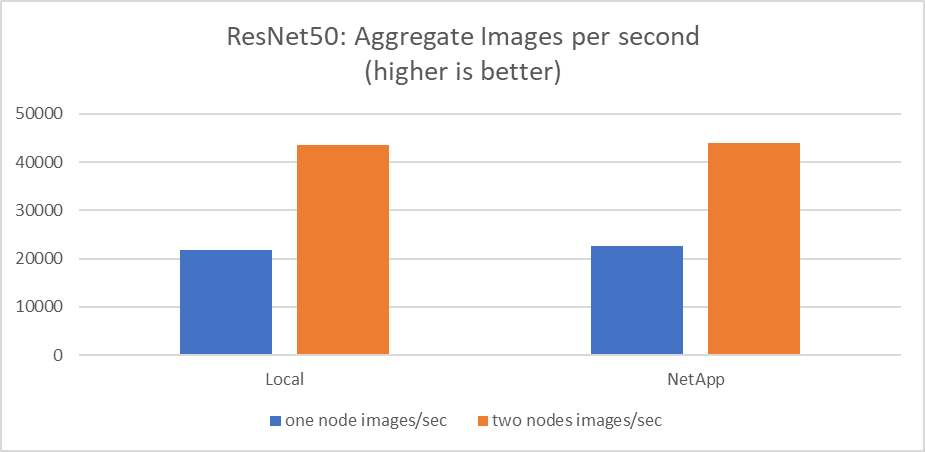
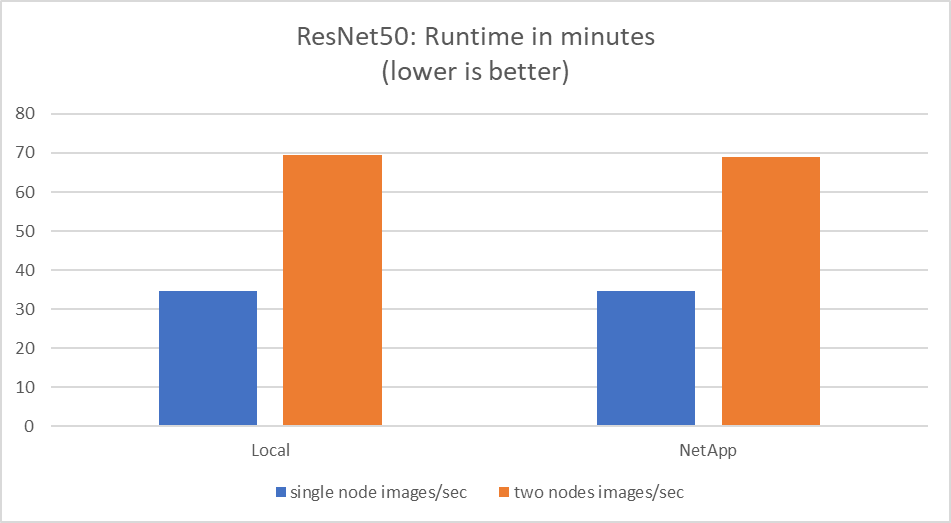
这些图表显示了使用 100 GbE 客户端网络上每个服务器的八个 GPU 的计算节点的运行时间(以分钟为单位)和每秒的聚合图像数,结合了并发训练模型和单一训练模型。训练模型的平均运行时间为35分9秒。个人成绩分别为34分32秒、36分21秒、34分37秒、35分25秒、34分31秒。训练模型每秒的平均图像数为 22,573 张,每秒的单个图像数为 21,764 张;23,438 张;22,556 张;22,564 张;22,547 张。
根据我们的验证,一个使用NetApp数据运行时间的独立训练模型的运行时间为 34 分 54 秒,每秒 22,231 张图像。一个具有本地数据(DAS)的独立训练模型的运行时间为 34 分 21 秒,每秒 22,102 张图像。在这些运行期间,平均 GPU 利用率为 96%,如在 nvidia-smi 上观察到的。请注意,此平均值包括测试阶段,在此期间未使用 GPU,而 CPU 利用率为 40%(由 mpstat 测量)。这表明在每种情况下数据传输率都是足够的。