

技术概述
 建议更改
建议更改
本节更详细地介绍该解决方案的主要组件。
NetApp AFF 系统
NetApp AFF存储系统使企业能够通过行业领先的性能、卓越的灵活性、云集成和一流的数据管理来满足企业存储需求。 AFF系统专为闪存设计,有助于加速、管理和保护关键业务数据。

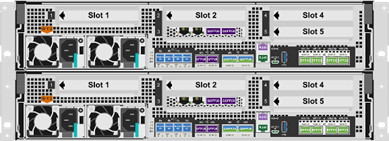
NetApp AFF A400是一款中端 NVMe 闪存存储系统,具有以下功能:
-
最大有效容量:~20PB
-
最大横向扩展:2-24 个节点(12 个 HA 对)
-
25GbE 和 16Gb FC 主机支持
-
通过融合以太网 (RoCE) 的 100GbE RDMA 连接到 NVMe 扩展存储架
-
如果未连接 NVMe 机架,则可以使用 100GbE RoCE 端口进行主机网络连接
-
全12Gbps SAS连接扩展存储架
-
有两种配置可供选择:
-
以太网:4个25Gb以太网(SFP28)端口
-
光纤通道:4x 16Gb FC(SFP+)端口
-
-
100% 8KB 随机读取 @.4 毫秒 400k IOPS
NetApp AFF A250适用于入门级 AI/ML 部署的功能包括:
-
最大有效容量:35PB
-
最大横向扩展:2-24 个节点(12 个 HA 对)
-
440k IOPS 随机读取@1ms
-
基于最新的NetApp ONTAP版本ONTAP 9.8 或更高版本
-
两个 25Gb 以太网端口,用于 HA 和集群互连
NetApp还提供其他存储系统,例如AFF A800和AFF A700 ,它们为更大规模的 AI/ML 部署提供更高的性能和可扩展性。
NetApp ONTAP
ONTAP 9 是NetApp最新一代存储管理软件,它支持企业实现基础架构现代化并过渡到云就绪数据中心。 ONTAP利用业界领先的数据管理功能,只需一套工具即可管理和保护数据,无论数据位于何处。数据还可以自由移动到任何需要的地方:边缘、核心或云端。 ONTAP 9 包含许多功能,可简化数据管理、加速和保护关键数据以及跨混合云架构的未来基础架构。
简化数据管理
数据管理对于企业 IT 运营至关重要,以便为应用程序和数据集使用适当的资源。 ONTAP包括以下功能,可简化操作并降低总体运营成本:
-
*内联数据压缩和扩展重复数据删除。*数据压缩减少了存储块内部浪费的空间,重复数据删除显著增加了有效容量。这适用于本地存储的数据和分层到云的数据。
-
*最小、最大和自适应服务质量 (QoS)。*细粒度的 QoS 控制有助于在高度共享的环境中维持关键应用程序的性能水平。
-
* ONTAP FabricPool.*此功能自动将冷数据分层到公共和私有云存储选项,包括 Amazon Web Services (AWS)、Azure 和NetApp StorageGRID对象存储。
加速并保护数据
ONTAP提供卓越级别的性能和数据保护,并通过以下方式扩展这些功能:
-
性能和更低的延迟。 ONTAP以尽可能低的延迟提供尽可能高的吞吐量。
-
数据保护 ONTAP提供内置数据保护功能,并在所有平台上提供通用管理。
-
* NetApp卷加密。* ONTAP提供原生卷级加密,并支持板载和外部密钥管理。
面向未来的基础设施
ONTAP 9 有助于满足苛刻且不断变化的业务需求:
-
无缝扩展和无中断运行。 ONTAP支持无中断地向现有控制器以及横向扩展集群添加容量。客户可以升级到最新技术,例如 NVMe 和 32Gb FC,而无需昂贵的数据迁移或中断。
-
云连接。 ONTAP是与云连接最紧密的存储管理软件,在所有公共云中均提供软件定义存储(ONTAP Select)和云原生实例(Google Cloud NetApp Volumes)的选项。
-
与新兴应用程序集成。 ONTAP使用支持现有企业应用程序的相同基础架构,为下一代平台和应用程序(如 OpenStack、Hadoop 和 MongoDB)提供企业级数据服务。
NetApp FlexGroup卷
训练数据集通常是数十亿个文件的集合。文件可以包括文本、音频、视频和其他形式的非结构化数据,这些数据必须存储和处理才能并行读取。存储系统必须存储许多小文件,并且必须并行读取这些文件以实现顺序和随机 I/O。
FlexGroup卷(下图)是由多个组成成员卷组成的单一命名空间,对存储管理员而言,该卷的管理方式和NetApp FlexVol volume类似。 FlexGroup卷中的文件被分配给各个成员卷,并且不会跨卷或节点进行条带化。它们支持以下功能:
-
高达 20 PB 的容量和可预测的低延迟,适用于高元数据工作负载
-
同一命名空间内最多可容纳 4000 亿个文件
-
跨 CPU、节点、聚合体和组成FlexVol卷的 NAS 工作负载的并行操作

联想 ThinkSystem 产品组合
联想 ThinkSystem 服务器采用创新的硬件、软件和服务,可解决客户当前面临的挑战,并提供革命性的、适合用途的模块化设计方法来应对未来的挑战。这些服务器利用一流的行业标准技术以及差异化的联想创新,为 x86 服务器提供最大的灵活性。
部署联想 ThinkSystem 服务器的主要优势包括:
-
高度可扩展的模块化设计,可随着您的业务增长而增长
-
行业领先的弹性,可节省数小时昂贵的计划外停机时间
-
快速闪存技术可实现更低的延迟、更快的响应时间和更智能的实时数据管理
在人工智能领域,联想正在采取切实可行的方法帮助企业了解并采用机器学习和人工智能为其工作负载带来的好处。联想客户可以在联想人工智能创新中心探索和评估联想人工智能产品,以充分了解其特定用例的价值。为了缩短价值实现时间,这种以客户为中心的方法为客户提供了可立即使用且针对 AI 进行优化的解决方案开发平台的概念验证。
联想SR670 V2
Lenovo ThinkSystem SR670 V2 机架式服务器为加速 AI 和高性能计算 (HPC) 提供最佳性能。 SR670 V2 支持多达八个 GPU,适合 ML、DL 和推理的计算密集型工作负载要求。

ThinkSystem SR670 V2 配备支持高端 GPU(包括NVIDIA A100 80GB PCIe 8x GPU)的最新可扩展 Intel Xeon CPU,可为 AI 和 HPC 工作负载提供优化、加速的性能。
由于越来越多的工作负载需要使用加速器的性能,因此对 GPU 密度的需求也随之增加。零售、金融服务、能源和医疗保健等行业正在使用 GPU 来获取更深入的见解,并通过 ML、DL 和推理技术推动创新。
ThinkSystem SR670 V2 是一款优化的企业级解决方案,用于在生产中部署加速的 HPC 和 AI 工作负载,最大限度地提高系统性能,同时保持下一代平台超级计算集群的数据中心密度。
其他功能包括:
-
支持 GPU 直接 RDMA I/O,其中高速网络适配器直接连接到 GPU,以最大化 I/O 性能。
-
支持 GPU 直接存储,其中 NVMe 驱动器直接连接到 GPU,以最大限度地提高存储性能。
MLPerf
MLPerf 是业界领先的评估 AI 性能的基准套件。在本次验证中,我们将其图像分类基准与最流行的 AI 框架之一 MXNet 一起使用。使用MXNet_benchmarks训练脚本来驱动AI训练。该脚本包含几种流行的常规模型的实现,并且旨在尽可能快。它可以在单台机器上运行,也可以在多台主机上以分布式模式运行。