

TR-4928:负责任的 AI 和机密推理 - NetApp AI 与 Protopia 图像和数据转换
 建议更改
建议更改
Sathish Thyagarajan、Michael Oglesby、 NetApp Byung Hoon Ahn、Jennifer Cwagenberg、Protopia
随着图像捕捉和图像处理技术的出现,视觉解读已经成为交流不可或缺的一部分。数字图像处理中的人工智能 (AI) 带来了新的商业机会,例如在医疗领域用于癌症和其他疾病的识别、在地理空间可视化分析中用于研究环境危害、在模式识别中、在视频处理中用于打击犯罪等等。然而,这一机遇也伴随着非凡的责任。
组织交给人工智能的决策越多,他们承担的与数据隐私和安全以及法律、道德和监管问题相关的风险就越大。负责任的人工智能使公司和政府组织能够建立信任和治理的实践,这对于大型企业大规模应用人工智能至关重要。本文档介绍了NetApp在三种不同场景下验证的 AI 推理解决方案,该解决方案使用NetApp数据管理技术与 Protopia 数据混淆软件来私有化敏感数据并降低风险和道德问题。
消费者和商业实体每天都会使用各种数字设备生成数百万张图像。随之而来的数据和计算工作量的激增使得企业转向云计算平台来实现规模和效率。同时,随着图像数据转移到公共云,人们对其所含敏感信息的隐私问题也产生了担忧。缺乏安全和隐私保障成为图像处理人工智能系统部署的主要障碍。
此外,还有 "删除权"根据 GDPR,个人有权要求组织删除其所有个人数据。还有 "隐私法",该法案制定了公平信息实践准则。根据 GDPR,照片等数字图像可以构成个人数据,GDPR 规定了数据的收集、处理和删除方式。不这样做就是不遵守 GDPR,这可能会导致违反合规性的巨额罚款,这可能会对组织造成严重损害。隐私原则是实施负责任的人工智能的支柱之一,它确保机器学习 (ML) 和深度学习 (DL) 模型预测的公平性,并降低违反隐私或法规遵从性相关的风险。
本文档描述了在三种不同场景下经过验证的设计解决方案,包括带有和不带有图像混淆,这些场景与保护隐私和部署负责任的 AI 解决方案有关:
-
场景 1. Jupyter 笔记本中的按需推理。
-
场景 2.在 Kubernetes 上进行批量推理。
-
场景 3. NVIDIA Triton 推理服务器。
对于该解决方案,我们使用人脸检测数据集和基准(FDDB),这是一个为研究无约束人脸检测问题而设计的人脸区域数据集,结合 PyTorch 机器学习框架来实现 FaceBoxes。该数据集包含 2845 张不同分辨率图像中 5171 张人脸的注释。此外,本技术报告还介绍了从NetApp客户和现场工程师那里收集的一些适用于该解决方案的解决方案领域和相关用例。
目标受众
本技术报告面向以下受众:
-
希望设计和部署负责任的人工智能并解决公共场所面部图像处理的数据保护和隐私问题的商业领袖和企业架构师。
-
旨在保护和维护隐私的数据科学家、数据工程师、人工智能/机器学习 (ML) 研究人员以及人工智能/机器学习系统开发人员。
-
为符合 GDPR、CCPA 或国防部 (DoD) 和政府组织的隐私法等监管标准的 AI/ML 模型和应用程序设计数据混淆解决方案的企业架构师。
-
数据科学家和人工智能工程师正在寻找有效的方法来部署深度学习 (DL) 和 AI/ML/DL 推理模型来保护敏感信息。
-
负责边缘推理模型的部署和管理的边缘设备管理员和边缘服务器管理员。
解决方案架构
该解决方案旨在利用 GPU 和传统 CPU 的处理能力来处理大型数据集上的实时和批量推理 AI 工作负载。此验证证明了寻求负责任的 AI 部署的组织所需的 ML 隐私保护推理和最佳数据管理。该解决方案提供了一种适用于单节点或多节点 Kubernetes 平台的架构,用于边缘和云计算,并通过 Jupyter Lab 和 CLI 界面与核心本地的NetApp ONTAP AI、 NetApp DataOps Toolkit 和 Protopia 混淆软件互连。下图显示了由NetApp提供支持、采用 DataOps Toolkit 和 Protopia 的数据结构的逻辑架构概览。
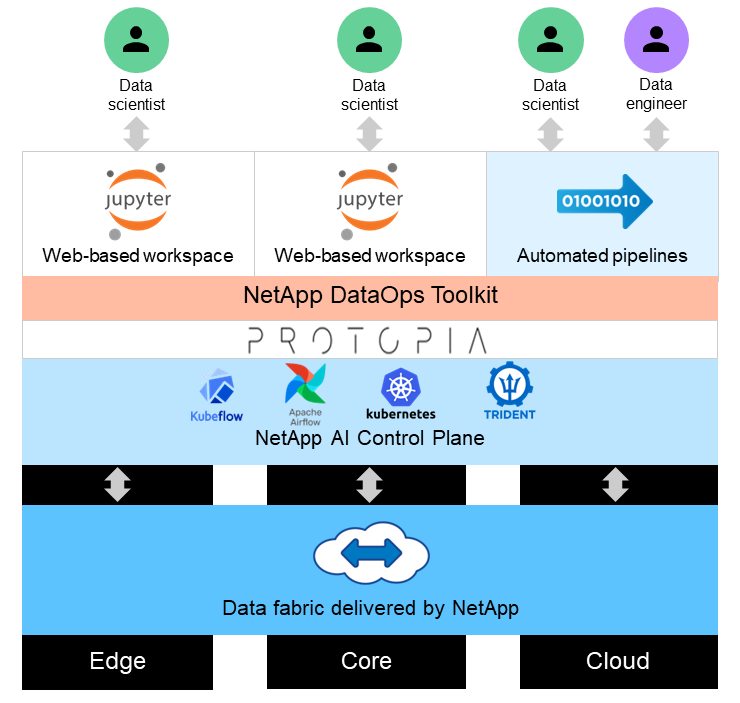
Protopia 混淆软件在NetApp DataOps Toolkit 上无缝运行,并在离开存储服务器之前转换数据。