

性能事件分析和通知
 建议更改
建议更改
性能事件用于通知您由于集群组件上的争用而导致卷工作负载出现的I/O性能问题。Unified Manager 将分析事件以确定涉及的所有工作负载,争用组件以及事件是否仍为您可能需要解决的问题描述。
Unified Manager 可监控集群上卷的 I/O 延迟(响应时间)和 IOPS (操作)。例如,当其他工作负载过度使用集群组件时,该组件处于争用状态,无法在最佳级别执行以满足工作负载需求。使用同一组件的其他工作负载的性能可能会受到影响,从而导致延迟增加。如果延迟超过性能阈值、Unified Manager将触发性能事件并发送电子邮件警报以通知您。
事件分析
Unified Manager 会使用前 15 天的性能统计信息执行以下分析,以确定事件中涉及的受影响工作负载,抢占资源的工作负载和集群组件:
-
确定延迟已超过性能阈值(即预期范围的上限)的受影响工作负载:
-
对于HDD或Flash Pool (混合)聚合上的卷、只有当延迟超过5毫秒且IOPS超过每秒10次操作(操作/秒)时、才会触发事件。
-
对于纯SSD聚合或FabricPool (复合)聚合上的卷、只有当延迟超过1毫秒且IOPS超过100次操作/秒时、才会触发事件
-
-
标识处于争用状态的集群组件。

如果集群互连中受影响工作负载的延迟超过 1 毫秒,则 Unified Manager 会将此问题视为严重问题,并为此集群互连触发事件。
-
确定过度使用集群组件并导致其处于争用状态的抢占资源的工作负载。
-
根据相关工作负载在集群组件的利用率或活动方面的偏差对其进行排名,以确定哪些抢占资源的工作负载在集群组件的使用情况上变化最大,哪些受影响最大。
事件可能只会短暂发生,然后在其所使用的组件不再处于争用状态后自行更正。连续事件是指同一集群组件在五分钟间隔内重新发生的事件,并且该事件始终处于活动状态。对于持续事件, Unified Manager 会在两个连续分析间隔内检测到同一事件后触发警报。状态为NEW的未解决事件可能会在事件更改涉及的工作负载时显示不同的问题描述 消息。
事件解决后,它将在 Unified Manager 中作为卷以往性能问题记录的一部分保持可用。每个事件都有一个唯一的 ID ,用于标识事件类型以及涉及的卷,集群和集群组件。
|
|
一个卷可以同时参与多个事件。 |
事件状态
事件可以处于以下状态之一:
-
* 活动 *
指示性能事件当前处于活动状态(新事件或已确认事件)。导致此事件的问题描述未自行更正或未得到解决。存储对象的性能计数器仍高于性能阈值。
-
* 已废弃 *
指示事件不再处于活动状态。导致此事件的问题描述已自行更正或已解决。存储对象的性能计数器不再高于性能阈值。
事件通知
事件警报将显示在Dashboards/Overview页面、Dashboards/Performance页面、Performance/Volume Details页面上、并发送到指定的电子邮件地址。您可以在事件详细信息页面上查看有关事件的详细分析信息并获取解决建议。
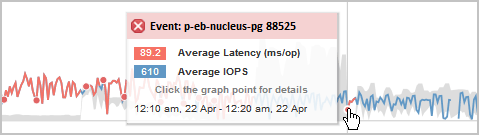
在此示例中、事件由一个红点(![]() )。将鼠标光标悬停在红点上方会显示一个弹出窗口、其中包含有关事件的更多详细信息以及用于分析事件的选项。
)。将鼠标光标悬停在红点上方会显示一个弹出窗口、其中包含有关事件的更多详细信息以及用于分析事件的选项。
事件交互
在"性能/卷详细信息"页面上、您可以通过以下方式与事件进行交互:
-
将指针移动到红点上方将显示一条消息、其中会显示事件ID、延迟、每秒操作数以及检测到事件的日期和时间。
如果在同一时间段内存在多个事件、则此消息将显示事件数量以及卷的平均延迟和每秒操作数。
-
单击单个事件将显示一个对话框、其中显示有关该事件的更多详细信息、包括所涉及的集群组件、类似于"事件详细信息"页面上的"摘要"部分。
处于争用状态的组件将圈出并以红色突出显示。您可以单击事件ID或*查看完整分析*以在"事件"详细信息页面上查看完整分析。如果在同一时间段内存在多个事件,则此对话框将显示有关最近三个事件的详细信息。您可以单击事件ID以在事件详细信息页面上查看事件分析。如果同一时间段内存在三个以上的事件、则单击红点不会显示对话框。