

VMware vSphere解决方案概述
 建议更改
建议更改
vCenter Server Appliance (VCSA) 是一个功能强大的集中式管理系统和 vSphere 的单一管理界面,使管理员能够有效地操作 ESXi 集群。它支持虚拟机配置、vMotion 操作、高可用性 (HA)、分布式资源调度器 (DRS)、VMware vSphere Kubernetes 服务 (VKS) 等关键功能。它是 VMware 云环境中的一个重要组成部分,在设计时应考虑到服务的可用性。
vSphere高可用性
VMware的集群技术可将ESXi服务器分组到虚拟机的共享资源池中、并提供vSphere高可用性(HA)。vSphere HA可为虚拟机中运行的应用程序提供易于使用的高可用性。在集群上启用HA功能后、每个ESXi服务器都会与其他主机保持通信、以便在任何ESXi主机无响应或隔离时、 HA集群可以在集群中的无故障主机之间协商恢复该ESXi主机上运行的虚拟机。如果子操作系统发生故障、vSphere HA可以在同一物理服务器上重新启动受影响的虚拟机。vSphere HA可以减少计划内停机、防止计划外停机、并从中断中快速恢复。
vSphere HA 集群从故障服务器恢复虚拟机。
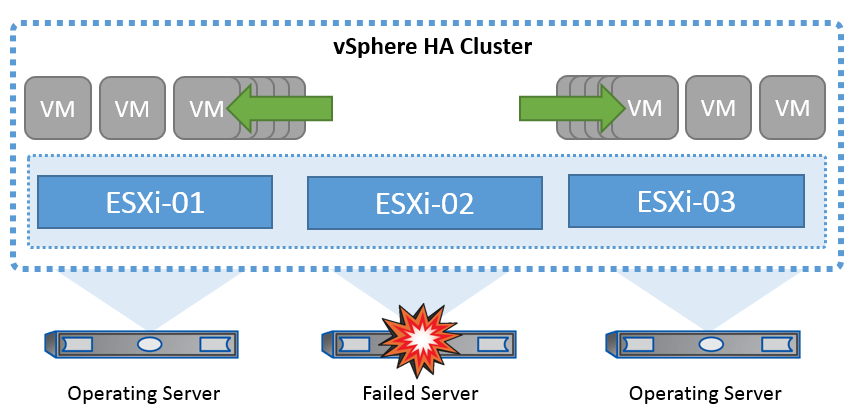
请务必了解、VMware vSphere不了解NetApp MetroCluster或SnapMirror主动同步、并且会根据主机和VM组关联性配置将vSphere集群中的所有ESXi主机视为符合HA集群操作条件的主机。
主机故障检测
HA集群创建完成后,集群中的所有主机都会参与选举,其中一台主机将成为主主机。每个从设备都会向主设备发送网络心跳信号,而主设备反过来也会向所有从设备主机发送网络心跳信号。vSphere HA 集群的主主机负责检测从主机的故障。
根据检测到的故障类型、可能需要对主机上运行的虚拟机进行故障转移。
在vSphere HA集群中、检测到三种类型的主机故障:
-
故障—主机停止运行。
-
隔离—主机变为网络隔离。
-
分区-主机与主主机断开网络连接。
主主机监控集群中的从主机。此通信通过每秒交换一次网络检测信号来完成。当主主机停止从从从主机接收这些检测信号时、它会先检查主机活动性、然后再声明主机出现故障。主主机执行的活动性检查用于确定从主机是否正在与某个数据存储库交换检测搏。此外、主主机还会检查该主机是否对发送到其管理IP地址的ICMP ping做出响应、以检测它是仅与其主节点隔离还是与网络完全隔离。它通过对默认网关执行pinging来实现此目的。可以手动指定一个或多个隔离地址、以提高隔离验证的可靠性。

|
NetApp建议至少指定两个额外的隔离地址、并且每个地址都是站点本地地址。这将提高隔离验证的可靠性。 |
主机隔离响应
隔离响应是 vSphere HA 中的一项设置,用于确定当 vSphere HA 集群中的主机失去其管理网络连接但仍继续运行时,在虚拟机上触发的操作。此设置有三个选项:“禁用”、“关闭并重启虚拟机”和“关闭电源并重启虚拟机”。
“关机”比“断电”更好,“断电”不会将最近的更改刷新到磁盘或提交事务。如果虚拟机在 300 秒内没有关闭,则会将其断电。要更改等待时间,请使用高级选项 das.isolationshutdowntimeout。
在HA启动隔离响应之前、它会首先检查vSphere HA主代理是否拥有包含VM配置文件的数据存储库。否则、主机将不会触发隔离响应、因为没有主节点可重新启动VM。主机将定期检查数据存储库状态、以确定是否由具有主角色的vSphere HA代理声明数据存储库。
|
|
NetApp建议将"主机隔离响应"设置为"已禁用"。 |
如果主机与vSphere HA主主机隔离或分区、并且主主机无法通过检测信号数据存储库或ping进行通信、则可能发生脑裂情况。主节点会声明隔离的主机已停止运行、并在集群中的其他主机上重新启动VM。现在存在脑裂情况、因为虚拟机有两个实例正在运行、其中只有一个实例可以读取或写入虚拟磁盘。现在、可以通过配置虚拟机组件保护(VM Component Protection、VMCP)来避免脑裂情况。
VM组件保护(VMCP)
vSphere 6中与HA相关的一项增强功能是VMCP。VMCP可针对块(FC、iSCSI、FCoE)和文件存储(NFS)提供增强的保护、使其免受所有路径关闭(APD)和永久设备丢失(PDL)情况的影响。
永久设备丢失(永久设备丢失)(财产和财产
PDL 是指存储设备永久发生故障或被管理员移除且预计不会恢复的情况。NetApp存储阵列向 ESXi 发出 SCSI Sense 代码,声明该设备已永久丢失。在 vSphere HA 的“故障条件和 VM 响应”部分,您可以配置检测到 PDL 条件后应采取的响应。
|
|
NetApp建议将“带有 PDL 的数据存储的响应”设置为“关闭电源并重新启动虚拟机”。当检测到此情况时,虚拟机将在 vSphere HA 集群中运行正常的宿主机上立即重新启动。 |
所有路径已关闭(APD)
APD 是指存储设备对主机不可见,且没有通往阵列的路径时发生的情况。ESXi 认为这是设备的暂时性问题,预计该设备将再次可用。
检测到APD情况时、计时器将启动。140秒后、系统将正式声明APD条件、并且设备会标记为APD超时。超过140秒后、HA将开始计算VM故障转移APD延迟中指定的分钟数。指定时间过后、HA将重新启动受影响的虚拟机。您可以根据需要将VMCP配置为以不同方式响应("Disabled (已禁用)"、"VM Events (问题描述事件)"或"Power Off and Restart VM (关闭并重新启动VM)")。
|
|
|
为NetApp SnapMirror活动同步实施VMware DRS
VMware DRS是一项将主机资源聚合到集群中的功能、主要用于在虚拟基础架构中的集群内进行负载平衡。VMware DRS主要计算在集群中执行负载平衡所需的CPU和内存资源。由于vSphere无法识别延伸型集群、因此在进行负载平衡时、它会考虑两个站点中的所有主机。
适用于NetApp MetroCluster的VMware DRS实施
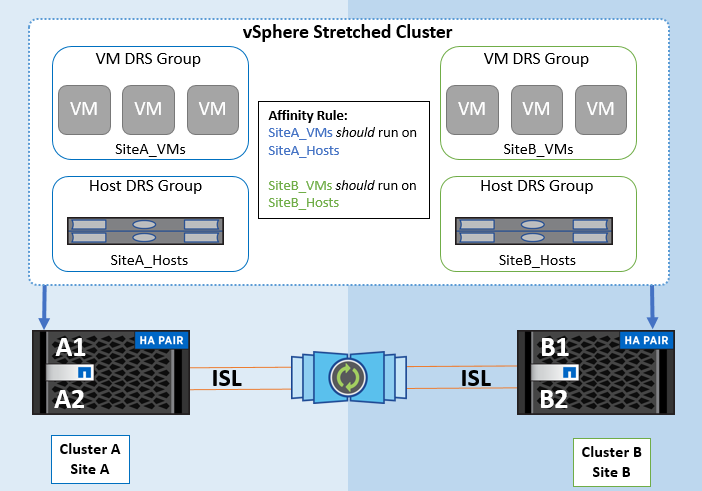
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. 如果为集群创建DRS关联性规则、则可以指定vSphere在虚拟机故障转移期间如何应用该规则。
您可以为 vSphere HA 故障转移行为指定两种类型的规则:
-
VM反关联性规则会强制指定的虚拟机在故障转移操作期间保持分离状态。
-
在故障转移操作期间、VM主机关联性规则会将指定的虚拟机放置在特定主机或已定义主机组的成员上。
使用VMware DRS中的VM主机关联性规则、可以在站点A和站点B之间进行逻辑隔离、以便VM与配置为给定数据存储库的主读/写控制器的阵列在同一站点的主机上运行。此外、VM主机关联性规则还可以使虚拟机保持在存储本地、从而确保在站点间发生网络故障时虚拟机连接。
以下是VM主机组和关联性规则的示例。
最佳实践
NetApp建议实施"应该"规则、而不是"必须"规则、因为如果发生故障、vSphere HA会违反这些规则。使用"必须"规则可能会导致服务中断。
服务的可用性应始终优先于服务的性能。如果整个数据中心发生故障,“必须”规则必须从 VM 主机亲缘性组中选择主机,并且当数据中心不可用时,虚拟机将不会重新启动。
使用NetApp MetroCluster实施VMware存储DRS
通过VMware Storage DRS功能、可以将数据存储库聚合到一个单元中、并在超过存储I/O控制(SIIOC)阈值时平衡虚拟机磁盘。
默认情况下、启用了存储DRS的DRS集群会启用存储I/O控制。通过存储I/O控制、管理员可以控制在I/O拥塞期间分配给虚拟机的存储I/O量、这样、在分配I/O资源时、更重要的虚拟机就可以优先于不太重要的虚拟机。
存储DRS使用Storage vMotion将虚拟机迁移到数据存储库集群中的不同数据存储库。在NetApp MetroCluster环境中、需要在该站点的数据存储库中控制虚拟机迁移。例如、在站点A的主机上运行的虚拟机A最好在站点A的SVM数据存储库中进行迁移否则、虚拟机将继续运行、但性能会下降、因为虚拟磁盘读/写操作将通过站点间链路从站点B进行。
|
|
*使用ONTAP存储时、建议禁用存储DRS。
|