关于 MetroCluster 切换和切回
 建议更改
建议更改
从 ONTAP System Manager 9.6 开始,如果发生灾难,导致源集群中的所有节点均无法访问并关闭,您可以使用 MetroCluster 切换和切回操作。在灾难恢复测试或站点脱机进行维护等情况下,您还可以使用切换工作流进行协商(计划内)切换。
关于 MetroCluster 切换和切回
从 System Manager 9.6 开始,您可以使用 MetroCluster 切换和切回操作来允许一个集群站点接管另一个集群站点的任务。通过此功能,您可以方便地进行维护或从灾难中恢复。
切换操作允许一个集群(站点 A )接管另一个集群(站点 B )通常执行的任务。切换后,可以关闭已接管的集群(站点 B )以进行维护和修复。维护完成后,站点 B 将启动并完成修复任务,然后您可以启动切回操作,使修复后的集群(站点 B )能够恢复其通常执行的任务。
System Manager 支持两种切换操作,具体取决于远程集群站点的状态:
-
协商(计划内)切换:当需要对集群执行计划内维护或测试灾难恢复过程时,您可以启动此操作。
-
计划外切换:如果集群(站点 B )发生灾难,而您希望其他站点或集群(站点 A )在执行修复和维护期间接管受灾难影响的集群(站点 B )的任务,则可以启动此操作。
您可以在 System Manager 中对两个切换操作执行相同的步骤。启动切换时, System Manager 会确定此操作是否可行并相应地对齐工作负载。
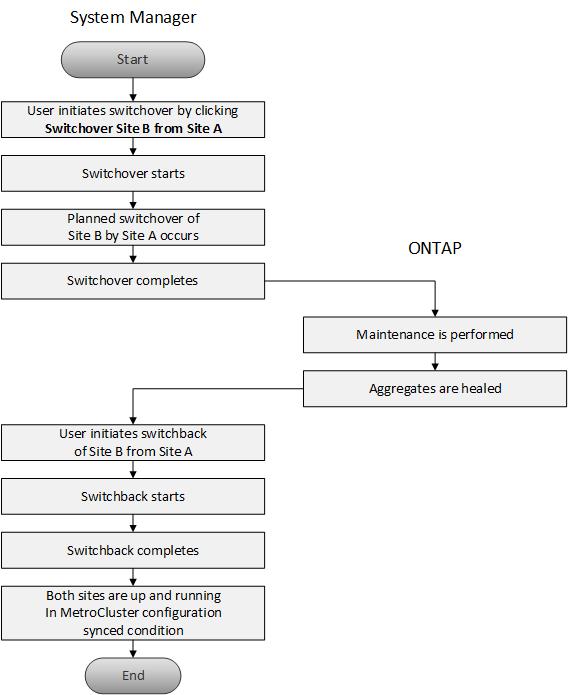
MetroCluster 切换和切回工作流
切换和切回工作流的整个过程包括以下三个阶段:
-
* 切换 * :切换过程允许您将存储和客户端访问的控制权从源集群站点(站点 B )传输到另一个集群站点(站点 A )。此操作可帮助您在测试和维护期间实现无中断运行。此外,通过此过程还可以从站点故障中恢复。对于灾难恢复测试或计划内站点维护,您可以执行 MetroCluster 切换以将控制权移交给灾难恢复( DR )站点(站点 A )。在开始此过程之前,必须至少有一个运行正常的站点节点已启动且正在运行,然后才能执行切换。如果之前在灾难恢复站点上的某些节点上执行的切换操作失败,则可以在所有这些节点上重试此操作。
-
* 站点 B 操作 * :切换完成后, System Manager 将完成 MetroCluster IP 配置的修复过程。修复是一个计划内事件,可让您完全控制每个步骤,从而最大限度地减少停机时间。修复过程分为两个阶段,在存储和控制器组件上执行,以便为修复后的站点上的节点做好切回准备。在第一阶段,此过程会通过重新同步镜像丛来修复聚合,然后通过将根聚合切回灾难站点来修复根聚合。
在第二阶段,站点已做好切回准备。
-
* 切回 * :在站点 B 上执行维护和修复后,您可以启动切回操作,将存储和客户端访问的控制权从站点 A 交还给站点 B要成功切回,必须满足以下条件:
-
主节点和存储架必须已启动,并且可由站点 A 中的节点访问
-
System Manager 必须已成功完成修复阶段,然后才能启动切回操作。
-
站点 A 中的所有聚合都应处于已镜像状态,并且不能处于已降级或正在重新同步状态。
-
在执行切回操作之前,必须完成所有先前的配置更改。这样可以防止这些更改与协商切换或切回操作相冲突。
-
MetroCluster 切换和切回工作流流程图
以下流程图展示了启动切换和切回操作时发生的阶段和过程。