

性能
 建议更改
建议更改
NetApp AFX 在构建时考虑到了性能和规模——专门针对需要高读取和写入吞吐量的工作负载,并且可以提供简单的线性扩展。
每节点性能
每个 NetApp AFX 存储节点都为读取和写入提供特定数量的吞吐量。随着节点添加到集群中,它们线性地提高了性能,如本文档"节点性能的线性缩放"部分所述。
目前,节点类型为 "AFX 1K",提供的读取和写入吞吐量大致如下所示。随着 NetApp AFX 可以使用更新的硬件,这些限制可能会发生变化。注意:使用多个客户端读取和写入多个文件已达到最大性能,如下面的"基准结果"部分所示。
每节点性能预估
| 节点类型 | 读取性能最大值 | 写入性能最大值 |
|---|---|---|
AFX 1K |
~35GB/s |
~10GB/s |

|
如需了解最新的性能评估,请咨询您的 NetApp 销售团队。 |
每架性能
每个机架都包含具有 16 个 100GB 以太网端口的高性能机架模块,这些模块利用 RoCEv2 通信与集群中的计算节点进行高带宽存储交互。与任何物理资源一样,这些机架具有可以实现的最大值 – 特别是因为 NetApp AFX 可以呈现指向同一组磁盘的多个节点。下表显示了用于 TLC 和 QLC 驱动器的单个机架的估计最大读取和写入性能。有关 TLC 和 QLC 差异的更多信息,请参见 "TLC 与 QLC"。
每个磁盘架性能估算
| 磁盘架模块类型 | 读取性能最大值 | 写入性能最大值 |
|---|---|---|
NSM 140 |
140GB/s(TLC 和 QLC) |
70GB/s TLC 35GB/s QLC |
|
|
如需了解最新的性能评估,请咨询您的 NetApp 销售团队。 |
性能密度
在分解的 ONTAP 架构中将存储节点与盘架分离,允许更多节点将流量推送到更少的盘架,这有助于减少仅使用所需容量获得最大性能所需的整体数据中心占用空间。
这种"性能密度"的概念使存储管理员能够充分利用其拥有的硬件,同时无需过度配置其存储环境。
例如,在统一的 ONTAP 集群中,由于每个节点都有自己的磁盘集,因此性能仅针对节点拥有的磁盘,并且由于只有一个节点可以访问一组磁盘,因此不一定会使可用磁盘饱和并实现其最大性能。
Unified ONTAP – 性能如何划分
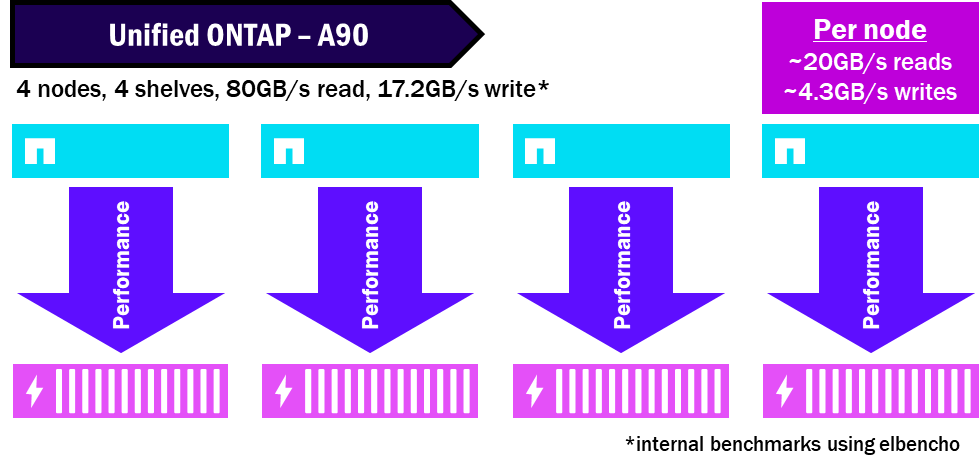
NetApp AFX 将所有磁盘集中到一个存储可用区中,因此所有节点都可以利用所有磁盘。而且由于磁盘和节点是分离的,因此您不需要那么多的盘架来获得相同的性能。这压缩了性能,并最大限度地发挥了盘架的最大性能潜力。
NetApp AFX – 性能密度
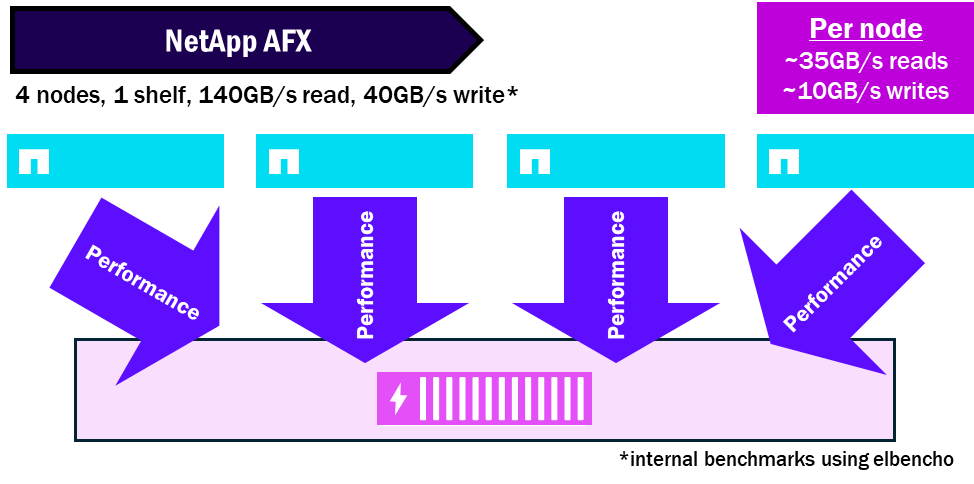
节点与磁盘架比率
Unified ONTAP 节点要求每个节点至少有一组磁盘,并且可以将多个盘架连接到单个节点。因此,单个节点可能存在性能瓶颈,可能无法使自己的磁盘饱和。
NetApp AFX 向所有节点呈现所有磁盘盘架。每个盘架都包含具有 16 x 100GB RoCE 功能接口的模块,以提高每个盘架所允许的总性能。因此,您可以使用多个节点使单个盘架饱和,这些节点将读取和写入同一组磁盘。
截至 ONTAP 9.19.1,节点:磁盘架饱和度比约为 4:1。
基准结果
以下部分介绍了使用具有以下配置参数的 NetApp AFX 集群的基准测试结果。
-
4 个节点,4 个数据接口
-
2 个盘架(7.6TB 驱动器)
-
ONTAP 9.19.1
-
NFSv4.2 (pNFS, 会话中继)
-
FlexGroup 卷
-
"ElBencho" 基准
-
写入:elbencho --hosts=x.x.x.[y-z] -d -w -b 1M -t 80 --iodepth 1 --direct -s 600g /fio_vol1/
-
读取:elbencho --hosts=x.x.x.[y-z] -r -b 256k -t 80 --lat --iodepth 2 --direct -s 600g --infloop /fio_vol1/
-
4 台 Cisco C240 M8 服务器,2 端口 * 200GbE CX-7 卡,80 个线程
-
NFS 挂载选项:rw,vers=4.2,rsize=1048576,wsize=1048576,trunkdiscovery,proto=tcp
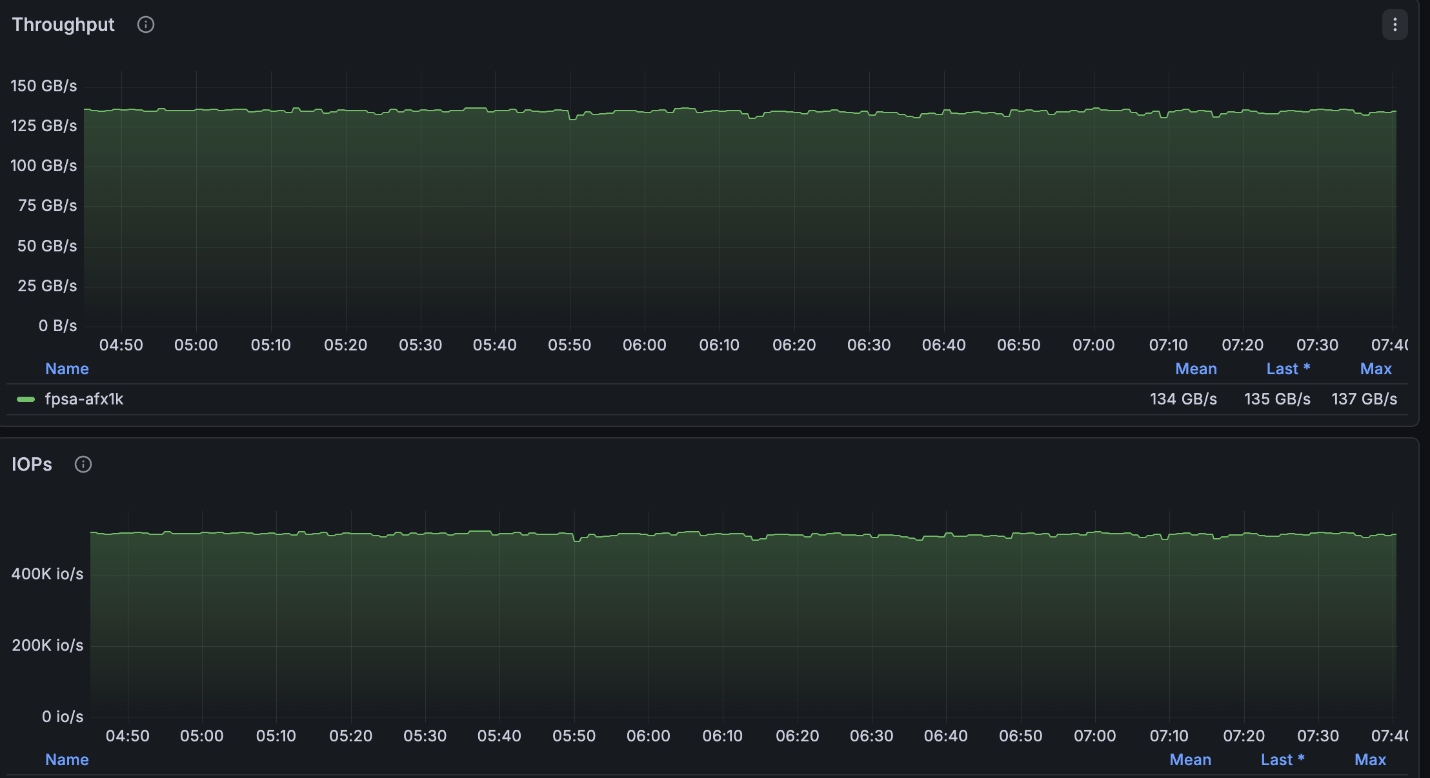
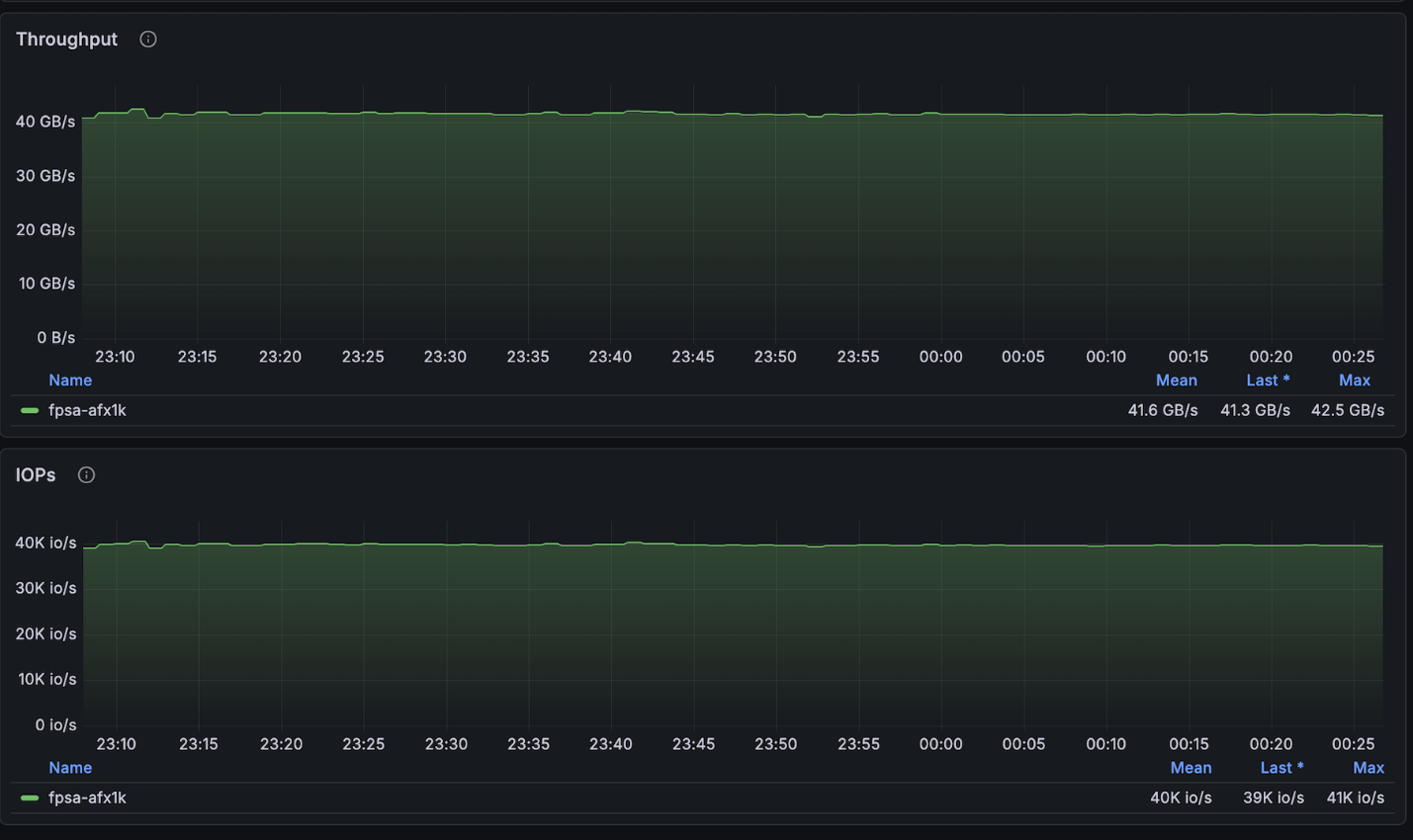
上述配置非常接近 4 节点集群可用的最大读取速度(~134GB/s),并且正好达到每个节点允许的最大写入速度(40GB/s)。
NetApp AFX – ElBencho 读取性能,4 个节点
NetApp AFX – ElBencho 写入性能,4 个节点
积极预读
在媒体流工作负载中,4K 电影通常分为数万个文件,每个文件的大小通常为 50 MB 至 250 MB。每个文件表示一个帧,应用程序在一个请求中读取整个帧。为了保持流畅、不间断的流且没有可见的缓冲,这些帧读取必须完成而不能有丢失。
ONTAP 提供了一个卷级选项(-aggressive-readahead-mode)来优化这些工作负载。从 ONTAP 9.19.1 开始,在 AFX 上引入了一种新的 `cross_file_sequential_read`模式,用于积极预读,以加速具有跨类似文件类型(例如,媒体渲染和流式传输)可预测 I/O 模式的工作负载。
cross_file_sequential_read 根据文件名预测下一个要读取的文件,并在客户端发出读取调用之前开始对这些文件进行预读。预测逻辑假设目录中的所有文件都遵循带有单调递增数字后缀的命名模式(例如 file1、file2、file3)。目录中的所有文件都必须遵循此模式,使用十进制或十六进制编号。文件名最长可达 255 个字符。该逻辑与扩展名无关,仅根据当前文件名生成当前目录中的下一组文件名。如果之前使用 base10 编号生成的文件名在目录中不存在,则使用十六进制编号重新生成名称。如果生成的文件名都不存在,则不会为该集合发出预取。当发出下一个客户端读取时,预取恢复。
启用这些选项后,"frametest" 性能基准测试能够在 30 个客户端(NFSv3 和 SMB3)和 34 个客户端(NFSv4.1)上以每秒 30 帧的速度读取 30,000 个 4K 帧,而无需丢弃一个帧。
虽然跨文件顺序读取主要是为媒体工作负载设计的,但具有可预测访问模式和文件名的其他读取密集型工作负载(如 AI 训练和推理)也可以从中受益。
注意事项和注意点
-
共享缓冲区缓存 – 主动提前读取使用与节点上其他卷相同的缓冲区缓存。启用它可能会影响该节点上其他卷的读取性能。
-
基础存储性能 – 如果文件读取速度不够快(例如,在基于 HDD 的 FAS 系统上),则可能会在客户端读取之前逐出缓存数据,从而抵消提前读取的好处。
-
访问模式要求 – 如果工作负载的读取模式不是顺序的,或者目录中的文件没有以递增的顺序命名,则 cross_file_sequential_read 激进提前读取模式将不会提供有意义的好处。
NFSv4.x 性能增强
几十年来,NFS 版本 3 一直是 NFS 应用程序的黄金标准——始于 1995 年,当时它首次正式发布。它融合了性能和弹性,因此很难考虑迁移到较新的 NFS 版本是有充分理由的。
但是,NFSv3 并非没有限制。该协议的无状态性虽然有利于提高性能并最大限度地减少存储故障转移的中断,但对于数据一致性和锁定管理来说并不是那么理想。NFS 服务器不会真正跟踪锁定状态,因此如果出现故障,NFS 服务器可能会或可能不会释放锁定,并且 NFS 客户端可能不知道文件是否已锁定。
Security for NFSv3 is also a bit lacking. The protocol requires multiple open firewall ports to function properly and numeric IDs are sent in plaintext over the wire. Furthermore, NFS does not have robust ACL support, and does not include native file and folder auditing. As a result of these limitations, NFSv4 was created in 2003 via link:https://datatracker.ietf.org/doc/html/rfc3530[RFC-3530^] (obsoleted in 2015 by link:https://datatracker.ietf.org/doc/html/rfc7530[RFC-7530^]). 虽然 NFSv4.x 已经存在了 20 多年,但由于一些原因,尚未得到广泛采用。
-
身份管理的复杂性:许多环境没有名称服务基础设施,无法正确利用 NFSv4.x 中的名称字符串和 Kerberos 安全要求。
-
对较新 NFS 客户端的需求:在当今的现代 NFS 环境中,这种担忧不那么紧迫,因为我们距离 NFSv4 的初始发布日期越来越远。几乎所有当前使用的操作系统都包括具有完全 NFSv4 支持的 NFS 客户端,但仍有遗留系统可能没有必要的 NFSv4.x 包。实际上,某些应用程序仍然需要使用较旧的 NFS 版本。
-
"如果没有中断,就不要修复它"的心态:众所周知,企业 IT 组织在采用新技术方面是保守的,即使那些已经存在了 20 多年的技术也是如此。如果当前 NFS 版本工作正常,为什么要更改?
-
性能问题:在过去 20 年的大部分时间里,像 NFSv4.x 这样的有状态协议的性能一直落后于无状态 NFSv3。在过去,性能影响往往超过 NFSv4.x 的好处。
使用 AFX 的 ONTAP 9.18.1 中的 NFSv4.x 改进
对 ONTAP 架构的一些更改总体上为 NFS 提供了急需的性能提升,并在总体上改善 NFSv4.x 性能方面取得了一些重大进展。
以下是其中一些更改的高级摘要。
顺序读取增强:NFSv4.1 比 NFSv3 好 30%
ONTAP 9.18.1 引入了对 NFSv4.1 多路径 IO 的支持。MPIO 不是处理来自 WAFL 文件系统的读取,而是将读取操作转移到网络域中,以多路径安全的方式提供服务。这种方法减少了上下文切换,在顺序读取流量中提供了更大的整体并行性,并通过绕过 WAFL 减少了缓冲区管理的开销。
FlexGroup 卷的随机读取增强功能:NFSv4.1 在 NFSv3 的 7% 以内
FlexGroup 卷是占用许多基础组成卷并将其呈现为单个统一命名空间的卷。在 AFX 中,FlexGroup 卷默认情况下启用了高级容量平衡,这将在多个组成卷上将大于 10GB 的文件写入为多部分文件。由于这些文件部分的远程位置,随机读取传统上对 NFSv4.x 具有适度的性能劣势(比 NFSv3 低约 18%)。ONTAP 9.18.1 引入了对 NFSv4.x 多部分读取缓存 IO 的支持,以帮助解决这个问题。注意:此更改不适用于 FlexVol 卷。
顺序写入:比先前版本提高 +10%
我们复制用于 HA 故障转移功能的 NVLOG 数据的方式的改进提高了 NetApp AFX 系统的整体顺序写入性能。
元数据操作:EDA 基准测试中 NFSv3 性能的 15% 以内
NFSv4.1 传统上序列化所有 OPEN 和 CLOSE 操作,集群节点一次处理一个操作,然后才能从网络发送到 WAFL。ONTAP 9.18.1 引入了 Concurrent Open Close (COC),通过改变竞争条件的解决方式消除了网络序列化,消除了以前版本中出现的 OPEN/CLOSE 瓶颈。
所有这些变化,加上 AFX 带来的架构变化,使得在 ONTAP 9.18.1 中提高整体 NFSv4.1 性能成为可能。
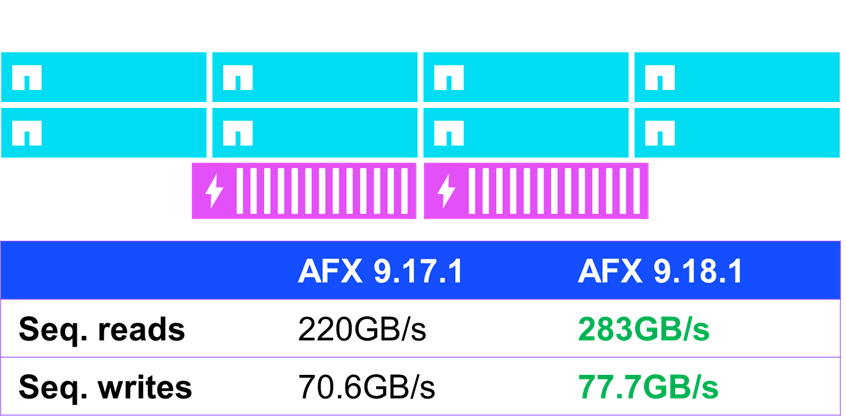
顺序 IO 结果
可以看到一些适度性能改进的领域之一是连续 IO(即可预测且连续发布的 IO)。在使用 fio 的标准性能测试中,运行 ONTAP 9.18.1 的 AFX 将顺序读取性能提高了近 30%,顺序写入性能提高了 10%。
NetApp AFX – ONTAP 9.18.1 中的 NFSv4.1 顺序 IO 性能
元数据密集型工作负载结果
更令人印象深刻的是 NFSv4.x 的顶级性能痛点之一–元数据的改进。这些是随机 IO,通常在 4K 范围内,用于管理文件所有者和属性、创建和列出文件等。由于 NFSv4.x 的状态性,这些类型的操作往往会在 CPU 和延迟方面花费更多,从而降低整体可能的性能。
随着 AFX ONTAP 9.18.1 的更改,这些类型工作负载的 NFSv4.x 性能大幅提高,并缩小了与 NFSv3 性能的差距(在 15% 以内)。
我们的性能工程团队比较了标准 AI 映像、EDA 和软件构建基准的性能,发现从先前的 ONTAP 版本中获得了巨大的收益。
NetApp AFX – ONTAP 9.18.1 中的 NFSv4.1 元数据 IO 性能
