

使用命令行界面手动对四节点或八节点MetroCluster配置进行无中断ONTAP升级
 建议更改
建议更改
手动升级四节点或八节点MetroCluster配置涉及准备更新、同时更新一个或两个DR组中每个DR对以及执行升级后任务。
-
此任务将对以下配置进行适用场景处理:
-
运行 ONTAP 9.2 或更早版本的四节点 MetroCluster FC 或 IP 配置
-
八节点 MetroCluster FC 配置,与 ONTAP 版本无关
-
-
如果您使用的是双节点 MetroCluster 配置,请勿使用此操作步骤。
-
以下任务涉及 ONTAP 的旧版本和新版本。
-
升级时,旧版本是 ONTAP 的早期版本,其版本号低于新版本的 ONTAP 。
-
降级时,旧版本是 ONTAP 的更高版本,其版本号高于新版本的 ONTAP 。
-
-
此任务使用以下高级工作流:
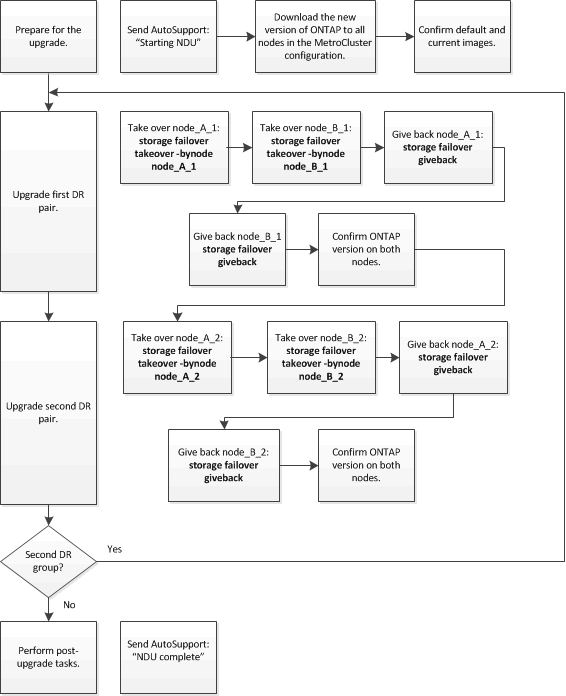
在八节点或四节点MetroCluster配置上更新ONTAP软件时的差异
MetroCluster软件升级过程会有所不同、具体取决于MetroCluster配置中的节点是八个还是四个。
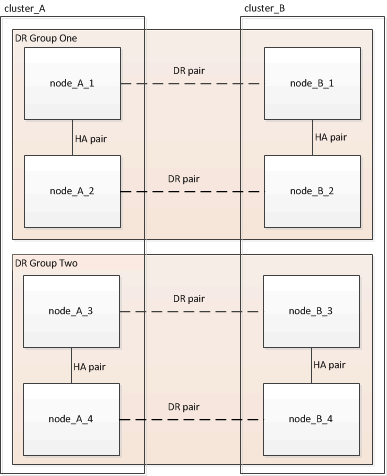
一个 MetroCluster 配置包含一个或两个 DR 组。每个 DR 组包含两个 HA 对,每个 MetroCluster 集群一个 HA 对。一个八节点 MetroCluster 包括两个 DR 组:
一次升级一个DR组。
-
升级DR组1:
-
升级NODE_A_1和NODE_B_1。
-
升级NODE_A_2和NODE_B_2。
-
-
升级DR组1:
-
升级NODE_A_1和NODE_B_1。
-
升级NODE_A_2和NODE_B_2。
-
-
升级DR组2:
-
升级NODE_A_3和NODE_B_3。
-
升级NODE_A_4和NODE_B_4。
-
准备升级MetroCluster DR组
在节点上升级ONTAP软件之前、您必须确定节点之间的DR关系、发送一条AutoSupport消息以说明您正在启动升级、并确认每个节点上运行的ONTAP版本。
必须在每个 DR 组上重复执行此任务。如果 MetroCluster 配置包含八个节点,则存在两个 DR 组。因此,必须在每个 DR 组上重复执行此任务。
此任务中提供的示例使用下图中所示的名称来标识集群和节点:
-
确定配置中的DR对:
metrocluster node show -fields dr-partnercluster_A::> metrocluster node show -fields dr-partner (metrocluster node show) dr-group-id cluster node dr-partner ----------- ------- -------- ---------- 1 cluster_A node_A_1 node_B_1 1 cluster_A node_A_2 node_B_2 1 cluster_B node_B_1 node_A_1 1 cluster_B node_B_2 node_A_2 4 entries were displayed. cluster_A::>
-
将权限级别从admin设置为advance,在系统提示您继续时输入*y*:
set -privilege advanced高级提示符 (
*>)。 -
确认cluster-A上的ONTAP版本:
system image showcluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
确认cluster-B上的版本:
system image showcluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_B_1 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 true true X.X.X MM/DD/YYYY TIME image2 false false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
触发 AutoSupport 通知:
autosupport invoke -node * -type all -message "Starting_NDU"此AutoSupport通知包括升级前的系统状态记录。如果升级过程出现问题、它会保存有用的故障排除信息。
如果集群未配置为发送 AutoSupport 消息,则通知的副本将保存在本地。
-
对于第一组中的每个节点、将目标ONTAP软件映像设置为默认映像:
system image modify {-node nodename -iscurrent false} -isdefault true此命令使用扩展查询将作为备用映像安装的目标软件映像更改为节点的默认映像。
-
验证目标ONTAP软件映像是否设置为cluster-A上的默认映像:
system image show在以下示例中, image2 是新的 ONTAP 版本,并设置为第一组中每个节点上的默认映像:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed.-
验证目标ONTAP软件映像是否设置为cluster-B上的默认映像:
system image show以下示例显示目标版本已设置为第一组中每个节点上的默认映像:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ------- ------------------- node_A_1 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/YY/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 2 entries were displayed. -
-
确定要升级的节点当前是否为每个节点的任何客户端提供两次服务:
system node run -node target-node -command uptimeuptime 命令显示节点自上次启动以来对 NFS , CIFS , FC 和 iSCSI 客户端执行的操作总数。对于每个协议,您需要运行两次命令来确定操作计数是否在增加。如果它们不断增加,则表示节点当前正在为该协议的客户端提供服务。如果不增加,则节点当前不会为该协议的客户端提供服务。

您应记下客户端操作不断增加的每种协议、以便在升级节点后验证客户端流量是否已恢复。 此示例显示了具有 NFS , CIFS , FC 和 iSCSI 操作的节点。但是,此节点当前仅为 NFS 和 iSCSI 客户端提供服务。
cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:16 800000260 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32810 iSCSI ops cluster_x::> system node run -node node0 -command uptime 2:58pm up 7 days, 19:17 800001573 NFS ops, 1017333 CIFS ops, 0 HTTP ops, 40395 FCP ops, 32815 iSCSI ops
更新 MetroCluster DR 组中的第一个 DR 对
您必须按正确顺序执行节点接管和交还,以使新版本的 ONTAP 成为节点的当前版本。
所有节点都必须运行旧版本的 ONTAP 。
在此任务中、将升级NODE_A_1和NODE_B_1。
如果您已升级第一个DR组上的ONTAP软件、并且现在要升级八节点MetroCluster配置中的第二个DR组、则在此任务中、您需要更新NODE_A_3和NODE_B_3。
-
将所有数据生命周期迁移出节点:
network interface migrate-all -node node_A_1network interface migrate-all -node node_B_1 -
如果启用了 MetroCluster Tiebreaker 软件,请将其禁用。
-
对于HA对中的每个节点、禁用自动交还:
storage failover modify -node target-node -auto-giveback false必须对 HA 对中的每个节点重复执行此命令。
-
验证是否已禁用自动交还:
storage failover show -fields auto-giveback此示例显示已在两个节点上禁用自动交还:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 false node_x_2 false 2 entries were displayed.
-
确保每个控制器的I/O不超过50%、并且每个控制器的CPU利用率不超过50%。
-
启动对 cluster_A 上目标节点的接管:
请勿指定 -option immediate 参数,因为要接管的节点需要正常接管才能启动到新软件映像。
-
接管cluster-A (NODE_A_1)上的DR配对节点:
storage failover takeover -ofnode node_A_1节点启动至 " 正在等待交还 " 状态。
如果启用了 AutoSupport ,则会发送一条 AutoSupport 消息,指示节点超出集群仲裁。您可以忽略此通知并继续升级。 -
验证接管是否成功:
storage failover show以下示例显示接管已成功。node_A_1 处于 " 正在等待交还 " 状态, node_A_2 处于 " 正在接管 " 状态。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 - Waiting for giveback (HA mailboxes) node_A_2 node_A_1 false In takeover 2 entries were displayed. -
-
接管 cluster_B 上的 DR 配对节点( node_B_1 ):
请勿指定 -option immediate 参数,因为要接管的节点需要正常接管才能启动到新软件映像。
-
接管NODE_B_1:
storage failover takeover -ofnode node_B_1节点启动至 " 正在等待交还 " 状态。
如果启用了 AutoSupport ,则会发送一条 AutoSupport 消息,指示节点超出集群仲裁。您可以忽略此通知并继续升级。 -
验证接管是否成功:
storage failover show以下示例显示接管已成功。node_B_1 处于 " 正在等待交还 " 状态, node_B_2 处于 " 正在接管 " 状态。
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 - Waiting for giveback (HA mailboxes) node_B_2 node_B_1 false In takeover 2 entries were displayed. -
-
至少等待八分钟,以确保满足以下条件:
-
客户端多路径(如果已部署)已稳定。
-
客户端将从接管期间发生的 I/O 暂停中恢复。
恢复时间特定于客户端,根据客户端应用程序的特征,可能需要超过八分钟。
-
-
将聚合返回到目标节点:
将 MetroCluster IP 配置升级到 ONTAP 9.5 或更高版本后,聚合将在短时间内处于降级状态,然后再重新同步并返回到镜像状态。
-
将聚合交还给cluster A上的DR配对节点:
storage failover giveback -ofnode node_A_1 -
将聚合交还给cluster B上的DR配对节点:
storage failover giveback -ofnode node_B_1交还操作首先将根聚合返回到节点,然后在节点完成启动后,返回非根聚合。
-
-
在两个集群上发出以下命令、以验证是否已返回所有聚合:
storage failover show-giveback如果 Giveback Status 字段指示没有要交还的聚合,则表示所有聚合均已返回。如果交还被否决,则该命令将显示交还进度以及否决了交还的子系统。
-
如果尚未返回任何聚合,请执行以下操作:
-
查看否决临时解决策以确定您是要解决 "
ve到" 条件还是覆盖此否决。 -
如有必要,请解决错误消息中所述的 " 从
ve到" 条件,确保已确定的任何操作均正常终止。 -
重新输入 storage failover giveback 命令。
如果您决定覆盖 "
ve到" 条件,请将 -override-vetoes 参数设置为 true 。
-
-
至少等待八分钟,以确保满足以下条件:
-
客户端多路径(如果已部署)已稳定。
-
客户端将从交还期间发生的 I/O 暂停中恢复。
恢复时间特定于客户端,根据客户端应用程序的特征,可能需要超过八分钟。
-
-
将权限级别从admin设置为advance,在系统提示您继续时输入*y*:
set -privilege advanced高级提示符 (
*>)。 -
确认cluster-A上的版本:
system image show以下示例显示系统 image2(目标 ONTAP 映像)是 node_A_1 上的默认和当前版本:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
确认cluster-B上的版本:
system image show以下示例显示系统 image2(目标 ONTAP 映像)是 node_B_1 上的默认和当前版本:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- -------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false true X.X.X MM/DD/YYYY TIME image2 true false Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::>
更新 MetroCluster DR 组中的第二个 DR 对
您必须按正确顺序接管和交还节点,以使新版本的 ONTAP 成为节点的当前版本。
您应已升级第一个 DR 对( node_A_1 和 node_B_1 )。
在此任务中、将升级NODE_A_2和NODE_B_2。
如果您已升级第一个DR组上的ONTAP软件、并且现在正在更新八节点MetroCluster配置中的第二个DR组、则在此任务中、您将更新NODE_A_4和NODE_B_4。
-
将所有数据生命周期迁移出节点:
network interface migrate-all -node node_A_2network interface migrate-all -node node_B_2 -
启动对 cluster_A 上目标节点的接管:
请勿指定 -option immediate 参数,因为要接管的节点需要正常接管才能启动到新软件映像。
-
接管 cluster_A 上的 DR 配对节点:
storage failover takeover -ofnode node_A_2 -option allow-version-mismatch
。 allow-version-mismatch从ONTAP 9.0升级到ONTAP 9.1或任何修补程序升级都不需要此选项。节点启动至 " 正在等待交还 " 状态。
如果启用了 AutoSupport ,则会发送一条 AutoSupport 消息,指示节点超出集群仲裁。您可以忽略此通知并继续升级。
-
验证接管是否成功:
storage failover show以下示例显示接管已成功。node_A_2 处于 " 正在等待交还 " 状态, node_A_1 处于 " 正在接管 " 状态。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_A_1 node_A_2 false In takeover node_A_2 node_A_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
启动对 cluster_B 上目标节点的接管:
请勿指定 -option immediate 参数,因为要接管的节点需要正常接管才能启动到新软件映像。
-
接管 cluster_B ( node_B_2 )上的 DR 配对节点:
升级位置 输入此命令 … ONTAP 9.2 或 ONTAP 9.1
storage failover takeover -ofnode node_B_2ONTAP 9.0 或 Data ONTAP 8.3.x
storage failover takeover -ofnode node_B_2 -option allow-version-mismatch
。 allow-version-mismatch从ONTAP 9.0升级到ONTAP 9.1或任何修补程序升级都不需要此选项。节点启动至 " 正在等待交还 " 状态。
如果启用了AutoSupport、则会发送AutoSupport消息、指示节点脱离集群仲裁关系。您可以安全地忽略此通知并继续升级。 -
验证接管是否成功:
storage failover show以下示例显示接管已成功。node_B_2 处于 " 正在等待交还 " 状态, node_B_1 处于 " 正在接管 " 状态。
cluster_B::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ------------------------------------- node_B_1 node_B_2 false In takeover node_B_2 node_B_1 - Waiting for giveback (HA mailboxes) 2 entries were displayed. -
-
至少等待八分钟,以确保满足以下条件:
-
客户端多路径(如果已部署)已稳定。
-
客户端将从接管期间发生的 I/O 暂停中恢复。
恢复时间特定于客户端,根据客户端应用程序的特征,可能需要超过八分钟。
-
-
将聚合返回到目标节点:
将 MetroCluster IP 配置升级到 ONTAP 9.5 后,聚合将在短时间内处于降级状态,然后再重新同步并返回到镜像状态。
-
将聚合交还给cluster A上的DR配对节点:
storage failover giveback -ofnode node_A_2 -
将聚合交还给cluster B上的DR配对节点:
storage failover giveback -ofnode node_B_2交还操作首先将根聚合返回到节点,然后在节点完成启动后,返回非根聚合。
-
-
在两个集群上发出以下命令、以验证是否已返回所有聚合:
storage failover show-giveback如果 Giveback Status 字段指示没有要交还的聚合,则表示所有聚合均已返回。如果交还被否决,则该命令将显示交还进度以及否决了交还的子系统。
-
如果尚未返回任何聚合,请执行以下操作:
-
查看否决临时解决策以确定您是要解决 "
ve到" 条件还是覆盖此否决。 -
如有必要,请解决错误消息中所述的 " 从
ve到" 条件,确保已确定的任何操作均正常终止。 -
重新输入 storage failover giveback 命令。
如果您决定覆盖 "
ve到" 条件,请将 -override-vetoes 参数设置为 true 。
-
-
至少等待八分钟,以确保满足以下条件:
-
客户端多路径(如果已部署)已稳定。
-
客户端将从交还期间发生的 I/O 暂停中恢复。
恢复时间特定于客户端,根据客户端应用程序的特征,可能需要超过八分钟。
-
-
将权限级别从admin设置为advance,在系统提示您继续时输入*y*:
set -privilege advanced高级提示符 (
*>)。 -
确认cluster-A上的版本:
system image show以下示例显示系统 image2(目标 ONTAP 映像)是 node_A_2 上的默认和当前版本:
cluster_A::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_A_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_A_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_A::> -
确认cluster-B上的版本:
system image show以下示例显示系统 image2(目标 ONTAP 映像)是 node_B_2 上的默认和当前版本:
cluster_B::*> system image show Is Is Install Node Image Default Current Version Date -------- ------- ------- ------- ---------- ------------------- node_B_1 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME node_B_2 image1 false false X.X.X MM/DD/YYYY TIME image2 true true Y.Y.Y MM/DD/YYYY TIME 4 entries were displayed. cluster_B::> -
对于HA对中的每个节点、启用自动交还:
storage failover modify -node target-node -auto-giveback true必须对 HA 对中的每个节点重复执行此命令。
-
验证是否已启用自动交还:
storage failover show -fields auto-giveback此示例显示已在两个节点上启用自动交还:
cluster_x::> storage failover show -fields auto-giveback node auto-giveback -------- ------------- node_x_1 true node_x_2 true 2 entries were displayed.