

客戶用例
 建議變更
建議變更
NetApp ActiveIQ 用例
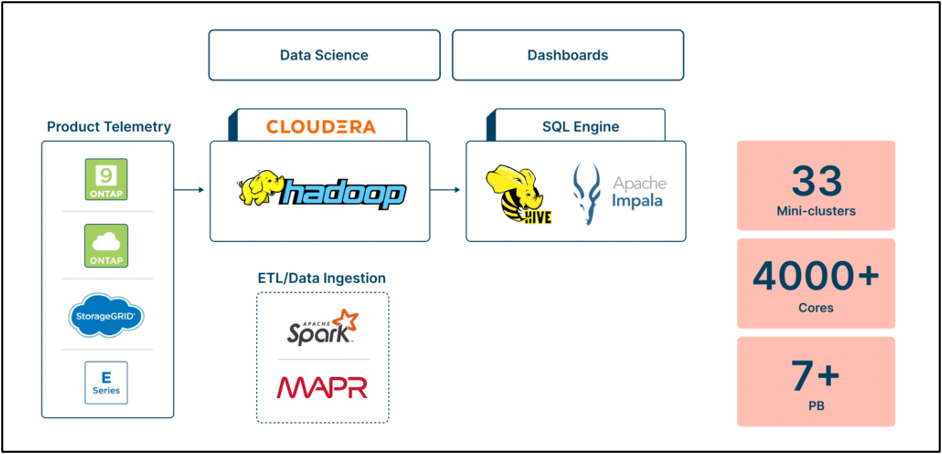
挑戰:NetApp 自己的內部Active IQ解決方案最初設計用於支援眾多用例,現已發展成為面向內部使用者和客戶的綜合產品。然而,由於資料的快速增長和對高效資料存取的需求,基於 Hadoop/MapR 的底層後端基礎設施在成本和效能方面帶來了挑戰。擴展儲存意味著添加不必要的運算資源,從而導致成本增加。
此外,管理 Hadoop 叢集非常耗時,並且需要專業知識。資料效能和管理問題進一步使情況複雜化,查詢平均需要 45 分鐘,並且由於配置錯誤導致資源匱乏。為了應對這些挑戰, NetApp尋求現有傳統 Hadoop 環境的替代方案,並確定基於 Dremio 構建的新型現代解決方案可以降低成本、分離儲存和運算、提高效能、簡化資料管理、提供細粒度控制並提供災難復原功能。
解決方案: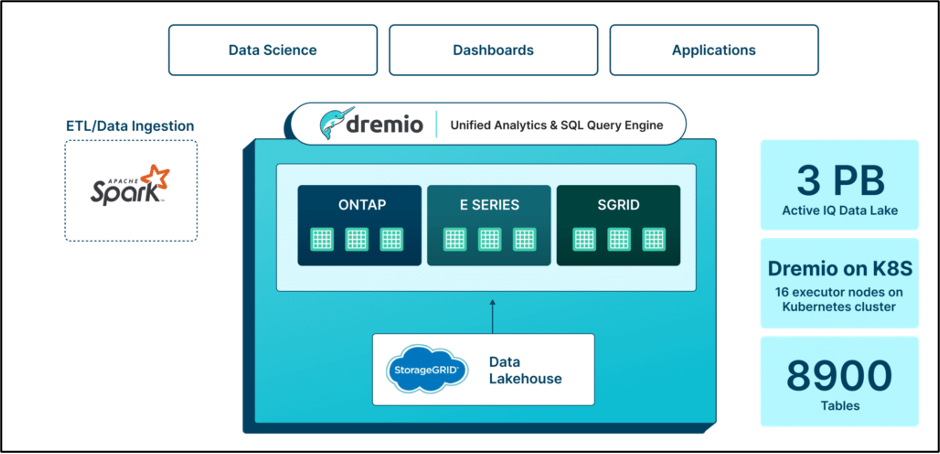 Dremio 使NetApp能夠分階段實現其基於 Hadoop 的資料基礎架構的現代化,為統一分析提供路線圖。與其他需要對資料處理進行重大更改的供應商不同,Dremio 與現有管道無縫集成,從而節省了遷移期間的時間和成本。透過過渡到完全容器化的環境, NetApp降低了管理開銷、提高了安全性並增強了彈性。 Dremio 採用 Apache Iceberg 和 Arrow 等開放式生態系統,確保了面向未來性、透明度和可擴展性。
Dremio 使NetApp能夠分階段實現其基於 Hadoop 的資料基礎架構的現代化,為統一分析提供路線圖。與其他需要對資料處理進行重大更改的供應商不同,Dremio 與現有管道無縫集成,從而節省了遷移期間的時間和成本。透過過渡到完全容器化的環境, NetApp降低了管理開銷、提高了安全性並增強了彈性。 Dremio 採用 Apache Iceberg 和 Arrow 等開放式生態系統,確保了面向未來性、透明度和可擴展性。
作為 Hadoop/Hive 基礎設施的替代品,Dremio 透過語意層提供了二級用例的功能。雖然現有的基於 Spark 的 ETL 和資料提取機制仍然存在,但 Dremio 提供了統一的存取層,以便更輕鬆地發現和探索數據,而無需重複。這種方法顯著減少了資料複製因素,並分離了儲存和計算。
好處:借助 Dremio, NetApp透過最大限度地減少資料環境中的運算消耗和磁碟空間要求,實現了顯著的成本削減。新的Active IQ數據湖由 8,900 個表組成,包含 3PB 的數據,而先前的基礎架構包含超過 7PB 的數據。遷移到 Dremio 還涉及從 33 個微型叢集和 4,000 個核心過渡到 Kubernetes 叢集上的 16 個執行器節點。即使運算資源大幅減少, NetApp 的效能仍被顯著提升。透過 Dremio 直接存取數據,查詢運行時間從 45 分鐘減少到 2 分鐘,從而使預測性維護和優化的洞察時間提高了 95%。遷移也使計算成本降低了 60% 以上,查詢速度提高了 20 倍以上,總擁有成本 (TCO) 節省了 30% 以上。
汽車零件銷售客戶用例。
挑戰:在這家全球汽車零件銷售公司中,高階主管和企業財務規劃和分析小組無法獲得銷售報告的綜合視圖,而被迫閱讀單獨的業務線銷售指標報告並嘗試合併它們。這導致客戶根據至少一天前的數據做出決策。獲得新的分析見解的準備時間通常需要四週以上的時間。排除資料管道故障需要更多時間,在本來就很長的時間表上再增加三天或更長時間。緩慢的報告開發過程以及報告效能迫使分析師群體不斷等待資料處理或加載,而不是讓他們發現新的業務見解並推動新的業務行為。這些問題環境由不同業務線的眾多不同資料庫組成,導致出現大量資料孤島。緩慢而分散的環境使資料治理變得複雜,因為分析師有太多方法可以得出自己的事實版本,而不是單一的事實來源。該方法在數據平台和人力成本上花費了超過 190 萬美元。維護遺留平台和填寫資料請求每年需要七名現場技術工程師 (FTE)。隨著資料請求的成長,資料智慧團隊無法擴展舊環境以滿足未來的需求
解決方案:在NetApp物件儲存中經濟高效地儲存和管理大型 Iceberg 表。使用 Dremio 的語意層建立資料域,讓業務用戶輕鬆建立、搜尋和分享資料產品。
客戶受益:• 改善並優化現有資料架構,將洞察時間從四周縮短至數小時 • 將故障排除時間從三天縮短至數小時 • 降低資料平台和管理成本超過 380,000 美元 • 每年節省 (2) 個 FTE 資料智慧工作量