

由NetApp支援的適用於大數據架構的資料結構
 建議變更
建議變更
NetApp提供支援的資料結構簡化並整合了跨雲端和本地環境的資料管理,從而加速數位轉型。
NetApp提供支援的資料結構為資料可見性和洞察、資料存取和控制以及資料保護和安全性提供了一致且整合的資料管理服務和應用程式(構建塊),如下圖所示。
經過驗證的資料結構客戶用例
NetApp支援的資料結構為客戶提供了以下九種經過驗證的用例:
-
加速分析工作負載
-
加速 DevOps 轉型
-
建置雲端託管基礎設施
-
整合雲端資料服務
-
保護和保障資料安全
-
優化非結構化數據
-
提高資料中心效率
-
提供數據洞察和控制
-
簡化和自動化
本文檔涵蓋九個用例中的兩個(及其解決方案):
-
加速分析工作負載
-
保護和保障資料安全
NetApp NFS 直接訪問
NetApp NFS 允許客戶在其現有或新的 NFSv3 或 NFSv4 資料上執行大數據分析作業,而無需移動或複製資料。它可以防止資料的多次複製,並且無需將資料與來源同步。例如,在金融領域,資料從一個地方移動到另一個地方必須滿足法律義務,這不是一件容易的事。在這種情況下, NetApp NFS 直接存取會從原始位置分析財務資料。另一個主要優勢是,使用NetApp NFS 直接存取可以透過使用本機 Hadoop 命令簡化 Hadoop 資料的保護,並利用 NetApp 豐富的資料管理產品組合實現資料保護工作流程。
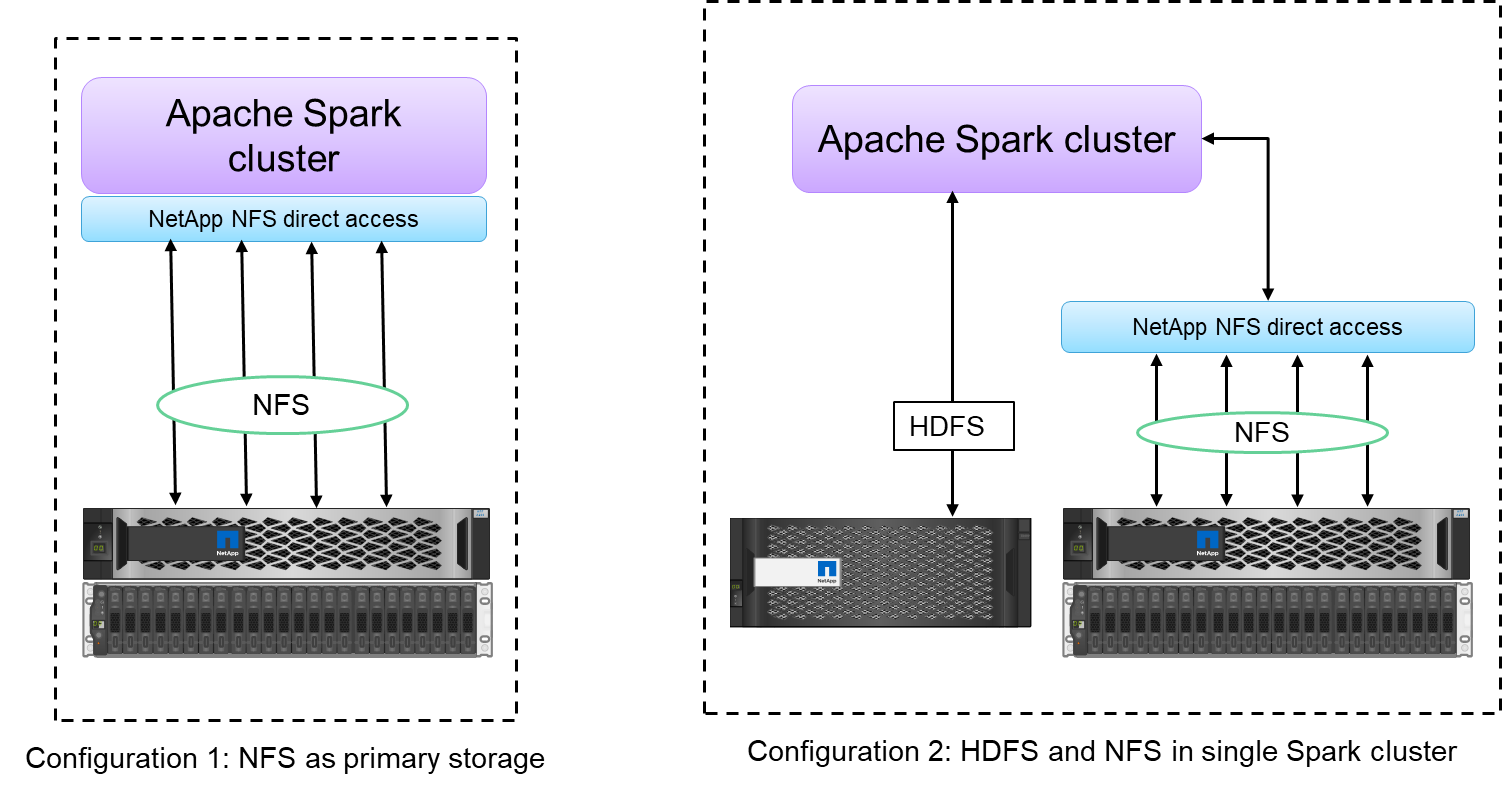
NetApp NFS 直接存取為 Hadoop/Spark 叢集提供了兩種部署選項:
-
預設情況下,Hadoop/Spark叢集使用Hadoop分散式檔案系統(HDFS)作為資料儲存和預設檔案系統。 NetApp NFS 直接存取可以用 NFS 儲存取代預設的 HDFS 作為預設檔案系統,從而實現對 NFS 資料的直接分析操作。
-
在另一個部署選項中, NetApp NFS 直接存取支援在單一 Hadoop/Spark 叢集中將 NFS 與 HDFS 一起配置為附加儲存。在這種情況下,客戶可以透過 NFS 匯出共享數據,並從同一個叢集存取數據以及 HDFS 數據。
使用NetApp NFS 直接存取的主要優勢包括:
-
從目前位置分析數據,從而避免將分析數據移動到 Hadoop 基礎架構(如 HDFS)這一耗時耗能的任務。
-
將副本數量從三個減少到一個。
-
使用戶能夠分離計算和存儲以獨立擴展它們。
-
利用ONTAP豐富的資料管理功能提供企業資料保護。
-
已通過 Hortonworks 資料平台認證。
-
支援混合資料分析部署。
-
利用動態多執行緒功能減少備份時間。
大數據的建構模組
NetApp提供支援的資料結構整合了資料管理服務和應用程式(構建塊),用於資料存取、控制、保護和安全,如下圖所示。
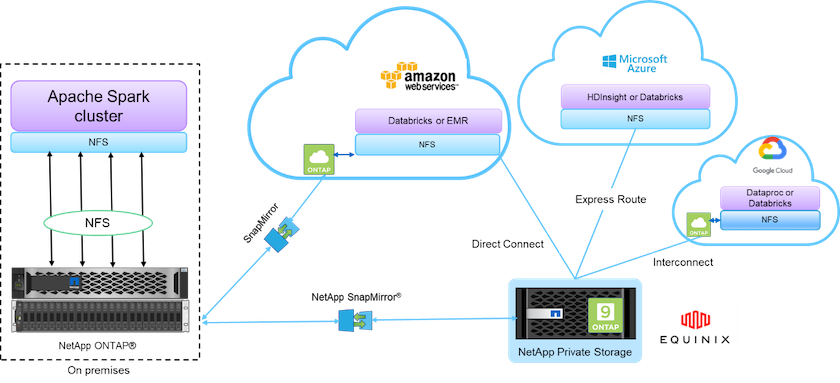
上圖中的構建塊包括:
-
* NetApp NFS 直接存取。 *為最新的 Hadoop 和 Spark 叢集提供對NetApp NFS 磁碟區的直接訪問,無需額外的軟體或驅動程式要求。
-
* NetApp Cloud Volumes ONTAP和Google Cloud NetApp Volumes 。 *基於在 Amazon Web Services (AWS) 或 Microsoft Azure 雲端服務中的Azure NetApp Files (ANF) 中執行的ONTAP的軟體定義連線儲存。
-
* NetApp SnapMirror技術*。在本機和ONTAP Cloud 或 NPS 實例之間提供資料保護功能。
-
*雲端服務提供者。 *這些供應商包括 AWS、Microsoft Azure、Google Cloud 和 IBM Cloud。
-
平台即服務。基於雲端的分析服務,例如 AWS 中的 Amazon Elastic MapReduce (EMR) 和 Databricks 以及 Microsoft Azure HDInsight 和 Azure Databricks。