

TR-4928:負責任的 AI 和機密推理 - NetApp AI 與 Protopia 影像和資料轉換
 建議變更
建議變更
Sathish Thyagarajan、Michael Oglesby、 NetApp Byung Hoon Ahn、Jennifer Cwagenberg、Protopia
隨著影像捕捉和影像處理技術的出現,視覺解讀已成為溝通不可或缺的一部分。數位影像處理中的人工智慧 (AI) 帶來了新的商業機會,例如在醫療領域用於癌症和其他疾病的識別、在地理空間視覺化分析中用於研究環境危害、在模式識別中、在視訊處理中用於打擊犯罪等等。然而,這一機會也伴隨著非凡的責任。
組織交給人工智慧的決策越多,他們承擔的與資料隱私和安全以及法律、道德和監管問題相關的風險就越大。負責任的人工智慧使公司和政府組織能夠建立信任和治理的實踐,這對於大型企業大規模應用人工智慧至關重要。本文檔介紹了NetApp在三種不同情境下驗證的 AI 推理解決方案,該解決方案使用NetApp資料管理技術與 Protopia 資料混淆軟體來私有化敏感資料並降低風險和道德問題。
消費者和商業實體每天都會使用各種數位設備產生數百萬張影像。隨之而來的數據和運算工作量的激增使得企業轉向雲端運算平台來實現規模和效率。同時,隨著影像資料轉移到公有雲,人們對其所含敏感資訊的隱私問題也產生了擔憂。缺乏安全和隱私保障成為影像處理人工智慧系統部署的主要障礙。
此外,還有 "刪除權"根據 GDPR,個人有權要求組織刪除其所有個人資料。還有 "隱私權法",該法案製定了公平資訊實踐準則。根據 GDPR,照片等數位影像可以構成個人數據,GDPR 規定了資料的收集、處理和刪除方式。不這樣做就是不遵守 GDPR,這可能會導致違反合規性的巨額罰款,這可能會對組織造成嚴重損害。隱私權原則是實施負責任的人工智慧的支柱之一,它確保機器學習 (ML) 和深度學習 (DL) 模型預測的公平性,並降低違反隱私或法規遵循相關的風險。
本文檔描述了在三種不同場景下經過驗證的設計解決方案,包括有和沒有影像混淆,這些場景與保護隱私和部署負責任的 AI 解決方案有關:
-
場景 1. Jupyter 筆記本中的按需推理。
-
場景 2.在 Kubernetes 上進行批次推理。
-
場景 3. NVIDIA Triton 推理伺服器。
對於該解決方案,我們使用人臉偵測資料集和基準(FDDB),這是一個為研究無約束人臉偵測問題而設計的人臉區域資料集,結合 PyTorch 機器學習框架來實現 FaceBoxes。此資料集包含 2845 張不同解析度影像中 5171 張臉的註釋。此外,本技術報告還介紹了從NetApp客戶和現場工程師收集的一些適用於此解決方案的解決方案領域和相關用例。
目標受眾
本技術報告面向以下受眾:
-
希望設計和部署負責任的人工智慧並解決公共場所臉部影像處理的資料保護和隱私問題的商業領袖和企業架構師。
-
旨在保護和維護隱私的資料科學家、資料工程師、人工智慧/機器學習 (ML) 研究人員以及人工智慧/機器學習系統開發人員。
-
為符合 GDPR、CCPA 或國防部 (DoD) 和政府組織的隱私法等監管標準的 AI/ML 模型和應用程式設計資料混淆解決方案的企業架構師。
-
資料科學家和人工智慧工程師正在尋找有效的方法來部署深度學習 (DL) 和 AI/ML/DL 推理模型來保護敏感資訊。
-
負責邊緣推理模型的部署和管理的邊緣設備管理員和邊緣伺服器管理員。
解決方案架構
該解決方案旨在利用 GPU 和傳統 CPU 的處理能力來處理大型資料集上的即時和批量推理 AI 工作負載。此驗證證明了尋求負責任的 AI 部署的組織所需的 ML 隱私保護推理和最佳資料管理。該解決方案提供了適用於單節點或多節點 Kubernetes 平台的架構,用於邊緣和雲端運算,並透過 Jupyter Lab 和 CLI 介面與核心本地的NetApp ONTAP AI、 NetApp DataOps Toolkit 和 Protopia 混淆軟體互連。下圖顯示了由NetApp支援、採用 DataOps Toolkit 和 Protopia 的資料結構的邏輯架構概覽。
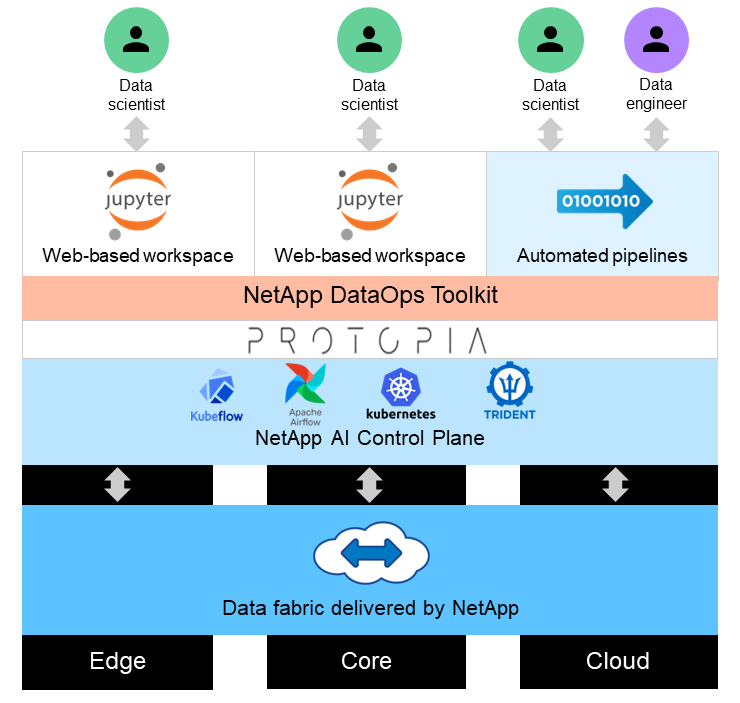
Protopia 混淆軟體在NetApp DataOps Toolkit 上無縫運行,並在離開儲存伺服器之前轉換資料。