

向量資料庫
 建議變更
建議變更
本節介紹NetApp AI 解決方案中向量資料庫的定義與使用。
向量資料庫
向量資料庫是一種特殊類型的資料庫,旨在使用機器學習模型的嵌入來處理、索引和搜尋非結構化資料。它不以傳統的表格格式組織數據,而是將數據排列為高維向量,也稱為向量嵌入。這種獨特的結構使得資料庫能夠更有效率、更準確地處理複雜、多維的資料。
向量資料庫的關鍵功能之一是使用生成式人工智慧進行分析。這包括相似性搜索,其中資料庫識別類似於給定輸入的資料點,以及異常檢測,其中它可以發現與常態有顯著偏差的資料點。
此外,向量資料庫非常適合處理時間資料或帶有時間戳記的資料。這種類型的數據提供有關發生了什麼以及何時發生的信息,按順序以及與給定 IT 系統中所有其他事件的關係。這種處理和分析時間資料的能力使得向量資料庫對於需要了解隨時間推移的事件的應用程式特別有用。
向量資料庫對於機器學習和人工智慧的優勢:
-
高維搜尋:向量資料庫擅長管理和檢索高維數據,這些數據通常在 AI 和 ML 應用程式中產生。
-
可擴展性:它們可以有效擴展以處理大量數據,支援 AI 和 ML 項目的成長和擴展。
-
靈活性:向量資料庫具有高度的靈活性,可以適應多種資料類型和結構。
-
效能:它們提供高效能資料管理和檢索,這對於 AI 和 ML 操作的速度和效率至關重要。
-
可自訂的索引:向量資料庫提供可自訂的索引選項,從而能夠根據特定需求優化資料組織和檢索。
向量資料庫和用例。
本節提供各種向量資料庫及其用例詳細資訊。
Faiss和ScaNN
它們是向量搜尋領域中的重要工具庫。這些庫提供的功能有助於管理和搜尋向量數據,使其成為數據管理這一專業領域的寶貴資源。
Elasticsearch
它是一種廣泛使用的搜尋和分析引擎,最近加入了向量搜尋功能。此新功能增強了其功能,使其能夠更有效地處理和搜尋向量資料。
松果
它是一個具有一組獨特功能的強大向量資料庫。它的索引功能同時支援密集和稀疏向量,從而增強了其靈活性和適應性。它的主要優勢之一在於能夠將傳統搜尋方法與基於人工智慧的密集向量搜尋相結合,從而創造出一種兼具兩全其美的混合搜尋方法。
Pinecone 主要基於雲端,專為機器學習應用而設計,可與各種平台良好集成,包括 GCP、AWS、Open AI、GPT-3、GPT-3.5、GPT-4、Catgut Plus、Elasticsearch、Haystack 等。值得注意的是,Pinecone 是一個閉源平台,可作為軟體即服務 (SaaS) 產品使用。
鑑於其先進的功能,Pinecone 特別適合網路安全產業,其高維度搜尋和混合搜尋功能可以有效地利用來檢測和應對威脅。
色度
它是一個向量資料庫,具有包含四個主要功能的核心 API,其中一個功能包括記憶體文件向量儲存。它還利用 Face Transformers 庫來向量化文檔,增強其功能和多功能性。 Chroma 的設計可在雲端和本地運行,可根據使用者需求提供靈活性。特別是在音訊相關應用方面表現出色,使其成為基於音訊的搜尋引擎、音樂推薦系統和其他音訊相關用例的絕佳選擇。
威維特
它是一個多功能向量資料庫,允許用戶使用其內建模組或自訂模組向量化其內容,根據特定需求提供靈活性。它提供完全託管和自託管解決方案,滿足各種部署偏好。
Weaviate 的主要功能之一是它能夠同時儲存向量和對象,從而增強其資料處理能力。它廣泛應用於一系列應用,包括 ERP 系統中的語義搜尋和資料分類。在電子商務領域,它為搜尋和推薦引擎提供支援。 Weaviate 也用於影像搜尋、異常偵測、自動資料協調和網路安全威脅分析,展示了其在多個領域的多功能性。
Redis
Redis 是一種高效能向量資料庫,以其快速的記憶體儲存而聞名,可為讀寫作業提供低延遲。這使其成為需要快速數據存取的推薦系統、搜尋引擎和數據分析應用程式的絕佳選擇。
Redis 支援向量的各種資料結構,包括列表、集合和有序集。它還提供向量運算,例如計算向量之間的距離或尋找交集和並集。這些功能對於相似性搜尋、聚類和基於內容的推薦系統特別有用。
在可擴展性和可用性方面,Redis 擅長處理高吞吐量工作負載並提供資料複製。它還可以與其他資料類型很好地集成,包括傳統的關係資料庫(RDBMS)。 Redis 包含一個用於即時更新的發布/訂閱(Pub/Sub)功能,這有利於管理即時向量。此外,Redis 輕量且易於使用,使其成為管理向量資料的使用者友善解決方案。
Milvus
它是一個多功能的向量資料庫,提供類似文件儲存的 API,非常類似於 MongoDB。它因支援多種數據類型而脫穎而出,成為數據科學和機器學習領域的熱門選擇。
Milvus 的獨特功能之一是其多向量化功能,它允許使用者在運行時指定用於搜尋的向量類型。此外,它利用 Knowwhere(一個位於 Faiss 等其他庫之上的庫)來管理查詢和向量搜尋演算法之間的通訊。
由於與 PyTorch 和 TensorFlow 相容,Milvus 還提供與機器學習工作流程的無縫整合。這使其成為一系列應用的絕佳工具,包括電子商務、圖像和視訊分析、物件識別、圖像相似性搜尋和基於內容的圖像檢索。在自然語言處理領域,Milvus 用於文件聚類、語意搜尋和問答系統。
對於這個解決方案,我們選擇了 milvus 進行解決方案驗證。為了提高效能,我們同時使用了 milvus 和 postgres(pgvecto.rs)。
為什麼我們選擇 milvus 作為這個解決方案?
-
開源:Milvus 是一個開源向量資料庫,鼓勵社群驅動的開發和改進。
-
AI 整合:它利用嵌入相似性搜尋和 AI 應用程式來增強向量資料庫功能。
-
大容量處理:Milvus 有能力儲存、索引和管理由深度神經網路 (DNN) 和機器學習 (ML) 模型產生的超過十億個嵌入向量。
-
使用者友善:易於使用,設定只需不到一分鐘。 Milvus 也為不同的程式語言提供 SDK。
-
速度:它提供極快的檢索速度,比一些替代方案快 10 倍。
-
可擴展性和可用性:Milvus 具有高度可擴展性,可根據需要進行擴展和縮小。
-
功能豐富:它支援不同的資料類型、屬性過濾、使用者定義函數 (UDF) 支援、可配置的一致性等級和旅行時間,使其成為各種應用的多功能工具。
Milvus 架構概述
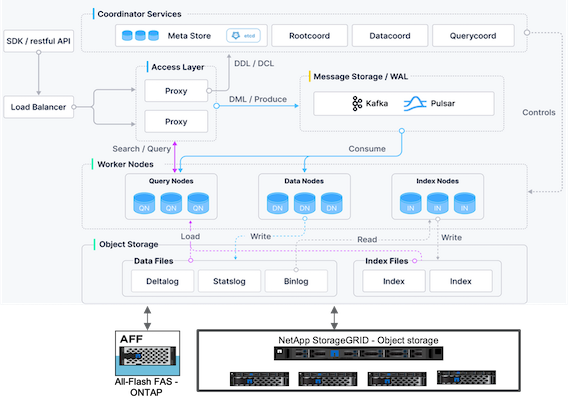
本節提供 Milvus 架構中使用的更高層級的元件和服務。 * 存取層-由一組無狀態代理程式組成,作為系統的前端層和使用者的端點。 * 協調器服務-它將任務分配給工作節點並充當系統的大腦。它有三種協調器類型:根協調器、資料協調器和查詢協調器。 * 工作節點:它遵循協調服務的指令並執行使用者觸發的DML / DDL命令。它有三種類型的工作節點,例如查詢節點,資料節點和索引節點。 * 儲存:負責資料持久化。它包括元存儲、日誌代理和物件存儲。 NetApp儲存(例如ONTAP和StorageGRID)為 Milvus 提供物件儲存和基於文件的存儲,用於客戶資料和向量資料庫資料。