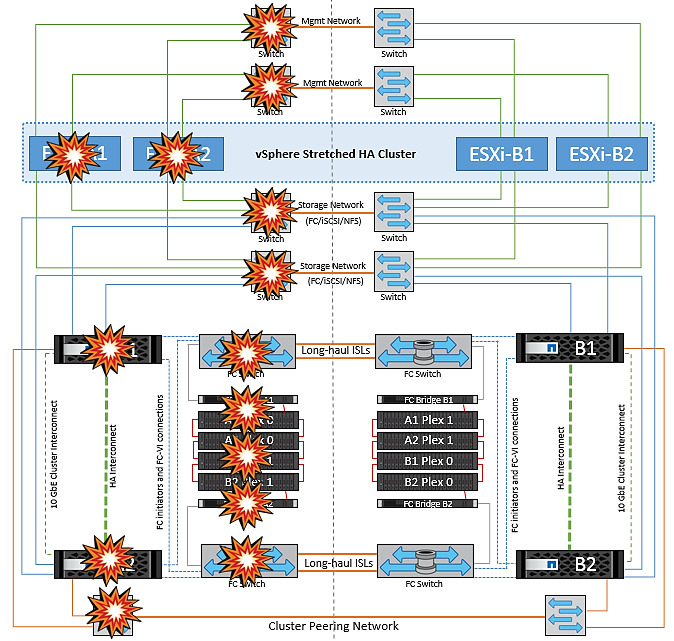
使用 MetroCluster 的 VMSC 的失敗案例
 建議變更
建議變更
以下各節概述 VMSC 和 NetApp MetroCluster 系統各種故障情況的預期結果。
單一儲存路徑故障
在這種情況下、如果 HBA 連接埠、網路連接埠、前端資料交換器連接埠或 FC 或乙太網路纜線等元件故障、 ESXi 主機會將該儲存裝置的特定路徑標記為已停用。如果在 HBA/ 網路 / 交換器連接埠上提供恢復功能、就能為儲存裝置設定多個路徑、 ESXi 理想情況下會執行路徑切換。在這段期間內、虛擬機器會持續執行而不會受到影響、因為提供多條路徑可通往儲存設備、因此可確保儲存設備的可用度。

|
在此案例中、 MetroCluster 行為並無任何變更、所有資料存放區仍會保持不變、不受其個別站台影響。 |
最佳實務做法 _
在使用 NFS/iSCSI 磁碟區的環境中、 NetApp 建議在標準 vSwitch 中、至少為 NFS vmkernel 連接埠設定兩個網路上行鏈路、而在對應 NFS vmkernel 介面的連接埠群組中、則必須設定相同的上行鏈路。NIC 群組可在雙主動式或雙主動式待命模式中進行設定。
此外、對於 iSCSI LUN 、必須將 vmkernel 介面繫結至 iSCSI 網路介面卡、以設定多重路徑。如需詳細資訊、請參閱 vSphere 儲存文件。
最佳實務做法 _
在使用光纖通道 LUN 的環境中、 NetApp 建議至少有兩個 HBA 、以保證 HBA/ 連接埠層級的恢復能力。NetApp 也建議將單一啟動器分區至單一目標分區、以做為設定分區的最佳實務做法。
應使用虛擬儲存主控台( VSC )來設定多重路徑原則、因為它會為所有新的和現有的 NetApp 儲存裝置設定原則。
單一 ESXi 主機故障
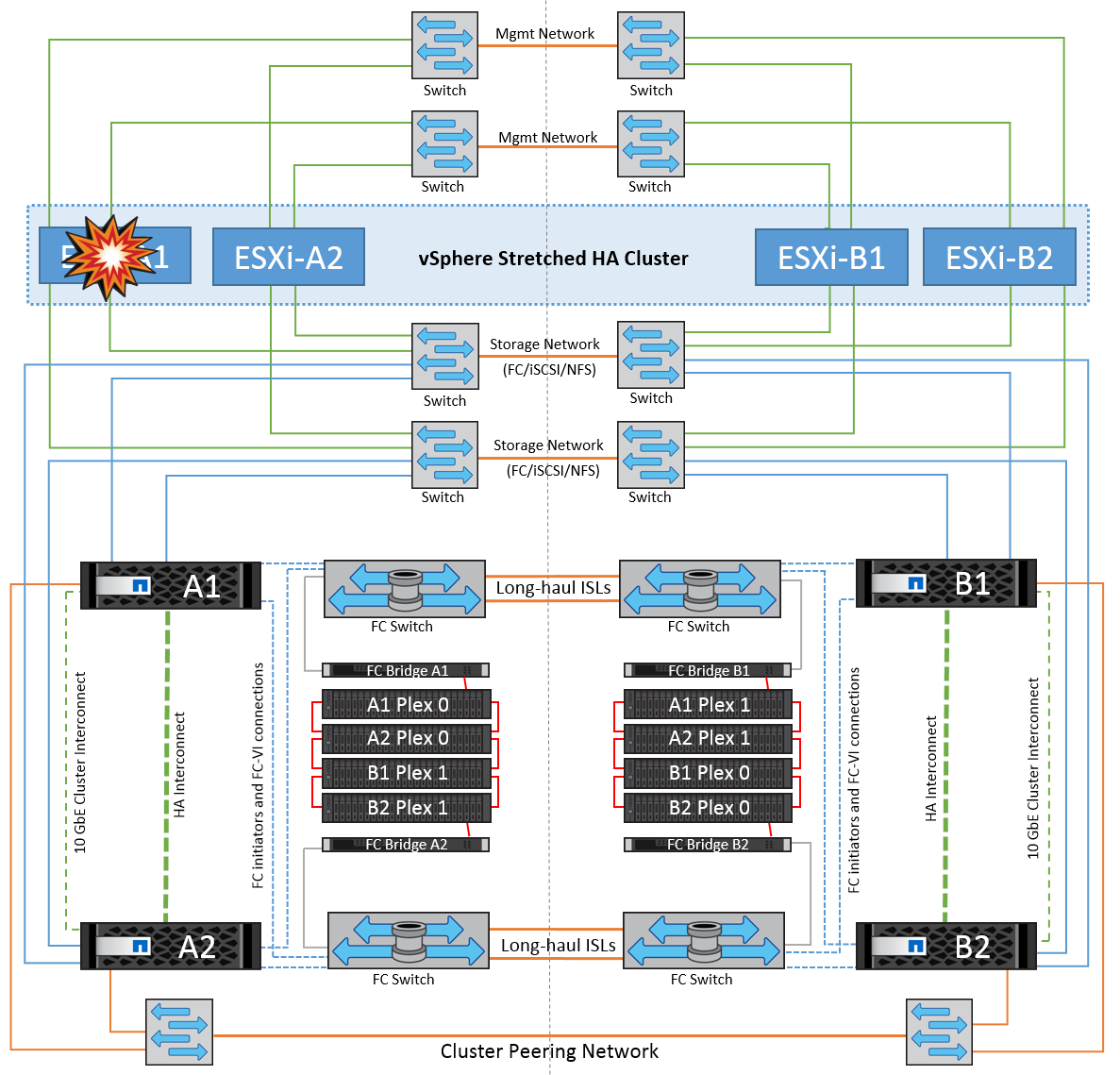
在這種情況下、如果 ESXi 主機發生故障、 VMware HA 叢集中的主節點會偵測主機故障、因為主機不再接收到網路心跳。若要判斷主機是否真的停機或只是網路分割區、主節點會監控資料存放區的訊次、如果沒有、則會 ping 失敗主機的管理 IP 位址、以執行最終檢查。如果所有這些檢查都是負數、則主節點會將此主機宣告為故障主機、而在該故障主機上執行的所有虛擬機器都會在叢集中的正常主機上重新開機。
如果已設定 DRS VM 和主機關聯性規則( VM 群組 sitea_vms 中的 VM 應在主機群組 sitea_hosts 中執行主機)、則 HA 主機會先檢查站台 A 的可用資源如果站台 A 沒有可用的主機、則主主機會嘗試在站台 B 的主機上重新啟動 VM
如果本機站台有資源限制、則可能會在其他站台的 ESXi 主機上啟動虛擬機器。不過、如果將虛擬機器移轉回本機站台中任何仍在運作的 ESXi 主機、而違反任何規則、則定義的 DRS VM 和主機關聯性規則將會修正。如果 DRS 設定為手動、 NetApp 建議您啟動 DRS 、並套用建議來修正虛擬機器的放置位置。
在此案例中、 MetroCluster 行為並無任何變更、所有資料存放區仍會保持不變、不受其個別站台影響。
ESXi 主機隔離
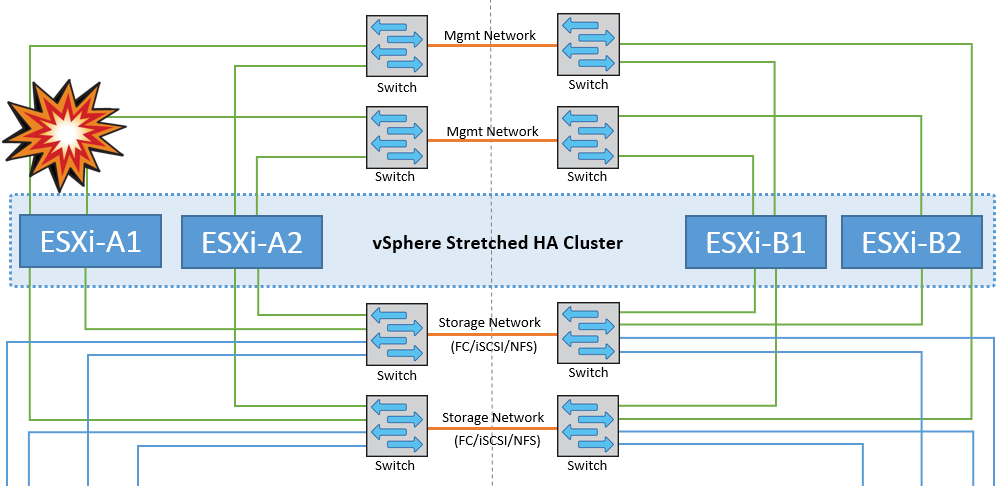
在此案例中、如果 ESXi 主機的管理網路中斷、 HA 叢集中的主節點將不會接收任何訊息、因此此主機會在網路中隔離。若要判斷它是否發生故障或只是隔離、主節點會開始監控資料存放區心跳。如果主機存在、則主機會由主節點宣告為隔離。根據設定的隔離回應、主機可能會選擇關閉、關閉虛擬機器、甚至讓虛擬機器保持開機。隔離回應的預設時間間隔為 30 秒。
在此案例中、 MetroCluster 行為並無任何變更、所有資料存放區仍會保持不變、不受其個別站台影響。
磁碟機櫃故障
在此案例中、有兩個以上的磁碟或整個機櫃發生故障。資料是從仍在運作的複合環境提供、不會中斷資料服務。磁碟故障可能會影響本機或遠端叢。由於只有一個叢處於作用中狀態、因此集合體會顯示為降級模式。更換故障磁碟後、受影響的集合體將自動重新同步以重建資料。重新同步後、集合體將自動返回正常的鏡射模式。如果單一 RAID 群組中有兩個以上的磁碟發生故障,則必須重新建置叢。
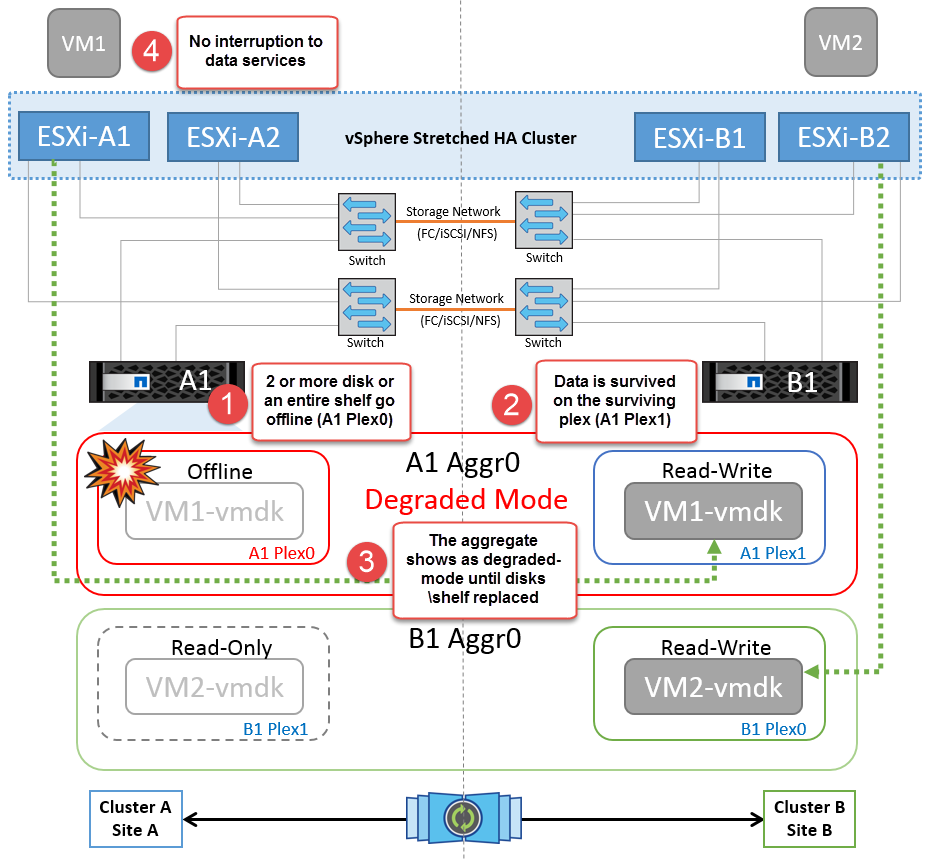
*[ 附註 ]
-
在此期間、虛擬機器 I/O 作業不會受到影響、但效能會降低、因為資料是透過 ISL 連結從遠端磁碟機櫃存取。
單一儲存控制器故障
在這種情況下、兩個儲存控制器中的其中一個會在一個站台發生故障。由於每個站台都有 HA 配對、因此一個節點的故障會以透明方式自動觸發容錯移轉至另一個節點。例如、如果節點 A1 故障、其儲存設備和工作負載會自動傳輸至節點 A2 。虛擬機器將不會受到影響、因為所有的叢集都仍然可用。第二個站台節點( B1 和 B2 )不受影響。此外、 vSphere HA 將不會採取任何行動、因為叢集中的主節點仍會接收到網路心跳。
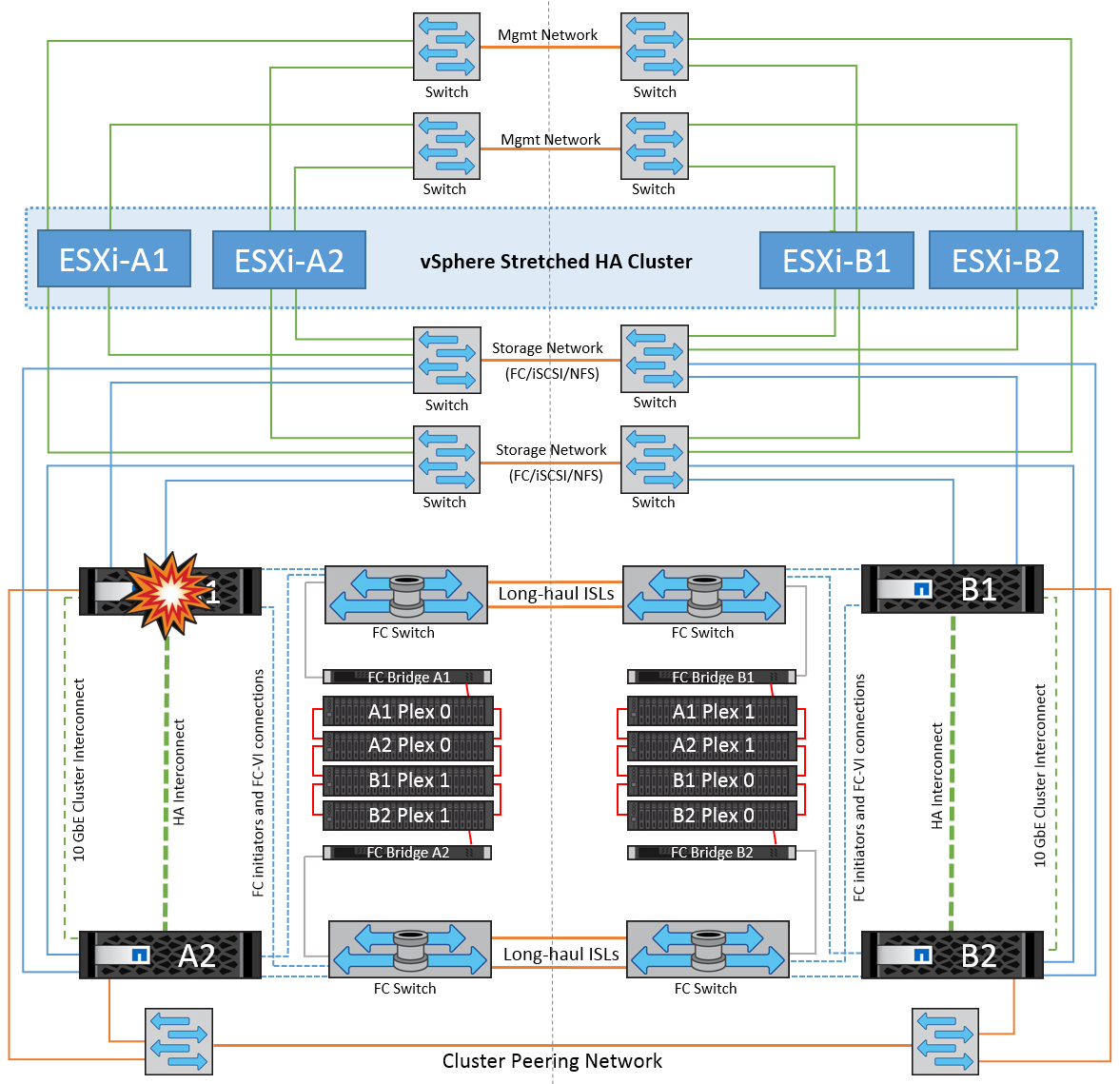
如果容錯移轉是循環災難的一部分(節點 A1 容錯移轉至 A2 )、而且之後發生 A2 故障、或是站台 A 完全故障、則災難後的切換可能會發生在站台 B
交換器間連結故障
管理網路的交換器間連結故障
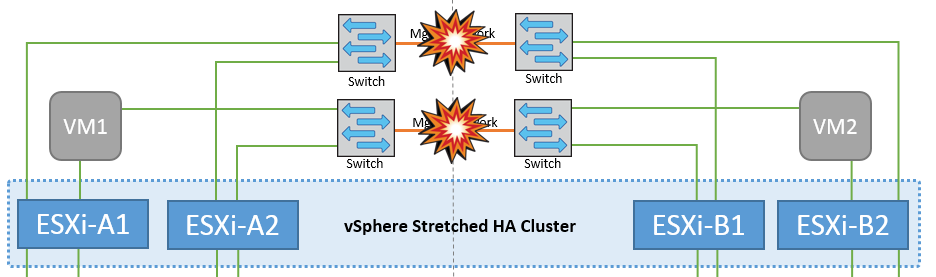
在此案例中、如果前端主機管理網路的 ISL 連結失敗、站台 A 的 ESXi 主機將無法與站台 B 的 ESXi 主機通訊這會導致網路分割區、因為特定站台的 ESXi 主機將無法將網路心跳傳送至 HA 叢集中的主節點。因此、由於分割區的緣故、將會有兩個網路區段、每個區段中都會有一個主節點、可保護 VM 免於特定站台內的主機故障。
|
|
在此期間、虛擬機器仍在執行中、在此案例中 MetroCluster 行為並無變更。所有的資料存放區都會繼續保持不變、不受其個別站台影響。 |
儲存網路的交換器間連結故障
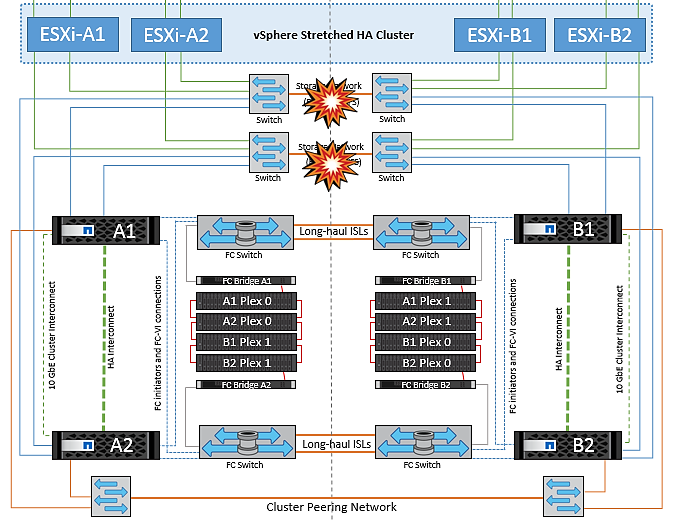
在此案例中、如果後端儲存網路的 ISL 連結故障、站台 A 的主機將無法存取站台 B 的儲存磁碟區或叢集 B 的 LUN 、反之亦然。VMware DRS 規則的定義、是為了讓主機儲存站台的關聯性能讓虛擬機器在不影響站台的情況下執行。
在此期間、虛擬機器會繼續在各自的站台上執行、在此案例中、 MetroCluster 行為不會有任何變更。所有的資料存放區都會繼續保持不變、不受其個別站台影響。
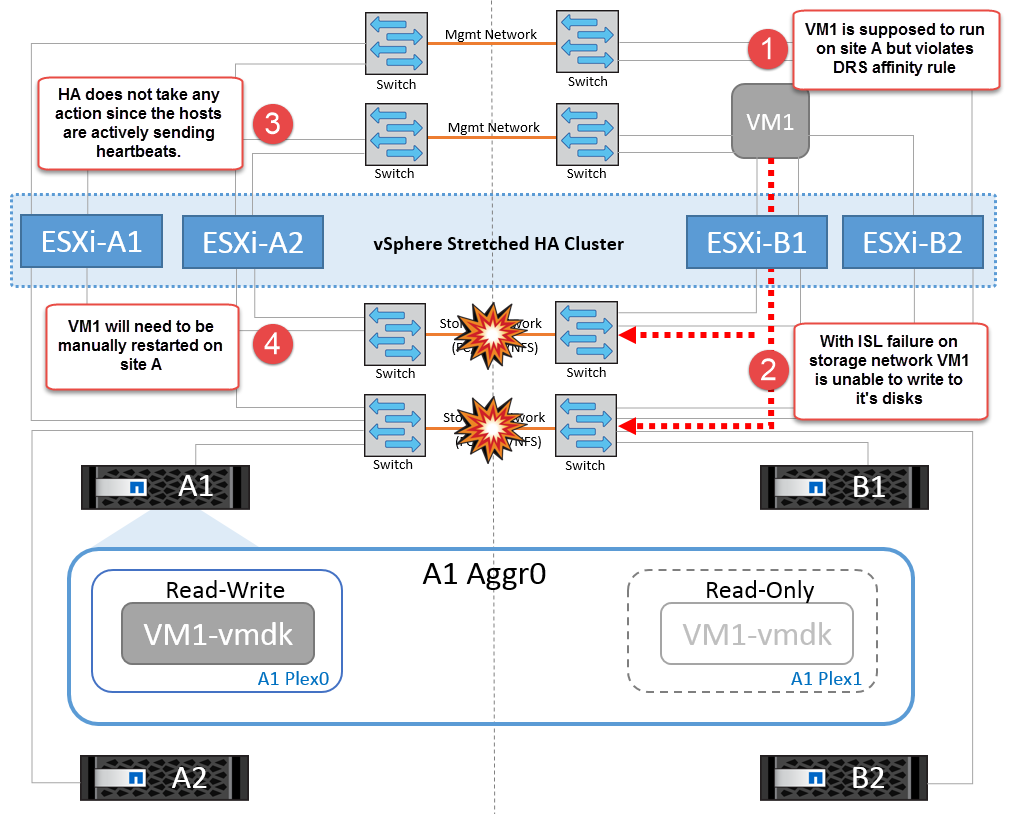
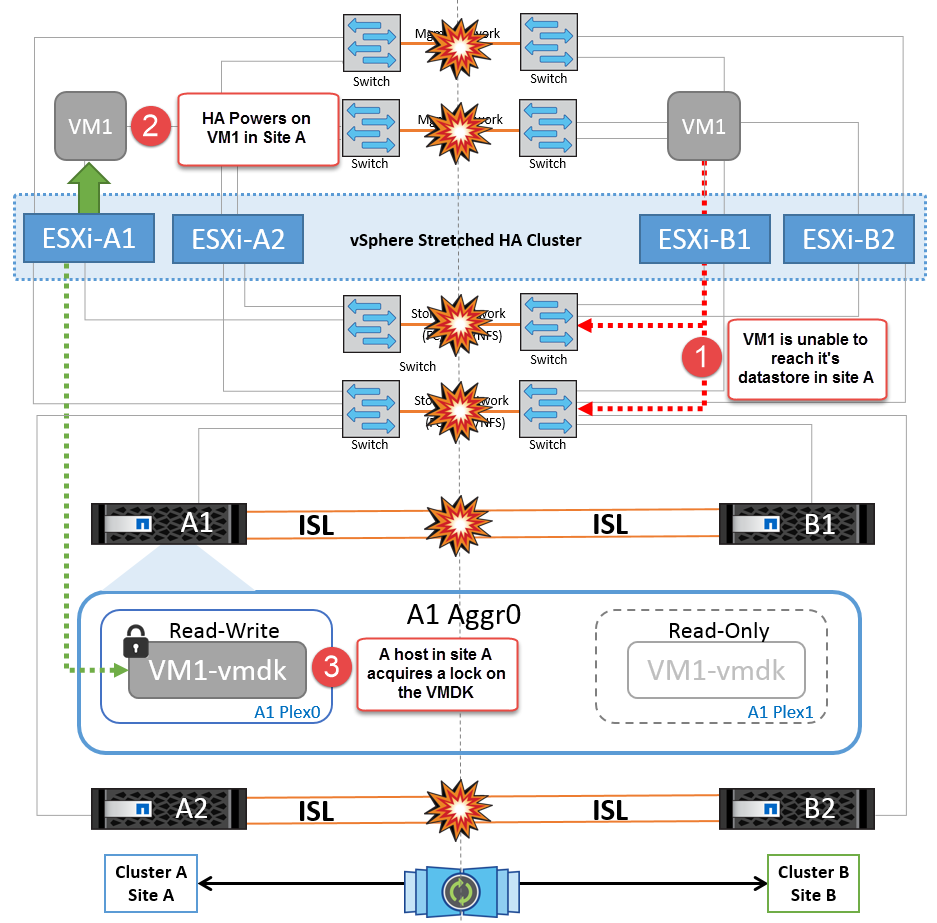
如果因為某種原因違反關聯規則(例如、 VM1 原本應從站台 A 執行、其磁碟位於本機叢集 A 節點上、而 VM1 則是在站台 B 的主機上執行)、則虛擬機器的磁碟將透過 ISL 連結遠端存取。由於 ISL 連結故障、在站台 B 執行的 VM1 將無法寫入其磁碟、因為通往儲存磁碟區的路徑已關閉、且該特定虛擬機器已關閉。在這些情況下、 VMware HA 不會採取任何行動、因為主機正在主動傳送心跳。這些虛擬機器必須在各自的站台手動關閉並開啟電源。下圖說明違反 DRS 關聯性規則的虛擬機器。
所有交換器間故障或完整資料中心分割區
在這種情況下、站台之間的所有 ISL 連結都會中斷、而且兩個站台彼此之間會隔離。如先前的案例所述、例如管理網路和儲存網路的 ISL 故障、虛擬機器在完全 ISL 故障時不會受到影響。
在站台之間分割 ESXi 主機之後, vSphere HA 代理程式會檢查資料存放區心跳,而且在每個站台中,本機 ESXi 主機將能夠將資料存放區心跳更新至各自的讀取 / 寫入磁碟區 /LUN 。站台 A 中的主機會假設站台 B 中的其他 ESXi 主機故障,因為沒有網路 / 資料存放區心跳。站台 A 的 vSphere HA 會嘗試重新啟動站台 B 的虛擬機器,因為站台 B 的資料存放區因為儲存 ISL 故障而無法存取,因此最終會失敗。站台 B 也會再次出現類似的情況
NetApp 建議判斷是否有任何虛擬機器違反 DRS 規則。從遠端站台執行的任何虛擬機器都會停機、因為它們將無法存取資料存放區、 vSphere HA 會在本機站台上重新啟動該虛擬機器。當 ISL 連結恢復上線後、在遠端站台上執行的虛擬機器將會停止運作、因為無法有兩個執行個體使用相同的 MAC 位址執行虛擬機器。
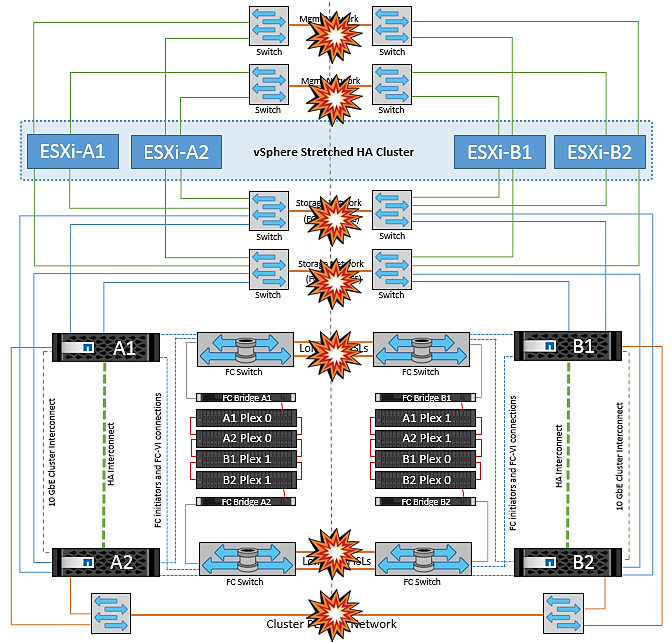
NetApp MetroCluster 中兩個 Fabric 上的交換器間連結故障
在一個或多個 ISL 故障的情況下、流量會繼續流經其餘的連結。如果兩個架構上的所有 ISL 都發生故障、使得儲存和 NVRAM 複寫站台之間沒有連結、則每個控制器都會繼續提供其本機資料。在至少還原一個 ISL 上,所有的叢會自動重新同步。
在所有 ISL 停機之後所發生的任何寫入動作、都不會鏡射到另一個站台。當組態處於此狀態時、發生災難時的切入將會遺失尚未同步的資料。在這種情況下、需要手動介入才能在進行重新操作後恢復。如果很可能在較長的時間內沒有可用的 ISL 、系統管理員可以選擇關閉所有資料服務、以避免在發生災難時發生資料遺失的風險。在至少有一個 ISL 可供使用之前、應將執行此動作的可能性與需要進行重新操作的災難可能性進行權衡。或者、如果 ISL 在串聯案例中發生故障、系統管理員可能會在所有連結失敗之前、觸發已規劃的切換至其中一個站台。
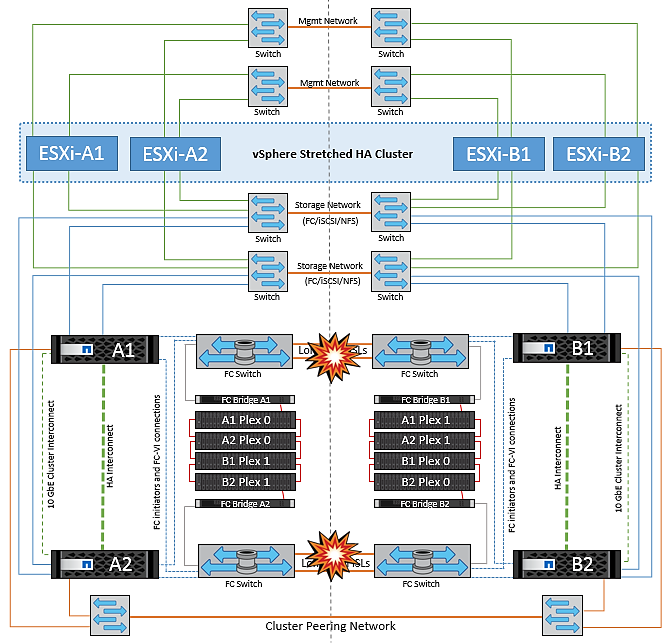
已消除叢集連結故障
在對等叢集連結故障案例中、由於 Fabric ISL 仍處於作用中狀態、因此兩個站台的資料服務(讀取和寫入)都會繼續存在於兩個叢集。任何叢集組態變更(例如、新增 SVM 、在現有 SVM 中配置 Volume 或 LUN )都無法傳播到其他站台。這些資料會保留在本機 CRS 中繼資料磁碟區中,並在還原對等叢集連結時自動傳播到其他叢集。如果必須強制切換才能還原對等叢集連結、則在切換程序中、仍在運作中的站台上、中繼資料磁碟區的遠端複寫複本會自動重新播放未完成的叢集組態變更。
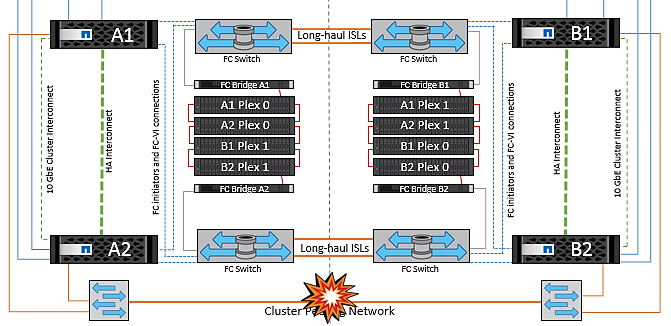
完成站台故障
在完整站台 A 故障案例中、站台 B 的 ESXi 主機因為故障而無法從站台 A 的 ESXi 主機取得網路心跳。站台 B 的 HA 主機會驗證資料存放區心跳不存在、宣告站台 A 的主機故障、並嘗試重新啟動站台 B 中的站台 A 虛擬機器在此期間、儲存管理員會執行一次轉換、以恢復仍在運作的站台上故障節點的服務、該站台將還原站台 B 上站台 A 的所有儲存服務站台 A 磁碟區或 LUN 在站台 B 上可用後、 HA 主代理程式會嘗試重新啟動站台 B 中的站台 A 虛擬機器
如果 vSphere HA 主要代理程式嘗試重新啟動虛擬機器(包括登錄及開機)失敗、則會在延遲後重試重新啟動。重新啟動之間的延遲時間最多可設定為 30 分鐘。vSphere HA 會嘗試重新啟動這些項目、最多嘗試次數(預設為六次)。
|
|
在放置管理程式找到適當的儲存設備之前、 HA 主機不會開始重新啟動嘗試、因此在站台完全故障的情況下、執行切入後即會發生重新啟動嘗試。 |
如果站台 A 已切換、則可透過容錯移轉至正常運作的節點、無縫地處理其中一個仍在運作的站台 B 節點的後續故障。在這種情況下、四個節點的工作現在僅由一個節點執行。在這種情況下、恢復將包括執行恢復到本機節點的贈品。然後、當站台 A 還原時、會執行切換作業、以還原組態的穩定狀態作業。