

VMware vSphere 解決方案概觀
 建議變更
建議變更
vCenter Server Appliance (VCSA) 是一個功能強大的集中式管理系統和 vSphere 的單一管理介面,使管理員能夠有效地操作 ESXi 叢集。它支援虛擬機器配置、vMotion 操作、高可用性 (HA)、分散式資源調度器 (DRS)、VMware vSphere Kubernetes 服務 (VKS) 等關鍵功能。它是 VMware 雲端環境中的重要組成部分,在設計時應考慮到服務的可用性。
vSphere 高可用度
VMware 的叢集技術可將 ESXi 伺服器分組為虛擬機器的共用資源集區,並提供 vSphere High Availability ( HA )。 vSphere HA 可為在虛擬機器中執行的應用程式提供易於使用的高可用度。當叢集上啟用 HA 功能時、每部 ESXi 伺服器都會與其他主機保持通訊、以便在任何 ESXi 主機無回應或隔離時、 HA 叢集可在叢集中的未運作主機之間、協調在該 ESXi 主機上執行的虛擬機器的還原作業。萬一來賓作業系統發生故障, vSphere HA 可在同一部實體伺服器上重新啟動受影響的虛擬機器。 vSphere HA 可減少計畫性停機,避免非計畫性停機,並快速從停機中恢復。
vSphere HA 叢集從故障伺服器還原虛擬機器。
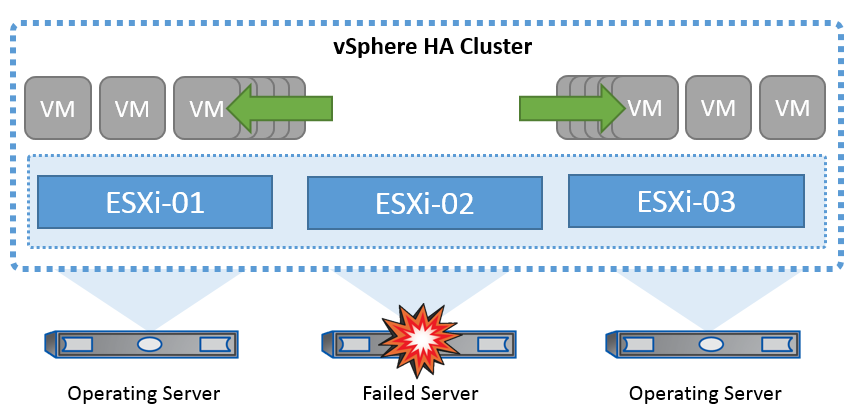
請務必瞭解 VMware vSphere 不知道 NetApp MetroCluster 或 SnapMirror 主動式同步,並視主機和 VM 群組關聯性組態而定,將 vSphere 叢集中的所有 ESXi 主機視為 HA 叢集作業的合格主機。
主機故障偵測
HA叢集建立完成後,叢集中的所有主機都會參與選舉,其中一台主機將成為主主機。每個從設備都會向主設備發送網路心跳訊號,而主設備反過來也會向所有從設備主機發送網路心跳訊號。vSphere HA 叢集的主主機負責偵測從主機的故障。
視偵測到的故障類型而定、在主機上執行的虛擬機器可能需要容錯移轉。
在 vSphere HA 叢集中、偵測到三種類型的主機故障:
-
故障:主機停止運作。
-
隔離:主機會變成網路隔離。
-
分割區 - 主機失去與主主機的網路連線。
主主機會監控叢集中的從屬主機。這種通訊是透過每秒交換網路訊號來完成。當主主機停止從從屬主機接收這些心跳時、它會在宣告主機故障之前先檢查主機的活動性。主要主機執行的活性檢查是判斷從屬主機是否與其中一個資料存放區交換活動訊號。此外、主主機會檢查主機是否回應傳送至其管理 IP 位址的 ICMP Ping 、以偵測其是否只是與主節點隔離、或完全與網路隔離。它會透過 ping 預設閘道來執行此作業。您可以手動指定一或多個隔離位址、以增強隔離驗證的可靠性。

|
NetApp 建議指定至少兩個額外的隔離位址、而且每個位址都是站台本機位址。這將提高隔離驗證的可靠性。 |
主機隔離回應
隔離回應是 vSphere HA 中的一項設置,用於確定當 vSphere HA 叢集中的主機失去其管理網路連線但仍繼續執行時,在虛擬機器上觸發的操作。此設定有三個選項:「停用」、「關閉並重新啟動虛擬機器」和「關閉電源並重新啟動虛擬機器」。
「關機」比「斷電」更好,「斷電」不會將最近的變更刷新到磁碟或提交事務。如果虛擬機器在 300 秒內沒有關閉,則會將其斷電。若要變更等待時間,請使用進階選項 das.isolationshutdowntimeout。
在 HA 起始隔離回應之前、會先檢查 vSphere HA 主要代理程式是否擁有包含 VM 組態檔案的資料存放區。如果沒有、則主機不會觸發隔離回應、因為沒有主節點可重新啟動 VM 。主機會定期檢查資料存放區狀態、以判斷是否由擁有主角色的 vSphere HA 代理程式宣告。
|
|
NetApp 建議將「主機隔離回應」設為「已停用」。 |
如果主機與 vSphere HA 主主機隔離或分割、而主主機無法透過心跳資料存放區或 ping 進行通訊、就可能發生分割腦部狀況。主機會宣告隔離的主機當機、並在叢集中的其他主機上重新啟動 VM 。現在存在分割腦狀況、因為有兩個執行中的虛擬機器執行個體、只有其中一個執行個體可以讀取或寫入虛擬磁碟。現在可以透過設定 VM 元件保護( VMCP )來避免發生大腦分裂的情況。
VM 元件保護( VMCP )
與 HA 相關的 vSphere 6 功能增強功能之一是 VMCP 。VMCP 針對區塊( FC 、 iSCSI 、 FCoE )和檔案儲存( NFS )、提供增強的保護、防止所有路徑中斷( APD )和永久裝置遺失( PDL )情況。
永久裝置遺失( PDL )
PDL 是指儲存設備永久發生故障或被管理員移除且預計不會恢復的情況。NetApp儲存陣列向 ESXi 發出 SCSI Sense 代碼,聲明該裝置已永久遺失。在 vSphere HA 的「故障條件和 VM 回應」部分,您可以設定偵測到 PDL 條件後應採取的回應。
|
|
NetApp建議將「具有 PDL 的資料儲存的回應」設定為「關閉電源並重新啟動虛擬機器」。當偵測到此情況時,虛擬機器將在 vSphere HA 叢集中運作正常的宿主機器上立即重新啟動。 |
所有下行路徑( APD )
APD 是指儲存設備對主機不可見,且沒有通往陣列的路徑時發生的情況。ESXi 認為這是設備的暫時性問題,預計該設備將再次可用。
偵測到 APD 狀況時、會啟動定時器。140 秒後、 APD 條件會正式宣告、且裝置會標示為 APD 逾時。140 秒過後、 HA 會開始計算 VM 容錯移轉 APD 延遲中指定的分鐘數。指定時間過後、 HA 會重新啟動受影響的虛擬機器。您可以設定 VMCP 在需要時以不同的方式回應(停用、問題事件、或關機和重新啟動 VM )。
|
|
|
適用於 NetApp SnapMirror Active Sync 的 VMware DRS 實作
VMware DRS 是一項功能、可將叢集中的主機資源集合在一起、主要用於在虛擬基礎架構中的叢集內進行負載平衡。VMware DRS 主要會計算 CPU 和記憶體資源、以便在叢集中執行負載平衡。由於 vSphere 不知道延伸叢集、因此在負載平衡時會考慮兩個站台中的所有主機。
適用於 NetApp MetroCluster 的 VMware DRS 實作
To avoid cross-site traffic, NetApp recommends configuring DRS affinity rules to manage a logical separation of VMs. This will ensure that, unless there is a complete site failure, HA and DRS will only use local hosts. 如果您為叢集建立 DRS 關聯性規則、您可以指定 vSphere 如何在虛擬機器容錯移轉期間套用該規則。
您可以為 vSphere HA 故障轉移行為指定兩種類型的規則:
-
VM 反關聯性規則會強制指定的虛擬機器在容錯移轉動作期間保持分離。
-
VM 主機關聯性規則會在容錯移轉動作期間、將指定的虛擬機器放置在特定主機或已定義主機群組的成員上。
使用 VMware DRS 中的 VM 主機關聯性規則、可以在站台 A 和站台 B 之間有邏輯分隔、以便 VM 在主機上執行、而該主機與陣列是設定為指定資料存放區的主要讀取 / 寫入控制器。此外、 VM 主機關聯性規則可讓虛擬機器保持儲存設備的本機狀態、進而在站台之間發生網路故障時確定虛擬機器連線。
以下是 VM 主機群組和關聯規則的範例。
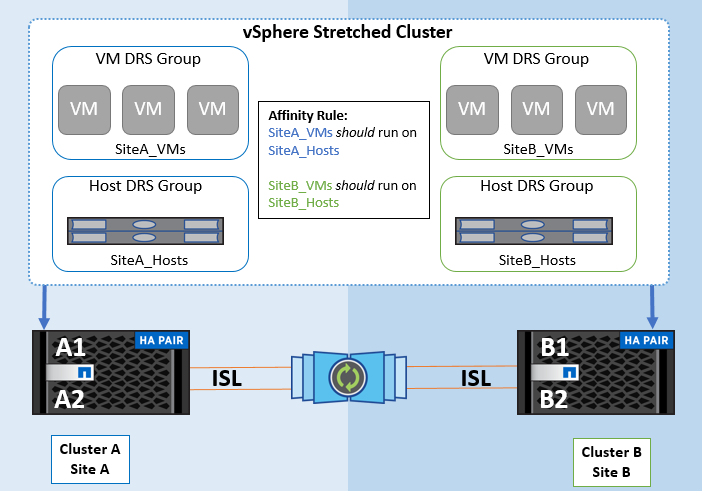
最佳實務做法 _
NetApp 建議實作「應該」規則,而非「必須」規則,因為在發生故障時 vSphere HA 會違反這些規則。使用「必須」規則可能導致服務中斷。
服務的可用性應始終優先於服務的效能。如果整個資料中心發生故障,「必須」規則必須從 VM 主機親緣性群組中選擇主機,且當資料中心無法使用時,虛擬機器將不會重新啟動。
使用 NetApp MetroCluster 實作 VMware Storage DRS
VMware Storage DRS 功能可將資料存放區集合至單一單元,並在超過儲存 I/O 控制( SEIOC )臨界值時平衡虛擬機器磁碟。
依預設、啟用 Storage DRS 的 DRS 叢集會啟用儲存 I/O 控制。儲存 I/O 控制功能可讓管理員控制 I/O 壅塞期間分配給虛擬機器的儲存 I/O 數量、讓更重要的虛擬機器能夠優先選擇較不重要的虛擬機器來分配 I/O 資源。
Storage DRS 使用 Storage VMotion 將虛擬機器移轉至資料存放區叢集中的不同資料存放區。在 NetApp MetroCluster 環境中、必須在該站台的資料存放區內控制虛擬機器移轉。例如、在站台 A 的主機上執行的虛擬機器 A 、最好能在站台 A 的 SVM 資料存放區內移轉如果無法這麼做、虛擬機器將繼續運作、但效能降低、因為虛擬磁碟讀取 / 寫入將透過站台間連結來自站台 B 。
|
|
|