

Verwendung der Latenzprognose für die Performance-Analyse
 Änderungen vorschlagen
Änderungen vorschlagen
Unified Manager verwendet die Latenzprognose, um die typischen Aktivitäten der I/O-Latenz (Reaktionszeit) für überwachte Workloads darzustellen. Er benachrichtigt Sie, wenn die tatsächliche Latenz für einen Workload über den oberen Grenzen der Latenzprognose liegt. Dadurch wird ein dynamisches Performance-Ereignis ausgelöst, sodass Sie das Performance-Problem analysieren und Korrekturmaßnahmen ergreifen können.
Durch die Latenzprognose wird die Performance-Baseline für den Workload festgelegt. Im Laufe der Zeit lernt Unified Manager aus früheren Performance-Messungen, um die erwartete Performance und Aktivitätslevel für den Workload zu prognostizieren. Die obere Grenze des erwarteten Bereichs bestimmt den dynamischen Leistungsschwellenwert. Unified Manager verwendet die Basiskapazität, um zu ermitteln, ob die tatsächliche Latenz einen Schwellenwert oder einen anderen Schwellenwert überschreitet oder außerhalb des erwarteten Bereichs liegt. Der Vergleich der ist-Werte mit den erwarteten Werten erstellt ein Performance-Profil für den Workload.
Wenn die tatsächliche Latenz für einen Workload den dynamischen Performance-Schwellenwert überschreitet, aufgrund von Konflikten bei einer Cluster-Komponente, ist die Latenz hoch, und der Workload arbeitet langsamer als erwartet. Die Performance anderer Workloads, die dieselben Cluster-Komponenten nutzen, ist möglicherweise auch langsamer als erwartet.
Unified Manager analysiert das Schwellenwertüberschreitereignis und legt fest, ob es sich bei der Aktivität um ein Performance-Ereignis handelt. Wenn die Aktivität mit hohen Workloads über einen langen Zeitraum konsistent bleibt, z. B. über mehrere Stunden, berücksichtigt Unified Manager die Aktivität als „Normal“ und passt die Latenzprognose dynamisch an, um den neuen dynamischen Performance-Schwellenwert zu bilden.
Einige Workloads weisen möglicherweise durchgängig niedrige Aktivitäten auf, bei denen die Latenzprognose für Latenz im Laufe der Zeit keine hohen Änderungsraten aufweisen. Um die Anzahl von Ereignissen während der Analyse von Performance-Ereignissen zu minimieren, löst Unified Manager ein Ereignis nur für Volumes mit niedriger Aktivität aus, deren Vorgänge und Latenzen erheblich höher sind als erwartet.
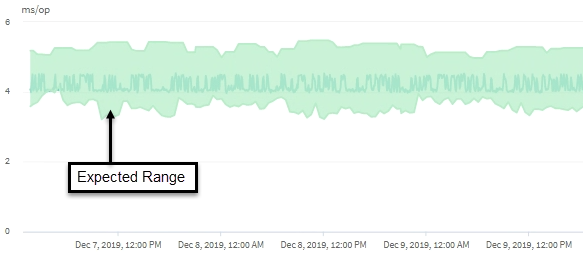
In diesem Beispiel weist die Latenz für ein Volume graue Latenzprognosen von 3.5 Millisekunden pro Betrieb (ms/op) mit dem niedrigsten Wert und 5.5 ms/op bei dem höchsten Wert auf. Wird die tatsächliche Latenz blau auf plötzlich 10 ms/op erhöht, weil der Netzwerk-Traffic oder die Konflikte einer Cluster-Komponente zeitweise zu hoch sind, liegt sie über der Latenzprognose und hat den dynamischen Performance-Schwellenwert überschritten.
Wenn der Netzwerk-Traffic gesunken ist oder die Cluster-Komponente keine Konflikte mehr hat, gibt die Latenz innerhalb der Latenzprognose zurück. Wenn die Latenz für einen langen Zeitraum bei oder über 10 ms/op bleibt, müssen Sie möglicherweise Korrekturmaßnahmen ergreifen, um das Ereignis zu beheben.